- The paper presents a comprehensive benchmark integrating 75 expert-validated tasks across seven asset classes to evaluate LLM-agent orchestration.
- It leverages multi-hop, tool-based decision workflows and rigorous ground truth pipelines to mimic complex industrial maintenance environments.
- Numerical results reveal performance gaps in task completion, tool sequencing, and regulatory compliance, underscoring the need for advanced agent architectures.
PHMForge: A Scenario-Driven Agentic Benchmark for Industrial Asset Lifecycle Maintenance
Motivation and Benchmark Gaps
Industrial AI systems, particularly for Prognostics and Health Management (PHM), must execute precise, high-stakes maintenance decisions with direct safety and financial consequences. Existing agentic benchmarks are primarily digital-native or limited to passive QA or controlled diagnostics, lacking alignment with the operational, regulatory, and orchestration exigencies of physical industrial assets. PHMForge systematically closes these gaps by introducing a benchmark for evaluating LLM-powered agents in the context of autonomous, tool-based maintenance decision-making workflows that capture the complexity and heterogeneity of industrial environments.
PHMForge Framework and Architecture
PHMForge integrates a scenario-driven benchmark covering 75 expert-validated tasks distributed across seven asset classes and five task categories: Remaining Useful Life (RUL) Prediction, Fault Classification, Engine Health Analysis, Cost-Benefit Analysis, and Safety/Policy Evaluation. Scenarios reflect authentic industrial information needs and workflow diversity: single-asset versus fleet-level analysis, open- versus closed-ended queries, and explicit versus data-discovery modalities.
Each scenario is executed in an environment where industrial stakeholder queries are handled by agentic orchestration frameworks (ReAct, Cursor Agent, Claude Code) interfaced with generalist LLMs, which in turn interact via the Model Context Protocol (MCP) with two dedicated servers: the Prognostics Server and the Intelligent Maintenance Server. The Prognostics Server assembles 38 specialized tools for RUL, fault classification, and engine health analyses, while the Intelligent Maintenance Server delivers 27 tools focused on cost, safety, and compliance tasks. This architectural stratification underpins support for multi-hop, tool-based, regulation-aware reasoning and orchestrated action.
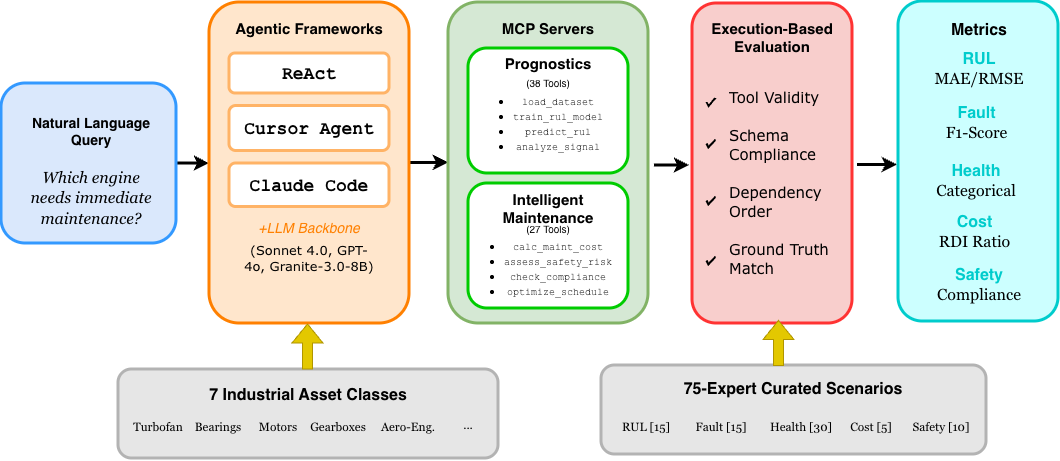
Figure 1: PHMForge system architecture, highlighting agentic tool orchestration across Prognostics and Intelligent Maintenance MCP servers for PHM tasks.
Expert-Driven Scenario Expansion and Dataset Curation
PHMForge scenario design reflects a progressive, SME-curated expansion methodology. Starting with a single RUL scenario on NASA’s CMAPSS turbofan data, the benchmark was extended through multi-asset and multi-task diversification, resulting in representation of real industrial conditions encountered in bearings, electric motors, gearboxes, and aero-engines. Datasets were curated from public repositories using stringent quality filters—ensuring verifiable ground truth (for MAE/RMSE or classification), task alignment, and scenario authenticity. Queries were not generated by LLMs but manually authored by domain specialists, with explicit mapping to operational roles (e.g., technician, manager, safety officer), reflecting both technical and business logic.
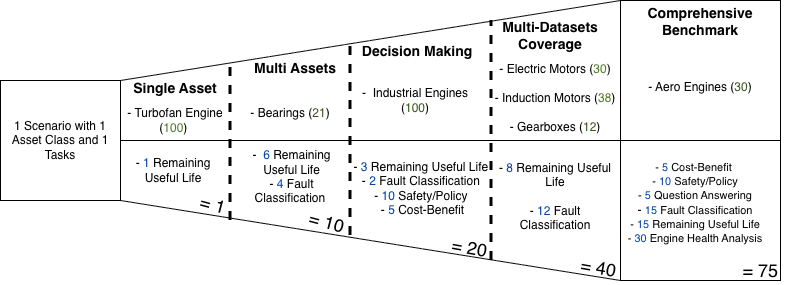
Figure 2: Five-stage scenario expansion pipeline, detailing dataset-task mapping and multi-asset scenario growth.
Ground Truth Pipeline and Validation
Ground truth for each scenario is rigorously constructed—either directly extracted from source datasets or, where infeasible, derived via SME consensus based on literature and industrial standards. Validation structures are task-specific: regression bounds for RUL, categorical templates for classification, and rule-based constraints for cost-benefit or compliance analysis. Agents are mandated to not only produce answers but also perform self-verification against these ground truths (e.g., explicit error computation), increasing robustness and real-world deployment fidelity.
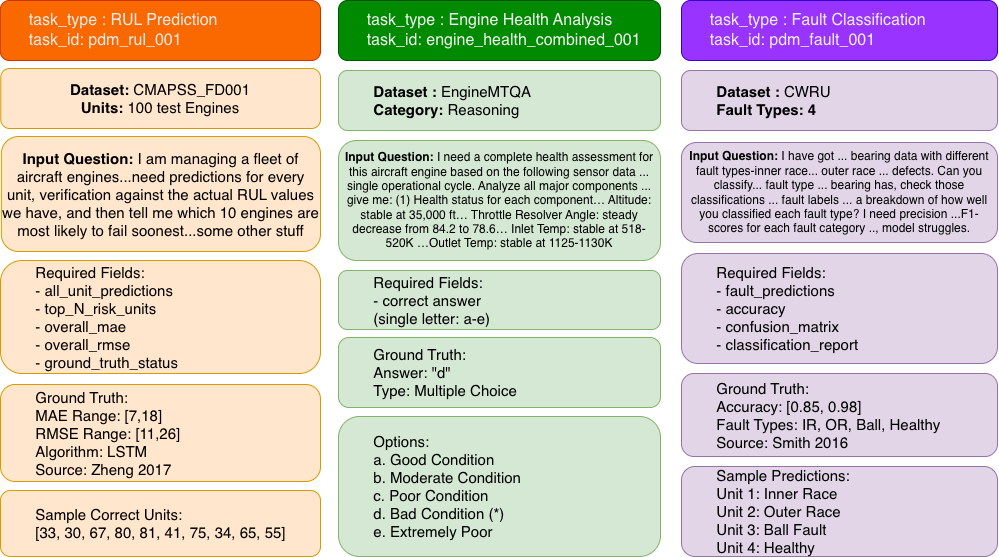
Figure 3: Open-ended (RUL, Fault Classification) versus close-ended (Engine Health Analysis) ground truth schemas in PHMForge.
Agentic Evaluation Protocol
Evaluations are performed with leading agentic frameworks (ReAct, Cursor Agent, Claude Code) and foundation models (Claude Sonnet 4.0, GPT-4o, Granite-3.0-8B) under deterministic settings (T=0), ensuring reproducibility. PHMForge introduces a critical unknown-tools challenge: agents must infer and retrieve correct domain tools from underspecified, natural stakeholder queries, reflecting actual deployment ambiguity.
Agents are evaluated for scenario completion (ground truth match), tool orchestration accuracy, correct sequencing, and performance on task-specific metrics (RUL: MAE/RMSE, Fault: F1-score, Health: categorical match, Cost/Safety: compliance/cost targets). Scenario complexity varies by tool dependencies (3–8 per scenario) and reasoning requirements.
Numerical Results and Failure Modes
The benchmark reveals important capability ceilings and systemic failure modes:
- Maximum observed task completion is 68% (Claude Code + Sonnet 4.0). Engine Health Analysis is particularly challenging, with 23.3–60.0% completion variability.
- Tool sequence failures occur in 23% of incorrect cases, primarily due to improper scheduling (e.g., invoking prediction pre-training) and distraction tool invocations.
- Multi-asset scenarios show a 14.9 percentage point completion drop versus single-asset settings. Zero-shot transfer, especially from bearings to motors, collapses to 42.7%, exposing a lack of architectural generalization.
- RUL predictions approach but do not match human/ML baselines; best MAE for turbofans is 14.8 cycles (versus benchmarked 10.5 cycles), with notable errors due to data leakage and invalid outputs.
- Classification performance lags on fine-grained taxonomies (e.g., motor faults: F1=0.68 vs. 0.79 baseline).
- Business logic and compliance tasks are acutely error-prone. For cost-benefit, agents frequently misapply asset-specific costs or skip intermediate reasoning steps; for safety, standard misidentification and risk granularity mismatches are common.
Ablation studies confirm that scenario simplification—removing ground truth verification or multi-asset complexity—artificially inflates completion rates and conceals critical orchestration weak points.
Implications for Industrial AI and Future Directions
PHMForge exposes the significant gap between current LLM-agent orchestration capability and the reliability required for high-stakes industrial deployment. The observed limitations are especially acute in scenarios requiring:
- Dynamic tool set discovery (unknown-tool specification)
- Regulatory and cross-domain transfer reasoning
- Multi-hop, multi-asset analysis and prioritization
- Deterministic output validation and self-verification
The results highlight that, while LLMs can enable partial autonomy in industrial PHM, their reliable deployment will require advances in orchestrated agent architectures, robust grounding to authentic tool inventories, and integration of regulatory standards as first-class reasoning objects. The benchmark’s living, extensible nature will facilitate longitudinal tracking of method improvements as new agent protocols and underlying foundation models mature.
Conclusion
PHMForge establishes a comprehensive, rigorously curated agentic benchmark that captures the authentic complexity of industrial asset maintenance decision-making. Through direct tool orchestration, realistic scenario coverage, and deterministic ground truth validation, it offers a robust empirical foundation for future agentic AI research in safety- and cost-critical industrial domains. Its findings substantiate the need for sustained advances in both LLM capabilities and agentic orchestration paradigms to approach human-level reliability in industrial settings.
Reference: "PHMForge: A Scenario-Driven Agentic Benchmark for Industrial Asset Lifecycle Maintenance" (2604.01532)