- The paper introduces a drift-field based one-step policy framework that shifts all refinement to training, eliminating costly iterative inference.
- It achieves high-fidelity multimodal control in both offline imitation and online RL settings while maintaining strict 1-NFE efficiency.
- Empirical results on simulation and real-world platforms demonstrate significant performance gains in latency-constrained robotic tasks.
Drift-Based Policy Optimization: One-Step Generative Policy Learning for Online Robot Control
Introduction and Motivation
High-frequency closed-loop visuomotor robot control with explicit multimodal action distributions has been dominated by iterative generative models, notably multi-step diffusion-based policies. While such models (e.g., Diffusion Policy, DP3) achieve high success rates, they incur substantial inference costs by requiring tens to hundreds of network function evaluations (NFEs) per action, rendering them unsuitable for latency-constrained or real-time control and for sample-inefficient use in online reinforcement learning. One-step generative acceleration via distillation or mean/flow-based policies ameliorates inference speed, but often either inherits dependency on multi-step teachers or requires auxiliary ad-hoc regularization.
"Drift-Based Policy Optimization: Native One-Step Policy Learning for Online Robot Control" (2604.03540) formalizes and empirically validates a novel two-stage framework for genuinely native one-step policies—Drift-Based Policy (DBP) and Drift-Based Policy Optimization (DBPO)—that achieve high-fidelity, real-time, multimodal policy generation for both offline imitation and online RL settings, with strict 1-NFE deployment by construction. The approach subsumes latent-autoregressive, diffusion, and mean-field flows into a principled drift-field learning setup that internalizes attraction-repulsion correction during training rather than inference.
Existing generative policy learning for robot control can be organized into:
- Multi-Step Iterative Policies: Rely on iterative denoising/transport (diffusion, flow) for generating actions, providing flexible modeling of multimodal distributions but with significant computation at deployment.
- Distillation-Based One-Step Policies: Compress multi-step policies into one-step surrogates via consistency distillation, inheriting quality from the teacher but losing nativeness and requiring complex pretraining.
- Mean-/Flow-Based One-Step Methods: Engineer special objective terms (dispersive, alignment, velocity-consistency) during learning to stabilize quality under 1-NFE constraint; can suffer from collapse or require loss tuning.
DBP departs fundamentally by shifting all refinement to the training phase and using fixed-point drift-field regression, thereby achieving natively efficient multimodal policies.
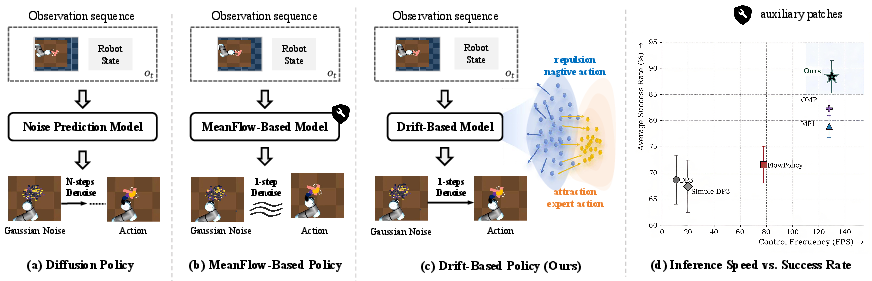
Figure 1: A taxonomy of generative policy designs and the performance–efficiency trade-off, highlighting the intrinsic 1-NFE property and superior empirical metrics of DBP/DBPO.
Drift-Based Policy: One-Step Drift-Field Regression
The core of DBP is a one-step generator fθ mapping observation history and latent noise z∼N(0,I) to a full chunk of actions. The generator is trained on an offline demonstration dataset using a drift-field loss:
- For a batch of G hypotheses per condition, the generator is optimized not simply for maximum likelihood w.r.t. expert actions, but for strong geometric integration of expert "attraction" and inter-hypothesis "repulsion."
- The drift-field, constructed via symmetric, temperature-scaled affinities, encourages hypotheses to approach expert actions while spreading out amongst themselves, enforcing both multimodal support and mode separation.
Geometric normalization, multi-temperature aggregation, and stop-gradient detached targets are employed to stabilize learning and avoid mode collapse.
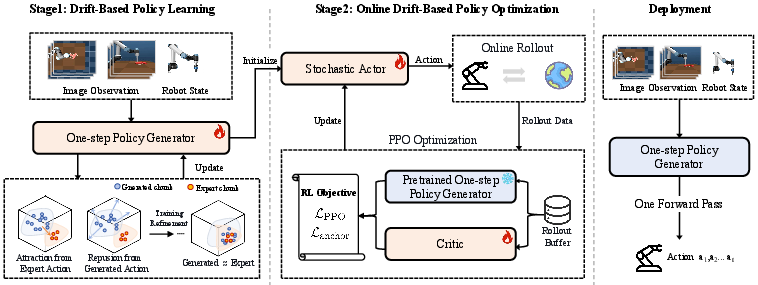
Figure 2: Two-stage training pipeline: Stage 1 (DBP) performs drift-field regression to shape a native one-step action generator; Stage 2 (DBPO) fine-tunes with on-policy PPO and anchor regularization, maintaining strict 1-NFE inference.
Drift Manifold Evolution
Empirically, as training proceeds, the hypothesis distribution that is initially dispersed and poorly aligned with expert actions contracts and concentrates around expert-supported modes, evidencing the progressive internalization of corrective dynamics.
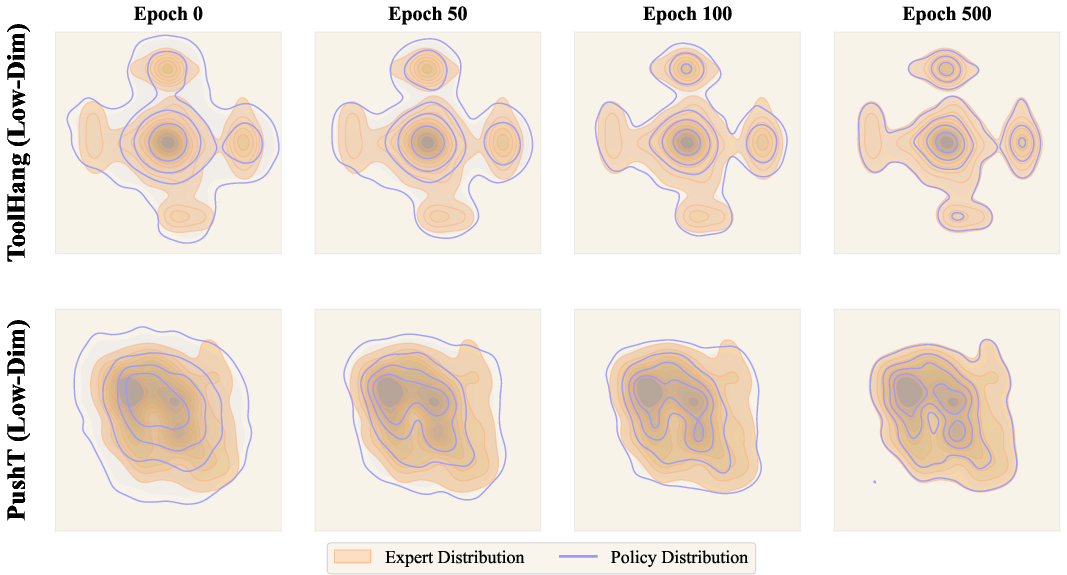
Figure 3: Alignment between policy hypothesis distribution and expert modes over training, demonstrating contraction toward expert support under the drift-field objective.
Drift-Based Policy Optimization: Online RL Extension
While DBP produces high-quality policies for imitation, further improvement in non-demonstrated regions or task-specific returns necessitates online RL. DBPO extends DBP via:
- An analytic stochastic actor built atop the frozen backbone, introducing Gaussian exploration with state-conditioned scale while preserving 1-NFE structure.
- An exact likelihood computation for PPO updates, using rollout-stored latents to avoid marginalization and ensure full compatibility with on-policy policy gradients.
- An anchor regularizer that penalizes deviation from the pretrained backbone, stabilizing optimization and controlling catastrophic drift.
During fine-tuning, only the executed prefix of each predicted chunk is credited via log-likelihood, aligning the optimization target with the control deployment strategy.
Empirical Results
Imitation Performance: On the 12-task Diffusion Policy suite, DBP achieves an average score improvement from 0.79 (100 NFE) to 0.83 (1 NFE), validating that drift-based one-step modeling can match or surpass vigorous iterative denoising when drift is properly internalized.
Point-cloud manipulation on Adroit and Meta-World benchmarks yields an 88.4% average success rate, outperforming prior one-step baselines such as OMP (82.3%) and mean-flow models, with especially strong gains on complex dexterous tasks.
RL Fine-Tuning: In both RoboMimic manipulation and D4RL locomotion, DBPO improves post-fine-tuning policy quality while preserving the strict 1-NFE property. Absence of the anchor regularizer notably degrades performance, confirming its role in controlling detrimental policy drift.
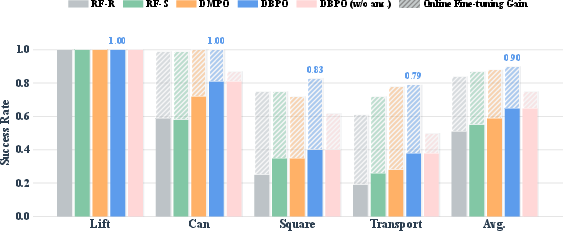
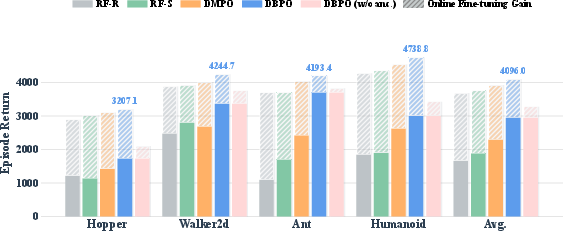
Figure 4: Fine-tuning metrics: DBPO achieves consistent post-update gains from strong offline initialization across vision-based control tasks.
Real-World Robotic Deployment
DBP/DBPO policies have been deployed at 105.2 Hz control rate on a dual-arm UR5 platform using real RGB point cloud observations, demonstrating a 75% success rate under severe occlusion and hardware constraints. This provides strong evidence of the framework's practical, low-latency viability.

Figure 5: Physical bimanual manipulations including precision and transport tasks, all executed at high frequency with only 1-NFE per control cycle.
Sensitivity Analyses and Ablations
- Performance peaks with small-to-moderate numbers of hypotheses (e.g., G=4).
- Single moderate temperature (e.g., T=0.2) is sufficient for best variance and performance.
- Training time scales linearly with hypothesis count G—adding minimal computational overhead compared to generator forward and backward pass.
Policy Rollout Qualitative Visualizations
Successful rollouts in simulation and physical robots show temporally coherent, smooth action sequences on dexterous and challenging manipulation tasks, with zero need for any iterative test-time correction.

Figure 6: DBP rollouts on Adroit and Meta-World: smooth non-iterative control across temporally sampled frames.

Figure 7: Rollout continuation: evidence of policy stability and precision across task complexity.
Theoretical and Practical Implications
By relocating all refinement to the training phase and constructing a drift field that functions as a distributional fixed-point operator, DBP/DBPO obviate the need for either time-consuming diffusion iterations or post-hoc corrective modules, while retaining multimodal expressiveness and analytic likelihoods required for online RL. This approach reshapes the design space for generative policy models—making it possible to jointly optimize for quality and deployment efficiency, a trade-off previously considered intractable.
From a robotics perspective, native one-step policies with drift-field internalization remove significant barriers to real-time policy deployment in industrial, assistive, and complex multitask settings. The framework is broadly compatible with multi-modality sensory inputs (RGB, point cloud, proprioception), and is not codependent on teacher policies or special-purpose architectures.
Conclusion
This work establishes drift-based generative policy optimization as a robust, scalable solution to the longstanding latency–quality trade-off in robot policy learning. The two-stage scheme—deterministically internalizing refinement in training (DBP), followed by stable, anchor-regularized online RL (DBPO)—demonstrates strong numerical and practical results across large-scale simulation, vision-based real robots, and standard RL domains. The intrinsic 1-NFE property, strict preservation of multi-modality, and successful online adaptation are notably contradictory to the view that iterative steps are necessary for high-action-quality multimodal policies.
Theoretically, this work motivates further investigation into geometric drift-field optimization and its convergence guarantees under high-dimensional function approximation. Practically, it suggests a pathway for generalizing real-time policy deployment to larger model scales, unstructured environments, and high-dimensional sensorimotor spaces. Integrating drift-based objectives with vision-language-action models, lifelong learning, and sample-efficient RL will likely be productive directions for future research.
Reference:
Yuxuan Gao et al., "Drift-Based Policy Optimization: Native One-Step Policy Learning for Online Robot Control," (2604.03540).