- The paper's main contribution is introducing LRSA, a Transformer-based low-rank spatial attention block that compresses and reconstructs global point interactions to boost PDE simulation accuracy.
- It harnesses a unified compress-process-reconstruct template to decouple latent feature processing, enabling efficient and robust modeling across diverse discretizations.
- Experiments show >17% error reduction and improved zero-shot generalization across benchmarks, proving LRSA's superiority over prior neural operator designs.
Introduction and Theoretical Foundations
Neural operators have become a powerful alternative to classical numerical solvers for partial differential equations (PDEs), addressing computational bottlenecks in high-resolution physics simulations. However, modeling long-range dependencies—core to many physical systems—remains a fundamental challenge, as explicit discretizations or dense attention scale quadratically with the number of spatial points, quickly overwhelming both GPU memory and time budgets.
This paper formalizes the empirical observation that global interaction kernels induced by common PDEs exhibit rapid spectral decay, rendering them highly compressible via low-rank approximations. This low-rank structure motivates a unified treatment of global-mixing modules in neural operator architectures: compress high-dimensional pointwise features into a compact latent space, process global interactions within this bottleneck, and reconstruct the global context—a template that subsumes both spectral (e.g., Fourier Neural Operators, FNO) and recent attention-based designs. The work's main contribution is the instantiation of this paradigm using only standard Transformer primitives, yielding the Low-Rank Spatial Attention (LRSA) block, which is concise, efficient, and natively compatible with modern hardware-optimized attention kernels.
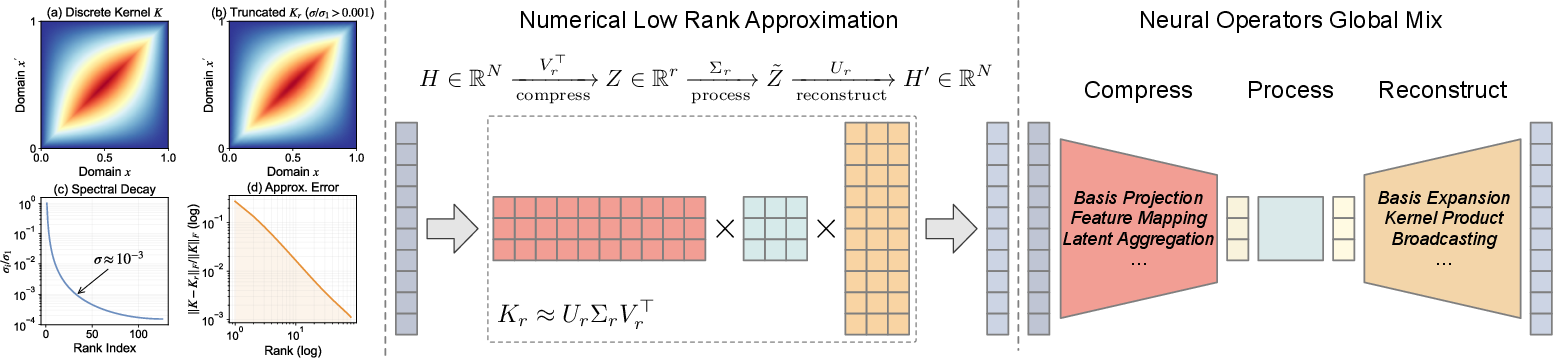
Figure 1: Compressibility of PDE kernels and global mixing; left: Poisson kernel and its fast spectral decay; middle: low-rank approximations; right: architectural unification as compress-process-reconstruct.
Unified Low-Rank Perspective: From Spectral to Latent Attention Operators
Spectral and basis-expansion methods (such as FNO) exploit analytic or geometry-induced bases (Fourier, Laplacian eigenfunctions), projecting fields to a compact mode set. These approaches rely on the analytic compressibility of kernel maps, but require discretization-specific machinery—DFT for regular grids, Laplace–Beltrami eigenfunctions for irregular domains—and are limited by basis misspecification and scaling in unstructured settings.
Attention-based operator models, and in particular those introducing latent bottlenecks (e.g., Transolver, LinearNO), attempt data-driven compression via learnable assignments of points to latent tokens. However, they typically require custom normalization or aggregation, break compatibility with optimized kernels, and often suffer from numerical instabilities in reduced precision regimes.
The unified low-rank template proposed here abstracts all these models as an implicit factorization K≈UGV⊤, where U, V are (potentially input-dependent) basis mappings, and G is an expressive latent mixer. Existing attention-based models are shown to be particular parametrizations (often tied or linear, sacrificing expressiveness or decoupling).
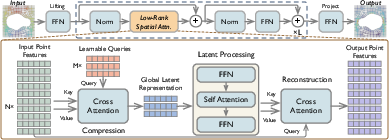
Figure 2: Neural operator backbone; LRSA’s three-stage architecture: compress (cross-attention to latents), process (latent self-attention and FFN), reconstruct (cross-attention from latents to points).
The Low-Rank Spatial Attention (LRSA) Block
The LRSA block fully realizes the compress-process-reconstruct template, with the following architecture:
- Compression: Cross-attention between a small set of learnable latent queries and the input point features aggregates information into M≪N latent tokens. This compression map is data-driven, discretization-invariant, and implemented with scaled dot-product attention.
- Processing: One or more layers of self-attention and FFNs on latents enable rich, nonlinear modeling of cross-token dependencies, essential for capturing the nonlinear couplings found in complex physical systems (e.g., time-dependent PDEs).
- Reconstruction: A second cross-attention step broadcasts the processed latents back to all spatial points, yielding an update that decouples the compressive and reconstructive projections; this contrasts prior approaches that force symmetry between write and read assignments.
The entire module is composed strictly of standard Transformer operations (attention, normalization, FFN), ensuring seamless deployment of fused kernels (e.g., FlashAttention-2), and unlocking large efficiency gains on modern accelerators.
Experimental Results and Empirical Analysis
LRSA is evaluated extensively on canonical PDE surrogates (Darcy, Navier–Stokes, Elasticity, Airfoil, Pipe, Plasticity), irregular domains, and large-scale, design-relevant cases (AirfRANS, ShapeNet Car). Across all benchmarks:
- Mean test errors are reduced by >17% on average compared to the strongest alternative, with best-in-class performance on all standard and industrial datasets.
- Qualitative results show sharper recovery of high-frequency physical features and lower error maps versus state-of-the-art baselines.
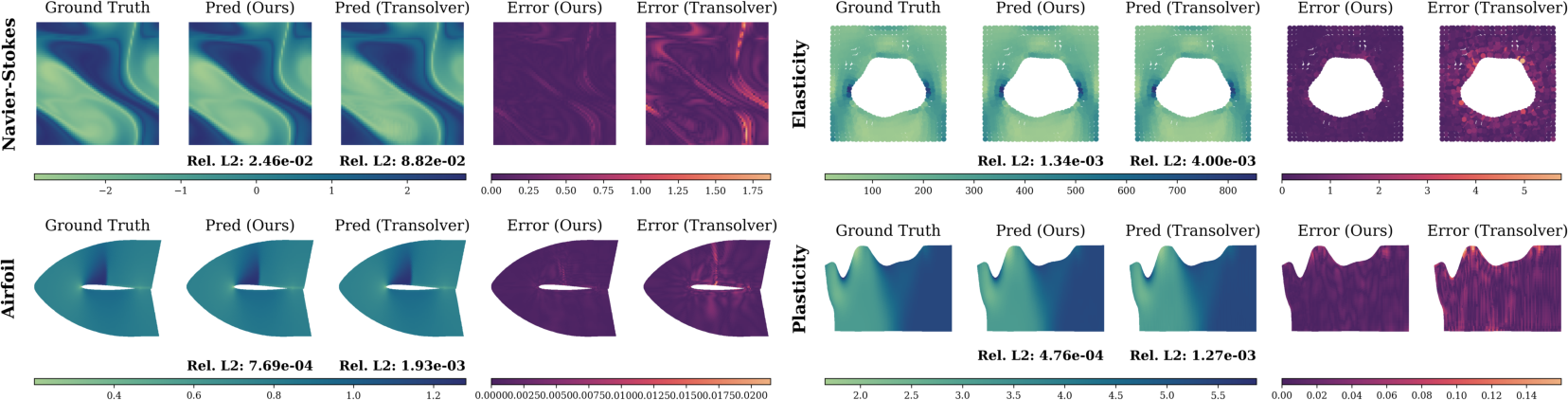
Figure 3: Qualitative comparison across discretizations; LRSA yields lower errors and preserves sharp features.
- Resolution Generalization: LRSA demonstrates superior zero-shot generalization to unseen spatial discretizations, maintaining stability and accuracy, a critical property for mesh-invariant operator learning.
- Mixed Precision Training: Unlike previous latent-attention architectures, LRSA is highly robust under bfloat16 and float16, matching FP32 accuracy and reducing peak memory usage and latency by factors of 2–3 due to the compatibility with hardware-optimized kernels.
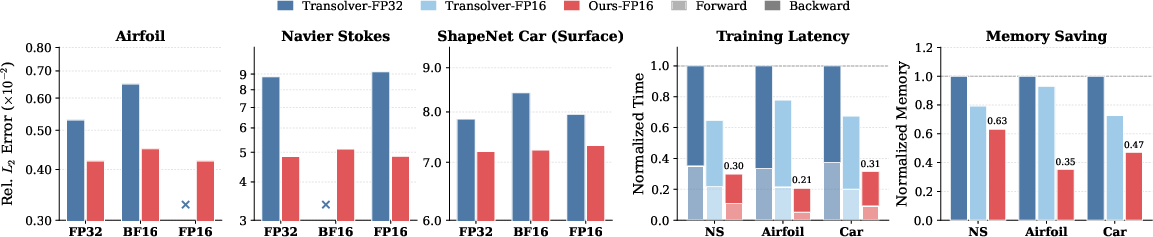
Figure 4: LRSA exhibits stable training and reduced error across floating point precisions (FP32, BF16, FP16), with substantial runtime and memory savings.
- Ablation Studies: Removing latent self-attention deteriorates performance, especially for time-dependent cases, validating the necessity of a nonlinear latent mixer. Enforcing symmetry between the compression and reconstruction projections (as in Transolver) yields higher error, indicating the value of receptive subspace decoupling.
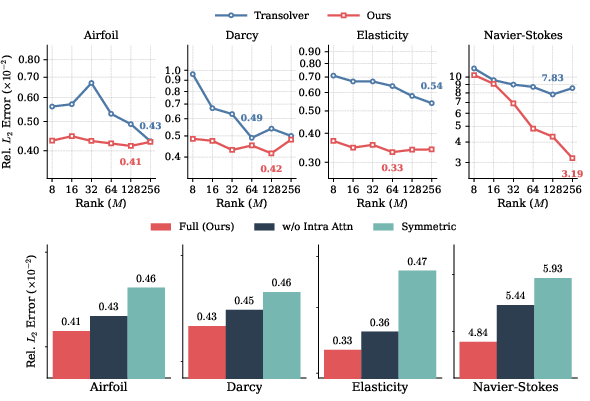
Figure 5: LRSA error saturates with moderate latent dimension M; ablations confirm the importance of decoupled compression and latent mixing.
Practical and Theoretical Implications
The results provide compelling evidence that a strictly Transformer-based, data-driven low-rank bottleneck can achieve accuracy competitive with, and often exceeding, both analytically motivated spectral methods and previous sophisticated latent attention designs. Particularly:
- Decoupling the compression and reconstruction stages is crucial for performance, as is retaining a nonlinear latent mixer.
- LRSA avoids custom aggregation or normalization steps, enabling robust deployment in large-batch, mixed-precision, and high-resolution scenarios that are common in practical scientific computing workflows.
- The approach generalizes seamlessly across regular grids, structured/unstructured meshes, and point clouds without requiring geometry-dependent design or precomputation.
Limitations and Future Directions
One of the remaining open questions regards optimal capacity allocation—how to balance model width between the latent processing and pointwise update paths, particularly as spatial resolution and the underlying physical complexity of problems scale further. Additionally, principled approaches for automatically adapting latent bottleneck width (M) and numbers of layers per physical context, potentially through meta-learning or adaptive profiling during large-scale multi-physics pretraining, represent promising future work.
Conclusion
This work establishes a rigorous, unified low-rank view of global mixing in neural operator design and proposes the LRSA architecture—a minimal, hardware-friendly, expressive block utilizing only standard Transformer modules. Extensive empirical evaluation confirms both theoretical and practical advances, with direct implications for scalable, robust, and efficient PDE surrogate modeling relevant to both core scientific computing and industrial engineering contexts. The approach paves the way for further research into architecture capacity allocation strategies and the broader exploitation of low-rank properties in scientific machine learning.