- The paper formalizes deep research as Hierarchical Constraint Satisfaction Problems (HCSPs), establishing a recursive tree-based approach for multi-level reasoning.
- It introduces InfoSeek, a dual-agent framework that extracts and validates unstructured data into over 50K QA pairs using controlled synthesis techniques.
- Empirical results show that InfoSeeker-3B outperforms larger models on multi-hop and deep research tasks with fewer search calls and enhanced verifiability.
Open Data Synthesis For Deep Research: A Technical Analysis
The paper introduces a rigorous formalization of Deep Research tasks as Hierarchical Constraint Satisfaction Problems (HCSPs), distinguishing them from classical single-hop, multi-hop, and flat CSP formulations. In HCSPs, the solution emerges only through progressive resolution of a hierarchy of interdependent constraints, represented as a research tree. Each node in the tree corresponds to a knowledge entity or fact, and edges encode logical dependencies. This structure enforces multi-level reasoning, where intermediate sub-questions must be solved and integrated to converge on a unique, verifiable answer.
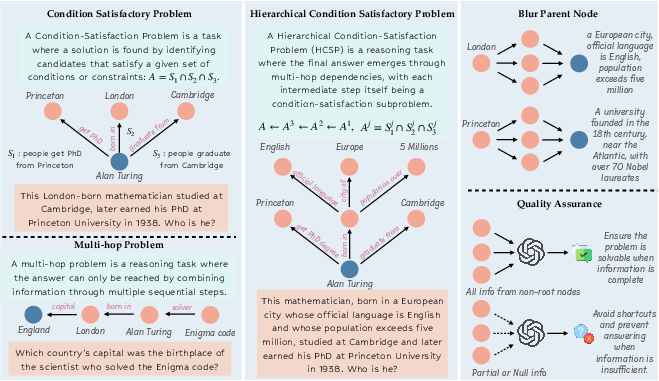
Figure 1: HCSPs formalize Deep Research as hierarchical, verifiable questions; the right panel illustrates the blurred parent node technique and quality assurance in InfoSeek synthesis.
The formalization is mathematically grounded, with the answer A defined recursively as A=H(qH), where H(⋅) denotes hierarchical decomposition over constraints and sub-questions. The approach generalizes both CSPs and multi-hop problems as special cases, but imposes stricter requirements for structural depth and logical interdependence. The paper also addresses potential issues in tree-based HCSP construction, such as underdetermination and overdetermination, and proposes data construction techniques to mitigate these.
InfoSeek: Scalable Data Synthesis Framework
To operationalize HCSPs, the authors present InfoSeek, a dual-agent data synthesis framework that autonomously generates large-scale Deep Research datasets from unstructured web and Wikipedia corpora. The Planner agent orchestrates tree construction, balancing sequential and parallel reasoning complexity, while the Browser agent executes targeted expansions by extracting entities, hyperlinks, and atomic claims.
The synthesis pipeline consists of four actions: initialization from research anchors, blurring parent nodes with constraints, vertical tree extension, and controlled termination. The blurring technique ensures that parent nodes are enriched with sufficient constraints to guarantee answer uniqueness and prevent shortcut reasoning. The framework is highly scalable, yielding over 50K QA pairs and 16.5K reasoning trajectories, with explicit evidence traces for verifiability.
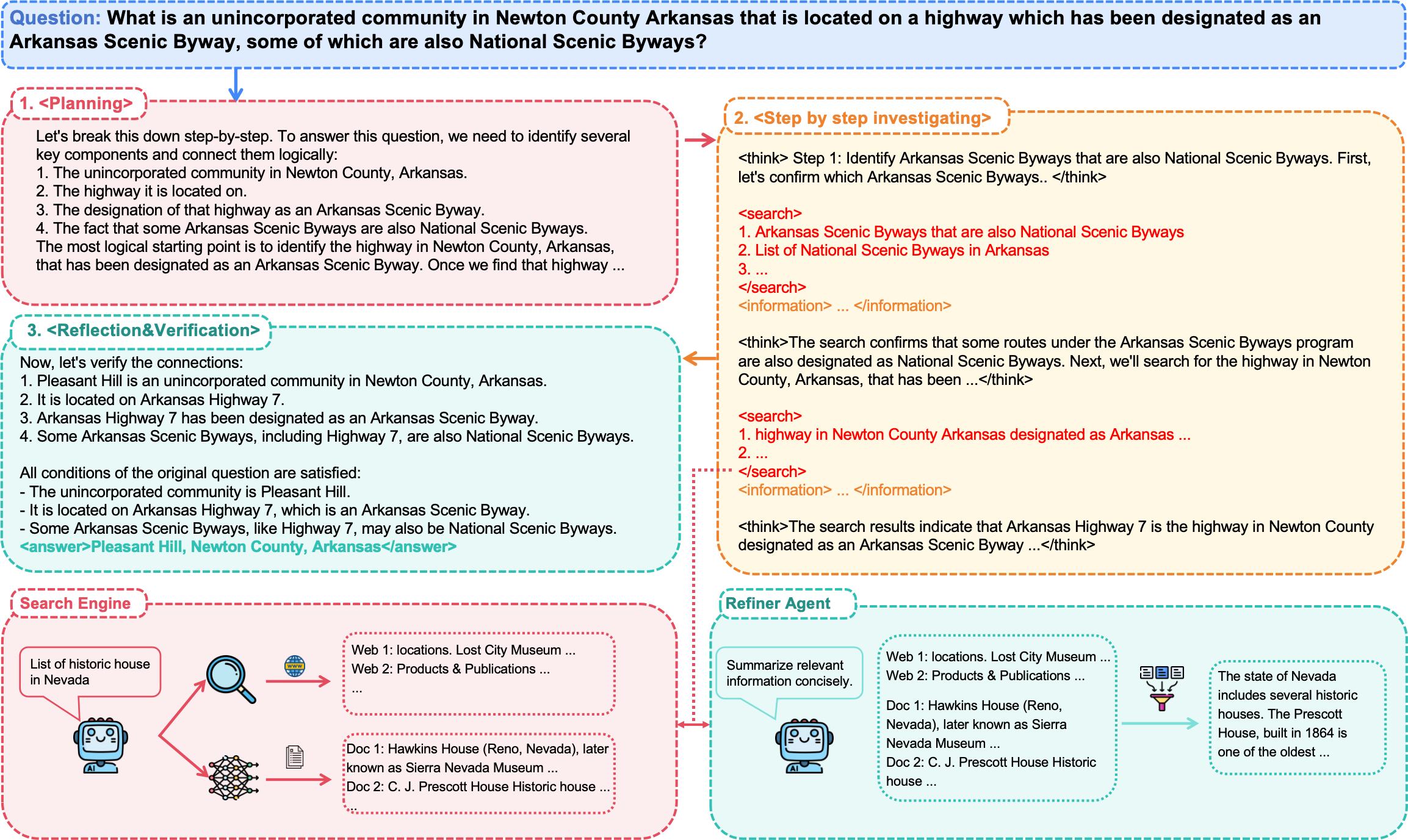
Figure 2: InfoSeeker decomposes tasks, conducts stepwise investigation, and synthesizes answers via Search Engine and Refiner Agent coordination.
A rigorous two-pronged quality assurance protocol is implemented: difficulty is validated by challenging strong LLMs (Qwen2.5-32B-Inst), and verifiability is ensured by requiring that answers be derivable from provided search paths using Gemini 2.5 Flash. Only 2% of questions are answerable by Qwen2.5-32B-Inst, and ambiguous or unsolvable samples are filtered out, resulting in a dataset with a 92.7% failure rate for Qwen2.5-72B under CoT prompting, strongly correlating with tree depth.
Agentic Search and Training Methodology
The InfoSeeker agentic framework features parallel multi-query search and a dedicated Refiner Agent, which condenses retrieved evidence into concise summaries, maintaining high recall while controlling context bloat. Each reasoning turn is structured with explicit "think" phases, parallelized search, and information refinement, culminating in answer synthesis.
Supervised fine-tuning (SFT) is performed using rejection sampling to construct high-quality reasoning trajectories, followed by reinforcement learning (RL) with Group Relative Policy Optimization (GRPO). The RL reward is binary, requiring both correct format and answer extraction. The training pipeline leverages knowledge distillation from a large teacher model (Qwen2.5-72B), two rounds of SFT and RL, and rejection sampling with Gemini 2.5 Flash validation.
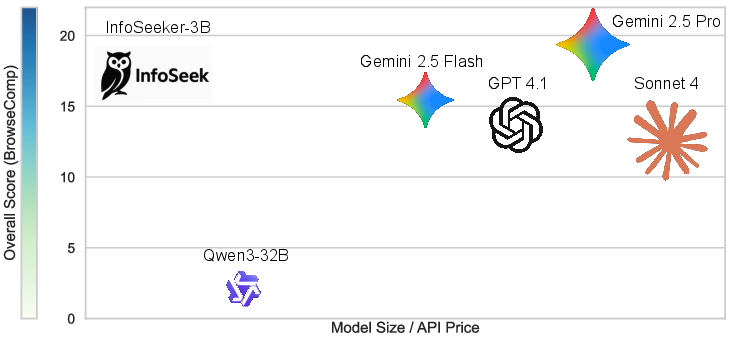
Figure 3: InfoSeeker-3B, trained on InfoSeek, outperforms Qwen3-32B and matches leading commercial LLMs on BrowseComp-Plus, with open-source data synthesis.
Empirical Results and Comparative Analysis
InfoSeeker-3B, a compact 3B-parameter LLM trained on InfoSeek, consistently outperforms strong baselines on both single-hop and multi-hop QA benchmarks, as well as advanced Deep Research tasks. On the BrowseComp-Plus benchmark, InfoSeeker-3B achieves 16.5% accuracy, surpassing Qwen3-32B and commercial APIs such as Gemini 2.5 Flash, Sonnet 4, and GPT-4.1, and approaching Gemini 2.5 Pro. Notably, InfoSeeker-3B requires only 8.24 search calls per problem, indicating efficient tool use.
Training on InfoSeek yields substantially stronger Deep Research performance compared to NQ+HotpotQA, with a fivefold increase in accuracy on BrowseComp-Plus (16.5% vs. 3.0%). The dataset's structural diversity and complexity control are validated by the strong positive correlation between tree depth and model failure rate.
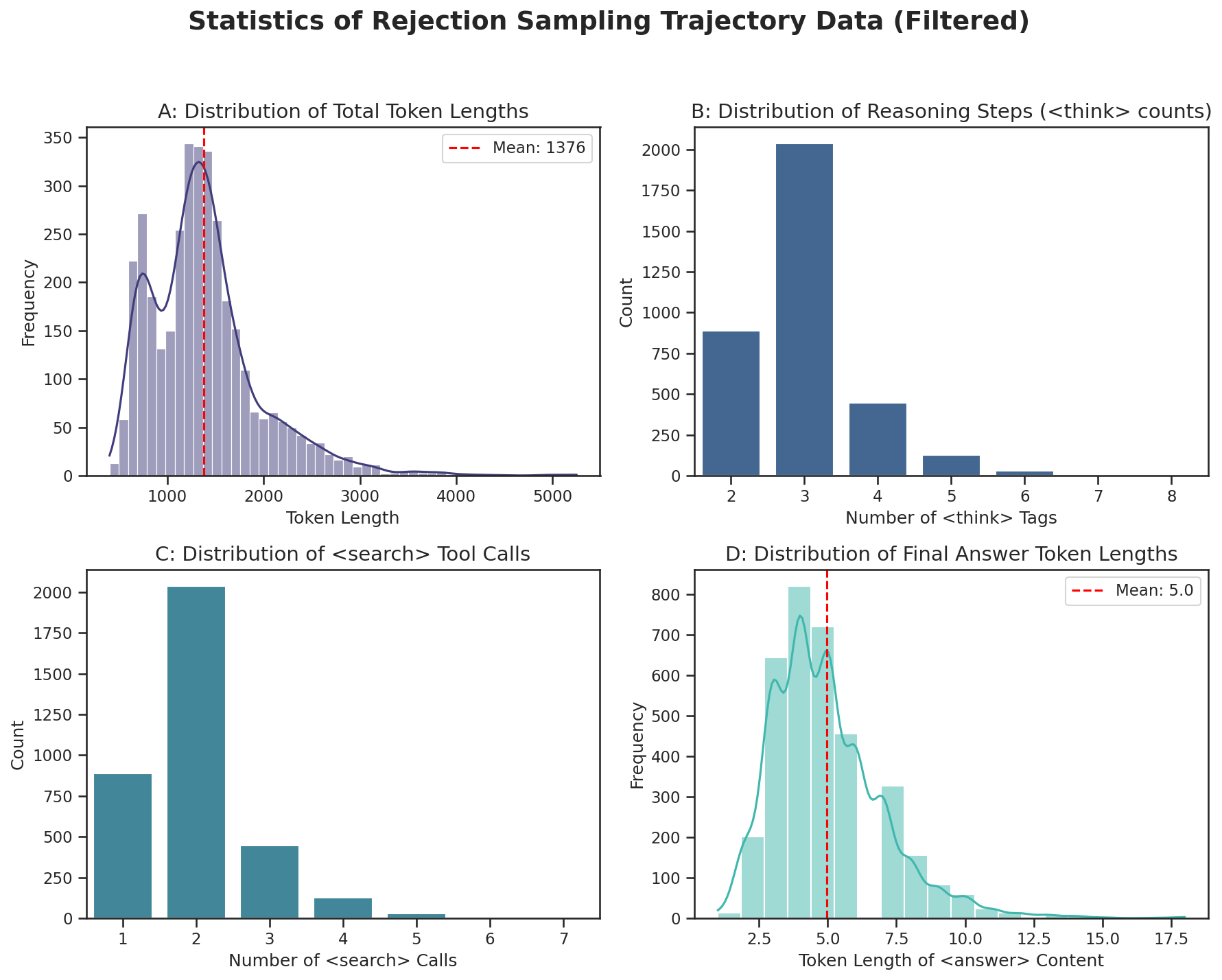
Figure 4: Distribution and statistics for SFT trajectory data, highlighting the scale and complexity of InfoSeek.

Figure 5: Research tree structure for Case One in InfoSeek, illustrating hierarchical reasoning paths.

Figure 6: Research tree structure for Case Two in InfoSeek, demonstrating multi-level constraint integration.
Implications and Future Directions
The formalization of Deep Research as HCSPs and the scalable synthesis of structurally complex, verifiable datasets represent a significant advance in training agentic LLMs for open-ended reasoning. The empirical results demonstrate that compact models can be endowed with robust Deep Research capabilities through principled data-centric pipelines, outperforming much larger models and commercial systems.
The preservation of meta-information (intermediate steps, retrieval labels) in InfoSeek enables advanced optimization strategies, such as compound reward design and trajectory-level exploration. This opens avenues for research in hierarchical RL, curriculum learning, and meta-reasoning. The open-source release of the framework and dataset facilitates reproducibility and further development in the community.
Theoretically, the HCSP formalism provides a foundation for analyzing and benchmarking reasoning depth, logical interdependence, and verifiability in LLMs. Practically, the InfoSeek pipeline can be extended to other domains requiring complex, multi-step synthesis, such as scientific discovery, policy analysis, and autonomous tool use.
Conclusion
The paper establishes a principled framework for Deep Research with LLMs by formalizing tasks as HCSPs and introducing InfoSeek, a scalable, open-source data synthesis paradigm. Through rigorous quality assurance and agentic training pipelines, InfoSeeker-3B demonstrates strong performance on challenging benchmarks, validating the effectiveness of structurally complex, verifiable data for enabling advanced reasoning. The work lays the groundwork for future research in hierarchical reasoning, agentic search, and data-centric optimization of LLMs.