LocalBench: Benchmarking LLMs on County-Level Local Knowledge and Reasoning
Abstract: LLMs have been widely evaluated on macro-scale geographic tasks, such as global factual recall, event summarization, and regional reasoning. Yet, their ability to handle hyper-local knowledge remains poorly understood. This gap is increasingly consequential as real-world applications, from civic platforms to community journalism, demand AI systems that can reason about neighborhood-specific dynamics, cultural narratives, and local governance. Existing benchmarks fall short in capturing this complexity, often relying on coarse-grained data or isolated references. We present LocalBench, the first benchmark designed to systematically evaluate LLMs on county-level local knowledge across the United States. Grounded in the Localness Conceptual Framework, LocalBench includes 14,782 validated question-answer pairs across 526 U.S. counties in 49 states, integrating diverse sources such as Census statistics, local subreddit discourse, and regional news. It spans physical, cognitive, and relational dimensions of locality. Using LocalBench, we evaluate 13 state-of-the-art LLMs under both closed-book and web-augmented settings. Our findings reveal critical limitations: even the best-performing models reach only 56.8% accuracy on narrative-style questions and perform below 15.5% on numerical reasoning. Moreover, larger model size and web augmentation do not guarantee better performance, for example, search improves Gemini's accuracy by +13.6%, but reduces GPT-series performance by -11.4%. These results underscore the urgent need for LLMs that can support equitable, place-aware AI systems: capable of engaging with the diverse, fine-grained realities of local communities across geographic and cultural contexts.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces LocalBench, a big “quiz” designed to test AI LLMs on very local knowledge in the United States—things happening at the county level. A county is a smaller area within a state, like a local region with its own government. The goal is to see how well AIs understand and reason about local facts, stories, culture, and community life, not just global or national things.
What questions did the researchers ask?
The researchers wanted to know:
- Can today’s AI models answer questions about specific counties, not just famous cities or global facts?
- Do AIs understand local culture and community discussions, not just statistics?
- Are bigger AI models better at local knowledge, or does adding web search help?
- Where do AIs succeed or fail—especially on story-like questions versus number-based questions?
How did they study it?
They built a new test set called LocalBench with 14,782 question-and-answer pairs from 526 counties across 49 states. These questions cover three types of local knowledge:
- Physical: concrete facts and places (like population or landmarks)
- Cognitive: how people think and talk locally (like slang or topics people discuss)
- Relational: how people and institutions connect (like local government roles, events, or community activities)
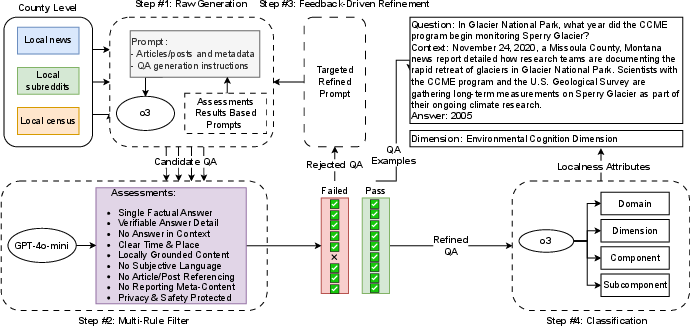
To make LocalBench, they pulled information from three sources:
- Census and official statistics (structured facts like income, voting numbers, housing stability)
- Local subreddit conversations (community chats and stories)
- Local news articles (county-level reporting on events and governance)
They used careful steps to ensure quality:
- They asked an AI to draft questions and answers grounded in the source texts.
- A special “quality checker” filtered out questions that were too subjective, not county-specific, or unclear.
- Human reviewers double-checked samples to make sure the questions and answers were accurate and fair.
- Each question was labeled by what kind of local knowledge it tested (physical, cognitive, or relational) for better analysis.
Then they tested 13 popular AI models in two modes:
- “Closed-book”: the model answers from its own memory, without searching the web.
- “Web-augmented”: the model is allowed to search online, like an open-book test with internet.
They scored the models on:
- Exact correctness and similarity to the right answer
- A special judge model that decides if an answer is correct in cases where wording varies
- Number accuracy for math- or metric-based questions
- Whether the model responds at all (some models choose to say “I don’t know”)
What did they find?
Here are the big results:
- AIs struggle with hyper-local knowledge. Even the best model only reached about 56.8% accuracy on story-like or narrative questions.
- AIs did very poorly on numbers. For questions that ask for a specific statistic (like “What is the median income?”), models were usually under 15.5% accurate.
- Bigger isn’t always better. Larger or more complex models did not consistently beat smaller ones on local knowledge.
- Web search helps some models but hurts others. For example, adding search improved Gemini’s accuracy by about +13.6% but reduced GPT’s accuracy by about –11.4%. This means connecting to the internet doesn’t automatically fix local knowledge gaps.
- Some models avoided answering number questions. One model answered fewer than half of the numeric questions, suggesting it was unsure or cautious.
Why this matters:
- Real-world tools—like local news assistants, city help desks, or neighborhood forums—need AIs that understand local details and community context. Today’s models are not reliable enough for these tasks.
- The results show a fairness issue: AIs often do better with big, well-known places and worse with rural or less-documented areas, which could leave smaller communities behind.
What does this mean for the future?
This research suggests that to make AI truly helpful for local communities, we need new kinds of models and methods:
- Models should be “place-aware,” meaning they can reason with geography, time, and local culture—not just memorize general facts.
- Better ways of using web search are needed. AIs must learn to find and trust high-quality local sources and handle conflicts between what they “know” and what they find online.
- Community involvement matters. Building fair, useful local AIs will require working with local journalists, governments, and residents to capture what’s meaningful in each place.
In short: LocalBench shows that today’s AIs are decent at global knowledge but shaky on real, fine-grained local understanding. Improving this is key if we want AI to support communities fairly and effectively across the country.
Knowledge Gaps
Below is a single, focused list of concrete knowledge gaps, limitations, and open questions left unresolved by the paper. Each point is phrased to enable actionable follow-up by future researchers.
- International generalization: How well do findings and methods transfer beyond the United States, given different administrative geographies, data availability, and sociolinguistic norms? Design and validate LocalBench-style datasets for non‑US contexts.
- Sub-county granularity: Can models handle hyper-locality at finer scales (neighborhoods, census tracts, ZIP codes, city wards)? Build and evaluate benchmarks at sub-county levels and compare with county-scale performance.
- Multilingual and code-switching locality: How do models perform with local knowledge expressed in Spanish, Indigenous languages, and mixed vernaculars? Construct multilingual and code-switch datasets for counties with diverse language communities.
- Rural digital footprint bias: Quantify coverage and model performance gaps in low‑resource rural counties. Develop sampling strategies and incorporate offline or non-indexed sources to mitigate underrepresentation.
- Source diversity expansion: What is the impact of adding local government documents (e.g., county board minutes), community radio transcripts, 311 datasets, Nextdoor/Facebook groups, and community newsletters? Systematically integrate and ablate these sources.
- Temporal dynamics and “as‑of” grounding: Can models track and cite time-sensitive local facts (e.g., policy changes, closures) with explicit “as‑of” dates? Build time-stamped queries, measure drift sensitivity, and require temporal grounding in answers.
- Data leakage assessment: To what extent are models memorizing Reddit/news content present in the benchmark? Perform exposure auditing, use held‑out counties/time splits, and test closed-book vs. retrieval settings for leakage.
- Generator-induced bias: The QA pairs were initially generated and refined by an LLM (o3). What biases in question style, difficulty, and topic selection does this introduce? Compare against human-authored QAs and alternative generators via controlled ablations.
- Ground-truth validation depth: Human verification covered limited samples (500 for filter, 200 for classification). Scale up audits, provide error taxonomies, and measure inter-annotator agreement across all hierarchical localness labels (domain/dimension/component/subcomponent).
- County mapping reliability for subreddits: The manual city/county mappings of local subreddits are error-prone. Quantify mapping accuracy, document decision rules, and report inter-rater agreement; address cases where city subreddits span multiple counties.
- Metric dependence on proprietary judges/embeddings: Evaluation uses GPT‑4o‑mini as judge and OpenAI embeddings. Replicate with open-source judges and multiple embedding models; benchmark inter-judge agreement and sensitivity to evaluator choice.
- Numerical evaluation design: A fixed 2% tolerance may penalize rounding and reporting norms. Evaluate alternative tolerances, unit/scale normalization, and task formulations (comparatives, ranges, ratios); analyze error types (rounding, unit mismatches, stale data).
- Tool-augmented reasoning: Would calculator/API/tool use (e.g., program-of-thought, table querying) remedy numerical failures? Test tool-enabled pipelines, geospatial API integrations, and structured data retrieval for quantitative locality tasks.
- Retrieval pipeline standardization: Web augmentation protocols differ by model. Create a unified retrieval benchmark: log queries, measure document coverage/quality, verify local provenance of citations, and attribute errors to retrieval vs. synthesis via fine-grained diagnostics.
- Stratified performance analysis: Beyond averages, report performance by source (Census vs. Reddit vs. News), RUCC group, region, county popularity, and demographic covariates. Identify systematic biases and their drivers.
- Confidence calibration and uncertainty: Quantify calibration (ECE, Brier score) and alignment between answer rate, stated uncertainty, and correctness. Test prompts that elicit calibrated uncertainty and evaluate effects on local reasoning.
- Evidence use and citation locality: Require models to provide citations; grade the locality and credibility of cited evidence. Detect and penalize non-local or generic sources; assess citation correctness and coverage.
- Generalization and adaptation: How well do models generalize to unseen counties or transfer knowledge across similar localities? Evaluate out‑of‑distribution counties, few-shot adaptation with limited local documents, and meta-learning strategies.
- Robustness to vernacular and slang: Construct adversarial and dialect-rich test sets (local slang, misspellings, code-switching) and measure robustness without performance collapse or stereotyping.
- Multi-turn, agentic tasks: Extend beyond single-turn QA to multi-step civic workflows (e.g., navigating county processes, scheduling, summarizing meetings) and evaluate procedural local reasoning in interactive settings.
- Ethical risk assessment: Develop tests for privacy leakage, stigmatizing narratives, and community harm (especially for small populations). Include red-team evaluations and community oversight in benchmark governance.
- Benchmark maintenance and versioning: Define update cadence, data freshness policies, and “as‑of” labeling to handle local change; track temporal drift and model degradation over time.
- Model ablations and prompt effects: Systematically study chain-of-thought, decomposition, and retrieval-augmented prompts; report their effects on locality tasks across architectures and sizes.
- Place-aware architectural advances: Design and test geographic reasoning modules, spatially grounded attention, or hybrid neuro-symbolic systems tailored to local knowledge integration; compare against transformer baselines.
- Licensing and reproducibility: Clarify data licensing for Reddit/news content and release fully reproducible pipelines using open-source evaluators; document seeds, prompts, and retrieval logs.
- Spatial autocorrelation in errors: Beyond Moran’s I for coverage, analyze spatial clustering of model failures and whether certain regions share error modes; relate to county prominence or media density.
- Task diversity: Evaluate additional local tasks (classification, summarization, decision support) beyond QA to probe broader local competence.
- Coverage completeness: Only 526 counties across 49 states are included; specify selection criteria and add a plan to reach comprehensive county coverage. Identify which state is missing and why.
Glossary
- Agentic web-search approaches: AI systems that autonomously perform web searches to gather and synthesize external evidence for answering queries. "we explore if LLMs and agentic web-search approaches are sufficiently capable to be trusted for community-focused applications."
- Bonferroni correction: A statistical method for controlling the probability of false positives when performing multiple comparisons. "we conduct paired t-tests with Bonferroni correction () to control for multiple comparisons."
- Cohen's d: An effect size measure expressing the standardized difference between two means. "We quantify performance differences with Cohen's , a standardized meanâdifference that expresses how many pooled standard deviations separate two systems;"
- Contrastive Spatial Pretraining (CSP): A pretraining approach using contrastive learning to build multimodal geospatial foundation models from remote sensing data. "Contrastive Spatial Pretraining (CSP)~\cite{mai2023csp} develops multimodal foundation models via visual-text contrastive learning on remote sensing data."
- Cosine similarity: A metric that measures the angle-based similarity between two vectors, often used for comparing embeddings. "we compute a semantic match score: the cosine similarity between dense embeddings of the generated answer and our ground-truth answer"
- Dense embeddings: Continuous vector representations capturing semantic information used for similarity and retrieval. "dense embeddings of the generated answer and our ground-truth answer, obtained with OpenAIâs text-embedding-3-small."
- Direct Preference Optimization (DPO): A training method that optimizes model outputs directly against human preference signals. "trained via Direct Preference Optimization (DPO)~\cite{rafailov2023direct}"
- Family-wise error rate: The probability of making at least one false positive across a family of statistical tests. "To protect the familyâwise error rate during the many pairwise contrasts, we adjust each âvalue with the Bonferroni procedure"
- GPT Judge mechanism: An LLM-based evaluation component that adjudicates whether a model’s answer matches the ground truth. "we introduce a GPT Judge mechanism."
- Inter-annotator agreement (κ): A reliability metric (Cohen’s kappa) quantifying consistency between annotators. "inter-annotator agreement ."
- Mixture-of-Experts (MoE): A model architecture that routes inputs to specialized expert subnetworks to improve capacity and efficiency. "mixture-of-experts (MoE) architectures show no consistent advantage over smaller non-MoE models."
- Moran's I: A statistic for measuring spatial autocorrelation, indicating how values are correlated across geographic space. "Moran's (), indicating no spatial autocorrelation."
- Parametric knowledge: Information implicitly stored in a model’s parameters rather than retrieved externally. "maintaining uncertainty calibration when external information conflicts with parametric knowledge."
- Relative error: A normalized measure of the difference between a predicted numeric value and the true value. "counts a numerical prediction as correct if its relative error is under 2\% of the gold value (and requires an exact zero when the gold answer is zero)."
- ROUGE-1 F1: A text similarity metric based on unigram overlap, used to assess paraphrase-level correctness. "and ROUGE-1 F1, which tolerates paraphrasing through unigram overlap."
- Rural-Urban Continuum Codes (RUCC): USDA classification codes that categorize U.S. counties by degrees of urbanization and adjacency. "Using Rural-Urban Continuum Codes (RUCC),we stratified counties into urban (RUCC 1â3), suburban (4â6), and rural (7â9) groups."
- Search Grounding: A retrieval setup where model responses are explicitly supported by external search evidence. "Gemini-2.5-Pro with Search Grounding."
- Semantic match score: An embedding-based similarity metric comparing the generated answer to the gold answer beyond lexical overlap. "we compute a semantic match score: the cosine similarity between dense embeddings of the generated answer and our ground-truth answer"
- Spatial autocorrelation: The degree to which a spatial variable correlates with itself across locations, indicating clustering or dispersion patterns. "indicating no spatial autocorrelation."
- Spatial embeddings: Learned vector representations that encode spatial or geographic properties for downstream tasks. "These efforts focus on spatial embeddings and regression tasks,"
- Temperature parameter: A sampling hyperparameter controlling randomness in model generation; lower values yield more deterministic outputs. "The generator operates with a temperature parameter of 0.7,"
- Top-p parameter: A nucleus sampling hyperparameter limiting sampling to the smallest set of tokens whose cumulative probability exceeds p. "top-p parameter of 0.9,"
- Web augmentation: Enhancing model performance by incorporating information retrieved from the web during inference. "Web augmentation further exposes architectural differences in retrieval integration."
Practical Applications
Immediate Applications
The following applications can be deployed now, using LocalBench as an evaluation asset, its construction pipeline as a template, and its findings to guide risk, tooling, and procurement decisions.
- Bold: Pre-deployment audit for local-use LLMs (Industry, Government/Civic Tech)
- What: Use LocalBench to score candidate models by county type (rural/suburban/urban) and task type (narrative vs. numeric); ship “Local QA Scorecards” to gate deployments.
- Tools/Workflows: LocalBench dataset; evaluation harness with EM/ROUGE/semantic/GPT-judge; county-type stratified dashboards; CI gates per metric.
- Assumptions/Dependencies: US-only coverage; dataset freshness; licensing of evaluated models; acceptance of GPT-judge as proxy for human review.
- Bold: Procurement criteria for place-aware AI (Policy, Public Sector)
- What: Add LocalBench thresholds and rural/suburban/urban parity checks to RFPs for chatbots, call centers, and information portals; require source-citation for numeric outputs.
- Tools/Workflows: “Place-aware” minimum scores; parity metrics across RUCC codes; numeric-claim guardrails.
- Assumptions/Dependencies: Agency willingness to adopt performance thresholds; periodic re-testing as models drift.
- Bold: Civic service chatbots with numeric-claim guardrails (Government, Healthcare, Utilities)
- What: Enforce citation or database-grounding for county-level numbers (permits, fees, deadlines, vaccination rates); otherwise abstain or hand off.
- Tools/Workflows: “Numeric Claim Gatekeeper” that checks 2% error tolerance; RAG to authoritative sources (Census, county portals); human escalation.
- Assumptions/Dependencies: API access to authoritative data; liability policies for abstentions; up-to-date datasets.
- Bold: County-aware RAG tuning for local products (Software, Maps/GIS, Travel)
- What: Evaluate retrieval sources (local news, county PDFs, Census APIs, local subreddits) and re-rankers using LocalBench non-numeric tasks; test web augmentation effects by model family (Gemini vs. GPT).
- Tools/Workflows: County-scoped indices, retrieval priors by RUCC codes, per-county cache; A/B tests on web augmentation because effects are model-dependent.
- Assumptions/Dependencies: Source licensing (news, Reddit); robust connectors; monitoring for drift and scraping bans.
- Bold: Newsroom assistants for local fact-check and context (Media/Publishing)
- What: Use LocalBench to calibrate assistants; flag high-risk classes (numeric, governance); require evidence links for claims about county boards, elections, or local ordinances.
- Tools/Workflows: Editorial sidecar that scores claims; “must-cite” policy for numbers; LocalBench-aligned QA checks.
- Assumptions/Dependencies: Integration with CMS; newsroom standards; archive/licensing constraints.
- Bold: Real estate and neighborhood guide QA (PropTech)
- What: Test and constrain neighborhood summaries to avoid stereotypes; add “uncertainty + cite” for socio-economic stats; suppress generic outputs for under-documented locales.
- Tools/Workflows: Localness category coverage checks; stereotype filters; numeric abstention rules.
- Assumptions/Dependencies: Fair housing compliance; liability review; up-to-date census slices.
- Bold: Customer support triage for county-specific rules (Healthcare payers/providers, Utilities)
- What: Route queries requiring local policy interpretation (e.g., eligibility, service territories) to grounded flows; use LocalBench parity metrics to ensure equitable performance across counties.
- Tools/Workflows: Policy KBs per county; RUCC-aware routing; evaluation across county cohorts.
- Assumptions/Dependencies: Accurate policy ingestion; PHI/PII controls; frequent updates.
- Bold: Education and community learning tools (Education)
- What: County civics study aids with verified numeric cards; built-in “learn more” links to local sources; bias demos using rural/suburban/urban comparisons.
- Tools/Workflows: Flashcards from authoritative data; LocalBench-driven lesson plans on model bias.
- Assumptions/Dependencies: FERPA compliance; accessibility; age-appropriate content.
- Bold: GIS-assisted summarization and reporting (Software, Planning)
- What: Summarize county-level map layers with strict numeric grounding; LocalBench-based regression tests before shipping updates.
- Tools/Workflows: GIS-in-the-loop RAG; numeric validator; CI tests with LocalBench subsets matching geographies in use.
- Assumptions/Dependencies: GIS data currency; API quotas; reproducibility of map states.
- Bold: Risk and compliance dashboards for model owners (Finance, Insurance, Regulated Industries)
- What: Track local QA risk classes (numeric vs. narrative), answer-rate behaviors, and county-type disparities; tie to rollout decisions and model routing.
- Tools/Workflows: Metrics from the paper (answer rate, GPT-judge accuracy); cohort-based SLOs; alerts on regression.
- Assumptions/Dependencies: Telemetry instrumentation; policy linking metrics to launch gates.
Long-Term Applications
These applications require additional research, scaling, or development. They draw directly from the paper’s findings on numeric weaknesses, retrieval paradoxes, and scaling limits.
- Bold: Place-aware LLM architectures with GIS/temporal modules (Software, Robotics)
- What: Architectures that encode spatial indices, time, and county hierarchies; attention over geographic entities; built-in spatial priors.
- Tools/Workflows: GIS-aware attention; spatial memory; temporal grounding.
- Assumptions/Dependencies: New training corpora with spatial annotations; benchmarks beyond US; compute budgets.
- Bold: Database- and SQL-in-the-loop numeric reasoning (Healthcare, Gov, Finance)
- What: Force numeric answers to execute against vetted databases (Census, CDC, county budgets) with 2% tolerance checks; log query provenance.
- Tools/Workflows: Toolformer-style DB connectors; provenance ledger; continuous schema sync.
- Assumptions/Dependencies: Stable schemas; data freshness SLAs; privacy and licensing.
- Bold: County knowledge graphs and entity-resolution pipelines (Civic Tech, Software)
- What: Merge Census, ordinances, permits, events, and forum discourse into county-level KGs to support precise grounding and disambiguation.
- Tools/Workflows: ETL, canonical IDs, ontology aligned to the Localness framework.
- Assumptions/Dependencies: Data partnerships; sustained curation; governance for contested facts.
- Bold: RUCC-aware model routing and retrieval policies (Transportation, E-commerce)
- What: Route rural queries to models/policies tuned for sparse-source uncertainty; adjust retrieval priors and abstention thresholds by county type.
- Tools/Workflows: Policy engine keyed on RUCC; per-county retrieval priors; uncertainty-aware UX.
- Assumptions/Dependencies: Reliable RUCC mappings; user tolerance for abstentions.
- Bold: Web augmentation that calibrates and reconciles conflicts (All sectors)
- What: Retrieval agents that detect conflicting local sources, quantify disagreement, and surface uncertainty instead of overconfident answers.
- Tools/Workflows: Conflict-detection heuristics; evidence aggregation; calibrated confidence.
- Assumptions/Dependencies: New training for uncertainty alignment; high-quality retrieval pipelines.
- Bold: International LocalBench variants and multilingual localness (Global Policy, NGOs, Education)
- What: Port the benchmark to counties/districts abroad; include multilingual and code-switch vernaculars; evaluate local governance structures.
- Tools/Workflows: Data sourcing playbooks; multilingual QA pipelines; cultural review boards.
- Assumptions/Dependencies: Local data availability; community consent; translation quality.
- Bold: “Place-Aware AI” certification (Standards, Policy)
- What: Third-party audits using LocalBench-style suites; publish parity, numeric accuracy, and sourcing disclosures for procurement and compliance.
- Tools/Workflows: Standard test subsets; reporting schema; model cards with locality metrics.
- Assumptions/Dependencies: Standards bodies buy-in; legal frameworks for disclosure.
- Bold: Privacy-preserving learning over hyper-local forums (Healthcare, Community Platforms)
- What: Differential privacy/federated learning to leverage local discourse without leaking identities; community-controlled opt-in.
- Tools/Workflows: DP budgets; on-device adapters; consent management.
- Assumptions/Dependencies: Platform cooperation; rigorous privacy guarantees; IRB/ethics oversight.
- Bold: Community-in-the-loop curation and redress mechanisms (Civic Tech)
- What: Allow residents to flag errors, contribute updates, and vote on contested local facts; integrate corrections into models/KGs.
- Tools/Workflows: Feedback portals; adjudication workflows; provenance tracking.
- Assumptions/Dependencies: Moderation capacity; abuse prevention; representation equity.
- Bold: Crisis/incident local intelligence (Emergency Management, Public Health)
- What: Systems that ground in real-time county feeds (alerts, shelters, closures) and abstain when sources conflict; localized multilingual output.
- Tools/Workflows: Streaming retrieval; reliability scoring; crisis UX patterns.
- Assumptions/Dependencies: Access to real-time feeds; resiliency under load; liability management.
- Bold: Geo-tailored content with stereotype safeguards (Marketing, E-commerce)
- What: Generate county-aware messaging constrained by bias and stereotype filters; require evidence for any socio-economic statistic.
- Tools/Workflows: Bias detectors; numeric guardrails; human-in-the-loop approvals.
- Assumptions/Dependencies: Brand safety requirements; audience testing; legal review.
- Bold: Transportation and logistics planning assistants with local constraints (Mobility, Energy)
- What: Incorporate county permitting, road restrictions, and community events into routing and scheduling; verify numerics via databases.
- Tools/Workflows: County rules KB; scenario planning; DB-grounded numerics.
- Assumptions/Dependencies: Data agreements with DOTs/counties; timeliness of restrictions.
Notes on Cross-Cutting Assumptions and Dependencies
- Data coverage and freshness: Current benchmark is US-only and time-bounded; many applications need continuous updates and local data partnerships.
- Licensing and ethics: Use of local news and subreddit content must respect terms, privacy, and community norms; multilingual and Indigenous contexts require special care.
- Model variability: Web augmentation effects are model-dependent (helped Gemini, hurt GPT in tests); teams must measure with their specific stack.
- Safety and liability: Especially for numeric outputs, require provenance and abstention pathways; align with legal and regulatory expectations.
- Equity: Monitor rural/suburban/urban disparities; include parity thresholds to avoid unequal service quality.
Collections
Sign up for free to add this paper to one or more collections.