Diffusion Policy Policy Optimization
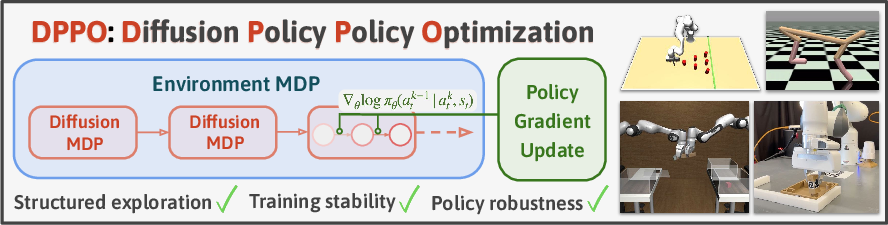
Abstract: We introduce Diffusion Policy Policy Optimization, DPPO, an algorithmic framework including best practices for fine-tuning diffusion-based policies (e.g. Diffusion Policy) in continuous control and robot learning tasks using the policy gradient (PG) method from reinforcement learning (RL). PG methods are ubiquitous in training RL policies with other policy parameterizations; nevertheless, they had been conjectured to be less efficient for diffusion-based policies. Surprisingly, we show that DPPO achieves the strongest overall performance and efficiency for fine-tuning in common benchmarks compared to other RL methods for diffusion-based policies and also compared to PG fine-tuning of other policy parameterizations. Through experimental investigation, we find that DPPO takes advantage of unique synergies between RL fine-tuning and the diffusion parameterization, leading to structured and on-manifold exploration, stable training, and strong policy robustness. We further demonstrate the strengths of DPPO in a range of realistic settings, including simulated robotic tasks with pixel observations, and via zero-shot deployment of simulation-trained policies on robot hardware in a long-horizon, multi-stage manipulation task. Website with code: diffusion-ppo.github.io

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Knowledge Gaps
Knowledge Gaps, Limitations, and Open Questions
Below is a single, concrete list of what remains missing, uncertain, or unexplored in the paper; each point is phrased so future researchers can act on it.
- Lack of theoretical guarantees: no analysis of convergence, stability, or sample complexity for DPPO in the two-layer (environment + denoising) MDP setting, especially under PPO clipping and the denoising-discount scheme.
- Reward assignment design in the denoising MDP: the paper assigns reward only at the final denoising step (k=0); it does not study alternative credit-assignment strategies (e.g., shaping or proxy rewards across denoising steps) and their effect on variance, bias, or learning speed.
- Advantage/value estimator choice: the value function ignores the denoised action component and uses only the environment state; there is no systematic evaluation of when this choice is optimal versus learning a critic that conditions on denoising state/action or modeling per-step value across the inner MDP.
- Hyperparameter sensitivity and tuning guidelines are under-specified: the impact of key choices (number of denoising steps to fine-tune K′, inner/outer discounts, PPO clip range, GAE λ, learning rates, batch sizes) on performance and stability is not quantified; actionable tuning recipes are missing.
- Noise schedule clipping: the paper clips σk to higher minima for exploration and likelihood evaluation, but does not characterize how these thresholds affect exploration structure, gradient magnitudes, bias of the policy gradient, or robustness across tasks; automatic or adaptive scheduling is unstudied.
- DDIM vs. DDPM trade-offs: while DDIM is used for efficiency, the paper does not analyze the bias introduced by training stochastically (η>0) but evaluating deterministically (η=0), nor quantify how KDDIM, η, and schedule choices impact asymptotic performance, stability, and sample efficiency.
- Gradient variance impact of the expanded horizon: treating denoising as an inner MDP multiplies the effective horizon by K; the paper claims stability but does not measure gradient variance or compare variance-reduction techniques (e.g., per-step baselines, control variates, inner-loop normalization).
- On-manifold exploration claim is not operationalized: there is no quantitative definition or metric for “on-manifold” exploration nor empirical measures (e.g., density estimation, coverage metrics, trajectory smoothness) that validate this mechanism across tasks and datasets.
- Robustness characterization is limited: robustness is asserted but not systematically stress-tested with controlled perturbations (e.g., dynamics shifts, sensor noise, actuator delays, contact uncertainties), distribution shifts, or safety constraints; robustness benchmarks and metrics are missing.
- Data efficiency vs. off-policy methods: comparisons focus on final performance/stability; the paper does not provide standardized interaction budgets, data reuse ratios, or controlled “equal-sample” studies to quantify data efficiency relative to off-policy baselines or replay-buffer augmentation.
- Baseline coverage gaps: important baselines (e.g., SAC+BC, AWAC variants, DreamerV3, KL-regularized actor-critic, Q-advantage actor methods) and non-diffusion on-manifold regularizers are not comprehensively included; systematic comparisons across continuous/pixel inputs and long horizons are incomplete.
- Credit-assignment and discounting design: the choice and interaction of environment discount γ and denoising discount γ̃ (inner-loop) are not theoretically analyzed; optimal schedules or criteria for selecting these discounts are unknown.
- Policy parameterization ablations are incomplete: the paper suggests benefits over Gaussian or GMM policies but does not explore hybrids (e.g., normalizing flows, energy-based policies) or multi-step latent-variable policies; actionable guidance on when diffusion parameterization is preferable is lacking.
- Structured critic design for the two-layer MDP is unexplored: critics that exploit the hierarchical structure (e.g., per-k value heads, temporal abstraction across denoising steps) or learned inner-loop advantages are not investigated.
- Action chunking design (Ta vs. Tp) is under-explored: the trade-offs among prediction horizon Tp, action horizon Ta, and architecture (MLP vs. UNet) are not systematically studied; guidelines for selecting Ta/Tp across tasks are missing.
- Safety and constraint handling: the framework does not address constraint satisfaction (e.g., safety shields, torque/joint limits, collision avoidance) or how to integrate constrained RL or safe exploration within diffusion denoising steps.
- Discrete or hybrid action spaces: applicability of DPPO to discrete or mixed discrete-continuous actions is not discussed; a generalization path (e.g., categorical diffusion, Gumbel variants) is an open question.
- Integrating guidance methods: the synergy between policy gradient updates and guidance-based sampling (e.g., classifier-free guidance, goal-conditioned score guidance) is unstudied; how guidance affects exploration, bias, and stability remains open.
- Catastrophic forgetting and distributional drift: the paper does not measure how RL fine-tuning alters the learned action distribution (e.g., mode dropping, calibration), nor track generative metrics that assess whether policies drift off the demonstration manifold after optimization.
- Pretraining data quality: sensitivity to suboptimal, noisy, or low-coverage demonstrations is not rigorously evaluated; mechanisms to correct for demonstration bias or learn from misspecified datasets (e.g., reweighting, inverse propensity) remain unexamined.
- Partial observability and memory: while POMDPs are mentioned, recurrent architectures, state estimators, or belief-space diffusion policies are not studied; the effect of memory on DPPO performance in long-horizon, pixel-based tasks is unknown.
- Real-world validation breadth: hardware evaluation is limited (single task/setting); the sim-to-real process (e.g., domain randomization specifics, sensory/actuation latencies, calibration drift) is not detailed, and generality across objects, embodiments, and environments is untested.
- Deterministic vs. stochastic evaluation: switching to η=0 at test time may reduce robustness; the impact of test-time stochasticity (e.g., small η>0, ensemble sampling) on reliability and performance is not analyzed.
- Off-policy variants of DPPO: whether DPPO can be adapted to off-policy actor-critic (e.g., importance sampling in the inner MDP, replay reuse, V-trace) to improve data efficiency remains open; algorithmic modifications and stability criteria are unknown.
- Regularization and entropy: the role of entropy bonuses, KL regularization to the pre-trained policy, or other trust-region variants in the diffusion setting is under-specified; optimal regularization for balancing exploration vs. staying on-manifold is unclear.
- Computational footprint: wall-clock and memory costs are only briefly discussed; no profiling of per-component cost (inner-loop sampling, likelihood computation, critic learning) or strategies for acceleration (e.g., caching, parallel denoising, distillation) are provided.
- Sensitivity to action dimensionality and task complexity: while some high-dimensional tasks are shown, scaling behavior to even larger action spaces, more complex contact-rich manipulation, or multi-agent coordination is not characterized.
- Metricization of training stability: claims of stability lack formal measures (e.g., variance of returns across seeds, gradient norm statistics, policy divergence over updates); standardized stability metrics and benchmarks are absent.
- Generalization beyond robotics is speculative: proposed extensions to text-to-image or drug discovery are not experimentally validated; domain-specific adaptations (e.g., reward design, feedback loops, discrete latent spaces) and obstacles are unidentified.
Glossary
- Action chunk size: The number of consecutive actions produced or executed per policy step by the policy. "action chunk size "
- Advantage estimator: A method to estimate the advantage used in policy optimization, often for PPO updates. "Given an advantage estimator "
- Advantage function: The expected extra return of taking an action versus the baseline value at a state; used to guide policy updates. "We show how to efficiently estimate the advantage function for the PPO update."
- Advantage-weighted regression (AWR): A regression technique that weights samples by their advantage to update policies. "advantage-weighted regression \citep{peng2019advantage}"
- Behavior Cloning (BC): Supervised imitation learning that fits a policy to expert demonstrations without using explicit rewards. "behavior cloning with expert data \citep{pomerleau1988alvinn}"
- Cosine schedule: A noise variance schedule for diffusion models that follows a cosine-shaped annealing. "We use the cosine schedule for introduced in \cite{nichol2021improved}"
- D4RL: A benchmark and datasets suite for offline reinforcement learning. "D4RL \citep{fu2020d4rl}"
- Denoising Diffusion Implicit Model (DDIM): An implicit, typically fewer-step sampler for diffusion models that can be deterministic or stochastic. "Denoising Diffusion Implicit Model (DDIM) \cite{song2020denoising}"
- Denoising diffusion probabilistic model (DDPM): A generative modeling framework that defines data via a reverse denoising process of a noisy forward diffusion. "A denoising diffusion probabilistic model (DDPM) \citep{nichol2021improved, ho2020denoising, sohl2015deep}"
- Denoising steps: The iterative reverse-process steps in diffusion sampling that progressively remove noise to produce a sample. "the last few steps of the denoising process"
- Diffusion MDP: An MDP representation of the denoising process, enabling RL-style optimization through diffusion steps. "Markov Decision Process (``Diffusion MDP'')"
- Diffusion noise schedule: The schedule controlling the noise levels (variances) across denoising steps in diffusion models. "modifications to the diffusion noise schedule"
- Diffusion Policy (DP): A reinforcement learning policy parameterized by a diffusion model that generates actions via denoising conditioned on observations. "Diffusion Policy (DP; see \citet{chi2023diffusion})"
- Diffusion Policy MDP: A two-layer MDP embedding the denoising MDP inside the environment MDP to propagate rewards through diffusion sampling. "forming a two-layer ``Diffusion Policy MDP''"
- Diffusion Policy Policy Optimization (DPPO): A framework for fine-tuning diffusion-based policies using policy gradient methods like PPO. "We introduce Diffusion Policy Policy Optimization"
- Dirac distribution: A point-mass distribution concentrated at a single value. "to denote a Dirac distribution"
- Generalized Advantage Estimation (GAE): A technique to compute advantages with a bias-variance tradeoff using temporal discounting. "we use Generalized Advantage Estimation (GAE, \citet{schulman2015high})"
- Gaussian likelihood: The probability density of actions under a Gaussian model, enabling analytic gradients in diffusion steps. "tractable Gaussian likelihood at each denoising step"
- Guidance: Procedures for steering diffusion sampling using auxiliary objectives, such as rewards or conditions. "guidance \citep{janner2022planning,ajay2022conditional}"
- Long-horizon manipulation tasks: Robotic tasks requiring many sequential actions and stages to complete. "long-horizon manipulation tasks with sparse reward."
- Markov Decision Process (MDP): A mathematical model for sequential decision making with states, actions, transitions, and rewards. "Markov Decision Process (MDP)"
- Off-policy Q-learning: RL methods that learn value functions and policies from data collected by potentially different behavior policies. "off-policy Q-learning \citep{wang2022diffusion, hansen2023idql, yang2023policy, psenka2023learning}"
- On-manifold exploration: Exploration that stays close to the data manifold learned during pre-training, yielding structured behavior. "structured and on-manifold exploration"
- Partially Observed Markov Decision Process (POMDP): An MDP where the agent observes only partial information about the true state. "Partially Observed Markov Decision Process (POMDP)"
- Policy Gradient (PG): A class of RL algorithms that optimize the expected return by differentiating through action likelihoods. "policy gradient (PG) method"
- Product distribution: A distribution representing independent components whose joint density factors as a product. "to denote a product distribution"
- Proximal Policy Optimization (PPO): An on-policy policy gradient algorithm using a clipped objective to stabilize updates. "Proximal Policy Optimization (PPO) \citep{schulman2017proximal}"
- Q-function estimator: An estimator of the action-value function used to replace returns in policy gradient updates. "more generally, can be replaced by a Q-function estimator"
- Reward-weighted regression (RWR): A regression method that weights training samples by their rewards to improve policies. "reward-weighted regression \citep{peters2007reinforcement}"
- Sim-to-real gap: The performance discrepancy observed when transferring policies from simulation to real hardware. "a remarkably small sim-to-real gap compared to the baseline."
- Sparse reward: A reward structure where positive feedback is given infrequently, often only upon task completion. "with sparse reward"
- State-value function: The expected return from a given state under a policy. "a state-value function "
- UNet: A convolutional neural network architecture with skip connections, commonly used as a diffusion model backbone. "UNet \cite{ronneberger2015u}"
- Zero-shot deployment: Deploying a policy to a new setting without additional training or adaptation. "zero-shot deployment of simulation-trained policies"
Collections
Sign up for free to add this paper to one or more collections.