- The paper presents OmniSonic, a universal model that generates synchronized on- and off-screen audio from video and textual descriptions.
- It employs a TriAttn-DiT backbone with triple cross-attention and adaptive MoE gating to effectively fuse multimodal cues.
- Quantitative benchmarks such as a FAD of 3.07 and high MOS ratings demonstrate its superior performance in holistic audio generation.
Universal Holistic Audio Generation with OmniSonic
This paper presents Universal Holistic Audio Generation (UniHAGen), a task that addresses comprehensive auditory scene synthesis from video and textual cues, subsuming both visible (on-screen) and invisible (off-screen) sound sources across speech and environmental domains. This formulation addresses critical limitations in existing multimodal generative models, which either restrict attention to on-screen events or focus exclusively on non-speech domains. The proposed OmniSonic model is introduced as a unified diffusion framework to overcome these obstacles, capable of generating temporally and semantically congruent audio reflecting complex, mixed-domain real-world scenes.
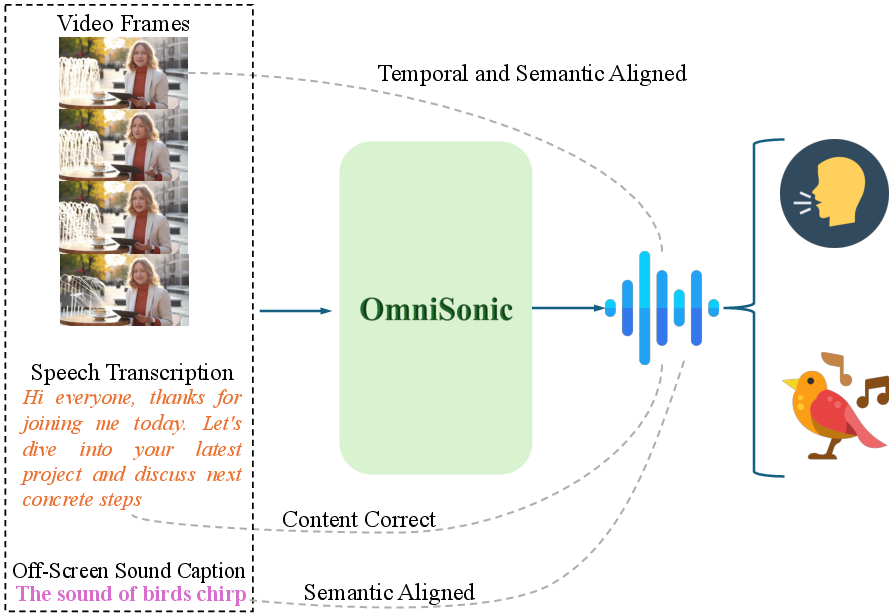
Figure 1: The UniHAGen task—requiring simultaneous, semantically-faithful generation of on-screen speech, visually aligned, and off-screen environmental sound from multimodal conditions.
In contrast to previous frameworks, UniHAGen explicitly stresses three canonical configurations: (1) on-screen environmental + off-screen speech; (2) on-screen speech + off-screen environmental sound; and (3) on-screen environmental + off-screen environmental + off-screen speech. This taxonomy facilitates evaluation of a model's capacity for multimodal reasoning and cross-domain (environmental and speech) audio synthesis.
Model Architecture and Methodology
OmniSonic is structured as a flow-matching-based diffusion model, operating in the latent space of Mel-spectrograms. The architecture encapsulates a sequence of learned condition encoders (FLAN-T5 for environmental captions, SpeechT5 for transcriptions, CLIP for visual frames), a VAE-based audio encoder-decoder stack, and a newly designed TriAttn-DiT backbone featuring triple cross-attention and Mixture-of-Experts (MoE) gating.
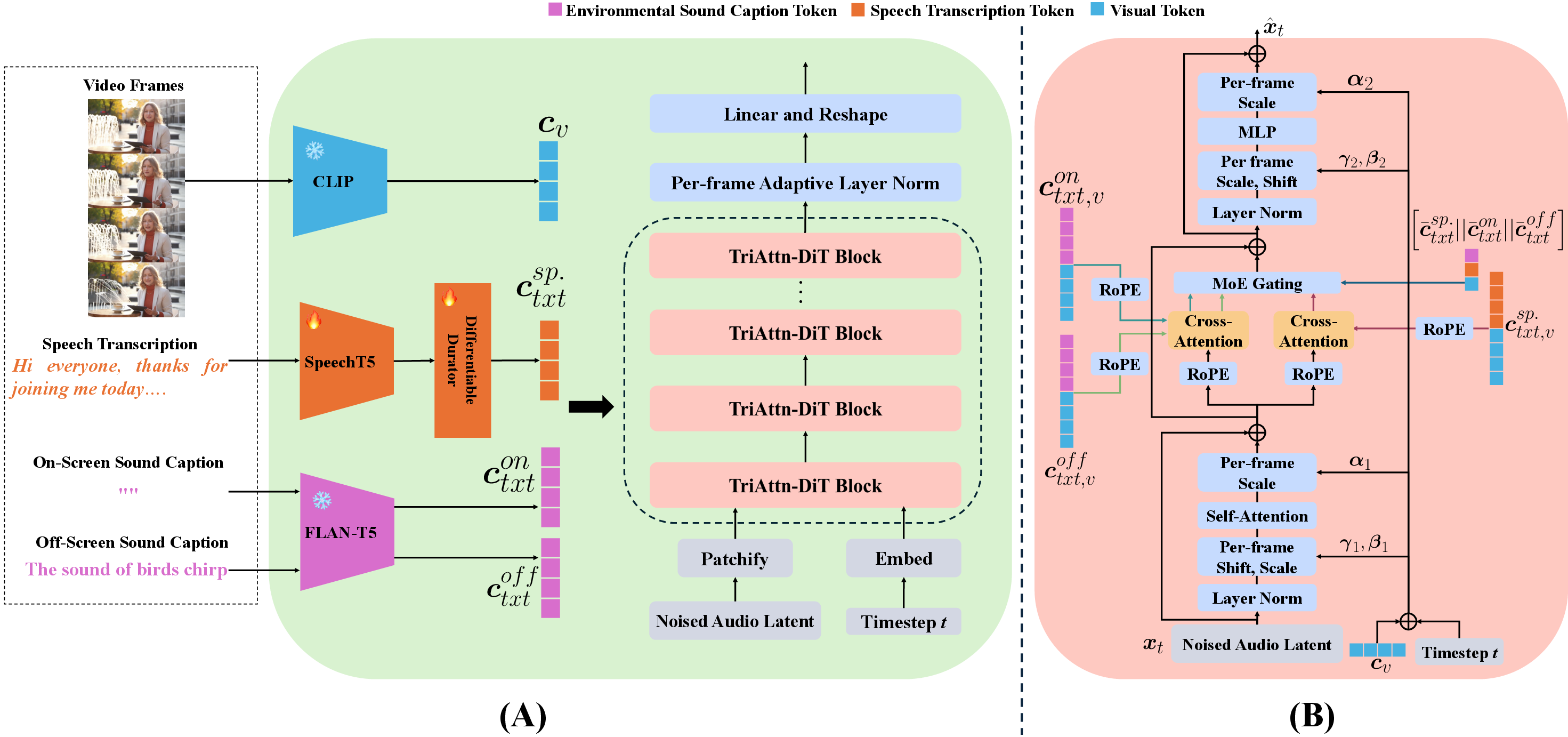
Figure 2: OmniSonic system overview and details of TriAttn-DiT block, integrating encoders and triple cross-attention with MoE-based dynamic fusion.
Key architectural innovations include:
- TriAttn-DiT Backbone: This extends prior DiT (Diffusion Transformer) models by introducing per-block triple cross-attention modules, enabling joint reasoning over on-screen, off-screen environmental captions, and speech transcriptions. Visual features are adaptively fused, ensuring robust temporal alignment between synthesized speech or events and the video.
- MoE Gating: The MoE module computes adaptive, context-driven fusion weights for each conditioning stream at every block, enforcing an optimal trade-off among the three modalities per sample and timestep. Ablation studies demonstrate catastrophic performance drops in all objective and semantic metrics without this module.
- Frame-aligned Adaptive Layer Normalization: Leveraging video context at the frame-level, this layer enhances precise synchronization between visual events and the generated audio, though it is constrained by the temporal granularity of the underlying visual encoder (CLIP).
The overall flow-matching objective is minimized in the audio latent space, where the network predicts optimal velocities transforming Gaussian noise into samples following the true data distribution.
Benchmark and Experimental Setup
Given the absence of appropriate public datasets, UniHAGen-Bench is constructed by mixing and aligning samples from VGGSound (non-speech environmental sound), LRS3 (speech video), and CommonVoice (TTS speech). Three scenarios reflecting the UniHAGen taxonomy are synthesized by mixing on/off-screen sources with random SNRs; the benchmark comprises 1,003 test samples stratified across all configurations. Careful curation and controlled condition assignment facilitates rigorous benchmarking of holistic and universal generation capacity.
Evaluation metrics span Fréchet Audio Distance (FAD) and Mean KL Divergence (MKL) for generation quality, WER/CER/PER for speech fidelity, AT/AV for semantic alignment, DeSync for temporal alignment, and four MOS subjective ratings for overall, environmental, speech, and temporal quality.
Quantitative and Qualitative Results
OmniSonic achieves dominant or SoTA results across nearly all benchmarks:
- Generation Quality: FAD (3.07), MKL (2.79) indicating distributional proximity to ground-truth well beyond prior art.
- Semantic Alignment: AT/AV mean (18.54) surpasses prior SoTA by a significant margin.
- Speech Accuracy: Consistently low WER/CER/PER, besting speech-specialized TTS models and text-video fusion systems.
- Subjective Ratings: MOS-Q: 4.35, MOS-EF: 4.42, MOS-SF: 4.74, and MOS-T: 4.29, reflecting high listener-perceived fidelity, relevance, and naturalness.
Failure modes are linked to the sole reliance on CLIP for visual features, limiting precise synchronization in static or weakly dynamic settings, as reflected in slightly inferior DeSync scores relative to Synchformer-based systems.
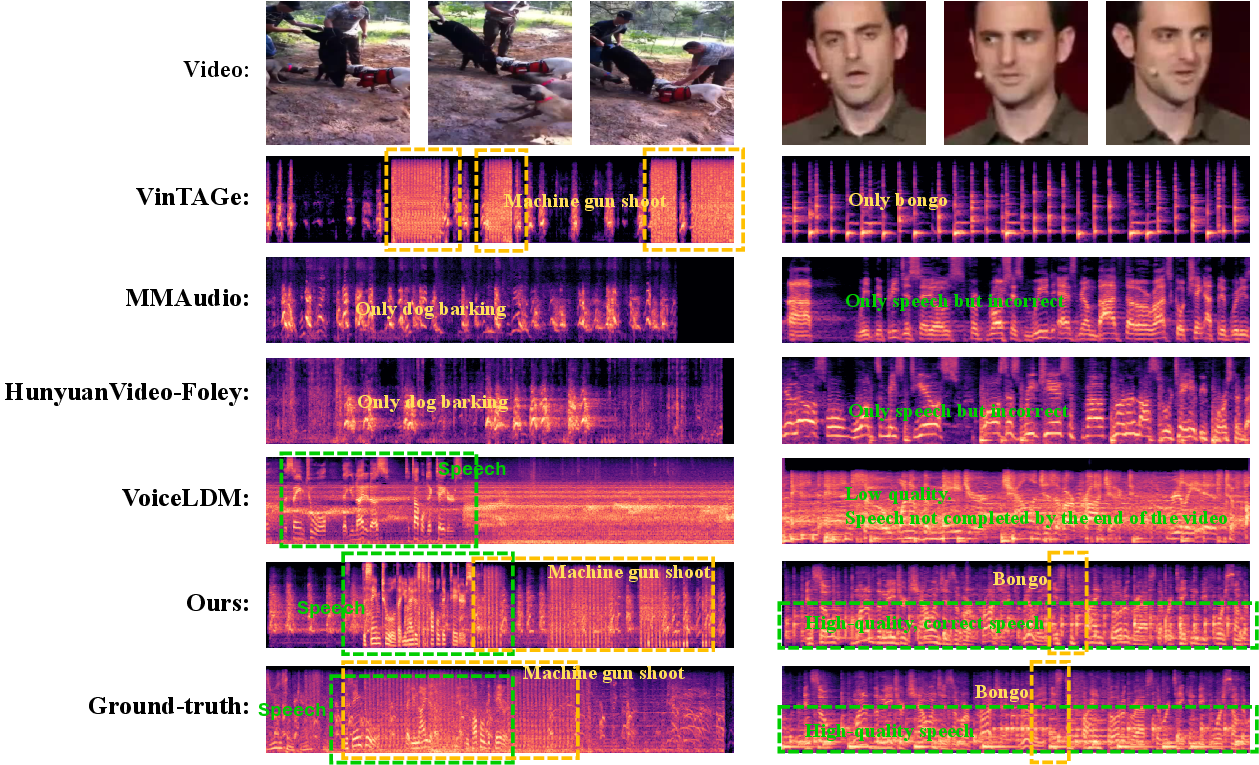
Figure 3: Spectrograms of OmniSonic outputs and ground-truth in complex multi-source scenes, showing close fidelity and accurate source separation.

Figure 4: Effect of MoE Gating ablation in real-world samples; suppression of branches leads to modality omission or degraded mix quality, confirming necessity for adaptive balancing.
Subjective and Qualitative Analysis
Detailed inspection reveals consistent failure of prior models to simultaneously handle mixed speech-environmental cases. Text-to-audio models either neglect off-screen sources or lack temporal alignment. Single-domain speech models generate intelligible speech but with noisy, unrealistic environments and poor visual grounding. OmniSonic, by contrast, is consistently able to synthesize complete, high-fidelity auditory scenes with accurate and natural blending of both on- and off-screen events, and robust cross-modal content alignment.
Implications, Limitations, and Theoretical Insights
This work signifies a substantive advance in universal multimodal coordination for generative audio models by both (1) formally specifying the UniHAGen task/benchmark, and (2) demonstrating a scalable system capable of handling previously unsolved mixed-domain and spatial configurations. Notably, the TriAttn-DiT + MoE architecture establishes a strong architectural precedent for subsequent research in multimodal fusion, highlighting the significance of dynamic conditional weighting.
Practically, these results foreshadow applicability in automated foley, video restoration for legacy content, immersive XR experiences, and multimodal embodied agents requiring nuanced auditory scene construction.
Limitations include the synthetic nature of training samples (potentially lacking organic cross-modal correlations present in true wild data), and the current visual encoder's temporal expressivity. Future work should address collection or simulation of in-the-wild corpora and development of temporally attentive visual encoders, as well as multi-lingual and domain transfer generalization.
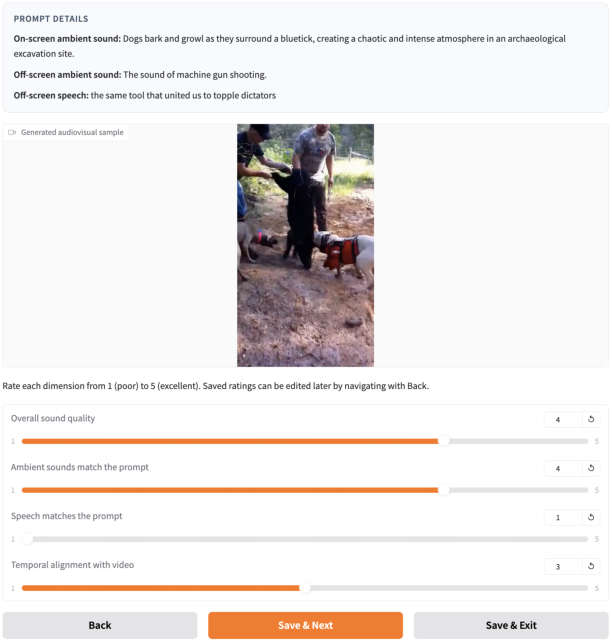
Figure 5: Subjective evaluation interface for human rating, critical for robust perceptual assessment and model validation.
Conclusion
OmniSonic, as introduced for the UniHAGen task, delivers state-of-the-art results for universal holistic audio generation from video and text, enabled by a flow-matching diffusion backbone, triple cross-attention, and adaptive MoE gating. Ablative and comparative analyses verify each architectural decision and demonstrate substantial improvements over specialized and holistic-only baselines. This framework defines a robust technical foundation and benchmark for subsequent advances in holistic, multimodal audio synthesis.