- The paper presents AtomEval, a framework that decomposes claims into atomic propositions and applies hard binary gating alongside soft semantic degradation scoring.
- It reveals that conventional metrics like ASR and surface similarity often misclassify adversarial rewrites by neglecting subtle semantic shifts.
- Empirical results on the FEVER benchmark show that even strong LLMs can yield high textual similarity while producing semantically invalid paraphrases.
AtomEval: Atomic-Scale Validity Assessment in Adversarial Claim Fact Verification
The increasing deployment of automated fact verification systems in information-critical domains has led to a surge in adversarial evaluation, particularly adversarial claim rewriting. While state-of-the-art LLM-based generators are able to produce adversarial paraphrases that fool current verifiers, standard evaluation protocols—centering on label flip (attack success rate, ASR) and surface or sentence-level similarity (e.g., SBERT, BLEU)—fail to determine whether adversarial edits preserve the original claim's semantic meaning. This oversight results in the systematic misclassification of semantically corrupted or drifted attacks as "successful," especially in cases where adversarial rewrites move toward the evidence-supported fact, hallucinate, or inject contradictions.
AtomEval addresses this evaluation gap by introducing atomic validity-aware metrics. The framework decomposes claim-rewrite pairs into structured atomic propositions (SROM tuples) and implements both hard binary validity gating and soft semantic degradation scoring to rigorously distinguish legitimate adversarial manipulations from factually corrupting ones.
Framework Overview and Methodology
AtomEval is instantiated as a modular pipeline that, for a given original claim, its retrieved evidence, and a candidate adversarial rewrite, extracts corresponding atomic facts and evaluates the transformation at the proposition level rather than relying on aggregate surface metrics.
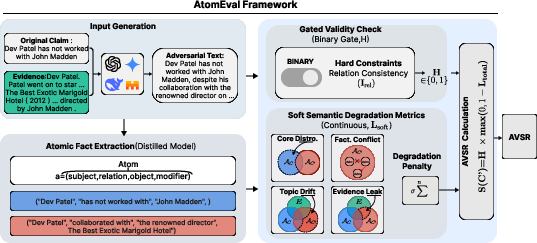
Figure 2: Overview of AtomEval—original and adversarial claims and evidence are decomposed into atomic SROM facts; rewrites are evaluated through a hard structural gate and interpretable soft semantic degradation metrics.
Atomic Fact Decomposition
Claims and rewrites are parsed into minimal verifiable units using a domain-tuned SROM (Subject–Relation–Object–Modifier) tuple extractor. Extraction reliability is empirically validated (F1 ≈ 0.77), outpacing both large-scale LLM and smaller LLM baselines. This enables fine-grained, interpretable error detection: surface-matched text can be differentiated from subtle semantic drift through explicit role mapping in atomic tuples.
Validity Assurance: Hard Binary and Soft Degradation Signals
- Hard validity gate (Relation Consistency): A binary constraint is imposed—an adversarial rewrite is only accepted as valid if, for every atomic fact, at most one of the four SROM roles is altered (the “minimal edit” constraint), thereby disqualifying rewrites exhibiting role or polarity reversal, subject or object swaps, or relational tampering.
- Soft degradation metrics: For structurally valid rewrites, AtomEval computes a weighted sum of interpretable semantic corruption signals:
- Core Distortion: Loss of original atomic facts
- Fact Conflict: Internal contradictions in rewritten SROMs
- Topic Drift: Introduction of atoms not present in the original or evidence
- Evidence Leakage: Direct copying of factual atoms from evidence absent in the original
The final validity score compounds these (with explicit weights), and the system sharply separates legitimate adversarial paraphrase from semantically invalid generation.
Experimental Analysis
Evaluation Setup
Experiments are conducted on the FEVER benchmark, focusing on "refuted" claims. Adversarial generators include both proprietary (e.g., GPT-4.1, DeepSeek-v3) and open-weight (Qwen2.5-32B, Llama-3-8B, Mistral-7B) LLMs. Attack strategies span a comprehensive perturbation taxonomy, including stylistic rewriting, paraphrasing, fact mixing, omission, and contextual hijacking, which simulates a broad distribution of adversarial behaviors.
Evaluation Results
Empirical findings demonstrate a consistent and substantial gap between conventional attack success rate (ASR) and validity-aware success rate (VASR). In most attack settings, a significant proportion of rewrites deemed "successful" under label-flip and similarity metrics are in fact semantically invalid. AtomEval identifies that the predominant corruption arises from core distortion—adversarial generators typically preserve superficial relational templates but manipulate crucial fact-bearing components.
Notably, the paper highlights that stronger LLMs do not universally produce more valid or effective adversarial claims under atomic validity assessment. This contradicts assumptions derived from raw ASR or fluency-centered evaluation.
Qualitative Signal Diagnostics
AtomEval's diagnostic granularity exposes specific failure modes linked to adversarial rewriting and semantic robustness evaluation:
- Many textually similar rewrites drift toward evidence-supported truths or hallucinate new content.
- Evidence-leakage (diagnosed, but not always invalidating) is frequent, especially with evidence-aware LLMs, and can co-occur with semantic drift or core distortion.
- Fact conflict detection, though effective for explicit logical contradiction, underperforms on complex or implicit inconsistency, motivating hybrid approaches with higher-order reasoning modules.
Representative adversarial rewrites reveal that the ASR–VASR gap is nontrivial; it reflects misclassification of attacks that would not challenge a human user's truth-conditional understanding.
Implications and Theoretical Perspectives
AtomEval asserts the necessity of atomic, claim-centered validity assessment in adversarial settings, as existing surface-level protocols are fundamentally insufficient for robust evaluation. Implicitly, the work suggests that to genuinely measure factual robustness, future research should adopt proposition-level metrics that are both structurally and semantically aware.
Pragmatically, the deployment of such atomic evaluation frameworks can drive:
- More reliable benchmarking for adversarial claim generation and robust model development
- Informed adversarial training for enhanced fact-checkers
- Diagnosis of specific weaknesses (e.g., evidence-leakage bias) in LLM-based generators
- Potential for cross-lingual and multi-hop or compositional fact-checking, with extensions to hybrid symbolic–neural reasoning pipelines
Limitations and Forward Directions
The applicability of AtomEval is currently constrained by atomic extraction accuracy and a monolingual focus. The framework’s hard validity gate does not fully accommodate implicit or multi-hop reasoning failures—a direction for integrating neurosymbolic or logic-based modules. Further, future variants of AtomEval could support multilingual fact verification or be adapted for continuous, retrieval-augmented claim verification scenarios.
Conclusion
AtomEval formalizes and operationalizes atomic-level validity assessment for adversarial claim rewriting in fact verification. Its empirical analysis reveals that conventional metrics substantially overestimate adversarial effectiveness by neglecting meaningful semantic preservation. By leveraging atomic fact decomposition and interpretable semantic degradation metrics, AtomEval offers a principled, reproducible, and fine-grained validity-aware evaluation framework that advances the state of robustness benchmarking for fact-checking and LLM research (2604.07967).