Beyond Chunks and Graphs: Retrieval-Augmented Generation through Triplet-Driven Thinking (2508.02435v1)
Abstract: Retrieval-augmented generation (RAG) is critical for reducing hallucinations and incorporating external knowledge into LLMs. However, advanced RAG systems face a trade-off between performance and efficiency. Multi-round RAG approaches achieve strong reasoning but incur excessive LLM calls and token costs, while Graph RAG methods suffer from computationally expensive, error-prone graph construction and retrieval redundancy. To address these challenges, we propose T$2$RAG, a novel framework that operates on a simple, graph-free knowledge base of atomic triplets. T$2$RAG leverages an LLM to decompose questions into searchable triplets with placeholders, which it then iteratively resolves by retrieving evidence from the triplet database. Empirical results show that T$2$RAG significantly outperforms state-of-the-art multi-round and Graph RAG methods, achieving an average performance gain of up to 11\% across six datasets while reducing retrieval costs by up to 45\%. Our code is available at https://github.com/rockcor/T2RAG
Summary
- The paper introduces a novel retrieval-augmented generation framework, T²RAG, that leverages atomic triplets to improve multi-hop reasoning while reducing computational overhead.
- It details a graph-free approach with offline indexing and iterative online retrieval, which minimizes LLM calls and token consumption compared to traditional methods.
- Experimental results demonstrate state-of-the-art performance on diverse QA benchmarks, showing significant gains in accuracy and efficiency.
Triplet-Driven Thinking for Retrieval-Augmented Generation
The paper "Beyond Chunks and Graphs: Retrieval-Augmented Generation through Triplet-Driven Thinking" (2508.02435) introduces T2RAG, a novel retrieval-augmented generation (RAG) framework. T2RAG aims to improve the performance and efficiency of RAG systems by operating on a knowledge base of atomic triplets, thereby circumventing the computational overhead and potential inaccuracies associated with multi-round and graph-based RAG methods. The paper demonstrates that T2RAG achieves state-of-the-art performance across various question answering benchmarks, accompanied by significant reductions in retrieval costs.
Introduction to T2RAG
RAG has become a crucial paradigm for mitigating hallucinations and incorporating external knowledge into LLMs. However, existing RAG systems often face a trade-off between performance and efficiency. Multi-round RAG approaches, while achieving strong reasoning capabilities, incur excessive LLM calls and token costs. Graph RAG methods, on the other hand, suffer from computationally expensive and error-prone graph construction, as well as retrieval redundancy.
T2RAG addresses these challenges by operating on a simple, graph-free knowledge base of atomic triplets. It decomposes questions into searchable triplets with placeholders, which it then iteratively resolves by retrieving evidence from the triplet database. This approach aims to maintain a balance between multi-hop reasoning and computational efficiency.
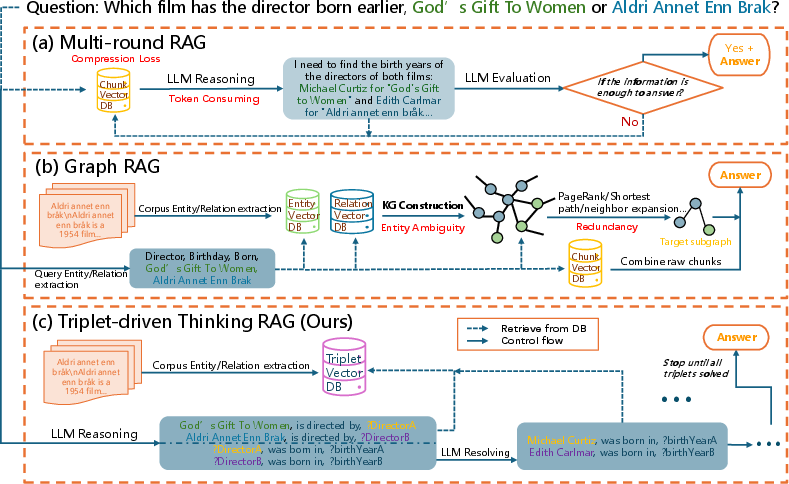
Figure 1: A comparison of three RAG paradigms, with their primary challenges highlighted in red.
Methodology
The T2RAG framework operates in two primary stages: offline indexing and online retrieval.
Offline Indexing: Graph-Free Knowledge Base Construction
The offline indexing stage focuses on transforming a raw text corpus into a searchable knowledge base of atomic propositions. This involves two key steps:
- Canonical Triplet Generation: An information extraction model extracts knowledge triplets from the text corpus, formalizing each triplet as a (subject, predicate, object) tuple.
- Triplet Embedding: The extracted triplets are converted into natural language sentences (propositions) and encoded into dense vector representations using a high-performance embedding model. These vectors are then indexed using a vector search library to enable rapid similarity search.
Online Retrieval: Iterative Triplets Resolution
The online retrieval stage involves an iterative process of resolving triplets to answer user queries. This process consists of three main steps:
- Structured Query Decomposition: An LLM decomposes the input query into a set of atomic knowledge triplets, with placeholders for unknown entities. These triplets are categorized into resolved, searchable, and fuzzy triplets based on the number of placeholders.
- Multi-Round Triplet Resolution: The system iteratively retrieves context to resolve the searchable and fuzzy triplets. This involves converting the triplets into query propositions, embedding them, and querying the proposition index. The retrieved context is then used by an LLM to populate the placeholders within the triplets.
- Final Answer Synthesis: Once the iterative loop terminates, the resolved triplets are aggregated, and a final LLM call is made to generate the answer, conditioned on whether all triplets were successfully resolved.
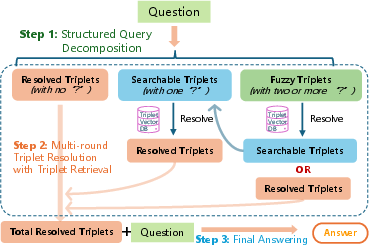
Figure 2: Online retrieval stage of T2RAG.
Experimental Results
The paper presents a comprehensive evaluation of T2RAG across various question answering datasets, including simple QA, multi-hop QA, and domain-specific QA. The results demonstrate that T2RAG achieves state-of-the-art performance, outperforming leading models in both multi-round RAG and graph RAG.
Performance Against Baselines
T2RAG demonstrates superior overall performance, leading in both average EM and F1 scores across different LLM backbones. Its advantage is particularly pronounced in multi-hop QA datasets, where it surpasses both single-round baselines and the multi-round baseline, IRCoT.
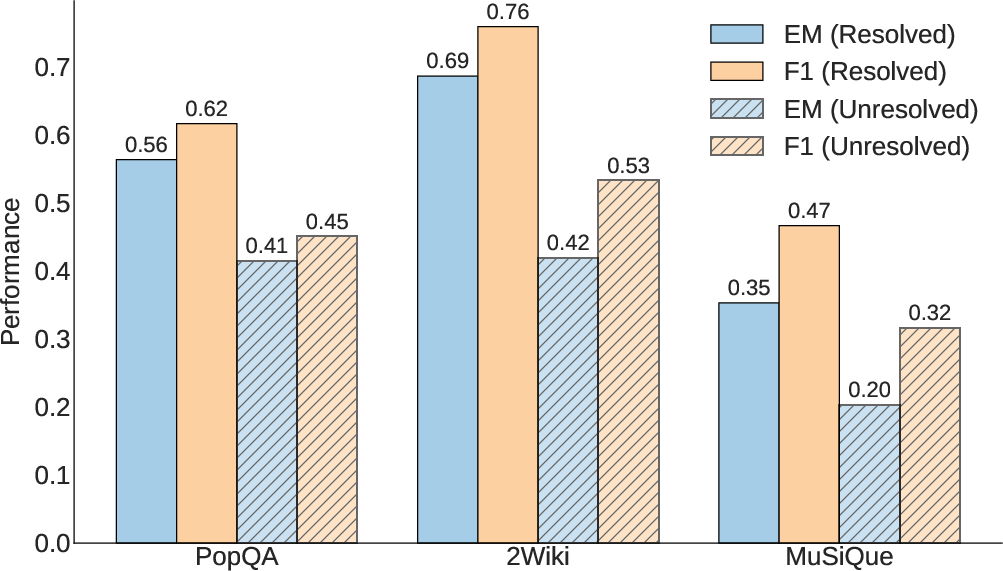
Figure 3: Performance vs. final resolution status.
Impact of Triplet Resolution
The paper analyzes the impact of the triplet resolution module by comparing performance based on whether the query's underlying triplets are fully resolved. The results reveal a significant performance delta between resolved and unresolved questions, confirming the importance of successful triplet resolution.
Computational Efficiency
The paper compares the computational cost of T2RAG with baselines during both offline indexing and online retrieval. T2RAG exhibits comparable indexing costs to other graph-based RAG methods. Moreover, its retrieval stage demonstrates remarkable efficiency, with significantly lower time and token consumption compared to multi-round baselines.
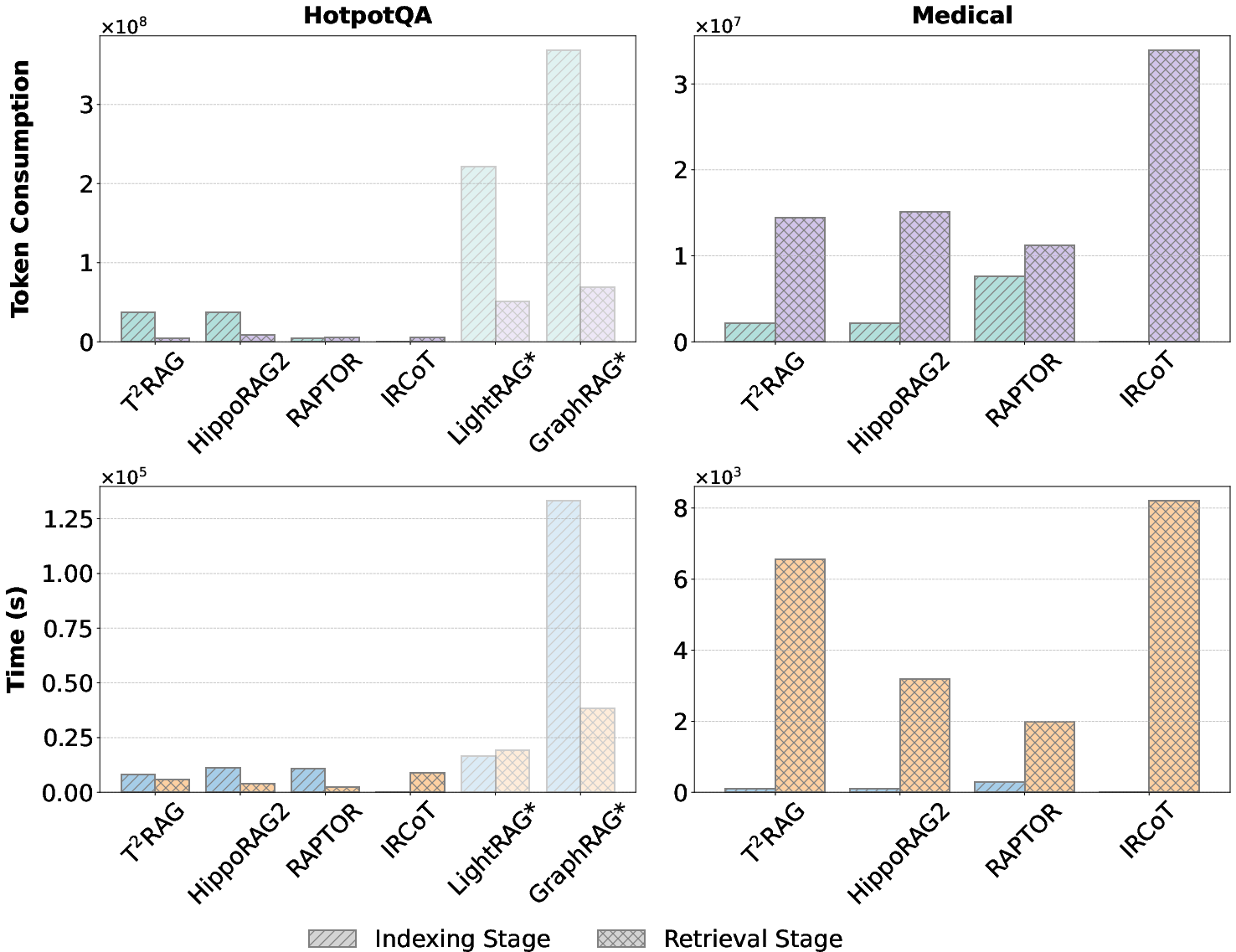
Figure 4: Comparison of token consumption and time. Token consumption is calculated by (input + 4timesoutput). Results of LightRAG and GraphRAG are from a benchmark~\cite{zhou2025depth}.
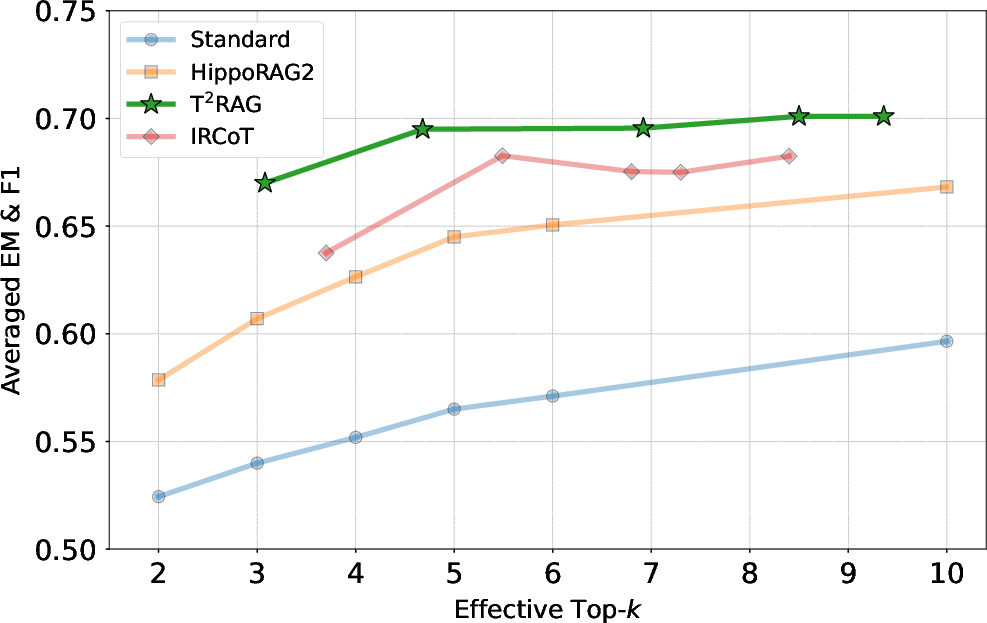
Figure 5: Performance vs. top-k. Multi-round methods are calibrated by k× average number of iterations.
Scaling with Context
The paper investigates how T2RAG's performance scales with context size by varying the number of retrieved documents. The results demonstrate that T2RAG's performance is consistently high and robust to the value of top-k, indicating that its effectiveness does not rely on scaling up the volume of retrieved text.
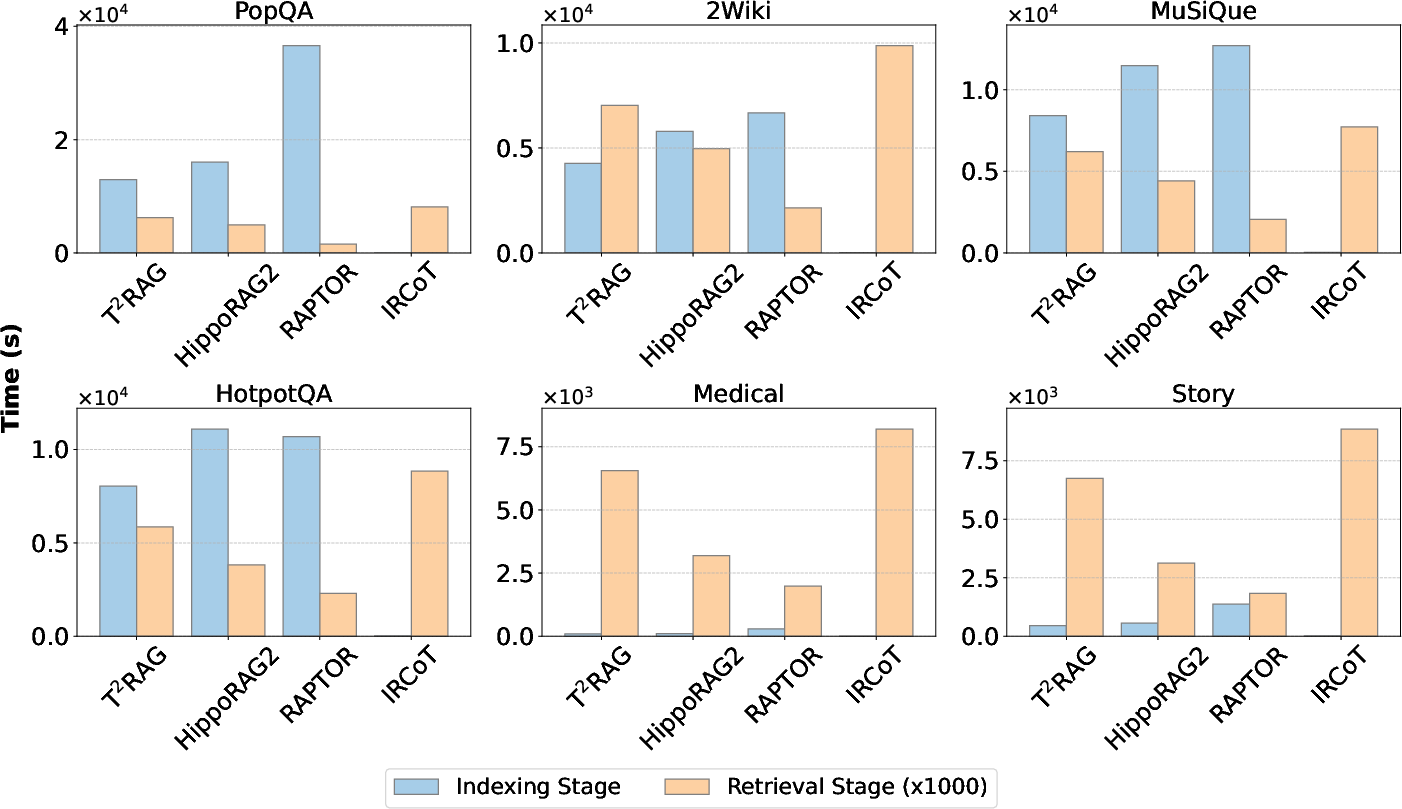
Figure 6: Time consumption at indexing and retrieval stages across all datasets.
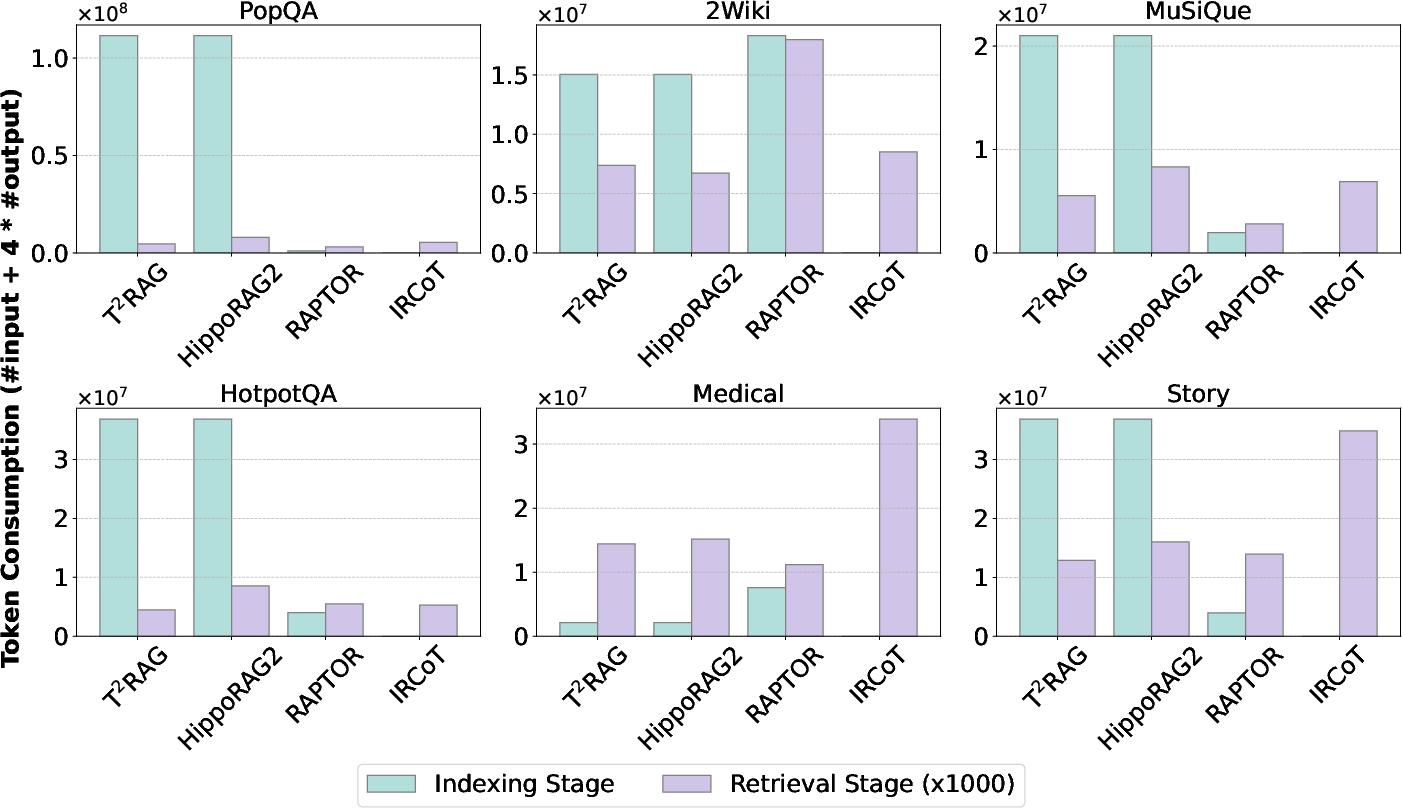
Figure 7: Token consumption at indexing and retrieval stages across all datasets.

Figure 8: An example of T2RAG QA. To answer the question, we need intermediate facts about Michael Curtiz (marked by yellow) and Edith Carlmar (marked by red).
Implications and Future Directions
T2RAG's ability to leverage atomic facts and iteratively resolve triplets has significant implications for the development of more accurate and efficient RAG systems. By moving away from unstructured context retrieval and toward a reasoning-driven synthesis of atomic facts, T2RAG paves the way for a new paradigm in RAG research.
Future research directions may include exploring hypergraph modeling to represent more complex knowledge relationships, improving the efficiency of triplet extraction, and developing methods for incremental updates to the triplet database.
Conclusion
The T2RAG framework represents a significant advancement in the field of retrieval-augmented generation. By embedding reasoning directly into the retrieval process and operating on a knowledge base of atomic triplets, T2RAG achieves state-of-the-art performance with remarkable efficiency. This work highlights the potential of shifting the RAG paradigm from retrieving and generating unstructured contexts toward a more deliberate, reasoning-driven synthesis of atomic facts.
Follow-up Questions
- How does T²RAG handle multi-round reasoning compared to traditional RAG systems?
- What are the advantages of using a graph-free, triplet-based knowledge base in retrieval tasks?
- In what ways does the iterative triplet resolution improve the overall system performance?
- How do the computational costs and token consumption of T²RAG compare with other RAG paradigms?
- Find recent papers about retrieval-augmented generation.
Related Papers
- MultiHop-RAG: Benchmarking Retrieval-Augmented Generation for Multi-Hop Queries (2024)
- RQ-RAG: Learning to Refine Queries for Retrieval Augmented Generation (2024)
- GNN-RAG: Graph Neural Retrieval for Large Language Model Reasoning (2024)
- Searching for Best Practices in Retrieval-Augmented Generation (2024)
- Think-on-Graph 2.0: Deep and Faithful Large Language Model Reasoning with Knowledge-guided Retrieval Augmented Generation (2024)
- EfficientRAG: Efficient Retriever for Multi-Hop Question Answering (2024)
- Plan*RAG: Efficient Test-Time Planning for Retrieval Augmented Generation (2024)
- KiRAG: Knowledge-Driven Iterative Retriever for Enhancing Retrieval-Augmented Generation (2025)
- Hierarchical Lexical Graph for Enhanced Multi-Hop Retrieval (2025)
- Graph-R1: Towards Agentic GraphRAG Framework via End-to-end Reinforcement Learning (2025)
Authors (4)
alphaXiv
- Beyond Chunks and Graphs: Retrieval-Augmented Generation through Triplet-Driven Thinking (1 like, 0 questions)