MCP-Bench: Benchmarking Tool-Using LLM Agents with Complex Real-World Tasks via MCP Servers
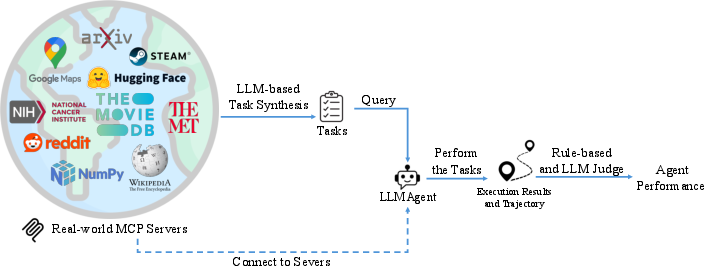
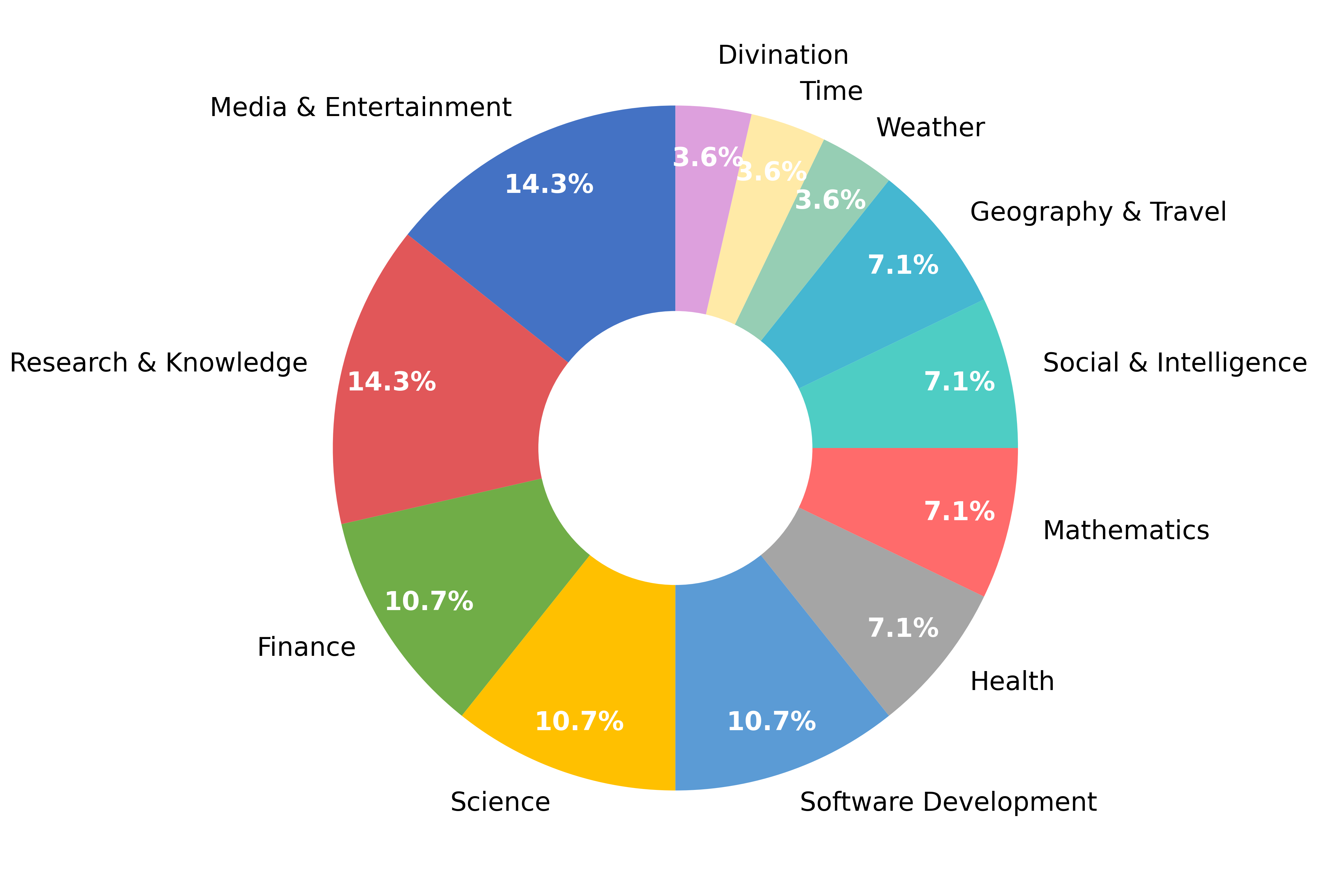
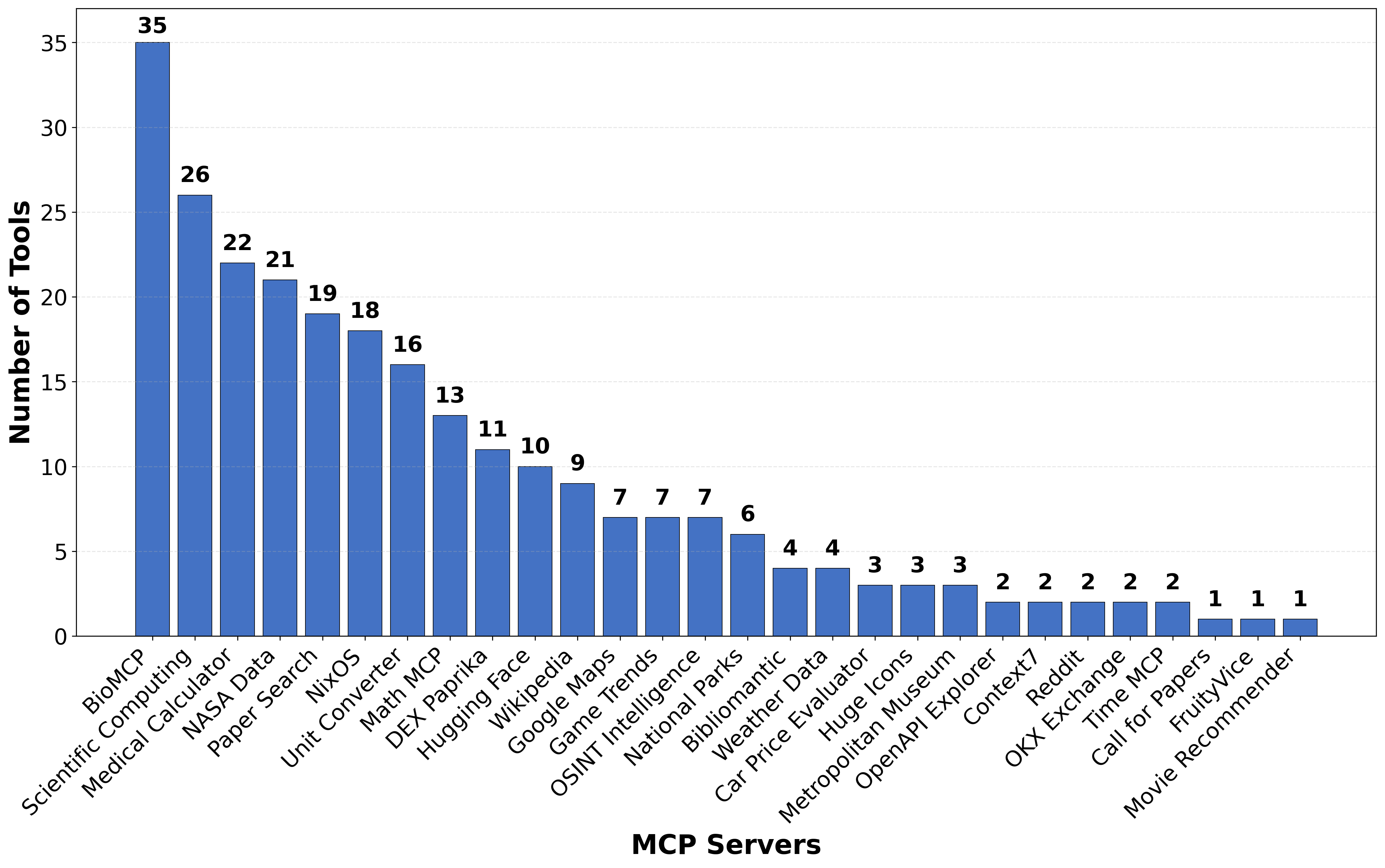
Abstract: We introduce MCP-Bench, a benchmark for evaluating LLMs on realistic, multi-step tasks that demand tool use, cross-tool coordination, precise parameter control, and planning/reasoning for solving tasks. Built on the Model Context Protocol (MCP), MCP-Bench connects LLMs to 28 representative live MCP servers spanning 250 tools across domains such as finance, traveling, scientific computing, and academic search. Unlike prior API-based benchmarks, each MCP server provides a set of complementary tools designed to work together, enabling the construction of authentic, multi-step tasks with rich input-output coupling. Tasks in MCP-Bench test agents' ability to retrieve relevant tools from fuzzy instructions without explicit tool names, plan multi-hop execution trajectories for complex objectives, ground responses in intermediate tool outputs, and orchestrate cross-domain workflows - capabilities not adequately evaluated by existing benchmarks that rely on explicit tool specifications, shallow few-step workflows, and isolated domain operations. We propose a multi-faceted evaluation framework covering tool-level schema understanding and usage, trajectory-level planning, and task completion. Experiments on 20 advanced LLMs reveal persistent challenges in MCP-Bench. Code and data: https://github.com/Accenture/mcp-bench.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Knowledge Gaps
Unresolved Gaps and Limitations
Below is a concise list of concrete knowledge gaps, limitations, and open questions that remain unresolved and could guide future research:
- Benchmark stability and reproducibility: Live MCP servers can change over time (data drift, outages, rate limits, schema updates), but no server versioning, snapshotting, or replay logs are provided to guarantee reproducible runs.
- Judge reliability and bias: The LLM-as-a-Judge (o4-mini) is a single-model evaluator; there is no inter-judge agreement analysis, cross-family judge comparison, or correlation with human judgments to validate scoring reliability and fairness.
- Circularity and contamination risk: The same vendor family is used for task synthesis and judging, and many evaluated systems are from that vendor; the impact of this circularity on outcomes is not quantified.
- Underspecified metric definitions: The paper claims rule-based checks for “dependency order/compliance,” but only defines three metrics (tool validity, schema compliance, execution success) formally; dependency compliance and parallelism efficiency lack explicit, reproducible formulas.
- Overall score construction: How the multiple axes are combined into the final “Overall Score” (weights, normalization, aggregation) is not precisely defined, hindering interpretability and replication.
- Run-to-run variance and statistical testing: Model sampling settings, seeds, and multi-run variance for agents (not just judges) are not reported; no confidence intervals or significance tests are presented.
- Effect of compression policy: The summarization step π_compress can drop crucial details; there is no ablation on different compression strategies, lossiness, or its impact on planning and grounding.
- Parallelism evaluation vs. capability: “Parallelism and efficiency” is scored by an LLM judge, but the agent runtime appears sequential; it is unclear whether true concurrency is supported or how efficiency is objectively measured.
- Tool parameter correctness beyond schema: Rule-based checks only ensure format/schema validity; semantic correctness of parameters (e.g., correct units, ranges, constraints) is left to the judge with no grounded verification.
- Limited task diversity and scale: Only 104 tasks (with max 20 steps) may be insufficient to expose long-horizon weaknesses; the benchmark does not explore very long plans, dynamic replanning, or workflows with more than three servers.
- Representativeness of domains and operations: Many real-world scenarios (authentication, payments, irreversible side-effects like booking, rate limiting, quotas) are absent or underrepresented, limiting ecological validity.
- Fuzzy-instruction fidelity: Fuzzy tasks preserve numeric details; real users often omit key parameters. The benchmark does not measure the agent’s ability to elicit missing information via clarification questions.
- Real-user task realism: Tasks are LLM-synthesized with limited human curation; there is no evaluation on user-sourced tasks or an analysis of synthesis-induced biases.
- Distractor selection rigor: Adding 10 distractor servers per task increases difficulty, but their semantic closeness to the target tools and the effect of varying distractor count/quality are unstudied.
- Generalization to unseen tools/servers: There is no leave-one-server-out or unseen-schema evaluation to assess transfer beyond the specific MCP servers included.
- Robustness to tool/output hazards: The benchmark does not test adversarial conditions (malformed schemas, prompt-injected outputs, noisy/contradictory results, flaky endpoints) or recovery strategies after failures.
- Safety, privacy, and compliance: No metrics or scenarios test safe tool use (e.g., medical decision boundaries, PII handling, regulatory constraints) or the agent’s ability to refuse unsafe requests.
- Cross-lingual robustness: Tasks and tool descriptions are English-centric; the benchmark does not evaluate multilingual instructions or localization differences in tool outputs.
- Alternative valid trajectories: Judges are given the unfuzzed task and dependency analysis unavailable to agents, risking bias toward a single canonical plan; there is no explicit accommodation for scoring correct, alternative execution paths.
- Agent design confounders: Only model families vary; agentic design choices (retrievers, memory modules, planners, tool-selection strategies) are not systematically ablated, making it hard to attribute gains to model vs. agent architecture.
- Error taxonomy and qualitative insights: There is no systematic categorization of failure modes (e.g., retrieval errors, parameterization mistakes, grounding lapses), which limits actionable guidance for improving agents.
- Temporal and geographic sensitivity: Tasks involving weather, maps, or finance are time/locale-sensitive; the benchmark does not control or report these contextual factors.
- Accessibility and maintenance: Reliance on external “production-grade” servers raises availability and licensing concerns; long-term maintenance plans (server deprecation, replacements, mirrored endpoints) are not described.
- Cost and latency: The benchmark does not measure computational cost, latency, or efficiency trade-offs, which are critical for practical deployment.
- Multi-agent or tool-learning settings: The benchmark focuses on a single agent and fixed tool schemas; it does not explore collaborative agents, on-the-fly tool learning, or schema induction from sparse documentation.
Collections
Sign up for free to add this paper to one or more collections.

