- The paper introduces a hybrid framework that decouples multi-modal action diversity from real-time efficiency by combining a stochastic SDE prefix with a one-step ODE consistency jump.
- The methodology employs consistency distillation with a continuous noise schedule to ensure temporal smoothness and accurate trajectory matching between teacher and student models.
- Experimental results show that HCP achieves a 75.5% success rate and reduces inference steps by 68% while preserving multi-modal behavior, outperforming traditional approaches.
Hybrid Consistency Policy for Decoupling Multi-Modal Diversity and Real-Time Efficiency in Robotic Manipulation
Introduction
The Hybrid Consistency Policy (HCP) addresses a central challenge in diffusion-based visuomotor policy learning: achieving both multi-modal action diversity and real-time inference efficiency in robotic manipulation. Traditional Stochastic Differential Equation (SDE)-based diffusion policies excel at capturing multi-modal behaviors but suffer from slow sampling, while Ordinary Differential Equation (ODE)-based approaches offer fast inference at the cost of mode collapse. HCP introduces a hybrid approach, running a short stochastic SDE prefix to form modal branches, followed by a one-step consistency jump along the probability-flow ODE, thereby decoupling mode retention from inference speed.
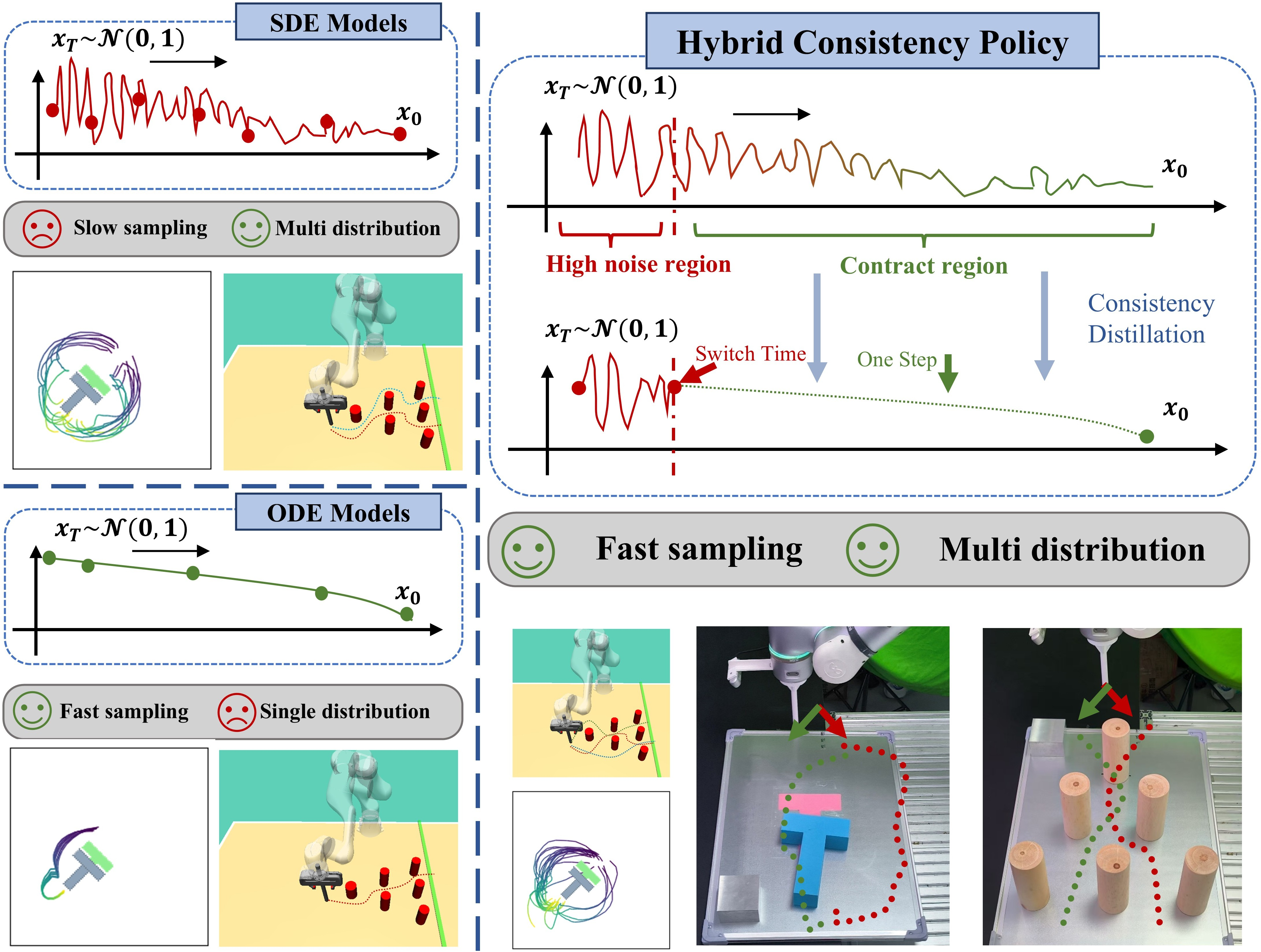
Figure 1: HCP executes a stochastic SDE prefix to form branches, then performs a one-step ODE consistency jump, enabling fast sampling and reliable multi-distribution execution.
Methodology
Hybrid Score Matching and Sampling
HCP models data trajectories using a reverse-time SDE for the initial prefix, transitioning to a deterministic ODE for the final action prediction. The stochastic prefix leverages the multi-modal capacity of SDEs, while the ODE jump ensures rapid inference. The transition point, or switch time ts∗, is adaptively selected based on the stabilization of modal bifurcations and noise contraction metrics.
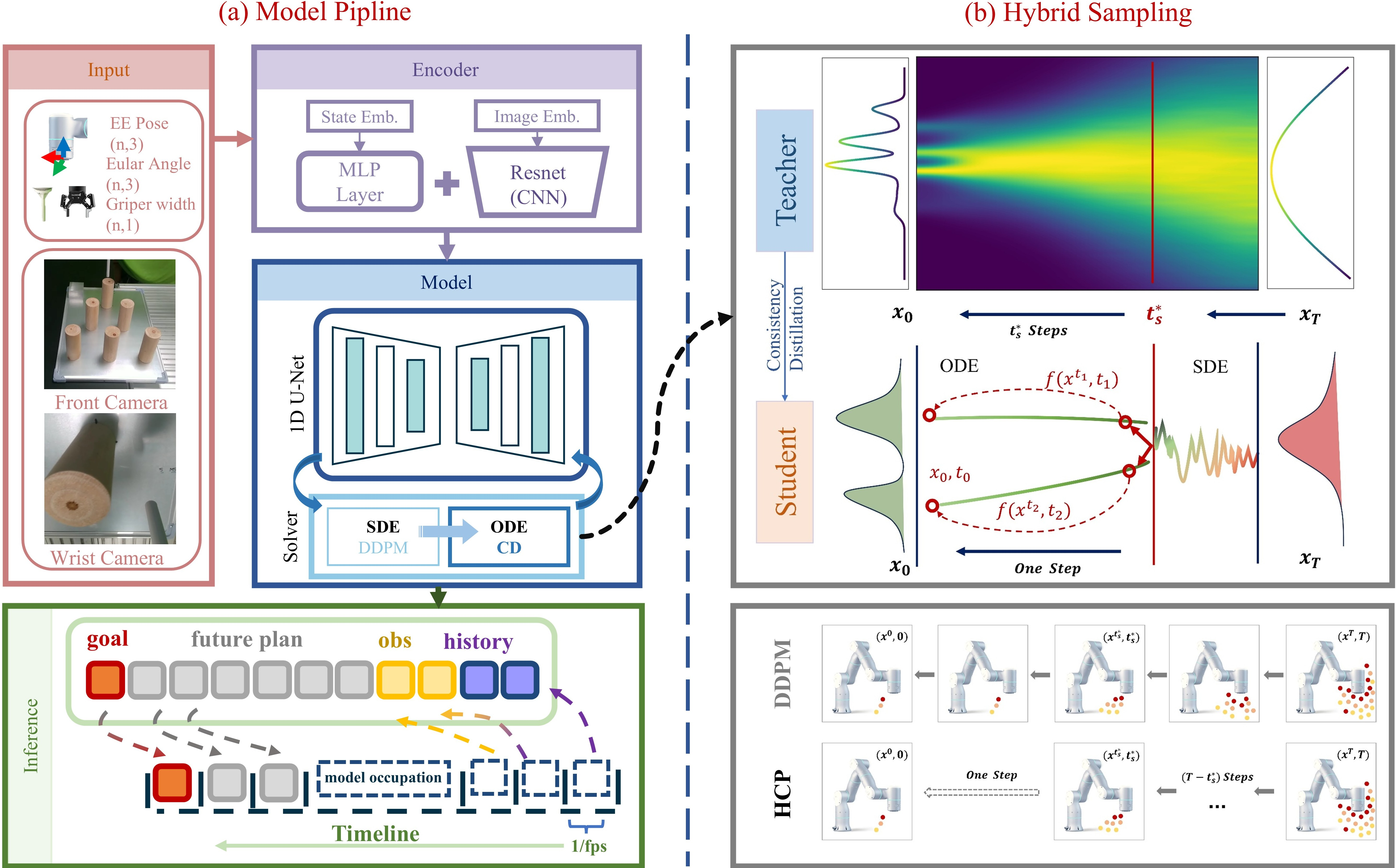
Figure 2: HCP architecture: (a) Policy pipeline encodes robot state and multi-view images; (b) Hybrid sampling uses a DDPM teacher for stochastic trajectories and a student trained via consistency distillation for one-step ODE mapping.
The student model is trained in a continuous noise schedule, aligning with the DDPM teacher via consistency distillation. The loss function combines a trajectory-consistency term (LCTM) to enforce temporal coherence and a denoising-matching term (LDSM) for local fidelity. The hybrid score matching framework enables seamless bridging between stochastic and deterministic regimes.
Consistency Distillation
Consistency distillation is performed by sampling triplets of time steps (s,u,t) and minimizing the discrepancy between student predictions at adjacent times, ensuring temporal smoothness around the switch region. The denoising score matching term evaluates the absolute reconstruction quality against the teacher or ground-truth trajectory. The weighted combination of these losses is tuned to balance smoothness and accuracy.
Switch Time Optimization
The switch time ts∗ is determined by three criteria: (i) sufficient inter-mode gap, (ii) low cumulative noise share, and (iii) stabilized distributional change. Gaussian mixture modeling and kernel density estimation are used to detect stable modal splits and contraction speed, ensuring the jump occurs after bifurcation stabilization but before excessive contraction.
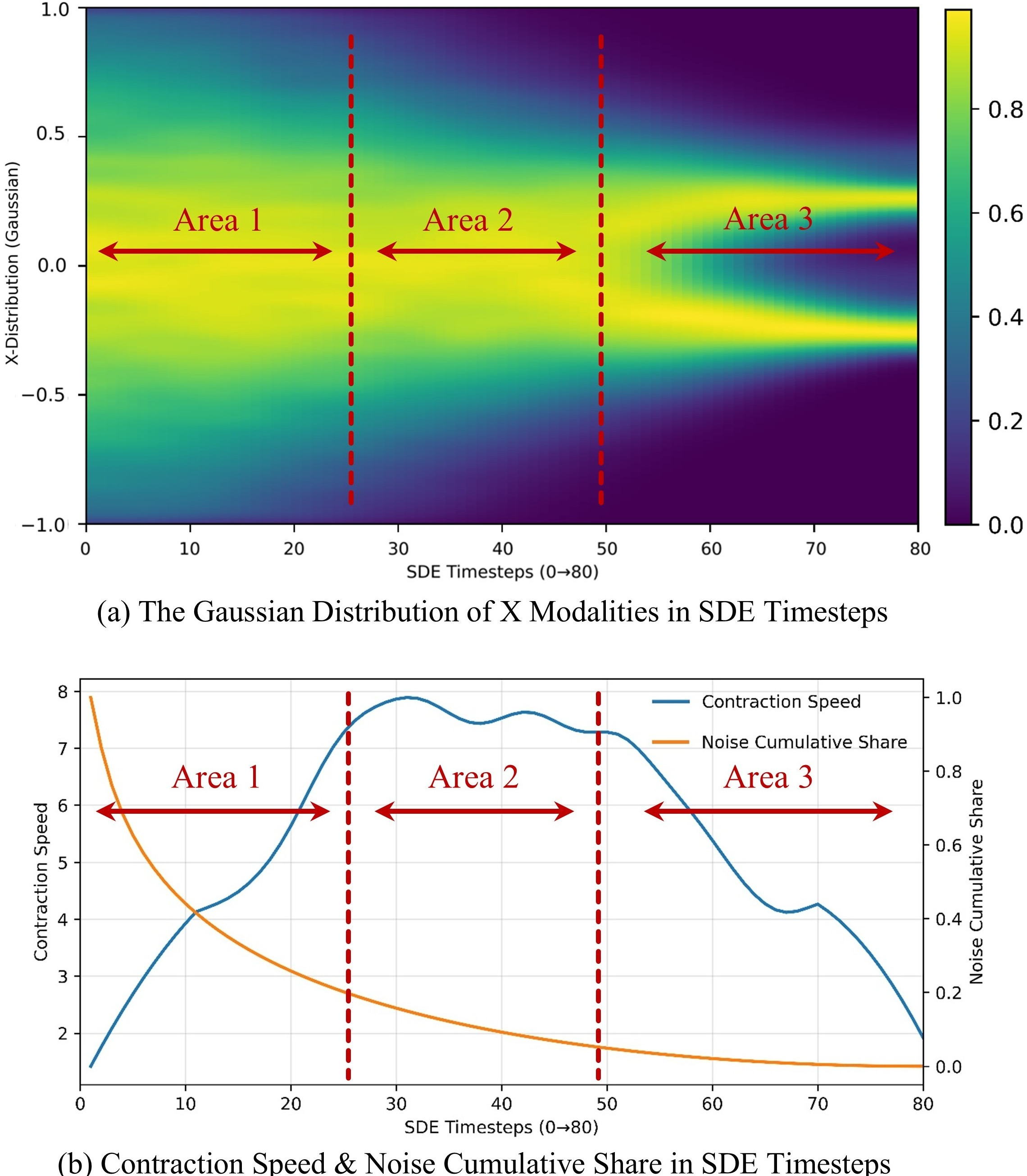
Figure 3: SDE prefix phases and viable switch window: modality formation stabilizes in Area 2, with peak contraction speed and low noise indicating the optimal ts∗.
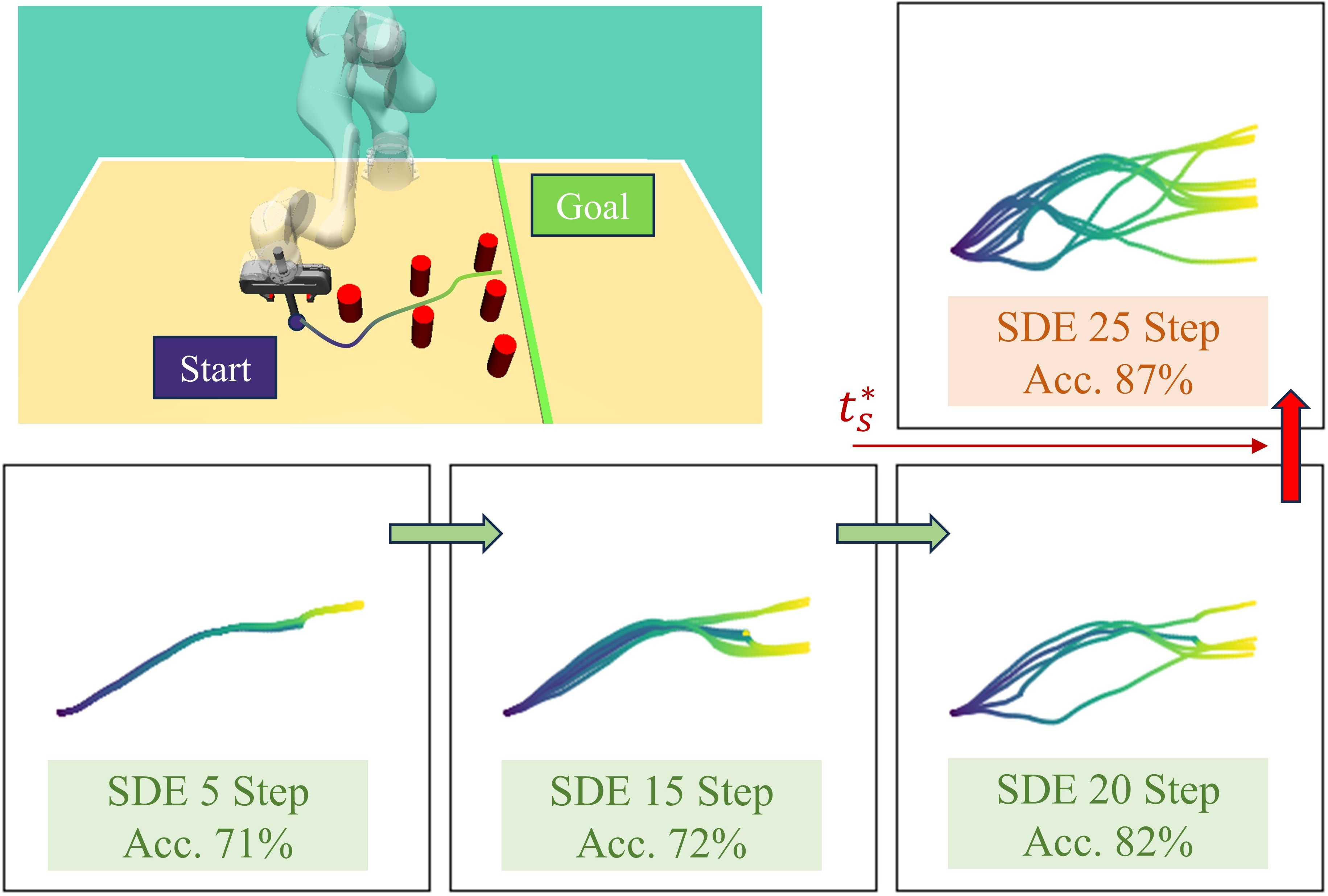
Figure 4: Multi-modal and optimal switch time in Avoiding-Sim: after ts∗, success is maximized and branches are stable, enabling effective one-step consistency jumps.
Experimental Evaluation
Simulation Results
HCP was evaluated on multi-modal simulation tasks (Push-T-Sim, Avoiding-Sim) and compared against DP-ddpm (80 steps) and DP-ddim (50 steps). HCP with a 25-step SDE prefix and one-step jump achieved a success rate of 75.5% and entropy of 1.50, closely matching DP-ddpm's multi-modal capacity while reducing inference steps by 68%. DP-ddim, while faster, suffered from mode collapse and lower entropy.
Real-World Robotic Manipulation
Experiments on a 7-DoF collaborative arm with multi-view visual inputs demonstrated HCP's efficacy in real-world multi-modal and single-modal tasks. HCP reduced per-sequence action generation time from 0.54s (DP-ddpm) to 0.17s, maintaining comparable success rates and multi-modal coverage. In tasks such as Push-T-Real and Avoiding-Real, HCP preserved multiple solution families and high entropy, outperforming DP-ddim in diversity and matching DP-ddpm in accuracy.
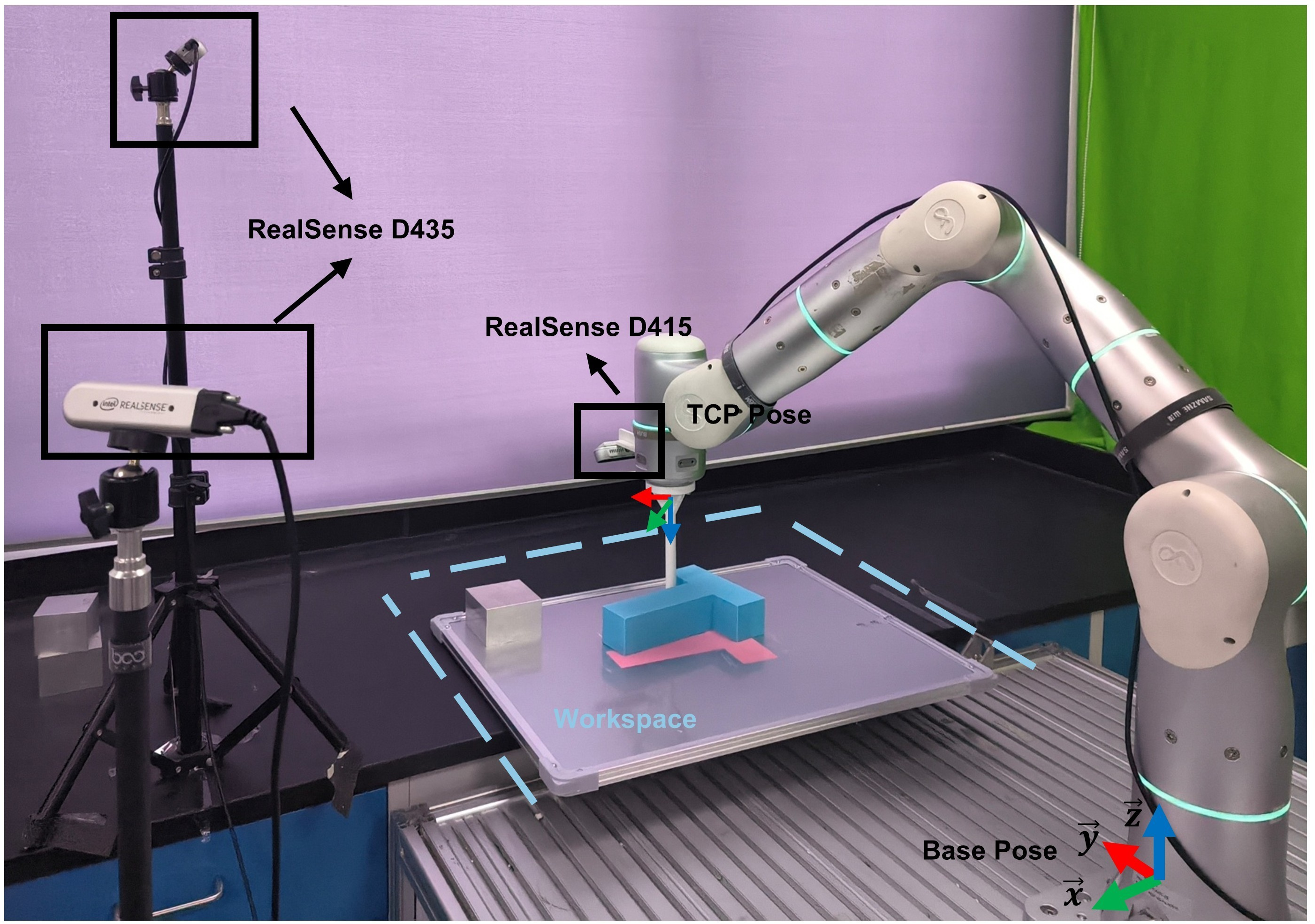
Figure 5: Real-world setup: 7-DoF arm with wrist and third-person cameras for multi-view observations.
Figure 6: Real-world tasks: (a)-(c) multi-modal, (d)-(f) single-modal, with demonstrations collected via VR teleoperation.

Figure 7: HCP achieves multiple modes in real-world multi-modal tasks, closely matching the teacher in accuracy and diversity.

Figure 8: HCP maintains high accuracy in single-modal tasks, performing comparably to the teacher.
Ablation Studies
Ablation on switch time revealed that early switching (short SDE prefix) leads to mode collapse and reduced success rates. Optimal switching at or after ts∗ preserves diversity and feasibility, with empirical results showing significant gains in accuracy and entropy for both simulation and real-world tasks.
Figure 6: Multi-modal and single-modal task demonstrations, highlighting the diversity captured by HCP.
Implications and Future Directions
HCP demonstrates that multi-modality in diffusion-based policies does not inherently require slow inference. By decoupling mode retention from sampling speed, HCP enables practical deployment of expressive policies on resource-constrained robotic platforms. The adaptive switch time mechanism provides a principled approach to balancing diversity and efficiency, with potential extensions to more complex embodied AI systems and scalable generative control.
Theoretically, HCP's hybrid approach suggests new directions for bridging stochastic and deterministic generative modeling, with implications for policy distillation, trajectory consistency, and mode promotion. Future work may focus on automating switch time selection, extending to higher-dimensional action spaces, and integrating with vision-language-action models for broader generalization.
Conclusion
Hybrid Consistency Policy introduces a robust framework for mode-preserving, efficient policy distillation in robotic manipulation. By combining a stochastic SDE prefix with a one-step ODE consistency jump, HCP achieves near-teacher performance in multi-modal coverage and accuracy while dramatically reducing inference latency. This work provides a generalizable recipe for accelerating diffusion-based policies without sacrificing expressivity, advancing the state-of-the-art in real-time, multi-modal robotic control.

