- The paper introduces POCO, which reframes policy improvement as posterior inference with a robust clipped surrogate objective to stabilize fine-tuning.
- It employs an implicit E-M procedure over temporal action chunks, ensuring sample efficiency and effective adaptation in offline-to-online settings.
- Experimental results demonstrate POCO's enhanced success rates and stability over baselines in both simulated and real-world robotic manipulation tasks.
Posterior Optimization with Clipped Objective: Sample-Efficient and Stable Policy Improvement for Generative Robotic Policies
Introduction and Problem Setting
The POCO framework targets the offline-to-online adaptation of high-capacity, likelihood-free generative policies—such as diffusion or flow matching models and Vision-Language-Action (VLA) models—for complex robotic manipulation. Prior RL methods for such policies are limited by a stability-efficiency dilemma: off-policy approaches are sample-efficient but exacerbate policy collapse due to OOD value overestimation, while on-policy methods are stable but impractically data-inefficient in physical systems. This work formulates policy improvement as a posterior inference problem over temporal action chunks, distilling reward-weighted posteriors via a clipped objective, thereby addressing the conflicting needs of efficient data usage and stable learning.
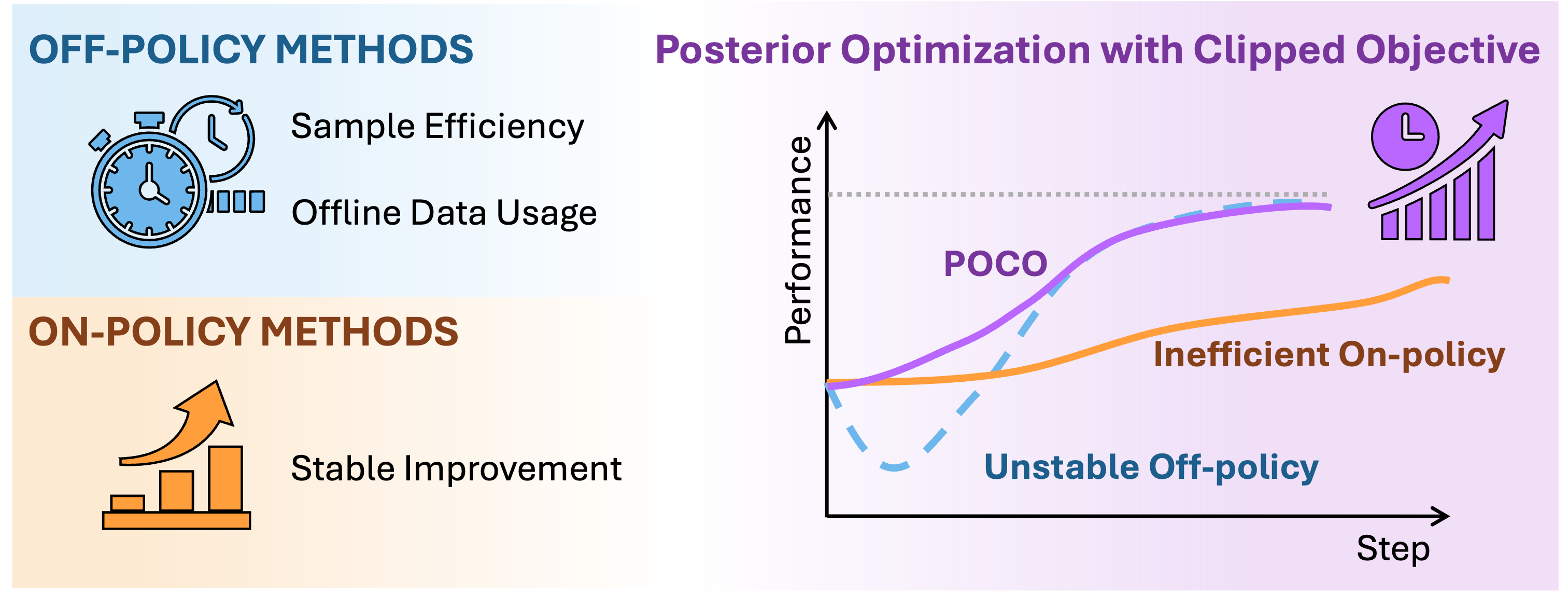
Figure 1: Conceptual overview contrasting off-policy, on-policy, and POCO's sample-efficient and stable improvement paradigm.
Theoretical Framework and Methodology
From Policy Optimization to Posterior Inference
POCO recasts RL policy improvement as inference, applying a maximum-entropy formulation to express reward-weighted trajectory optimality. The framework consistently treats the current policy as a prior over action chunks and refines this prior through a reward-informed posterior via an Expectation-Maximization (E-M) process. This yields a variational ELBO objective for policy adaptation, replacing explicit single-step likelihood computations with chunk-level reward-weighted inference.
To render inference tractable for expressive policies lacking closed-form likelihoods, POCO utilizes implicit posterior evaluation: it samples candidate action chunks from the current policy and assigns them normalized importance weights exponentially proportional to their critic Q-value estimates. This strategy supports efficient credit assignment in high-frequency, temporal-chunked action spaces, addressing the deficiencies of single-step updates in preventing compounding errors.
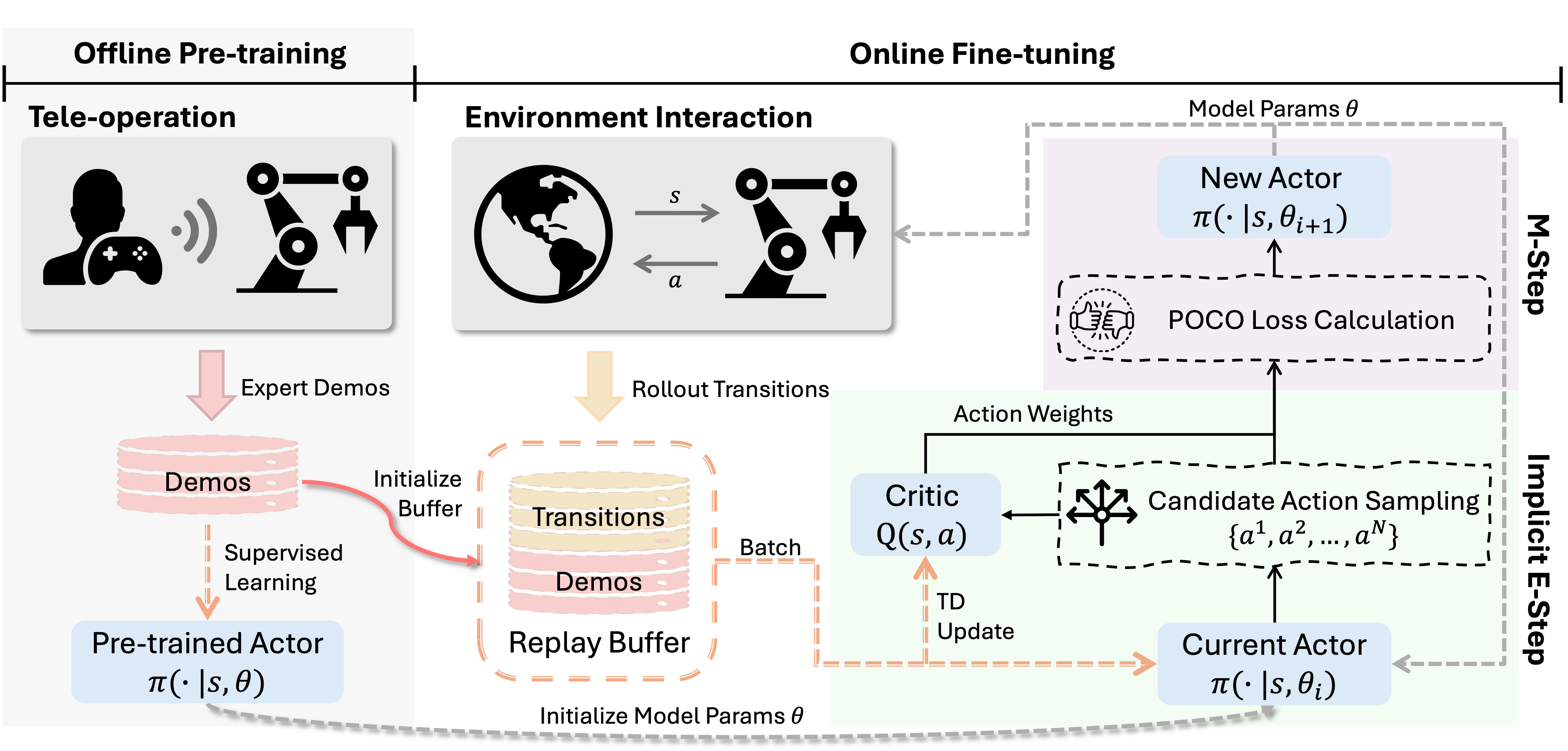
Figure 2: The POCO framework: Stage I—offline expert demonstration pre-training; Stage II—sample-based E-M fine-tuning via implicit posterior and clipped objective.
POCO Loss and Stability Guarantee
The update operator is constructed to be model-agnostic, supporting all expressive likelihood-free generative models. The M-step of E-M is translated into a supervised regression loss with a clipped surrogate objective: the gradient step size attributable to high-weight, potentially OOD, actions is explicitly capped, mathematically enforcing a local trust region around the data manifold and preventing catastrophic collapse of the pre-trained prior. Crucially, the loss includes both a BC (behavior cloning) regularizer and a posterior guidance term weighted by a tunable scaling hyperparameter β, affording explicit control over the exploitation-exploration regularization.
This approach is robust to inaccuracies in Q-value estimation during the initial online adaptation phase, as the clip threshold ζ and guidance scale β can be tuned to minimize performance degradation from overestimated or noisy sample rewards.
Experimental Evaluation
The efficacy of POCO is demonstrated across comprehensive simulation benchmarks ("scene", "puzzle-3x3", "cube-double/triple", "lift", "can", "square") and real-world, contact-rich manipulation tasks (Pick Cube, Route Cable, Insert USB, Assemble SSD, among others). The evaluation protocol covers both pure online RL and offline-to-online fine-tuning settings, with particular attention to success rate, sample efficiency, and the stability of learned trajectories.

Figure 3: Simulated task benchmarks exhibiting varying action dimensionality, sparse-reward dynamics, and long-horizon requirements.

Figure 4: Real-robot platform featuring human-in-the-loop reward assignment and hardware safety mechanisms.

Figure 5: Diverse real-world manipulation tasks, including precision insertion and deformable object handling.
POCO outperforms relevant state-of-the-art methods:
- In online RL, it exhibits notably higher sample efficiency and rapid convergence, especially on complex long-horizon and sparse-reward tasks where direct Q-gradient-based baselines (e.g., FQL) fail due to instability.
- In offline-to-online finetuning, POCO avoids catastrophic forgetting that plagues QC, FQL, and even advanced inference-time control methods (DSRL, ReinFlow), achieving stable monotonic improvements.
- For contact-rich real-robot tasks, POCO attains an average success rate of 96.7%, outperforming both BC initialization (52.5%) and other RL fine-tuning methods by a wide margin.
Figure 6: POCO learning curves in online training, indicating superior sample efficiency and avoidance of OOD-induced collapse.
Figure 7: Offline-to-online adaptation stability: POCO preserves prior performance and enables steady improvement.
Figure 8: Real-world fine-tuning: POCO achieves consistently high final performance with rapid, safe policy adaptation.
Ablation Studies
Ablation on the clip threshold ζ and posterior guidance scale β reveal their criticality: excessively large values for either parameter cause over-fitting to noisy Q-values and early policy degradation, while excessively small values preclude meaningful adaptation, effectively reverting to BC. Proper tuning produces robust, monotonic learning dynamics, with safe exploitation of Q-based posterior information and maintenance of performance guarantees.
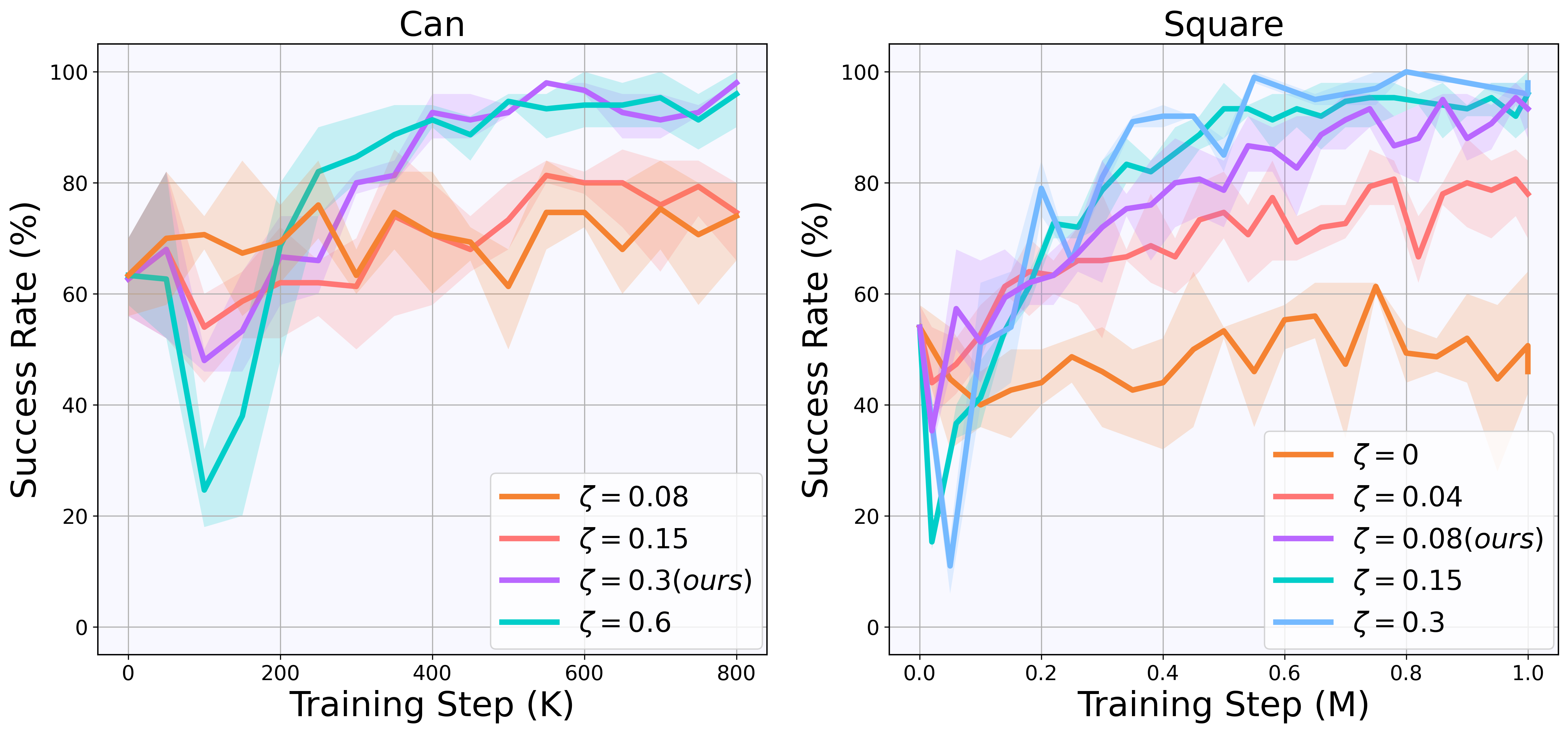
Figure 9: Ablation on ζ (clip threshold) in offline-to-online simulation: excessively permissive thresholds lead to instability.
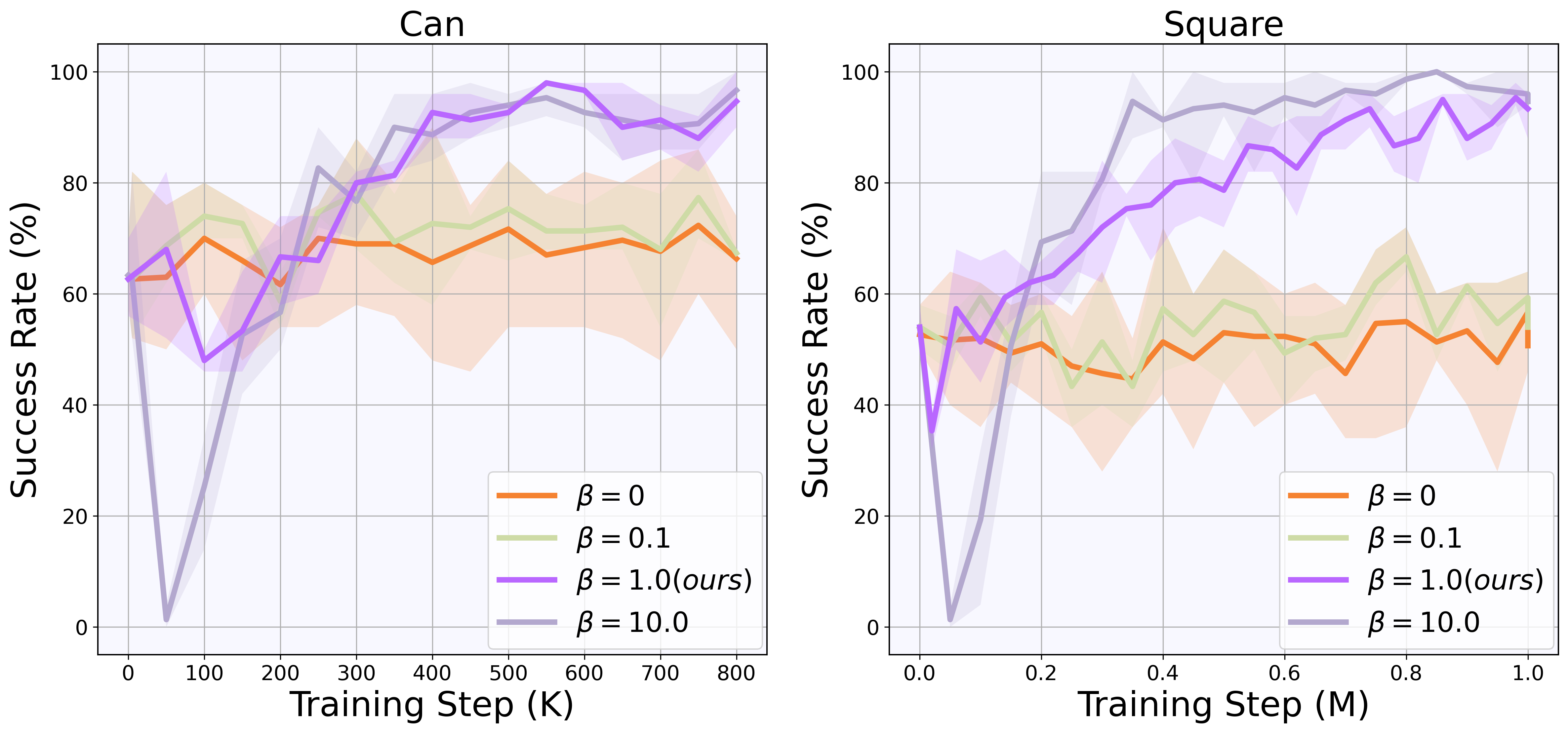
Figure 10: Ablation on β (posterior guidance scale): inappropriate weighting can either neuter exploration or destabilize learning.
Implications and Scalability to Foundation Models
A key strength is the model-agnostic, likelihood-free formulation: POCO extends directly to large VLA models (e.g., π0.5, GR00T N1.6), requiring only partial adaptation of flow-based action modules while keeping frozen encoders and transformers. Experimentally, this yields substantial improvement over supervised finetuning baseline success rates on challenging real-world tasks (e.g., from 63.3%→86.7% on GR00T N1.6 Pick Pen).
The framework's reliance on critic accuracy spotlights future research directions, including the integration of automated dense reward signals (e.g., world-model-based reward shaping) and structured, prior-driven exploration methods to further enhance sample efficiency and stability for open-ended robotic learning.
Conclusion
POCO offers a theoretically grounded and empirically validated solution to the stability-efficiency trade-off endemic to policy improvement with high-capacity generative models. The implicit E-M inference formulation, combined with a clipped objective, guarantees robust, monotonic adaptation in both simulated and physical domains, including when scaling to billion-parameter VLA architectures. The framework stands as a practical tool for enabling RL-driven, safe, and efficient deployment of generative policies for complex, real-world robotic manipulation, and motivates further work at the intersection of RL, foundation model adaptation, and robust value-based control.

