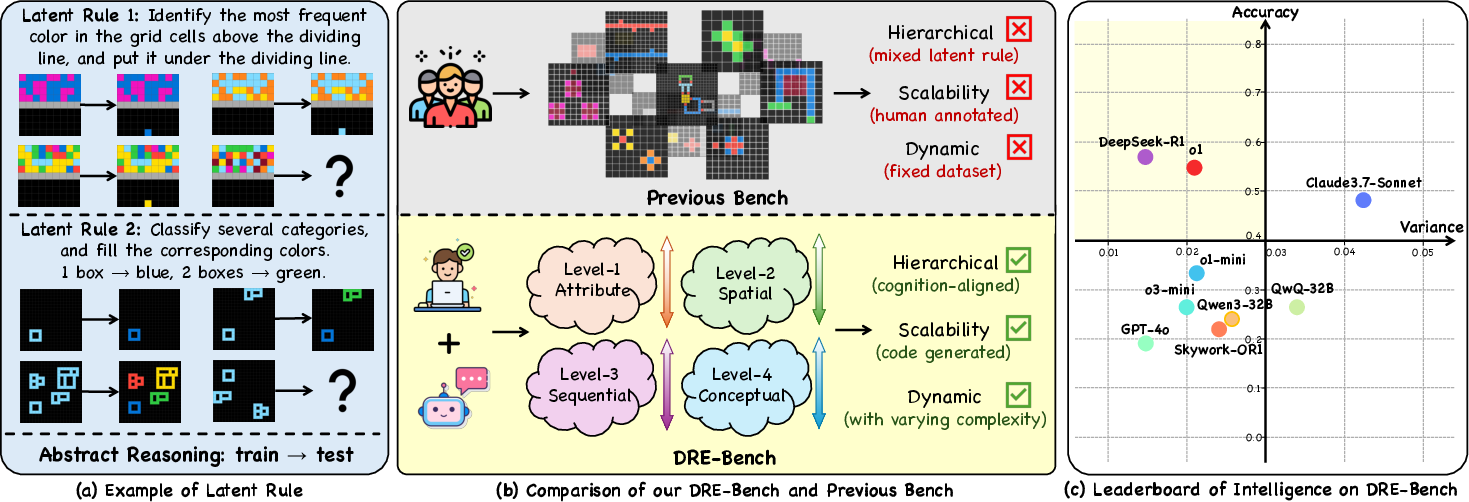
- The paper introduces DRE-Bench—a dynamic, cognition-aligned benchmark assessing LLM fluid intelligence through a hierarchical task structure.
- It employs a code-driven generator and solver pipeline to create scalable, reproducible tasks that prevent memorization-based performance claims.
- Empirical results reveal a decline in LLM performance with increased task complexity, underscoring gaps in abstract reasoning and fluid intelligence.
Rigorous Fluid Intelligence Evaluation in LLMs via Dynamic Reasoning: An Expert Overview of “Truly Assessing Fluid Intelligence of LLMs through Dynamic Reasoning Evaluation” (2506.02648)
The rapid progress of LLMs has led to improved performance across traditional reasoning and knowledge-based benchmarks. However, the extent to which LLMs possess genuine fluid intelligence—the capacity for abstract reasoning and rule generalization in novel contexts—remains insufficiently analyzed by current benchmarks, which often confound memorization, static templates, and domain-specific knowledge. This paper systematically addresses these issues by introducing DRE-Bench, a dynamic, cognition-aligned benchmark targeting fluid intelligence assessment in LLMs through abstract reasoning tasks designed along a rigorous, psychology-informed hierarchy.
Contributions and System Design
Cognition-Aligned Hierarchical Task Structure
The benchmark leverages a four-level cognitive framework inspired by established psychological models of intelligence. The task hierarchy is:
- Level 1 (Attribute): Simple enumeration (size, count, shape).
- Level 2 (Spatial): Spatial transformations (move, rotation, symmetry).
- Level 3 (Sequential): Higher-order abstract reasoning (categorization, sorting, planning) requiring multi-step inference.
- Level 4 (Conceptual): Physical concepts (gravity, reflection, expansion), demanding application of abstract conceptual knowledge.
Each level incorporates multiple latent rules, with distinct dynamic variables to modulate task complexity (Figure 1).
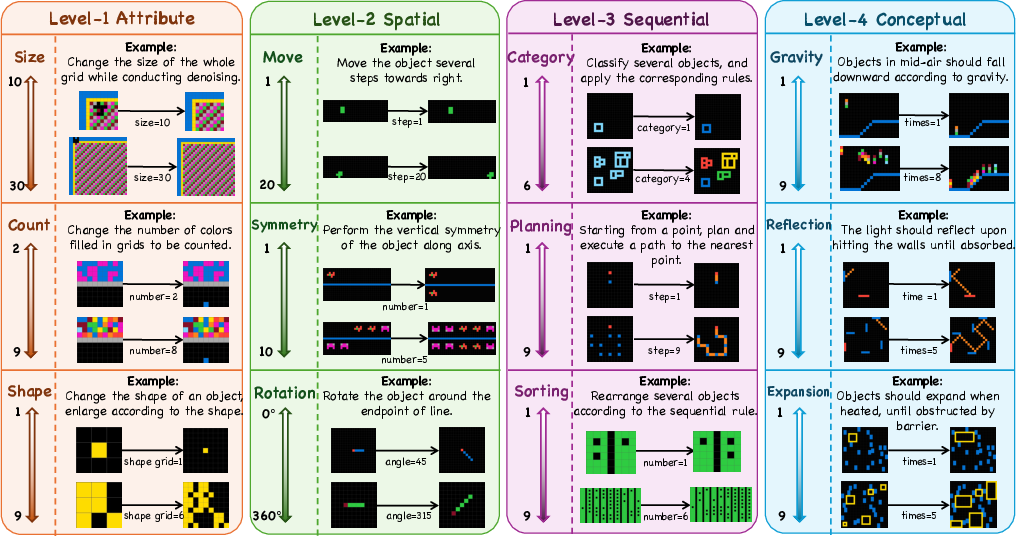
Figure 1: DRE-Bench’s four-level cognitive task taxonomy with dynamic variants visualized.
Dynamic, Scalable Data Generation
To overcome static benchmark limitations and reduce data contamination, DRE-Bench utilizes a code-driven generator–solver pipeline. Task-specific constraints and latent rules are identified by experts, with LLM-based agents implementing parametric generators and verifiable solvers (Figure 2). This approach produces large-scale, reproducible, and diverse task instances.
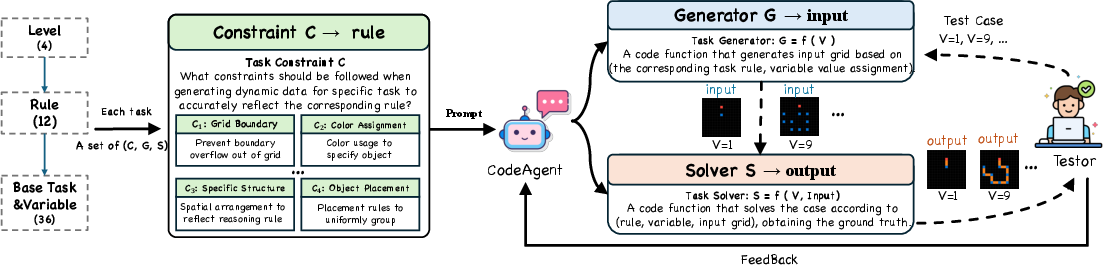
Figure 2: DRE-Bench’s human-agent collaborative data pipeline for scalable, verifiable case generation.
Benchmark Properties
Three core attributes distinguish DRE-Bench:
Experimental Analysis
Model Selection and Evaluation Protocol
The evaluation spans 11 strong LLMs, including generalist models (e.g., GPT-4o, Claude-3.7) and reasoning-specialized systems (e.g., o1, DeepSeek-R1, QwQ, Skywork-OR1). Metrics focus on grid-exact accuracy (output grids must match ground-truth), with average results over multiple seeds and variants per task to reduce randomness.
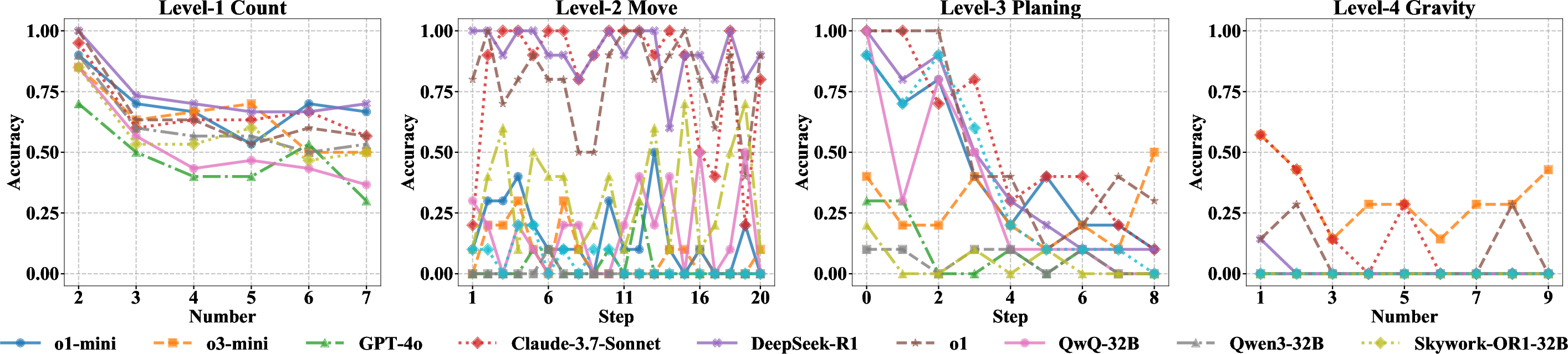
Empirical results show a monotonic performance decline with increasing task level and complexity. Reasoning-oriented models such as o1 and DeepSeek-R1 lead across all levels, especially in spatial and sequential reasoning, yet remain substantially sub-human, especially at Level 4. Other notable findings:
Accuracy-Stability Trade-Offs
Scatter analysis of accuracy vs. variance underscores that only a handful of models are both accurate and stable across dynamic variants on Level-1/2. At higher levels, the majority of LLMs are neither accurate nor stable, further confirming their fragile abstraction abilities (Figure 5).
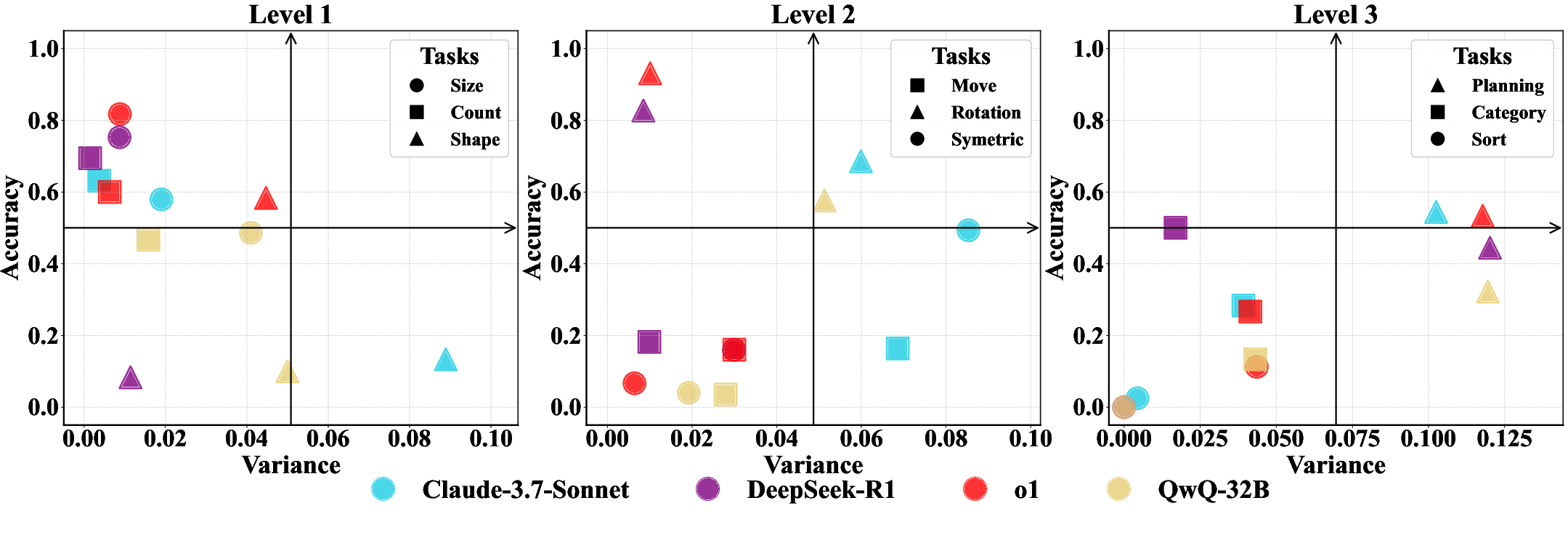
Figure 5: Model accuracy vs. output variance: top left indicates high, stable intelligence; most models cluster away from this region at high cognitive levels.
Ablation: Context, Multimodality, and Inference Time
- In-context sample size: Marginal accuracy benefits, primarily when models are near mastery or on inherently easy tasks. For higher levels, performance plateaus quickly (Figure 6).
- Visual input (multimodality): Surprisingly, augmenting problems with visual representations yields inconsistent or negative gains, a finding in contrast with human cognition, highlighting a current architectural or training limitation (Figure 7).
- Inference time scaling: Longer inference is effective for low-level tasks but does not bridge the gap at higher levels; model architectural limitations rather than computational budget are the primary bottleneck (Figure 8).
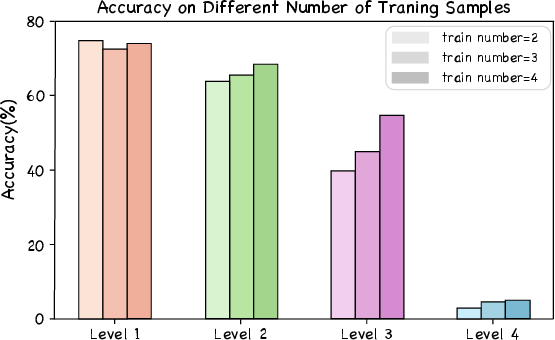
Figure 6: Effect of increasing in-context example count on DeepSeek-R1; diminishing returns beyond few-shot regimes.
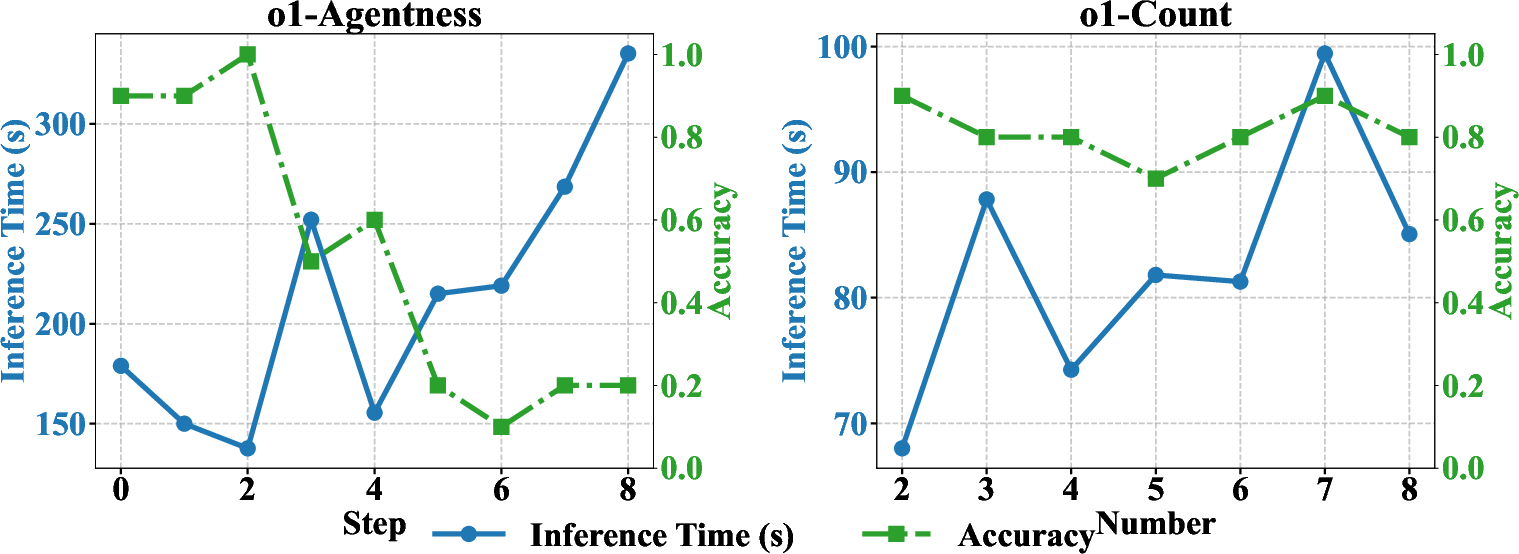
Figure 8: o1’s accuracy and latency as a function of reasoning complexity, evidencing diminishing benefit from increased inference time.
Error Analysis and Cognitive Divergences
Qualitative inspection reveals subtle errors at Levels 1/2, and outright rule failures with disorganized outputs at Levels 3/4 (Figure 9). The orientation analysis—where models show unexpected anisotropies (e.g., vertical > horizontal accuracy)—exposes cognitive idiosyncrasies divergent from human intuition.
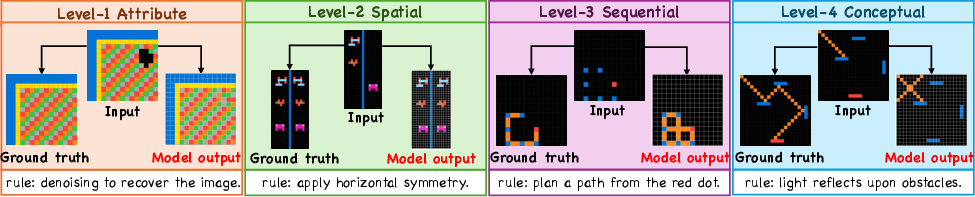
Figure 9: Visualization of LLM error types across cognitive levels, reflecting increasing misalignment and rule confusion.
Implications and Future Directions
The study establishes that even the strongest LLMs (including those specifically engineered for reasoning) lack robust, transferable fluid intelligence. Key takeaways for the community:
- Benchmarking: Static benchmarks are inadequate for measuring fluid intelligence; dynamic, rule-aligned benchmarks are essential for progress.
- Model design: There is substantial headroom for architectural innovation or training algorithm redesign to foster true abstraction, multi-step planning, and conceptual mapping.
- Evaluation: Incorporating task difficulty, output stability, and systematic error analysis should be standard in intelligence assessments.
- Human cognition mapping: The divergence between model and human strategies, especially in spatial or conceptual domains, signals novel directions for hybrid cognitive architectures or inductive bias engineering.
Conclusion
DRE-Bench delivers a rigorous, interpretable, and contamination-resilient benchmark suite for evaluating fluid intelligence in LLMs (2506.02648). Empirical results demonstrate fundamental gaps between current models and human-like reasoning, especially as abstraction and dynamism increase. This framework sets a new standard for both measuring and driving the next phase of LLM research, emphasizing the necessity of models that internalize—not just memorize—generalizable rules and concepts.