- The paper introduces a tri-phasic architecture that combines intelligent triage, diverse expert generation, and structured consensus synthesis to significantly mitigate hallucination and bias.
- It achieves a 35.9% reduction in hallucination, a 7.8-point improvement in TruthfulQA scores, and an 85–89% decrease in bias variance compared to individual models.
- The architecture provides a scalable and robust framework for trustworthy LLM deployment, maintaining high factual accuracy in complex reasoning tasks despite a moderate latency trade-off.
Council Mode: Multi-Agent Consensus for Hallucination and Bias Mitigation in LLMs
Motivation and Problem Statement
The proliferation of Mixture-of-Experts (MoE) LLMs such as GPT-5.4, Claude Opus 4.6, and Gemini 3.1 Pro, has underscored two principal limitations: hallucination and systematic bias. Hallucination, manifesting as factually incorrect yet plausible outputs, and bias, emerging through uneven expert activation, are exacerbated in MoE paradigms via sparse routing and expert collapse. Prior mitigation relies on single-model paradigms such as Retrieval-Augmented Generation (RAG) and Reinforcement Learning from Human Feedback (RLHF), inherently restricted in epistemic diversity and prone to individual failure modes. Recent literature demonstrates the efficacy of multi-agent debate and consensus, yet extant implementations often lack architectural diversity and fail to employ semantically rich synthesis protocols.
Council Mode Architecture
Council Mode introduces a tri-phasic pipeline harnessing architectural diversity and structured consensus synthesis.
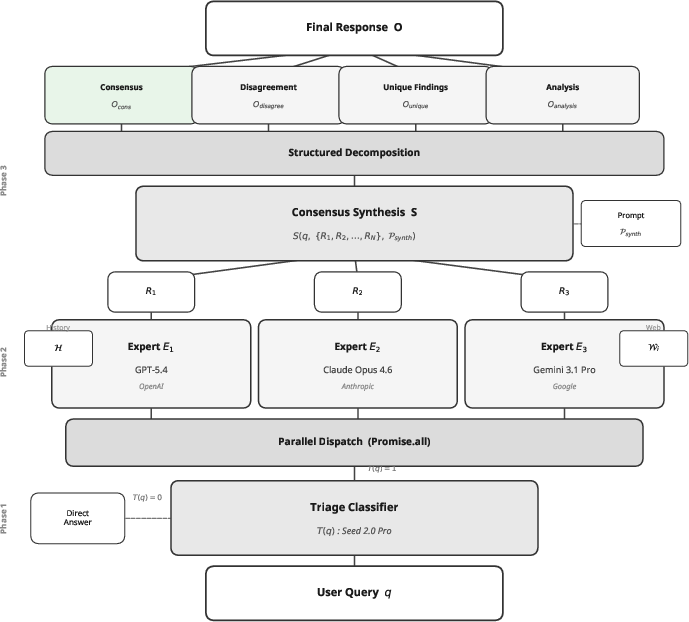
Figure 1: The Council Mode architecture utilizes triage, parallel expert generation, and structured consensus synthesis to systematically mitigate hallucination and bias.
Phase 1: Intelligent Triage employs a lightweight classifier (Seed 2.0 Pro) that screens for query complexity, minimizing computational overhead by bypassing trivial prompts.
Phase 2: Parallel Expert Generation dispatches nontrivial queries to three architecturally diverse expert models (GPT-5.4, Claude Opus 4.6, Gemini 3.1 Pro), each possessing unique parametric and training foundations.
Phase 3: Consensus Synthesis aggregates expert outputs using an overview model via a four-section protocol: consensus points (claims supported by all experts), disagreements (conflicting claims with reasoning), unique findings (claims from a single expert), and a comprehensive analysis integrating all evidence. The synthesis prompt enforces strict structural and evidentiary constraints.
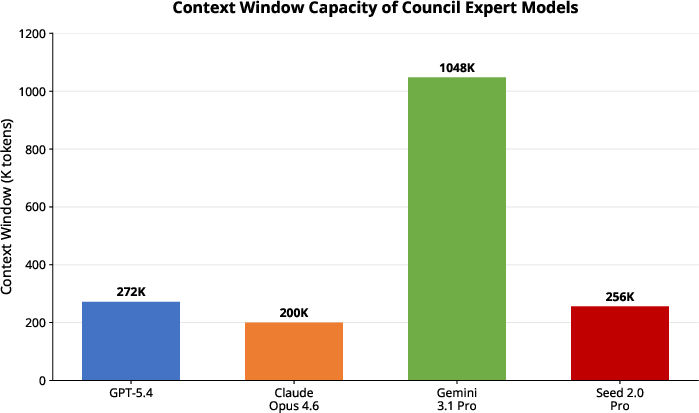
Figure 2: Significant contextual window heterogeneity allows complementary information retrieval and cognitive diversity among Council models and baselines.
Theoretical Foundation
Assuming independence among heterogeneous experts, the likelihood of unanimous hallucination is multiplicatively reduced even if individual rates are nontrivial. Empirical rates (p1=0.18, p2=0.16, p3=0.19) indicate that Council Mode decreases same-claim hallucination by approximately 97.1\% relative to the worst expert. Structured synthesis further enables semantic cross-verification, minimizing propagation of model-specific errors and domain-specific biases.
Council Mode was benchmarked against five individual models (using unified API-based scripts) across HaluEval, TruthfulQA, and a custom multi-domain reasoning suite. Metrics include hallucination rate, Truthful score, Informative score, accuracy, and cross-domain bias variance.
Hallucination Reduction: Council Mode achieves a 35.9% relative reduction in average hallucination rate (10.7% vs.\ 16.7% for Claude Opus 4.6), with gains most pronounced in summarization.
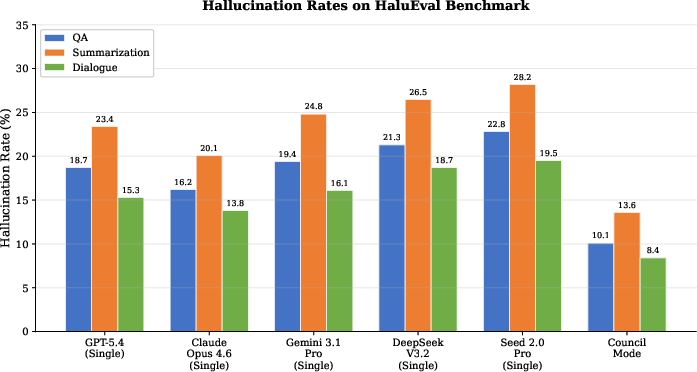
Figure 3: Hallucination rates (%) on HaluEval tasks, demonstrating Council Mode's dominant performance across QA, summarization, and dialogue.
TruthfulQA: Council Mode outperforms all baselines, scoring 82.6% (Truthful) and 91.3% (Informative), a 7.8-point increase over the best individual expert.
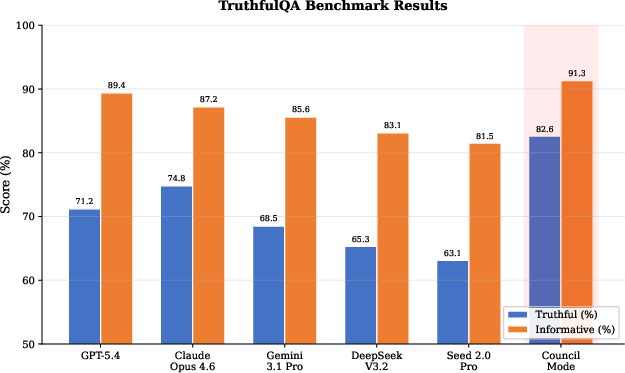
Figure 4: TruthfulQA evaluation reveals Council Mode's elevated Truthful and Informative ratings compared to state-of-the-art models.
Bias Mitigation: Factual consistency and neutrality scatter plots reveal substantially diminished variance (σ2=0.003) for Council Mode versus individual models (σ2=0.021--$0.028$), indicating robust bias mitigation.
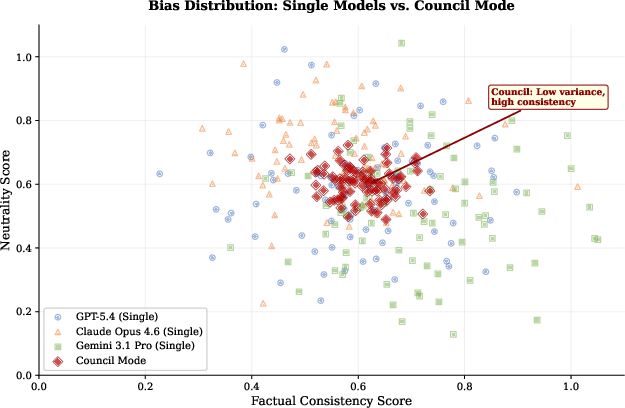
Figure 5: Council Mode outputs cluster tightly with high consistency and neutrality, evidencing superior bias mitigation.
Domain-Specific Hallucination: Across six domains, Council Mode exhibits consistently lower hallucination rates, most notably in Law and History where individual models produce elevated error rates.
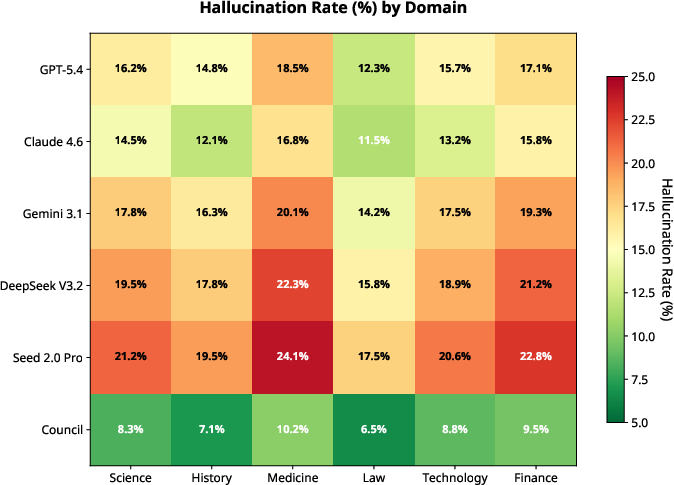
Figure 6: Heatmap showing domain-specific hallucination rates; Council Mode's row highlights across-the-board gains, especially in error-prone domains.
Complexity Scaling: Council Mode sustains higher accuracy as reasoning complexity increases, maintaining a substantial advantage at 10-step tasks (71.2% vs. 50.8--43.5% for baselines).
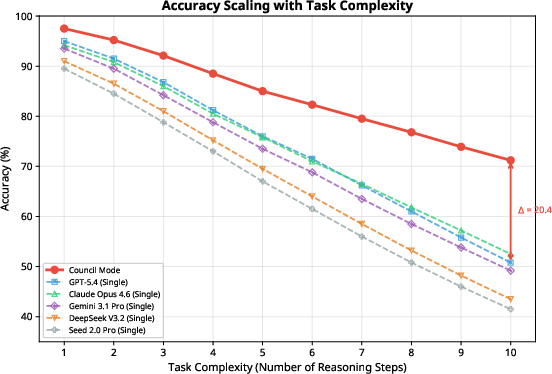
Figure 7: Task complexity scaling; Council Mode demonstrates graceful accuracy degradation while individual models falter.
Latency vs Quality: While Council Mode incurs increased latency (8.4s average), its superior quality score (91.7%) renders the latency trade-off favorable for accuracy-critical applications.
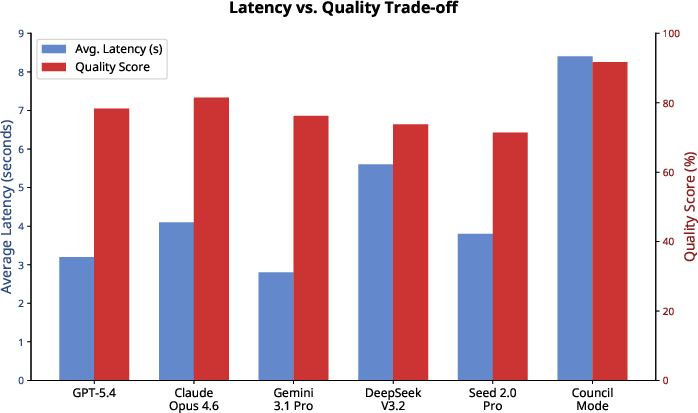
Figure 8: Latency-quality trade-off illustrates Council Mode's Pareto dominance in accuracy despite moderate latency increase.
Ablation and Design Insights
Ablation studies confirm:
- Triaging reduces latency without sacrificing quality.
- Structured synthesis is indispensable for hallucination reduction; na{\"i}ve majority voting increases error by 32.7%.
- Expert diversity is critical; same-model ensembles yield only modest improvement.
- Three-expert configuration achieves optimal balance between computational cost and epistemic coverage.
Implications and Future Perspectives
Council Mode delivers robust mitigation of hallucination and bias via architectural heterogeneity and structured cross-verification. By leveraging cognitive diversity and precise synthesis prompts, Council Mode achieves compelling factuality and neutrality advantages, especially in complex reasoning and domain-sensitive tasks. This paradigm offers a scalable pathway for composite LLM orchestration, complementing ongoing advancements in alignment and retrieval augmentation. Future directions may involve adaptive expert selection, dynamic synthesis strategies, and deeper integration of external retrieval mechanisms to further reduce residual consensus hallucinations.
Conclusion
Council Mode represents an effective multi-agent consensus architecture that outperforms individual MoE LLMs on hallucination, bias, and factual reasoning metrics. Empirical evidence substantiates significant gains (35.9% hallucination reduction, 7.8-point TruthfulQA improvement, 85--89% reduction in bias variance) across established benchmarks. The architecture’s structured synthesis and diversity-driven expert aggregation establish a robust foundation for trustworthy LLM deployment, and its open-source implementation facilitates further research in multi-agent LLM orchestration and interpretability.