- The paper introduces VinTAGe, a novel framework that integrates video and text inputs to generate audio with high semantic and temporal fidelity.
- The methodology employs a dual-encoder and VT-SiT model, effectively using motion cues and pre-trained T2A/V2A models to minimize modality bias.
- Experimental results on benchmarks like VGGSound demonstrate that VinTAGe outperforms existing methods in audio quality, faithfulness, and alignment.
A Technical Overview of VinTAGe: Joint Video and Text Conditioning for Holistic Audio Generation
Introduction
The paper "VinTAGe: Joint Video and Text Conditioning for Holistic Audio Generation" (2412.10768) addresses the challenge of generating semantically rich and temporally synchronized audio that captures both onscreen and offscreen sound elements from video and text prompts. While previous methods in text-to-audio (T2A) and video-to-audio (V2A) generation each have limitations—T2A methods lack visual alignment and V2A methods cannot capture offscreen sounds—this work proposes a comprehensive approach through the VinTAGe model.
VinTAGe leverages a flow-based transformer architecture that balances audio generation through text and video inputs while minimizing modality bias. This design overcomes the limitations of previous models which favored either text or video too heavily.
Methodology
VinTAGe's architecture centers around two principal components: the Visual-Text Encoder and the Joint VT-SiT model. The Visual-Text Encoder is responsible for encoding video and text embeddings and facilitating their cross-modal interactions. Specifically, it integrates motion and frame index information to provide temporal guidance for audio generation. On the other hand, the VT-SiT model generates audio by leveraging these contextual embeddings through an enhanced flow matching approach, ensuring high-quality temporal and semantic alignment with the input data.
Key innovations include the use of pre-trained unimodal T2A and V2A models as teachers, guiding the VT-SiT model to reduce modality bias and improve generation quality. VinTAGe, therefore, effectively harmonizes text and video modalities, as well as onscreen and offscreen audio elements.
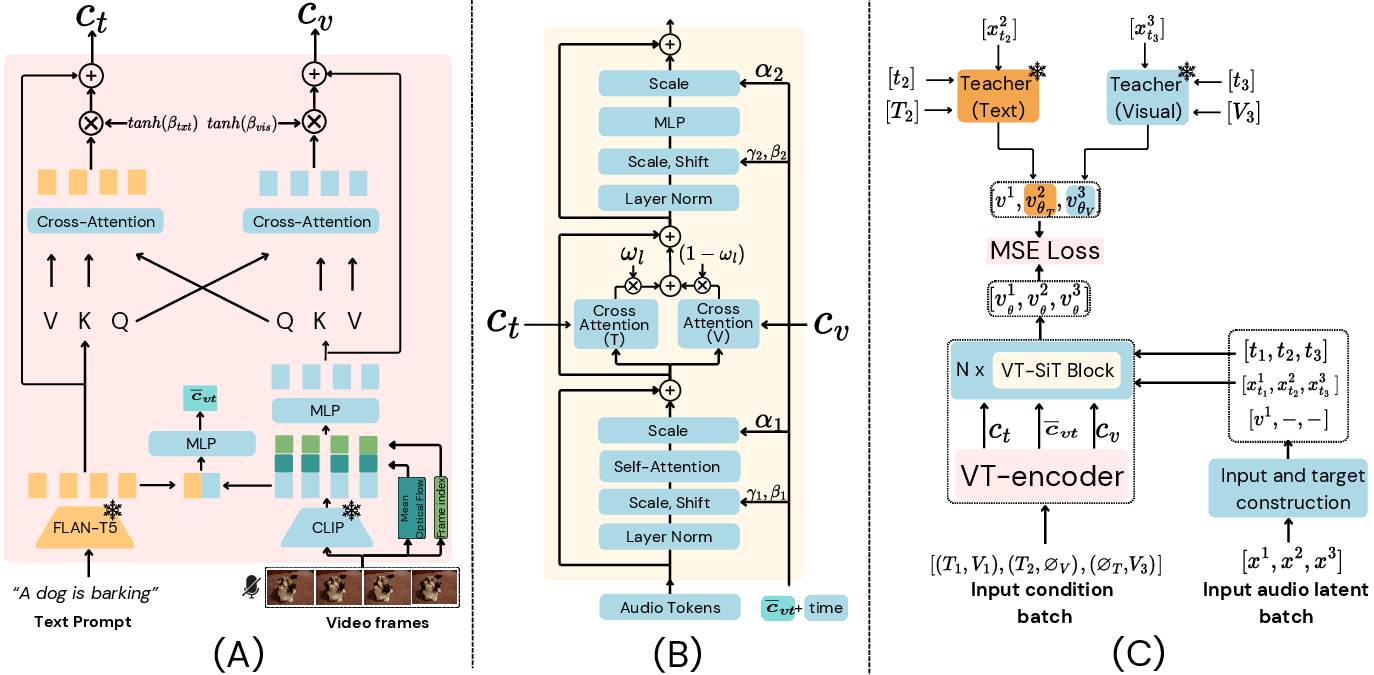
Figure 1: (A) VT-Encoder, (B) Joint VT-SiT block, (C) Overall training pipeline.
The methodology section also introduces VinTAGe-Bench, a new dataset developed to evaluate the model's ability to handle the complexities of joint video-text to audio generation tasks. This dataset fills a critical gap, enabling robust testing of models across diverse scenarios involving both onscreen and offscreen sounds.
Experimental Results
VinTAGe achieves state-of-the-art results on multiple benchmarks, including the standard VGGSound dataset, demonstrating its effectiveness in producing high-quality, semantically rich audio aligned with both visual and textual inputs. The model outperforms existing methods in terms of metrics such as Frechet Audio Distance (FAD) and Melception-based Frechet Distance (FID), as well as subjective measures of audio quality, faithfulness, and alignment.
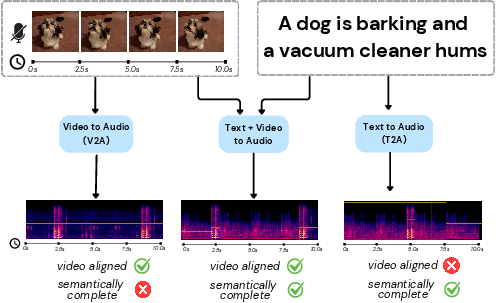
Figure 2: Our VinTAGe model can generate visually aligned and text-corresponding sounds, including both onscreen and offscreen sound sources, providing a more holistic audio experience.
The ablation studies further highlight the importance of each component of the VinTAGe architecture, including cross-modality attention and the integration of optical flow for temporal alignment. As shown in these studies, the inclusion of these components is crucial for achieving the best results.
Implications and Future Work
VinTAGe's ability to integrate text and video inputs for audio generation opens up new avenues in audiovisual media production, particularly in applications demanding intricate soundscapes such as films, animations, and virtual reality environments. The successful deployment of VinTAGe demonstrates the potential of transformer-based architectures in balancing complex multimodal tasks.
Future research could explore additional enhancements to the model, including automated methods for onscreen sound separation and improved metrics for temporal alignment evaluation. Such advancements would support even more sophisticated audio synthesis systems capable of operating in richer and more varied audiovisual contexts.
Conclusion
In conclusion, the VinTAGe framework represents a significant step forward in holistic audio generation, moving towards a more integrated multimodal approach that addresses previous limitations of T2A and V2A methods. With its robust architecture and promising results, VinTAGe sets a strong foundation for future developments in the field of audio synthesis, highlighting the growing importance of finely tuned transformer models in understanding and generating complex audio-visual interactions.