AgentDrive: An Open Benchmark Dataset for Agentic AI Reasoning with LLM-Generated Scenarios in Autonomous Systems
Abstract: The rapid advancement of LLMs has sparked growing interest in their integration into autonomous systems for reasoning-driven perception, planning, and decision-making. However, evaluating and training such agentic AI models remains challenging due to the lack of large-scale, structured, and safety-critical benchmarks. This paper introduces AgentDrive, an open benchmark dataset containing 300,000 LLM-generated driving scenarios designed for training, fine-tuning, and evaluating autonomous agents under diverse conditions. AgentDrive formalizes a factorized scenario space across seven orthogonal axes: scenario type, driver behavior, environment, road layout, objective, difficulty, and traffic density. An LLM-driven prompt-to-JSON pipeline generates semantically rich, simulation-ready specifications that are validated against physical and schema constraints. Each scenario undergoes simulation rollouts, surrogate safety metric computation, and rule-based outcome labeling. To complement simulation-based evaluation, we introduce AgentDrive-MCQ, a 100,000-question multiple-choice benchmark spanning five reasoning dimensions: physics, policy, hybrid, scenario, and comparative reasoning. We conduct a large-scale evaluation of fifty leading LLMs on AgentDrive-MCQ. Results show that while proprietary frontier models perform best in contextual and policy reasoning, advanced open models are rapidly closing the gap in structured and physics-grounded reasoning. We release the AgentDrive dataset, AgentDrive-MCQ benchmark, evaluation code, and related materials at https://github.com/maferrag/AgentDrive

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
A simple explanation of “AgentDrive: An Open Benchmark Dataset for Agentic AI Reasoning with LLM-Generated Scenarios in Autonomous Systems”
What is this paper about?
This paper introduces AgentDrive, a big, open dataset and test suite designed to help build and evaluate smart AI “agents” for self-driving cars. These agents use LLMs—the same kind of AI behind chatbots—to reason about driving, follow rules, and make decisions. AgentDrive creates hundreds of thousands of realistic, varied driving situations (all in simulation) and a huge set of multiple-choice questions about driving. Together, these let researchers train and test how well AI can think, plan, and stay safe on the road.
What questions is the paper trying to answer?
To make the purpose clear, the paper focuses on three main questions:
- How can we use LLMs to automatically generate lots of diverse, realistic, and safety-focused driving scenarios for training and testing AI drivers?
- How can we combine simulated driving data with reasoning questions to evaluate both the practical driving skills and the thinking skills (like physics understanding and ethics) of AI?
- How well do top AI models—both commercial and open-source—perform across different types of driving-related reasoning?
How did the researchers do it?
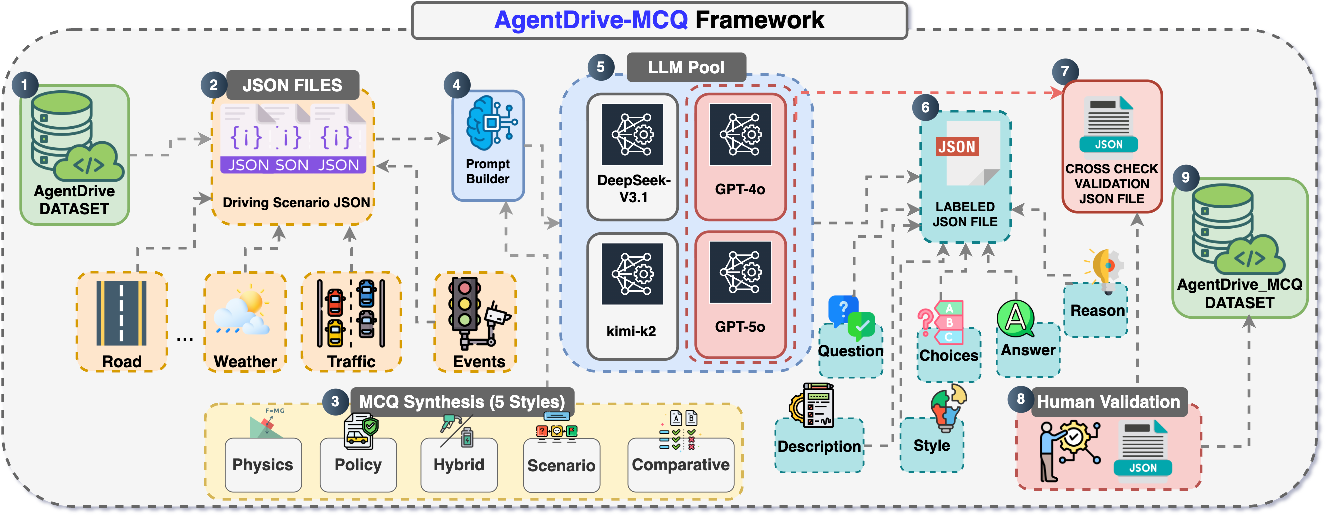
The researchers built an end-to-end pipeline—think of it like a factory—for creating, checking, and scoring driving scenarios and reasoning questions.
Here’s the process, explained with simple analogies:
- Designing the scenario space: They define seven “sliders” that shape each scenario: the type of situation, how drivers behave, the environment (like rain or fog), the road layout, the ego car’s goal, difficulty level, and traffic density. Moving these sliders creates many different combinations, like mixing ingredients to get new recipes.
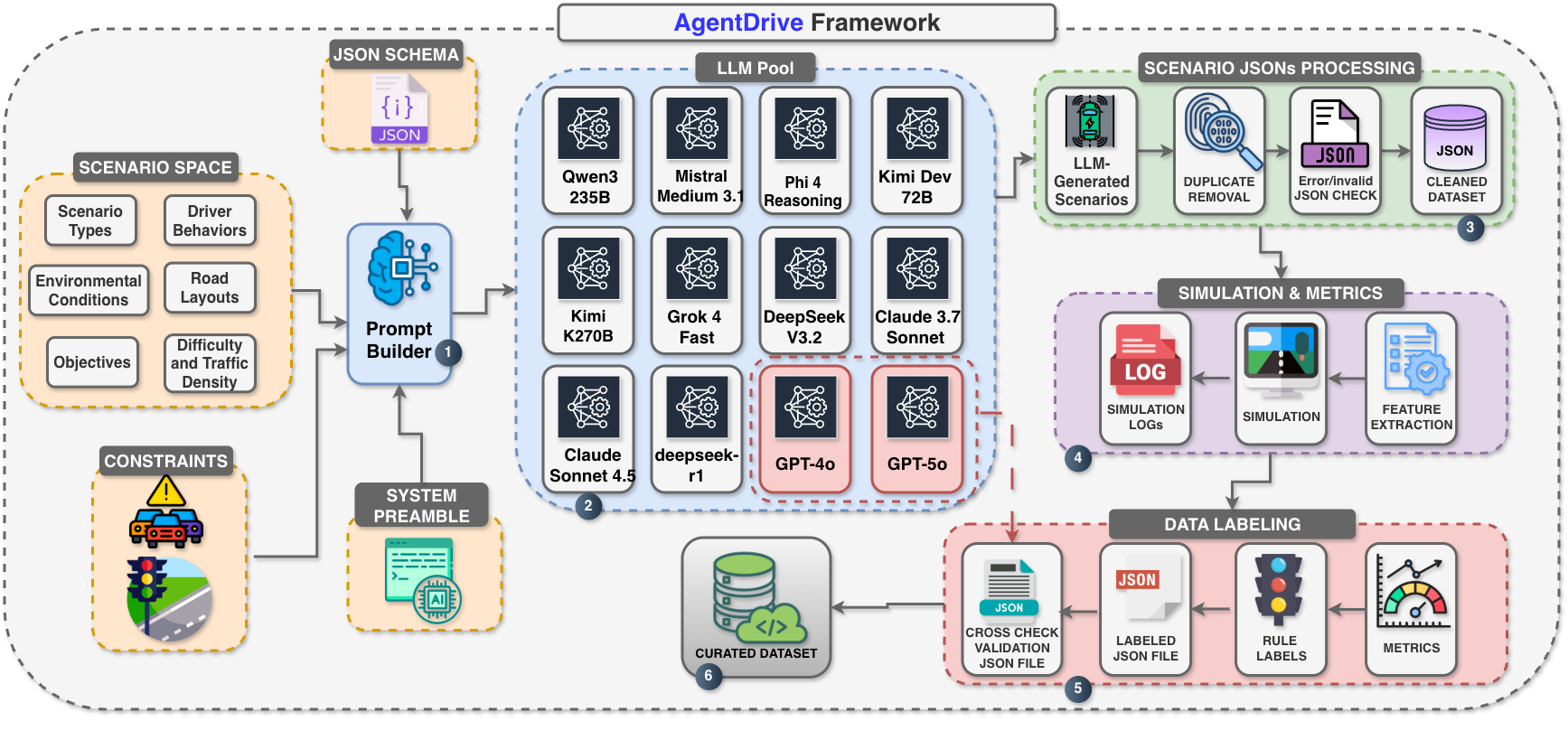
- LLM prompt-to-JSON generation: The AI (LLM) is given a structured prompt and asked to output a detailed scenario description in JSON (which is a computer-friendly “recipe card” format). This includes the road, cars, traffic lights, timing, and objectives.
- Schema and physics validation: The JSON is checked against rules (like “no negative speeds” and “traffic light timings make sense”) to make sure everything is consistent and possible in the real world.
- Simulation rollouts: Each scenario is then “played out” in a driving simulator, similar to running a level in a racing game to see what happens over time.
- Safety metrics: They compute surrogate safety metrics—quick-to-calculate numbers that reflect risk. One key metric is Time-To-Collision (TTC), which means “if you keep going as you are, how soon until you’d crash?” Lower TTC means higher danger.
- Outcome labels: Each run gets a simple label based on what happened: unsafe (e.g., a crash or red light violation), safe goal (e.g., stopped at red, then crossed on green), safe stop (stopped safely), or inefficient (safe but slow or unhelpful behavior).
- Reasoning questions (AgentDrive-MCQ): From the scenarios, they also auto-generate 100,000 multiple-choice questions to test an AI’s thinking. These questions cover:
- Physics: motion, distance, speed, safe following, braking
- Policy: traffic laws and ethics (e.g., right of way)
- Scenario: understanding the situation described
- Comparative: choosing the best option out of several
- Hybrid: a mix of physics and policy
In short, AgentDrive is both a virtual test track and a written exam, built at very large scale.
What did they find, and why does it matter?
The paper introduces three main pieces:
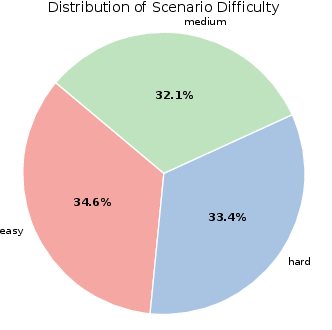
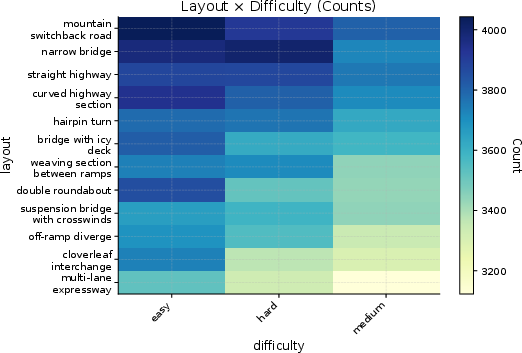
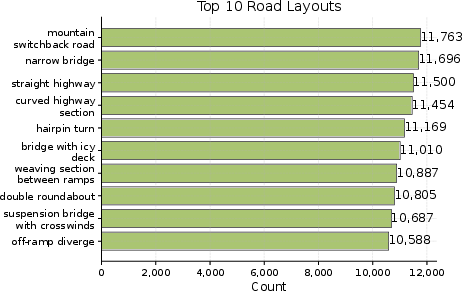
- AgentDrive-Gen: 300,000 simulation-ready, LLM-generated driving scenarios across the seven axes (type, driver behavior, environment, road layout, objective, difficulty, traffic density). These are validated and balanced so there are both everyday and rare, safety-critical cases.
- AgentDrive-Sim: The same scenarios, now with simulation rollouts, safety metrics (like TTC), and clear outcome labels. This makes it easy to train AI and measure performance.
- AgentDrive-MCQ: 100,000 reasoning questions that test different kinds of thinking relevant to driving.
They also tested 50 leading LLMs on the reasoning questions. The overall takeaway:
- Frontier commercial models performed best at policy and contextual reasoning (understanding rules and complex situations).
- Advanced open-source models are catching up fast in structured, physics-based reasoning (calculations and safety logic).
- This suggests that the gap is narrowing, especially in areas where precise logic and numbers matter.
Why it’s important:
- Safer self-driving: Better tests mean safer training, especially for rare but dangerous situations.
- Clear benchmarking: A standard, open benchmark helps everyone compare methods fairly and build on each other’s work.
- Balanced evaluation: It checks both “doing” (in simulation) and “thinking” (in reasoning questions), which is crucial for trustworthy autonomy.
What’s the big picture?
AgentDrive provides a unified, open toolkit for developing and evaluating AI that can drive and think safely. It could help:
- Researchers train more reliable self-driving agents with well-structured, diverse scenarios.
- Companies and regulators measure safety and reasoning in a consistent way.
- The community move toward autonomous systems that are not only capable but also ethical and compliant with traffic rules.
The authors note a current limitation: the reasoning part is text-based (no images or sensor data yet). They plan to add multimodal (visual + language) elements in the future, which will bring AgentDrive even closer to real-world driving.
Overall, AgentDrive is like building a huge, smart driving school for AI—complete with realistic practice tracks and challenging written exams—so we can better trust AI to make good choices on the road.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concrete list of what remains missing, uncertain, or unexplored in the paper, aimed to guide future research.
- Multimodal grounding absent: AgentDrive-MCQ and scenario specifications are text-only; integration of visual, LiDAR, radar, and map modalities (and evaluation of VLMs) within the same pipeline is not implemented.
- Simulator fidelity and transferability: The pipeline relies on highway-env (simplified kinematics and environment); it is unclear how results transfer to higher-fidelity simulators (e.g., CARLA) or real-world driving.
- Physical and legal validation depth: JSON schema checks ensure structure but not deep physical feasibility or traffic-law compliance; automated validators, formal verification, and human audits are not reported.
- Surrogate safety metrics coverage: Evaluation is dominated by TTC with fixed thresholds; lateral risk, PET, DRAC, jerk/comfort, severity, and scenario-specific metrics are missing and thresholds are not calibrated to real-world risk.
- Rule-based labeling reliability: The mapping to unsafe/safe_goal/safe_stop/inefficient may misclassify complex cases and seems objective-specific; no human-in-the-loop validation, inter-rater reliability, or label noise quantification is provided.
- Closed-loop agent evaluation: The benchmark assesses MCQ reasoning but does not evaluate LLM-driven planners/controllers on AgentDrive-Sim in real time (on-policy performance, latency, stability).
- Training efficacy evidence: Although designed for training/fine-tuning, the paper does not demonstrate that AgentDrive materially improves autonomous planning/safety vs. baselines; ablation studies are needed.
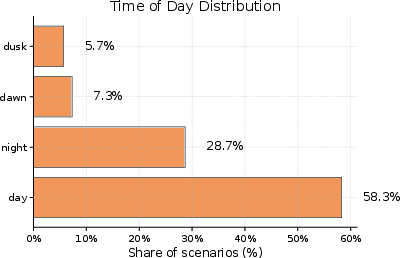
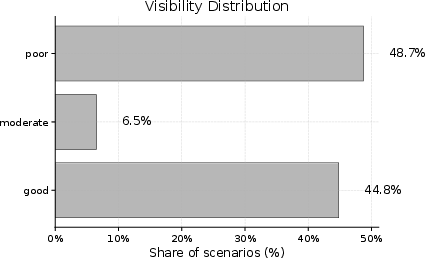
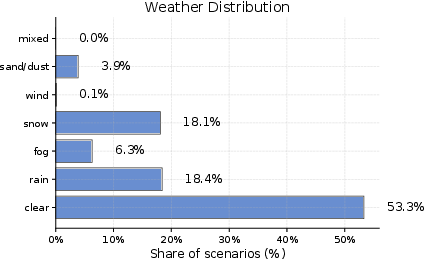
- Scenario diversity imbalances: Reported distributions skew toward daytime, good visibility, and clear weather; robust stratified sampling is needed to guarantee adequate coverage of rare adverse and edge conditions.
- Formal coverage measurement: No quantitative coverage metrics over the seven axes or their interactions are reported; rare-event density and compositional coverage remain unmeasured.
- LLM generation provenance and bias control: The specific LLMs, hyperparameters (temperature, decoding), seeds, and quality-control procedures used to generate the 300k scenarios are not detailed; bias/hallucination detection and repair remain unclear.
- MCQ validity and reliability: The 100k questions lack psychometric analysis (difficulty, discrimination), ambiguity checks, human verification rates, and adversarial option design; correctness and reliability need auditing.
- Policy/regulatory scope: “Policy” reasoning may be jurisdiction-specific; coverage across regions, updates to evolving laws, and explicit region tagging or retrieval of local statutes are not described.
- Environmental degradation modeling: Textual weather/visibility do not translate into sensor/perception degradation in highway-env; robust modeling of sensing failures and noise is absent.
- VRU realism: While VRUs are in the taxonomy, realistic pedestrian/cyclist dynamics, occlusions, and interactions (e.g., at crosswalks) appear limited by the simulator; dedicated VRU scenarios and models are needed.
- Efficiency metric definition: The “inefficient” label lacks explicit quantitative criteria (delay, stop count, fuel/energy, comfort); standardized efficiency metrics and thresholds are not defined.
- Orthogonality assumption: Scenario axes are treated as independent, but real-world dependencies (e.g., aggressive behavior in congestion) are not modeled; learning joint distributions from naturalistic data is open.
- Reproducibility of LLM evaluations: Testing 50 LLMs may be sensitive to prompt wording, temperatures, context lengths, and seeds; locked evaluation protocols and statistical significance reporting are missing.
- Contamination/leakage risk: Possible training-data overlap between LLMs and AgentDrive-MCQ is not analyzed; leakage detection and mitigation are needed to ensure fair benchmarking.
- Hardware-in-the-loop/real-vehicle validation: No HIL or limited on-road experiments are presented to validate that benchmark gains translate to safer real-world behavior.
- Long-horizon sequential reasoning: MCQs are single-turn; tasks requiring multi-step planning, memory, and plan revision (e.g., dynamic route changes) are not evaluated.
- Adversarial robustness: Scenarios do not include adversarial agents, sensor attacks, map errors, or perception spoofing; adversarial scenario generation and robustness testing are absent.
- Dataset governance and updates: Versioning, curation processes, error correction, and mechanisms to add new axes or retire flawed items are not documented; continuous dataset integration is an open need.
- Compute and sustainability: The resource/energy footprint for generating, simulating, and evaluating at this scale is not reported; efficiency baselines and lightweight subsets are needed.
- Cross-simulator standardization: The JSON schema is tailored to highway-env; portability and conformance across CARLA, LGSVL, Webots, and other simulators are not demonstrated.
- Reasoning-to-driving correlation: The paper reports MCQ scores but does not show whether higher reasoning performance predicts safer or more efficient behavior in simulation or real driving; correlation studies are missing.
Glossary
- AgentDrive: An open benchmark dataset of LLM-generated driving scenarios for training, fine-tuning, and evaluation of autonomous agents. "This paper introduces AgentDrive, an open benchmark dataset containing 300,000 LLM-generated driving scenarios designed for the training, fine-tuning, and evaluation of autonomous agents under diverse conditions."
- AgentDrive-Gen: The generation component that uses prompt engineering and schema validation to create structured, simulation-ready scenario JSONs. "AgentDrive-Gen: We developed AgentDrive-Gen, a large-scale benchmark comprising 300,000 LLM-generated driving scenarios."
- AgentDrive-MCQ: A 100,000-question reasoning benchmark evaluating physics, policy, hybrid, scenario, and comparative reasoning in LLM-based agents. "we introduce AgentDrive-MCQ, a 100,000-question reasoning benchmark spanning five reasoning dimensionsâphysics, policy, hybrid, scenario, and comparativeâto systematically assess the cognitive and ethical reasoning of LLM-based agents."
- AgentDrive-Sim: The simulation and labeling component that executes scenarios, computes surrogate safety metrics, and assigns outcome labels. "AgentDrive-Sim for simulation and outcome labeling"
- Agentic AI: AI systems with autonomous, goal-directed behavior, capable of reasoning and decision-making in complex environments. "evaluating and training such agentic AI models remains challenging due to the lack of large-scale, structured, and safety-critical benchmarks."
- Bench2ADVLM: A closed-loop evaluation framework for testing vision–language autonomous driving models in interactive settings. "One notable effort is Bench2ADVLM, a closed-loop evaluation framework introduced by Zhang et al. \cite{zhang2025bench2advlm} to test visionâlanguage AD models in interactive settings."
- Cartesian product: A mathematical construction combining multiple axes to define the complete scenario space. "The overall scenario space is expressed as the Cartesian product of these seven axes:"
- Closed-loop: An interactive evaluation setting where model decisions affect subsequent environment states. "Bench2ADVLM enables real-time closed-loop testing across simulators and physical vehicles"
- Compositional scenario space: A formal structure that composes multiple axes (type, behavior, environment, etc.) to generate diverse scenarios. "It defines a formal compositional scenario space and employs LLM-driven prompt engineering to generate 300K structured driving scenarios validated through a JSON schema."
- DETR-style 3D perceptrons: Perceptron-based tokenizers inspired by DETR, used to encode 3D object queries for planning with LLMs. "They propose a planner that uses DETR-style 3D perceptrons as tokenizers, feeding the LLM with 3D object queries from multi-view camera images."
- Dilemma zone: A hazardous area near an intersection where drivers must decide whether to stop or proceed during a yellow/red signal. "red-light dilemma zones, yield/priority confusion, highway merging at high speed, icy bridge segments, and pedestrian jaywalking."
- DriveGPT4: An LLM-based system that generates low-level control signals and natural language explanations for driving actions. "Xu et al. \cite{xu2024drivegpt4} propose DriveGPT4, which generates both low-level control signals and natural language explanations for each action."
- Early-fusion: A baseline approach that merges multimodal inputs at initial stages; contrasted with more advanced fusion strategies. "outperforms traditional early-fusion baselines in grounding objects and supporting collaborative driving strategies."
- Ego spawn: The initial position and state configuration for the ego vehicle in a scenario specification. "If traffic_light present: ego spawn.x 30 m before stopline_x."
- Ego vehicle: The autonomous vehicle under control and evaluation within the scenario. "The ego vehicle's intended task defines the contextual goal for each scenario."
- Entropy-maximized sampling: A data sampling strategy that encourages balanced coverage across scenario dimensions. "In addition, entropy-maximized sampling ensures balanced coverage across scenario dimensions, including rare safety-critical conditions."
- Headway distance: The longitudinal spacing between vehicles, used as a safety metric alongside TTC. "Surrogate safety metrics (e.g., minimum time-to-collision and headway distance) are computed"
- highway-env: A simulation framework used to implement and execute driving scenarios for rollouts. "the simulator is implemented using the highway-env framework~\cite{highway-env}"
- JSON schema: A formal schema that generated JSON scenarios must satisfy for structural and semantic validity. "validated through a JSON schema."
- LiDAR: Laser-based sensing used in multimodal datasets for autonomous driving research. "MAPLM \cite{cao2024maplm} provides a large-scale multimodal dataset combining maps, LiDAR, panoramic images, and Q{paper_content}A annotations"
- LLM4AD: A paradigm that integrates LLMs into autonomous driving systems for perception and decision-making. "Researchers have introduced the concept of LLM4AD, designing AD systems that leverage LLMs for tasks ranging from perception and scene understanding to decision-making"
- Near-miss: A safety-critical event where collision is narrowly avoided, often characterized by low TTC. "These thresholds allow us to classify events into unsafe, near-miss, and safe zones."
- Operational Design Domain (ODD): The defined conditions under which an autonomous system is intended to operate. "These variations directly reflect the operational design domains (ODDs) outlined by regulatory bodies"
- Open-loop: An evaluation mode where model outputs do not affect the environment dynamics during testing. "DriVLMe demonstrated competitive performance in open-loop simulations and closed-loop user studies"
- Perception fusion: The integration of sensory data from multiple sources or agents to improve situational awareness. "Shared perception fusion; V2V-QA dataset"
- Prompt engineering: Crafting structured prompts to guide LLMs in generating semantically rich and physically consistent scenario specifications. "It is built upon a prompt-engineering and schema-validation framework that transforms abstract scenario tuples into valid JSON specifications."
- Prompt-to-JSON pipeline: An LLM-driven process that converts textual prompts into validated, simulation-ready JSON scenario specifications. "employs an LLM-driven prompt-to-JSON pipeline to produce semantically rich, simulation-ready specifications that are validated against physical and schema constraints."
- Retrieval-augmented reasoning: A method that augments LLMs with retrieved domain knowledge (e.g., traffic regulations) for safer decisions. "present a retrieval-augmented reasoning framework where a Traffic Regulation Retrieval module automatically fetches relevant traffic laws and safety guidelines"
- Rollout: The simulated trajectory over time produced by executing a scenario in the simulator. "Each generated scenario from AgentDrive-Gen is executed within a simulator to produce dynamic rollouts."
- Rule-based labeling: A deterministic labeling system that maps detected events and metrics to interpretable outcome categories. "Surrogate safety metrics (e.g., minimum time-to-collision and headway distance) are computed, and a rule-based labeling system assigns interpretable outcome categories (safe_goal, safe_stop, inefficient, unsafe)."
- Scenario tuple: A structured representation of a scenario across seven axes (type, behavior, environment, road, objective, difficulty, density). "we define a scenario as a tuple: s = (t, b, e, r, o, d, q)"
- Schema validation: The process of checking and repairing generated JSON to ensure it adheres to the required structural constraints. "prompt-engineering and schema-validation framework"
- Stopline: The marked line at intersections indicating where vehicles must stop for traffic signals. "traffic_light & Stopline position, red/green durations"
- Surrogate safety metrics: Computed indicators (like TTC and headway) used to evaluate safety at scale without real-world tests. "Surrogate safety metrics (e.g., minimum time-to-collision and headway distance) are computed"
- Time-to-Collision (TTC): A predictive metric estimating the time remaining before a potential collision occurs. "Time-to-Collision (TTC) is the primary indicator of criticality."
- Vehicle-to-vehicle (V2V): Communication or cooperative reasoning between vehicles to enhance safety and planning. "vehicle-to-vehicle cooperative driving"
- Vision–LLMs (VLMs): Models that jointly process visual and textual inputs for tasks like perception and reasoning in driving. "Evaluation of Vision-LLMs (VLMs) for reliability and grounding"
- Vision–language planning: Planning approaches that incorporate both visual and language inputs, often via tokenization strategies. "prior visionâlanguage planning approaches, which tokenize only 2D images"
- Vulnerable Road Users (VRUs): Non-protected traffic participants such as pedestrians and cyclists, especially important in safety-critical scenarios. "The taxonomy explicitly incorporates vulnerable road users (VRUs)"
Practical Applications
Immediate Applications
The paper’s dataset, schema, and evaluation pipeline can be operationalized today in R&D, testing, and education. Below are the most deployable use cases.
- LLM-driven scenario generation for existing simulators
- What: Use AgentDrive-Gen’s prompt-to-JSON pipeline and schema to generate balanced, simulation-ready scenarios and port them to CARLA, LGSVL/Autoware, SUMO, Webots, or highway-env.
- Sectors: Automotive/robotaxi OEMs, Tier-1s, simulation tool vendors, robotics.
- Tools/products/workflows: JSON adapters for target simulators; schema validators; CI hooks for nightly scenario synthesis; “Scenario Pack” plugins for simulators.
- Assumptions/dependencies: Mapping from AgentDrive’s JSON schema to target simulator APIs; fidelity limits of highway-env-derived constraints; license compatibility and compute availability.
- Closed-loop regression testing and gating for AD stacks
- What: Run planning/control stacks over AgentDrive-Sim to compute TTC, near-miss rates, and labeled outcomes (unsafe, safe_goal, safe_stop, inefficient); use as CI/CD gates.
- Sectors: Automotive, robotaxi fleets, autonomy suppliers.
- Tools/products/workflows: Test suites parameterized by the seven axes; TTC- and violation-based pass/fail thresholds; dashboards tracking scenario coverage and risk trends.
- Assumptions/dependencies: Surrogate metrics (e.g., TTC) correlate with real-world crash risk; scenario diversity reflects target ODDs; availability of closed-loop interfaces.
- Rare-event training data augmentation
- What: Sample targeted combinations of behavior, weather, and density to synthesize edge cases for RL/IL fine-tuning and curriculum learning by difficulty.
- Sectors: AD/ADAS development, robotics.
- Tools/products/workflows: Curriculum schedulers using difficulty constraints H(d); data loaders for RL/IL; automatic replay of labeled near-miss segments.
- Assumptions/dependencies: Sim-to-real transfer; reward shaping aligned with safety; performance scaling with synthetic diversity.
- LLM policy benchmarking and fine-tuning
- What: Use AgentDrive-MCQ (physics, policy, hybrid, scenario, comparative) to pre-screen, compare, and fine-tune LLMs used in driving assistants or reasoning modules.
- Sectors: AI labs, autonomy teams, procurement.
- Tools/products/workflows: Evaluation harnesses and leaderboards; SFT/RLHF pipelines using MCQ items; ablation studies by reasoning dimension.
- Assumptions/dependencies: MCQ scores correlate with real-world decision quality; text-only reasoning sufficient for intended use; access to target LLMs.
- Safety case evidence and SOTIF/ISO documentation support
- What: Use labeled outcomes and surrogate safety metrics as structured evidence for hazard analyses, scenario coverage reports, and safety case traceability.
- Sectors: Safety engineering, certification/QA.
- Tools/products/workflows: Coverage matrices along seven axes; near-miss distributions; traceability from scenario taxonomy to hazards and mitigations.
- Assumptions/dependencies: Regulatory acceptance of synthetic/simulation evidence; mapping to ISO 26262/ISO 21448 work products.
- Compliance and policy checking
- What: Test rule adherence (e.g., red-light handling, headway) using labeled violations and policy-oriented MCQs; flag non-compliant behaviors during development.
- Sectors: Automotive compliance, governance/risk.
- Tools/products/workflows: Rule libraries linked to scenarios; automated violation detection; “Policy Compliance Checker” reports by region.
- Assumptions/dependencies: Up-to-date regional traffic rules; rule interpretation correctness; jurisdictional variance.
- Insurance and risk analytics sandbox
- What: Stress-test driver models or AD stacks across balanced scenarios; compute TTC/near-miss distributions and outcome rates to derive risk proxies.
- S
Collections
Sign up for free to add this paper to one or more collections.