- The paper introduces MPropositionneur-V2 and shows that using atomic propositions increases relation recall by up to 10 points on benchmarks like SMiLER.
- The method employs a three-stage pipeline—atomization, triplet extraction, and knowledge graph construction—demonstrating modular integration with various extractors.
- The approach improves interpretability and supports multilingual, low-resource extraction, thereby enhancing explainable AI in information retrieval tasks.
Introduction
This paper presents a rigorous empirical investigation into the utility of leveraging atomic propositions—minimal, semantically autonomous units—for enhancing relation and triplet extraction from natural language. The work introduces MPropositionneur-V2, a compact multilingual propositioner model distilled from Qwen3-32B into a Qwen3-0.6B backbone, and evaluates its efficacy in integration with both entity-centric (GLiREL) and generative (Qwen3) triplet extractors across a suite of benchmarks. The central claim is that the explicit decomposition of sentences into atomic propositions serves as an interpretable, modular intermediate, particularly elevating recall in weaker extractors and contributing to overall performance in low-resource or multilingual scenarios.
The atomic proposition methodology is grounded in the formalism of Carnap-Bar Hillel Semantic Information Theory, providing an information-theoretic criterion for the decomposition of complex, information-dense sentences into atomic units. In this framework, only conjunctions are decomposed, as splitting disjunctions or implications would hallucinate information. The implementation relies on recursive prompting with MPropositionneur-V2; decomposition continues until fixed-points are reached or a depth bound is satisfied.
The overall pipeline comprises three principal stages:
- Atomization: The input is decomposed into atomic propositions using MPropositionneur-V2, which incorporates coreference resolution and is trained on a multilingual Wikipedia corpus.
- Triplet Extraction: Each atomic proposition is processed to extract (subject,relation,object) triplets. Extraction is performed via either dependency/parser-based approaches (e.g., GLiREL) or zero/few-shot generative LLM prompts (e.g., Qwen3-based).
- Knowledge Graph Construction: Extracted triplets are aggregated into a structured graph.
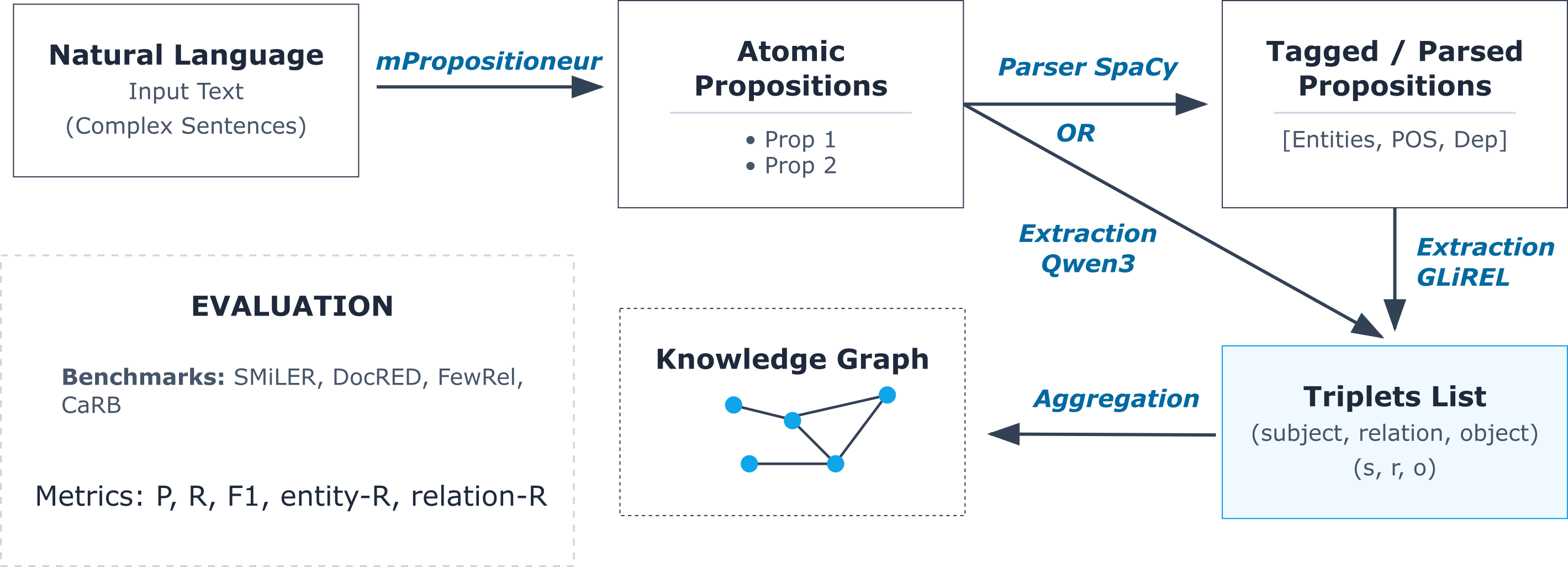
Figure 1: Schematic of the pipeline for atomic proposition extraction and triplet-based KG construction.
Empirical Evaluation
Rigorous experiments are conducted on SMiLER (multilingual relation extraction), FewRel, DocRED, and CaRB benchmarks. Both rule-based and LLM-based triplet extractors are benchmarked under direct (raw text), prop (atomized text), and combined or union modes.
Key findings include:
- Relation Recall Gains: Introduction of atomic propositions consistently boosts relation recall for weaker extractors (GLiREL, CoreNLP, small LLMs). For instance, on SMiLER, macro-averaged relation recall increased by up to 10 points when using atomized input compared to direct extraction.
- Entity Recall Tradeoff: Entity recall sometimes drops due to over-splitting (loss of global context or co-reference) but is recoverable via combined pipelines that fallback to direct extraction when atoms fail to supply candidates.
- Model Scaling: Large LLMs (e.g., Qwen3-4B) outperform propositioner methods in the document-scale setting (e.g., DocRED) on precision and F1, but at significant compute cost.
- Combined Pipelines: Fallback combinations (raw + atomized) achieve statistically significant improvements in accuracy for weak extractors, validating the complementarity hypothesis.
Qualitative Behavior and Interpretability
Atomic propositions render intermediate representations more interpretable and inherently auditable. The flattening of complex linguistic structures removes dependencies and obscured relations; however, some transitive relations may not appear directly in extracted triplets but can be inferred by graph traversal due to the compositional properties of the atomicized representation.
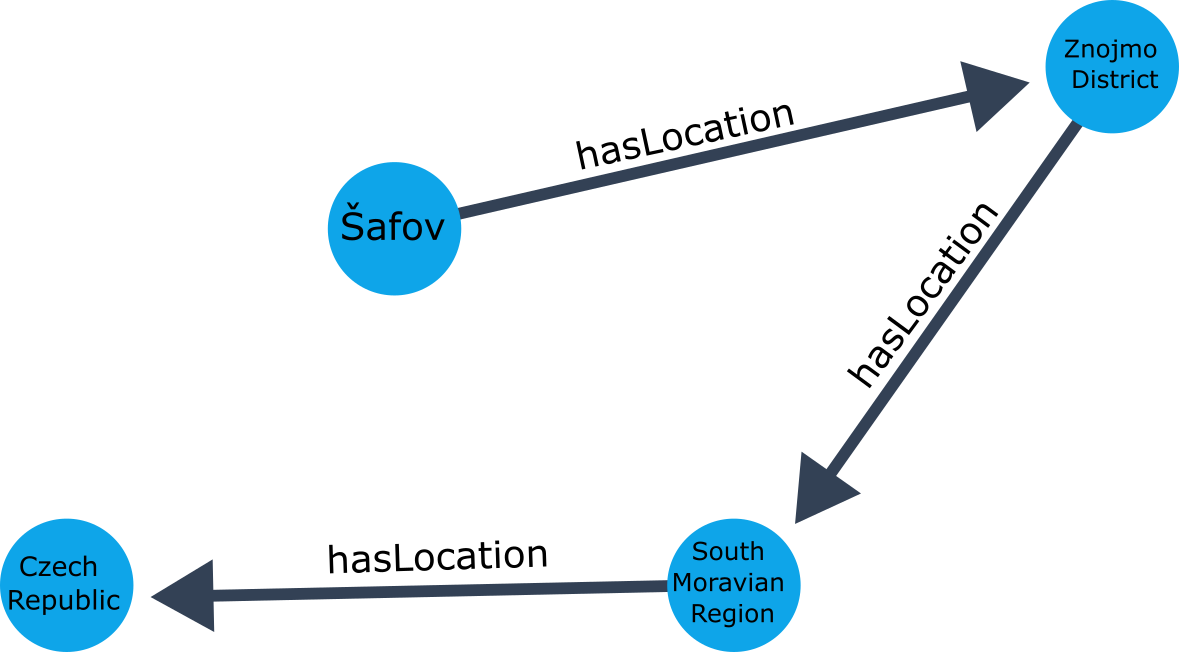
Figure 2: Knowledge graph from triplets extracted by GLiREL from atomic propositions, illustrating explicit entity-relational structure.
This property is theoretically justified by the formal properties of atomic propositions in CNF, ensuring that no informational “hallucinations” occur and that higher-order or implied relations can still be recovered via KG inference routines.
Practical and Theoretical Implications
The study demonstrates that atomic proposition intermediates provide interpretable scaffolding for relation extraction—valuable for downstream tasks such as KGs, fact-checking, information retrieval, and explainable NLU/IE pipelines. In practical terms:
- Multilingual/Low-Resource Extraction: The propositioner generalizes well to multiple languages without need for language-specific rules due to multilingual LLM distillation.
- Explainability: Each extracted fact is directly tied to a minimal, human-auditable atomic unit, supporting audit, fact-check, and trace for high-stakes applications.
- Model Integration: The approach is modular; atomic propositions can be slotted into various extractor architectures without architectural changes.
From a theoretical perspective, the employment of atomic propositions under semantic information theory constraints ensures minimal and lossless representations, avoiding common pitfalls in rule-based “sentence simplification.” This approach introduces a formal bridge between logical tractability (via CNF atomicity) and neural NLP pipelines.
Future Directions
Future research directions include:
- Full human evaluation of propositioner atomicity to verify conformance with formal atomicity criteria.
- Exploration of larger LLMs both for propositioning and triplet extraction, with focus on compute/performance tradeoffs.
- Enhanced graph-inference algorithms exploiting the inferable properties of atomic frameworks to recover latent relations omitted in surface triplet extraction.
- Application to knowledge-based retrieval, fact verification, summary evaluation, and RAG systems for better robustness and explainability.
Conclusion
This work empirically validates the hypothesis that explicit decomposition of text into atomic propositions serves as a high-utility, interpretable intermediate for triplet extraction from natural language. The methods proffered enable improved recall (especially for weak extractors and multilingual inputs) and facilitate modular integration with both parser-based and LLM-based pipelines. The interpretability and formal grounding of atomic propositions create new possibilities for explainable and auditable information extraction systems, with broad potential for future AI research and industrial applications.

