Internalizing Self-Consistency in Language Models: Multi-Agent Consensus Alignment
Abstract: LLMs (LMs) are inconsistent reasoners, often generating contradictory responses to identical prompts. While inference-time methods can mitigate these inconsistencies, they fail to address the core problem: LMs struggle to reliably select reasoning pathways leading to consistent outcomes under exploratory sampling. To address this, we formalize self-consistency as an intrinsic property of well-aligned reasoning models and introduce Multi-Agent Consensus Alignment (MACA), a reinforcement learning framework that post-trains models to favor reasoning trajectories aligned with their internal consensus using majority/minority outcomes from multi-agent debate. These trajectories emerge from deliberative exchanges where agents ground reasoning in peer arguments, not just aggregation of independent attempts, creating richer consensus signals than single-round majority voting. MACA enables agents to teach themselves to be more decisive and concise, and better leverage peer insights in multi-agent settings without external supervision, driving substantial improvements across self-consistency (+27.6% on GSM8K), single-agent reasoning (+23.7% on MATH), sampling-based inference (+22.4% Pass@20 on MATH), and multi-agent ensemble decision-making (+42.7% on MathQA). These findings, coupled with strong generalization to unseen benchmarks (+16.3% on GPQA, +11.6% on CommonsenseQA), demonstrate robust self-alignment that more reliably unlocks latent reasoning potential of LLMs.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
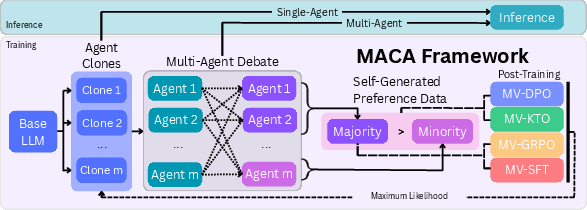
This paper is about teaching AI LLMs to be more “self-consistent.” That means getting them to give the same, reliable answer even when they explore different ways of thinking through a problem. The authors propose a training method called MACA (Multi-Agent Consensus Alignment) that makes several copies of the same model “debate” a question, agree on an answer, and then learn from the patterns that led to that agreement.
What questions did the researchers ask?
The researchers focused on a simple idea: a smart reasoner should explore different ideas but still end up with a stable, high-quality answer. They asked:
- How can we help a model explore multiple possible reasoning paths while still settling on a strong, consistent conclusion?
- Can a model learn better from its own debates than from just picking the most common answer once?
- Do improvements in self-consistency also make the model more accurate and better at working with other models?
- If we train for consistency on math, does that skill carry over to other areas like science and commonsense?
How did they do it?
Think of a small team of identical students tackling the same problem, each writing their own solution, then reading each other’s work, discussing, and updating their answers. That’s the core idea behind MACA.
The “classroom debate” setup
- Multiple copies (“agents”) of the same LLM solve a question independently.
- They share their reasoning with each other and have one more round to revise their answers.
- The group’s majority answer is treated as the “consensus.”
Learning from consensus (not just the final answer)
Instead of only rewarding the final answer, the model learns from the whole reasoning process:
- The reasoning paths that agree with the final majority are labeled “preferred.”
- The reasoning paths that disagree with the majority are labeled “not preferred.”
- The model is then trained to prefer the kinds of reasoning that led to consensus.
In everyday terms: the model practices by comparing “better” and “worse” solution write-ups and learns which patterns to trust.
How the training works (in simple terms)
The paper compares several training styles:
- Imitation (SFT): “Copy the majority’s reasoning traces.”
- Reward-based practice (GRPO): “Get a point if your answer matches the group’s consensus.”
- Comparison-based learning (DPO and KTO): “When we compare two write-ups, push the model to prefer the consensus one.” This uses side-by-side comparisons, which often teach more than simple points.
How they measured self-consistency
They used two easy-to-grasp checks:
- Single model, many tries: Ask the same model the same question multiple times (with a “randomness knob” turned on). How often do the answers match the most common one? More agreement = more self-consistency.
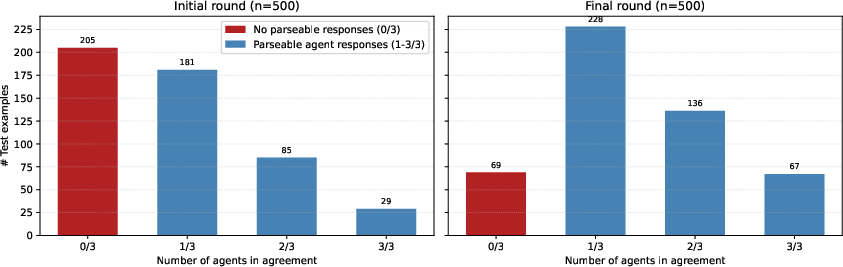
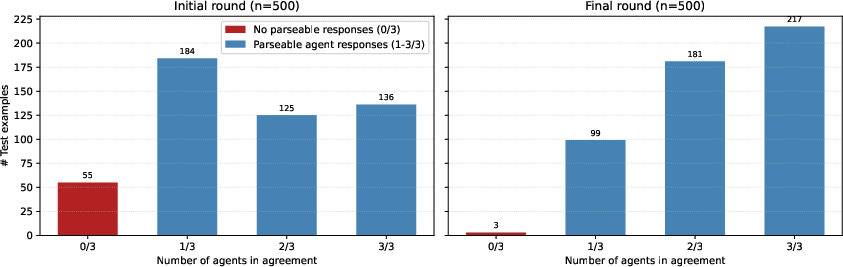
- Many models debating: After debate, how many agents end up agreeing on the final answer? More agreement = stronger consensus.
What did they find, and why does it matter?
Here are the key takeaways, summarized in plain language:
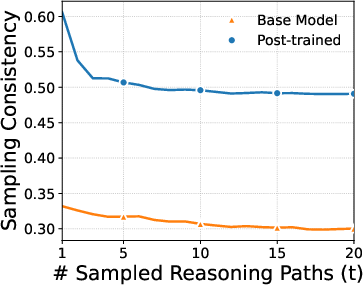
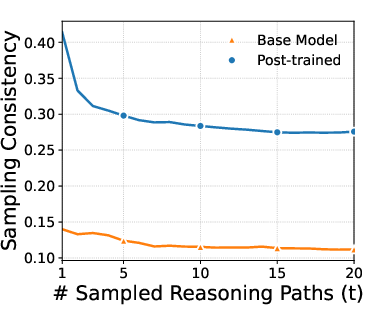
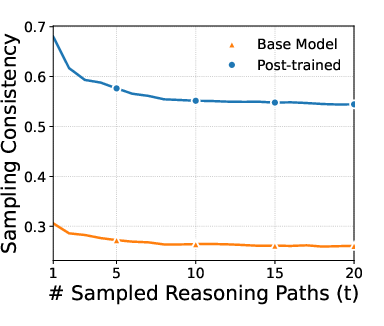
- Models became much more consistent without turning off creativity. After training, models were more likely to give the same correct answer even when sampling different chains of thought. The paper reports big jumps in consistency (up to about +27.6% on a grade-school math set).
- Accuracy went up too. The models didn’t just agree more—they were also more often right. Single-model accuracy improved a lot on tough math (e.g., around +23.7% on a hard math benchmark), and sampling multiple tries helped even more (Pass@20 improved by about +22.4%).
- Teamwork improved. When multiple copies debated, they reached strong consensus more often and got better results together (up to about +42.7% improvement on a math word-problem set).
- Learning from comparisons worked best. Training that compares “preferred vs. not preferred” reasoning paths (DPO/KTO) generally beat simple imitation or one-number rewards.
- Debate context mattered. Letting models read and respond to each other’s reasoning during training taught them to use peer arguments well—spotting mistakes, adjusting their thinking, and converging more reliably.
- Self-made labels were surprisingly good. Using the group’s majority answer (from debate) as a training signal worked about as well as using ground-truth labels. That’s helpful because it means the model can improve itself without needing lots of human-graded data.
- Consistency and accuracy went hand in hand. When self-consistency increased, accuracy did too. That’s a good sign that consistency is a useful target to train for.
- It generalizes beyond math. Training for self-consistency on math also helped with science and commonsense questions (improvements around +11% on some benchmarks). So, consistency looks like a core reasoning skill that transfers.
Why is this important? What could it change?
This research suggests a practical way to make AI reasoning more trustworthy and efficient:
- More reliable answers with less extra compute: Instead of always needing to sample many answers and vote at inference time, the model learns to be consistent internally. That saves time and cost.
- Better teamwork among models: Debate becomes more productive because models learn to ground their arguments in each other’s reasoning, not just repeat errors louder.
- Stronger general reasoning: Training for self-consistency on math boosted performance on science and commonsense tasks too, hinting that “being consistent” is a foundational thinking skill.
- Less dependence on human labels: Because the model learns from its own debates, it can self-improve in areas where labeled data is scarce.
The authors also note some limits: the base model needs to be good enough to have meaningful debates; majority opinions can still carry bias; and the method doesn’t directly check every step of reasoning for correctness. Future work could weigh confidence in votes, mix different kinds of agents, or learn more from insightful minority opinions.
In short, MACA shows how AI can use its own internal debates to become a steadier, smarter reasoner—more like a good student who tries different approaches yet knows how to tell which arguments truly make sense.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of what remains missing, uncertain, or unexplored, structured to guide future research.
- Theoretical guarantees: Formal conditions under which increasing self-consistency provably improves truthfulness/accuracy, especially with correlated errors among trajectories and agents (beyond Condorcet-style intuitions).
- Correlated error analysis: When do debate-driven majorities converge to confidently wrong answers, and how can aggregation be made robust to shared biases or herding?
- Minority-signal utilization: Systematic methods to identify “valuable dissent” (e.g., high-quality minority trajectories) and incorporate them without overwhelming the consensus objective.
- Argument-quality scoring: Designing and validating confidence- or evidence-weighted voting schemes (e.g., calibration-aware logit-based weights, citation/verification counts) rather than unweighted majority.
- Adversarial robustness: Behavior under adversarial or collusive peers, prompt attacks, or crafted deceptive arguments; defenses against agreement-on-error and back-scratching failure modes.
- Safety and bias: Whether self-supervised majority reinforcement amplifies societal or dataset biases; comprehensive fairness and toxicity evaluations across sensitive attributes and tasks.
- Hallucination and factuality: Impact on open-domain factuality and hallucination rates beyond math/QA benchmarks; interaction with retrieval or fact-checkers.
- Semantic vs sampling consistency: Whether gains in sampling consistency transfer to semantic consistency (paraphrase invariance) and how to jointly optimize both.
- Long-horizon reasoning: Performance on long proofs, multi-turn planning, program synthesis/debugging, and tasks requiring extended chains-of-thought beyond the 256-token main setting.
- Non-verifiable outputs: Generalization to tasks without ground truth or with subjective answers; metrics and training signals for consensus quality in such settings.
- Debate protocol design: Sensitivity to prompts, turn-taking rules, roles (e.g., proposer/critic/judge), and critique scaffolds; principled ways to design and learn protocols.
- Hyperparameter sensitivity: Systematic scaling studies over number of agents (M), rounds (R), sampling temperature, sample count t, and pair construction strategies on accuracy/consistency/diversity trade-offs.
- Diversity vs collapse: Does reinforcing consensus reduce exploration and solution diversity over time (mode collapse)? Metrics and mechanisms to preserve beneficial diversity.
- Calibration: Relationship between and well-calibrated confidence; ECE/Brier analyses and calibration-improving interventions during consensus alignment.
- Unanimity vs weak majorities: How to treat ties and narrow majorities during training; effects of preferring unanimity-only signals vs accepting weaker agreement.
- Iterative training stability: Convergence properties of repeated MACA cycles, risks of self-reinforcing errors/drift, and criteria to stop or reset.
- Noisy-preference robustness: Robust DPO/KTO variants for noisy DMV labels (e.g., noise-aware objectives, mentor correction, co-teaching) and their effect on stability.
- DMV vs ground truth divergence: Methods to detect when debate-majority labels disagree with truth and to correct for such cases during training (e.g., verifier gating).
- Peer heterogeneity: Effects of heterogeneous ensembles (different architectures, sizes, pretraining corpora) vs homogeneous clones on consensus quality and transfer.
- Integration with external tools: Combining consensus signals with verifiers, program executors, retrieval, and formal checkers; how MACA interacts with tool-augmented reasoning.
- Scaling to larger models: Applicability, compute/efficiency trade-offs, and emergent behaviors on frontier-scale LMs with longer context windows and tool use.
- Compute and sustainability: End-to-end cost/benefit analysis (debate generation, preference training, inference), energy/carbon footprint, and optimization of sample efficiency.
- Data scale and generalization: Results trained on small per-task splits (≈1.5k/0.5k) need validation at larger scale with stronger OOD and real-world datasets.
- Cross-lingual/multimodal: Transfer to non-English, code-mixed text, and multimodal reasoning; effects of debate on cross-lingual consistency and alignment.
- Mid-generation internalization: Direct probes and token-level analyses to verify claimed mid-generation bias toward consensus (e.g., early-logit alignment, interruption tests).
- Temperature policies: Train–test temperature mismatch, annealing schedules, and adaptive sampling policies that balance exploration and consistency.
- Debate stopping and adaptivity: Learning adaptive round counts (R), early-stopping criteria, and dynamic agent activation conditioned on disagreement/confidence.
- Minority-informed curriculum: Curriculum strategies that modulate the weight of dissent signals across training to reduce premature convergence and improve robustness.
- Explainability: Interpretable diagnostics of how consensus patterns are encoded (e.g., probing, circuit analysis) and how they influence token-level decisions.
- Privacy and CoT exposure: Risks of training on and possibly emitting chain-of-thought; approaches to retain gains while suppressing CoT at inference or using latent CoT.
- Evaluation breadth: Beyond MV@t and Pass@t, include human/Arena evaluations, reliability under non-determinism, and significance tests across more seeds.
- Estimating efficiently: Better estimators than brute-force sampling, variance-reduction techniques, and confidence intervals for consistency metrics.
- Comparison breadth: Benchmarks against alternative internalization strategies (self-reflection, latent-thought training, self-rewarding LMs, process supervision) under matched compute.
- Protocol for minority learning: Concrete algorithms to surface and refine dissent (e.g., counterexample harvesting, error chains, adversarial rounds) without degrading consensus stability.
- Real-world deployment: Behavior under product constraints (latency budgets, streaming inputs, interruption), failure recovery, and safe fallback mechanisms.
Glossary
- Anterior cingulate cortex (ACC): A brain region implicated in conflict monitoring and resolution during decision-making and reasoning. "this consistency emerges from the prefrontal and anterior cingulate cortices, which resolve conflicts between competing neural activations"
- Chain-of-thought (CoT): The explicit, step-by-step reasoning process or narrative a model generates to reach an answer. "exploring multiple valid reasoning paths like different theorem proofs or alternative chains of thought"
- Consensus alignment: Training that encourages models to prefer reasoning trajectories that converge to shared conclusions across agents or samples. "addressing consensus alignment through preference learning yields substantial improvements over scalar-reward RL and imitation learning"
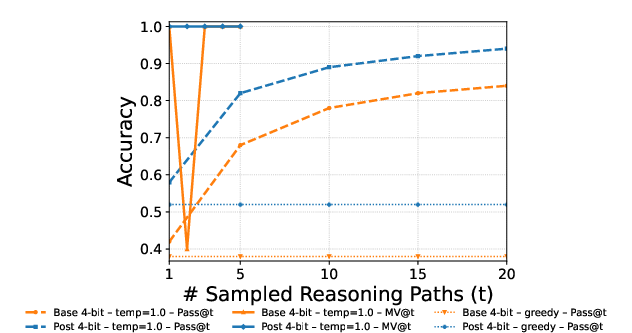
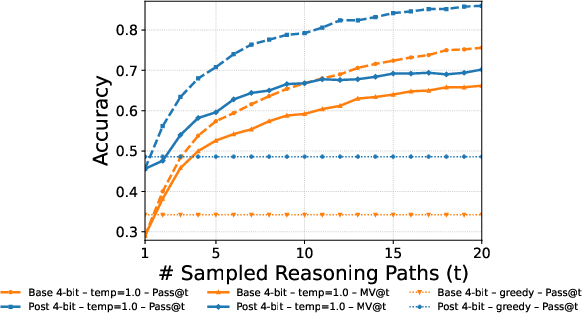
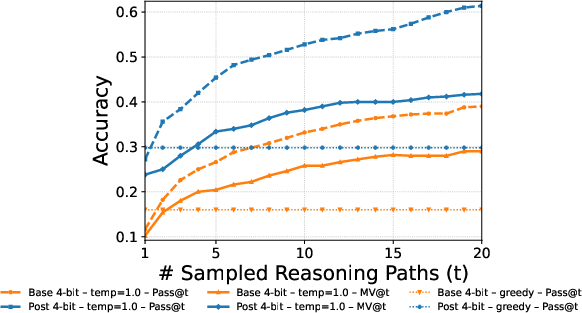
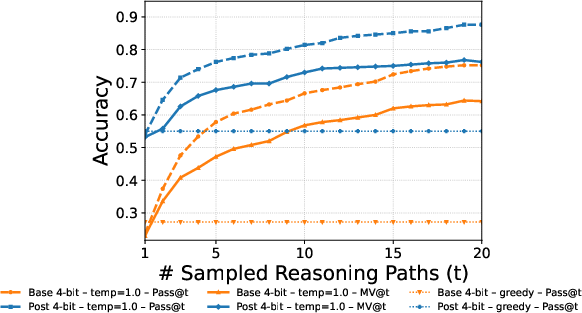
- Debate majority vote (DMV): The consensus label derived from the final round of multi-agent debate, used as a training signal. "Post-training with debate majority vote (DMV) is comparable to ground-truth (GT)."
- Direct Preference Optimization (DPO): A preference-learning objective that increases the log-probability of preferred responses relative to dispreferred ones. "We optimize the separation between majority and minority trajectories using majority vote variants of DPO and KTO, outperforming GRPO and SFT."
- Greedy decoding: Deterministic generation by always selecting the highest-probability token at each step. "While greedy decoding () trivially approaches perfect consistency, it eliminates exploration and often produces suboptimal solutions"
- Group Relative Policy Optimization (GRPO): A reinforcement learning method that normalizes advantages within groups to stabilize updates. "Majority-Vote GRPO (MV-GRPO) uses online sampling with consensus-based rewards."
- Group-normalized advantage: An advantage term centered by a group mean to improve learning stability in policy optimization. "where is the group-normalized advantage."
- Inductive bias: The model’s predisposition to favor certain solution patterns or structures during learning and generation. "develop an inductive bias toward consensus-forming trajectories even mid-generation"
- KTO: An unpaired preference-learning objective that uses logistic scoring of log-probability ratios for positive and negative examples. "Majority-Vote KTO (MV-KTO) applies KTO's unpaired formulation with debate-derived labels"
- KL divergence: A measure of dissimilarity between two probability distributions, often used as a regularization term. "+ $\lambda \, \text{KL}(\pi_\theta \| \pi_{\text{ref})$"
- Majority consensus: The answer agreed upon by the majority of agents or samples after deliberation. "The majority consensus partitions into consensus-supporting and dissenting trajectories."
- Majority-Vote DPO (MV-DPO): A DPO variant trained on pairs from debate that contrast majority (preferred) and minority (not preferred) trajectories. "Majority-Vote DPO (MV-DPO) follows the standard DPO formulation with preference pairs constructed from our pre-generated debate outcomes"
- Majority-Vote GRPO (MV-GRPO): A GRPO variant that assigns rewards based on agreement with the debate majority answer. "Majority-Vote GRPO (MV-GRPO) uses online sampling with consensus-based rewards."
- Majority-Vote KTO (MV-KTO): A KTO variant using unpaired debate-derived labels to separate majority and minority trajectories. "Majority-Vote KTO (MV-KTO) applies KTO's unpaired formulation with debate-derived labels"
- Majority-Vote SFT (MV-SFT): Supervised fine-tuning that imitates consensus-supporting (majority) trajectories from debate. "Majority-Vote SFT (MV-SFT) trains the model to mimic consensus-supporting trajectories:"
- Modal probability: The total probability mass assigned to the most likely answer under the model’s sampling distribution. "we track the sampling consistency where converges to the modal probability as "
- Multi-agent debate: A procedure where multiple copies of a model iteratively share and refine reasoning before forming a consensus. "In multi-agent debate, copies of the same model engage in iterative discussion"
- Multi-Agent Consensus Alignment (MACA): A self-supervised RL framework that trains models using consensus signals emerging from multi-agent debate. "introduce Multi-Agent Consensus Alignment (MACA), a reinforcement learning (RL) framework where multiple LM clones collaborate to solve problems through iterative debate"
- MV@t: Accuracy of majority vote computed over t sampled trajectories for a prompt. "MV@t (majority over samples)"
- Pass@t: The fraction of prompts for which at least one of the first t sampled trajectories is correct. "Pass@t (oracle upper bound)"
- Peer context: The inclusion of other agents’ reasoning traces during training or inference to improve grounding and consensus. "Conditioning on peer context improves both collective and individual reasoning."
- Preference leakage: Bias introduced when a judging model’s preferences inadvertently influence or leak into training signals. "LLM-as-a-Judge approaches suffer from preference leakage and bias under ambiguity"
- Preference learning: Training methods that learn from relative comparisons between preferred and non-preferred outputs. "self-guided preference learning (MV-DPO and MV-KTO) outperforms scalar rewards via MV-GRPO"
- QLoRA: A parameter-efficient fine-tuning technique that uses low-bit quantization and adapters for training large models. "We use 4-bit quantization with QLoRA and limit responses to 256 tokens"
- Quantization (4-bit): Reducing numerical precision of model parameters to 4 bits to lower memory and computation requirements. "We use 4-bit quantization with QLoRA and limit responses to 256 tokens"
- Scalar-reward RL: Reinforcement learning that optimizes policies using a single scalar reward per trajectory. "preference learning yields substantial improvements over scalar-reward RL and imitation learning"
- Self-consistency: The property of producing stable outputs across diverse sampled reasoning paths. "A fundamental trait of a reliable reasoning model is self-consistency: the intrinsic ability to produce stable outputs across various sampled reasoning paths"
- Self-consistency prompting: An inference-time technique that samples multiple reasoning paths and selects the majority-voted answer. "Self-consistency prompting~\citep{Wang2022, li2024self} samples multiple reasoning paths and selects the majority-voted answer"
- Semantic consistency: Invariance of a model’s outputs under paraphrasing or semantically equivalent reformulations. "our focus on sampling consistency, i.e., agreement across stochastic generations, differs from semantic consistency, which requires invariance under paraphrasing"
- Supervised fine-tuning (SFT): Training that directly imitates target responses using labeled data. "Building on~\citet{subramaniam2025multiagent}'s use of supervised fine-tuning for multi-agent debate optimization, we demonstrate that RL-based alternatives achieve superior performance."
- Temperature sampling: Adjusting token probabilities by a temperature parameter to control diversity during generation. "Under temperature sampling, the model samples from a modified distribution where token probabilities are adjusted by temperature "
Collections
Sign up for free to add this paper to one or more collections.

