- The paper introduces InfoSeeker, a hierarchical agent framework that decomposes web search tasks into host, manager, and worker layers for scalable synthesis.
- It employs parallel processing at the worker level to reduce end-to-end latency by over 5-fold compared to sequential baselines.
- Empirical evaluations on WideSearch and BrowseComp-zh benchmarks show significant improvements in success rates and item-level accuracy.
Motivation and Problem Definition
The growing complexity of agentic web search tasks, particularly those requiring both deep multi-step reasoning and wide-scale information aggregation, exposes critical limitations in the architecture of current LLM-based agents. Existing systems typically fail under wide-context scenarios due to context window saturation, cascading error propagation inherent to sequential reasoning, and excessive task latency. Empirical results on benchmarks like WideSearch and BrowseComp-zh reveal that simply scaling model or context capacity is insufficient for robust, efficient web-scale information seeking.
Architecture: Hierarchical Near-Decomposability
The InfoSeeker framework is founded on the principle of near-decomposability, structuring agentic reasoning as a three-layer hierarchy composed of a strategic Host, domain-specialized Managers, and tool-executing Workers. The Host is responsible for global planning over compressed state in a strictly bounded context; Managers decompose high-level directives into parallelizable subtasks, perform aggregation, and implement validation and reflection cycles; Workers execute atomic tool interactions in isolation, returning only synthesized outputs for further aggregation.
This architecture enforces strict context isolation between layers, preventing both host-level context explosion and error propagation across reasoning horizons. Each Manager acts as an encapsulated module, enabling domain- or modality-specific aggregation strategies (e.g., for web search, browsing, or file operations), while Worker pools enable large-scale concurrent execution. The design adheres to a MapReduce-inspired model where decomposition and result aggregation are tightly controlled by the Manager layer.
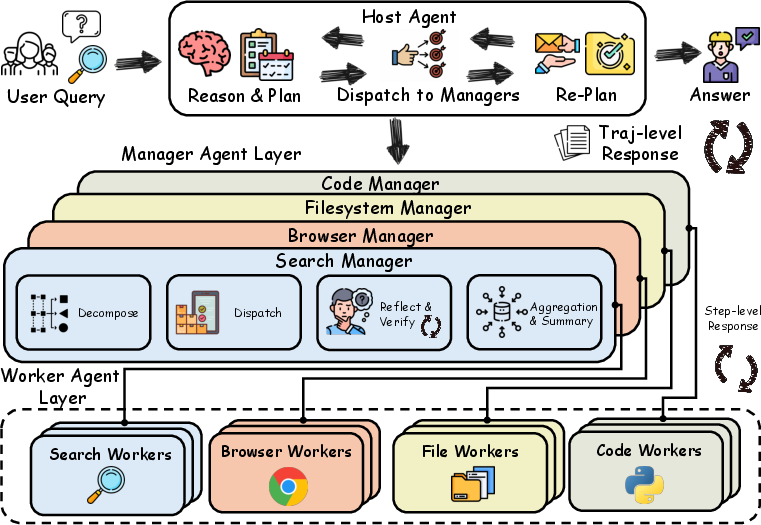
Figure 1: The InfoSeeker architecture consists of a strategic host, multiple managers, and parallel workers, isolating context and supporting decomposability for scalable planning.
This separation of concerns supports independent scaling of reasoning depth and execution width, permitting both long-horizon reasoning and broad information synthesis without saturating agent contexts.
Parallel Execution and Efficiency
InfoSeeker's parallelisation capabilities are realized primarily at the Worker layer, where large pools of subtasks can be executed concurrently with minimal coordination overhead. On typical WideSearch tasks, the system decomposes the input into dozens of subtasks and dispatches them across an expandable pool of Workers, with Managers orchestrating aggregation, redundancy elimination, and partial result synthesis. The Host aggregates step-level responses, ensuring that high-level planning remains agnostic to the scale and structure of Manager-internal computation.
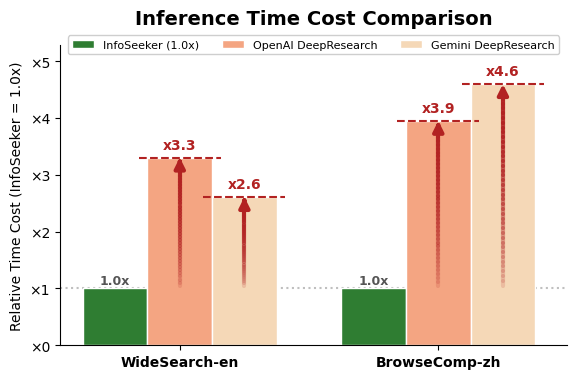
Figure 2: InfoSeeker's parallel execution yields more than a 2× reduction in end-to-end inference time compared to sequential baselines.
Empirical ablations demonstrate substantial efficiency improvements: scaling from a single Worker to a pool of 17 reduces end-to-end latency from 911 seconds to 162 seconds on WideSearch queries, a ≈5.7× acceleration. The observed wall-clock time saturates as the pool size grows, consistent with the theoretical maximum dictated by the slowest subtask execution. These findings establish that InfoSeeker's architecture efficiently unlocks parallel inference-time compute for width-heavy tasks.
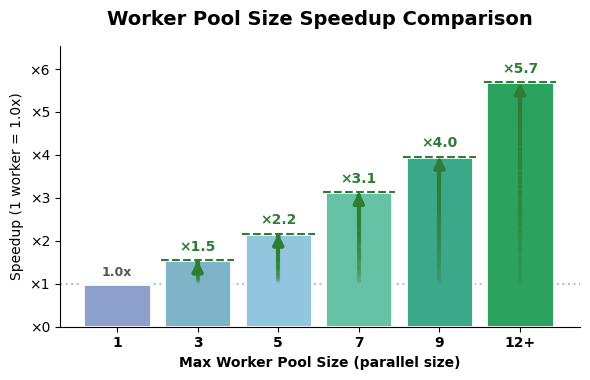
Figure 3: Increasing the worker pool size yields lower inference latency, elucidating the effect of parallelism on system throughput.
Empirical Evaluation and Results
The framework is evaluated on WideSearch (structured information synthesis over English and Chinese web content) and BrowseComp-zh (complex reasoning over the Chinese web ecosystem). On WideSearch, InfoSeeker achieves an Avg@4 success rate of 8.38%, representing a 64% increase over the best multi-agent baseline, and outpaces state-of-the-art commercial systems in both strict success and fine-grained F1 metrics. Item-level F1 reaches 75.11% (Max@4), a 13% improvement over competing frameworks. On BrowseComp-zh, InfoSeeker attains 52.9% accuracy, exceeding the strongest proprietary baseline by 10 points.
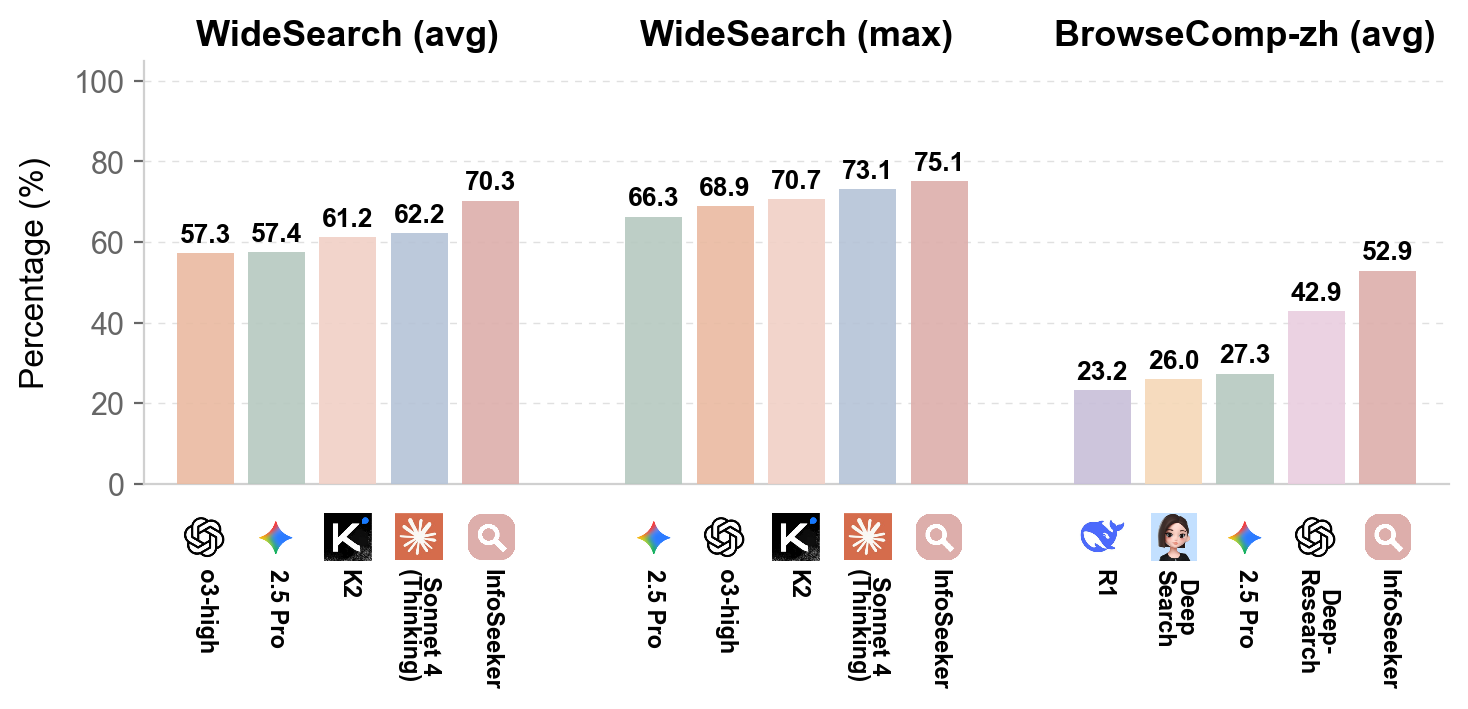
Figure 4: InfoSeeker achieves strong improvements over both WideSearch (English/Chinese) and BrowseComp-zh benchmarks, improving success and accuracy metrics.
Time efficiency is a defining advantage: compared to OpenAI and Gemini commercial deep research systems, InfoSeeker reaches 3.3× and 2.6× lower latencies, and these efficiency benefits are sustained in the linguistically distinct BrowseComp-zh, further validating the modularity and scalability of the approach.
Qualitative Analysis and Failure Modes
Case studies highlight InfoSeeker's ability to manage multi-source information requirements, dynamically balance search and browsing across independent managers, and degrade gracefully under context and execution constraints. For extremely high-volume aggregation tasks, the system identifies context limitations and generates partial outputs with traceable provenance, avoiding outright failure but exposing fundamental scalability limits of current LLM contexts. Additionally, when ambiguity exists in entity mapping under information-theoretic uncertainty, the architecture defaults to plausible candidate sets, revealing areas for future improvement in entity-level constraint resolution.
Implications, Theoretical and Practical
InfoSeeker's hierarchical decomposition and workflow-parallel execution provide architectural solutions to key pathologies in large-scale agentic search: context window explosion, error propagation in sequential chains, and compute-bound latency. By modularizing reasoning and execution domains and enforcing strict context isolation, the framework operationalizes principles from complex systems theory that have been largely unexploited in the LLM-agent setting. The design allows plug-and-play extensibility of domain-specialized managers and toolsets, which is crucial for transferring the approach to multimodal or multi-domain agentic tasks in production environments.
This architecture further opens avenues for automatic learning of decomposition and aggregation policies, as well as for cost-efficient deployments through specialized Worker pools and lightweight model variants. It motivates work on integrating dynamic agent routing, learned manager/worker roles, and fine-grained orchestration policies that go beyond prompt engineering.
Limitations and Potential Directions
Operational constraints include API rate limits, reliance on LLM backbones and tool integration, and continued dependence on hand-tuned prompts for task decomposition and aggregation. Addressing these will require advances in multi-agent coordination via RL, as well as training of manager and worker models that internalize both decomposition and aggregation strategies for specific domains.
The architecture also presumes that host-layer abstraction is sufficient for global planning, which may not hold in tasks requiring persistent memory, compositional symbolic reasoning, or robust handling of multi-modal evidence streams. Scalability to truly web-scale deep research tasks remains partially bottlenecked by context length and LLM throughput.
Conclusion
InfoSeeker demonstrates that hierarchical modularization and context-isolated, parallel execution constitute an effective and efficient approach for web information seeking agents confronting depth and width simultaneously. It provides both empirical and architectural evidence that large-scale information synthesis is tractable, not by scaling LLM size, but by aligning system architecture with principles of decomposability, bounded context expansion, and massive parallelization. Future developments in agentic frameworks will need to internalize these principles to achieve robust, generalizable, and efficient autonomous web research.

