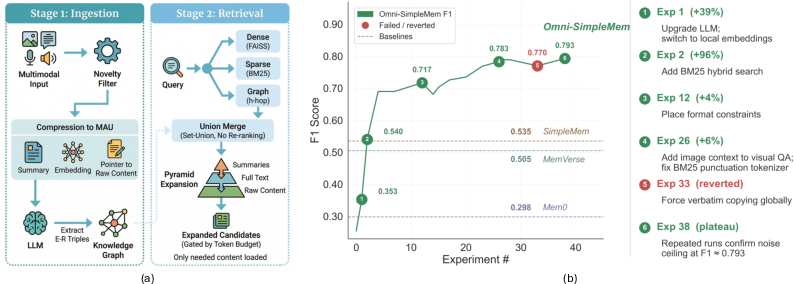
Omni-SimpleMem: Autoresearch-Guided Discovery of Lifelong Multimodal Agent Memory
Abstract: AI agents increasingly operate over extended time horizons, yet their ability to retain, organize, and recall multimodal experiences remains a critical bottleneck. Building effective lifelong memory requires navigating a vast design space spanning architecture, retrieval strategies, prompt engineering, and data pipelines; this space is too large and interconnected for manual exploration or traditional AutoML to explore effectively. We deploy an autonomous research pipeline to discover Omni-SimpleMem, a unified multimodal memory framework for lifelong AI agents. Starting from a naïve baseline (F1=0.117 on LoCoMo), the pipeline autonomously executes ${\sim}50$ experiments across two benchmarks, diagnosing failure modes, proposing architectural modifications, and repairing data pipeline bugs, all without human intervention in the inner loop. The resulting system achieves state-of-the-art on both benchmarks, improving F1 by +411% on LoCoMo (0.117$\to$0.598) and +214% on Mem-Gallery (0.254$\to$0.797) relative to the initial configurations. Critically, the most impactful discoveries are not hyperparameter adjustments: bug fixes (+175%), architectural changes (+44%), and prompt engineering (+188% on specific categories) each individually exceed the cumulative contribution of all hyperparameter tuning, demonstrating capabilities fundamentally beyond the reach of traditional AutoML. We provide a taxonomy of six discovery types and identify four properties that make multimodal memory particularly suited for autoresearch, offering guidance for applying autonomous research pipelines to other AI system domains. Code is available at this https://github.com/aiming-lab/SimpleMem.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Omni-SimpleMem: A simple explanation
What is this paper about?
This paper is about teaching AI “agents” (computer helpers) to remember important things over a long time, not just for a few minutes. It introduces Omni-SimpleMem, a memory system that can store and recall many kinds of information—text, pictures, audio, and video—so the AI can use its past experiences to answer questions better. Uniquely, the system was discovered and improved by an automatic “robot scientist” that ran its own experiments and fixed problems without a human constantly guiding it.
What questions did the researchers want to answer?
The team focused on a few easy-to-understand questions:
- How can an AI keep a lifelong, organized memory of many types of information (text, images, sounds, videos) without getting overwhelmed?
- How should the AI decide what to save, how to store it, and how to find it later?
- Can an automated research system, instead of people, discover the best design choices—like fixing bugs, improving prompts, and changing the architecture?
- Will this automatically discovered system actually perform better on tests that check long-term memory?
How did they approach it?
Think of this like building a super-organized digital scrapbook with a built-in librarian that learns how to organize better over time.
The “robot scientist” approach:
- The authors used an automated research pipeline (a set of AI tools that act like a robot scientist) to run about 50 experiments. It tried ideas, wrote code changes, tested them, and kept the ones that helped. It even found and fixed bugs by itself.
The memory system’s three big ideas:
- Selective saving: Like not saving every blurry photo on your phone, the system only keeps new or useful pieces of information. It checks if something is a repeat and skips it if it’s too similar.
- Unified memory units (MAUs): Everything saved—text, image, audio, video—is packed into a tidy “memory card” with:
- A short summary (like a caption),
- A compact “search fingerprint” (an embedding) to find it fast,
- A link to the full item (stored separately to save space),
- Time and type labels, plus links to related memory cards.
- Smart finding (progressive retrieval): When answering a question, the system:
- First pulls quick summaries of the most relevant memories,
- Then, only if needed, opens the detailed text,
- Finally, if still needed, loads the original photos/audio/video.
- This “pyramid” process saves time and space—start with headlines, read the full article only if necessary.
Better search by combining methods:
- Dense search (by meaning): Finds items that “mean” similar things even if words don’t match exactly.
- Sparse search (by keywords): Finds items with matching words.
- Set-union merging: Instead of mixing scores together, it keeps the meaning-based order and adds keyword-only matches at the end. The automated system discovered this worked better.
A simple knowledge graph:
- The system also builds a little map of “who/what/where/when” and how they’re connected (like a friend-and-places network). This helps answer multi-step questions that connect multiple memories.
What did they find, and why is it important?
Big performance gains:
- On long-term memory tests, the system jumped from poor to top-tier results:
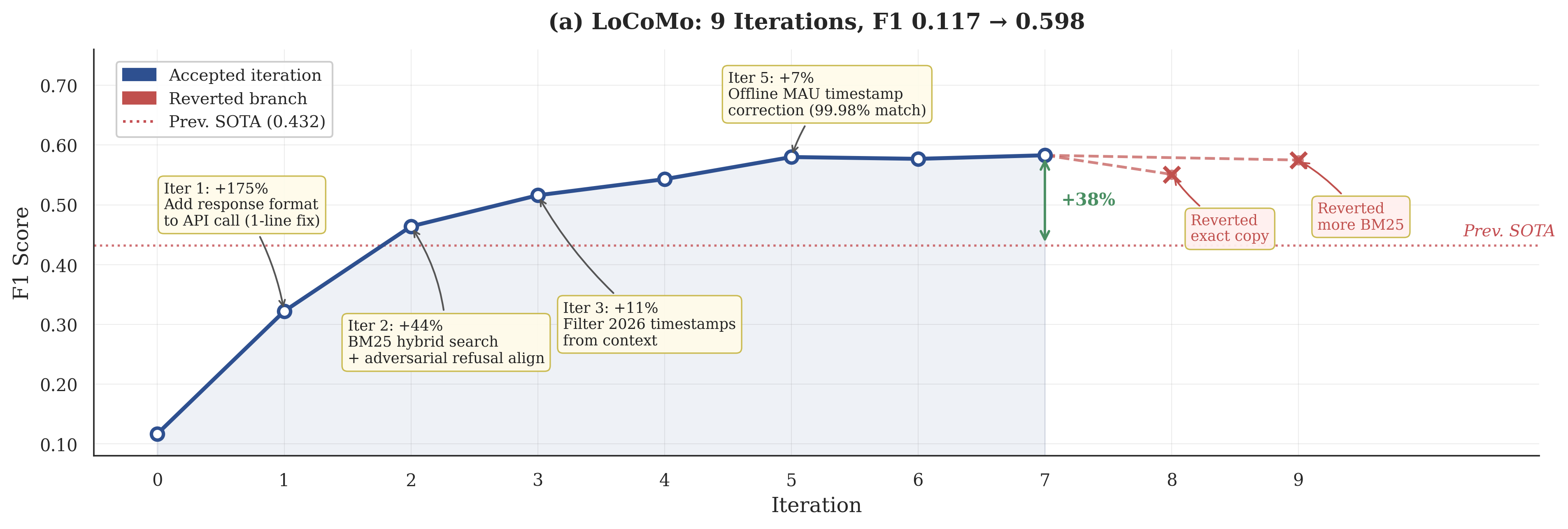
- LoCoMo benchmark: F1 score improved from 0.117 to 0.598 (about +411%).
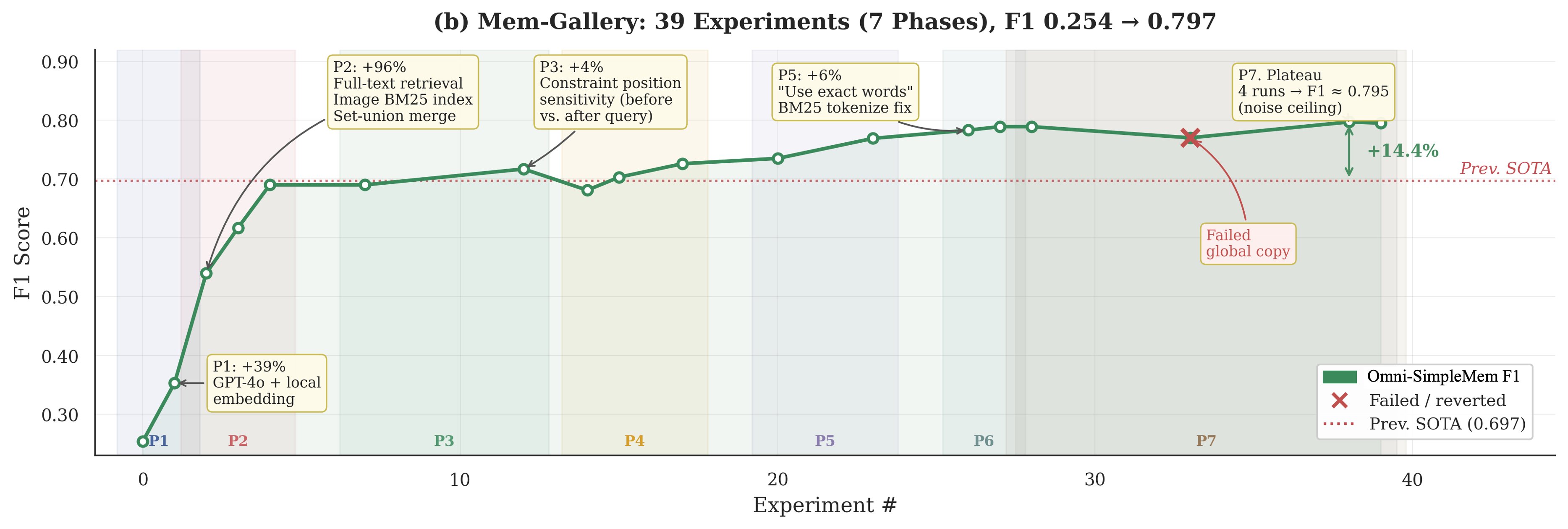
- Mem-Gallery benchmark: F1 improved from 0.254 to 0.797 (about +214%).
- F1 is a score that rewards answers that are both accurate and precise; higher is better.
Not just “tuning knobs”:
- The biggest improvements came from things normal automated tools usually miss:
- Bug fixes (+175%): For example, a tiny API setting caused overly long, messy outputs that ruined accuracy. The robot scientist found and fixed it.
- Architectural changes (+44%): Choosing better storage/search designs mattered a lot.
- Prompt improvements (+188% in some cases): How you ask the AI to answer can change results dramatically.
- Regular hyperparameter tuning (just changing numbers) was much less important than these deeper changes.
New, useful tricks:
- Combining meaning-based and keyword search by a simple set-union worked better than fancy score mixing.
- Saving full original text (not only summaries) helped on some tests that check exact word matching.
- The pyramid retrieval strategy and the knowledge graph made multi-step questions much easier.
Faster and more efficient:
- With parallel workers, Omni-SimpleMem answered more than three times as many queries per second than the fastest baseline, thanks to fast, read-only search indexes and staged retrieval.
Why does this matter?
- Smarter long-term AI: If AI helpers can remember important things and find them quickly, they can become far more helpful over days, weeks, or months.
- Automatic discovery works: This shows a “robot scientist” can meaningfully improve complex AI systems by doing more than just tuning numbers—like diagnosing bugs and redesigning parts of the system.
- Practical design lessons: The paper shares a blueprint of what worked—save only what’s new, represent everything in consistent “memory cards,” search using both meaning and keywords, and reveal information in stages. Other AI projects can borrow these ideas.
- Better tools for multimodal life: Since the system handles text, images, audio, and video together, it’s a step toward AI that can remember and reason across everything we encounter in the real world.
In short, the paper shows that an AI can learn how to build a better memory for itself—what to save, how to store it, and how to find it—by running its own experiments. The result is an AI that remembers more reliably, answers more accurately, and improves faster, with less human effort.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a consolidated, concrete list of what the paper leaves missing, uncertain, or unexplored, organized to guide follow-on research.
Evaluation scope and generalization
- Limited benchmark coverage: results are only on LoCoMo (text) and Mem-Gallery (image+text), leaving performance on audio/video-heavy settings, continuous streams, and real-world longitudinal deployments untested.
- Generalization risk from metric-specific optimizations: the pipeline discovered that including full original dialogue text substantially boosts token-overlap F1; it is unclear whether gains persist under semantic, human-judged, or retrieval-faithfulness metrics.
- Multilingual and cross-domain robustness are unaddressed: all experiments appear English-centric and dialogue-focused; behavior on other languages, domains (e.g., clinical, legal), and code-mixed inputs is unknown.
- Adversarial robustness gaps: in certain backbones/categories the “Adversarial” performance is below the best baseline (e.g., Table’s adversarial column), suggesting vulnerabilities to prompt injection/noisy memories that are not investigated.
- Lack of online/interactive evaluations: no A/B tests with live agents, user studies, or long-horizon tasks (days–weeks) to assess stability, user utility, and drift over time.
Scalability, efficiency, and systems concerns
- Storage growth and scaling limits are not quantified: selective ingestion is proposed, but there is no empirical characterization of MAU growth, storage footprint, and retrieval quality at million/billion-memory scale.
- Index maintenance under concurrent updates is unspecified: read-only FAISS/BM25 indices are used for speed; how to support low-latency online ingestion, re-embedding, and index refresh while serving queries is not addressed.
- Throughput/latency trade-offs are unclear: single-worker Omni-SimpleMem is slower than some baselines, with speed dependent on parallel workers; the compute/cost implications and scalability limits (e.g., contention, network I/O) are not analyzed.
- Ingestion pipeline costs are not reported: LLM calls for KG extraction and summarization (e.g., GPT-4o) can dominate cost; no breakdown of ingestion latency, dollar cost, or amortization strategies (e.g., batching, distillation).
- Embedding/model drift is unhandled: switching embedding backends (e.g., due to API errors) changes vector spaces; policies for re-embedding and mitigating drift-induced retrieval degradation are missing.
Architectural and algorithmic uncertainties
- Hybrid retrieval fusion is heuristic: the set-union merging strategy is shown to work on two benchmarks, but there is no theoretical rationale, sensitivity analysis (e.g., toward corpus size or query type), or comparison to advanced learned fusion/reranking (e.g., cross-encoders, MMR/diversification).
- Contribution of the knowledge graph (KG) is not quantified: no ablation isolates KG augmentation; precision/recall of entity/relation extraction and entity resolution error rates are not reported, nor their impact on final answers.
- KG schema and extraction scope are limited and unclear for non-text: a 7-type schema is used on LLM-generated summaries; how visual/audio content is grounded into entities/relations, and how well cross-modal links are formed and maintained, remains unspecified.
- Pyramid retrieval parameters are hand-tuned: token budget B, similarity thresholds, and “similarity-per-token” heuristics lack principled derivations or adaptive control policies; sensitivity under different LLMs and contexts is unstudied.
- Novelty filtering risks are not evaluated: CLIP/VAD/Jaccard-based filters may discard subtle but important repetitions or context; there is no ablation of filtering thresholds or analysis of recall loss introduced during ingestion.
- Temporal reasoning isn’t fully leveraged: timestamps are stored (and were once corrupted), but there is no explicit temporal retrieval/ranking model or evaluation of time-aware reasoning beyond basic storage and a single bug fix.
- Memory maintenance is underspecified: beyond selective ingestion, there is no policy for consolidation, deduplication, contradiction resolution, or forgetting under storage constraints to maintain consistency over very long horizons.
- Modality handling at retrieval Level 3 is vague: how raw images/audio/video are represented and fused with LLM context under token budgets (e.g., image-token limits, audio transcription policies) is not detailed or stress-tested.
- Error propagation through MAU and KG pipelines is unquantified: how summarization/captioning errors and entity resolution mistakes affect downstream retrieval and generation is not measured.
Autoresearch pipeline limitations and risks
- Reproducibility and stability are under-specified: the pipeline involves stochastic LLMs, code edits, and self-healing; seeds, variance across runs, and controls for randomness are not systematically reported.
- Overfitting to development subsets is possible: the pipeline optimizes on small dev slices; generalization safeguards (e.g., cross-validation, holdouts per phase) are not detailed.
- Metric gaming vs. general improvements: changes like “return original dialogue text” exploit F1 token overlap; safeguards to detect and prevent metric-specific hacks are not described.
- Safety of autonomous code modifications is unproven: while self-healing fixed bugs (e.g., timestamp corruption, API keys), there is no framework for verifying that automated patches don’t introduce subtle regressions or security vulnerabilities.
- External validity across codebases is unknown: whether AutoResearchClaw’s discoveries and self-healing capabilities transfer to other memory systems or larger production stacks is not evaluated.
- Cost and carbon footprint of autoresearch are not detailed: experiments in ~72 hours implies significant LLM/API usage; budget, sustainability, and efficiency of the search process are unreported.
Evaluation methodology and fairness
- Lack of human-centered evaluation: no human judgment of answer helpfulness, factual alignment, or perceived quality; reliance on F1/BLEU can misrepresent semantic utility.
- Missing per-category error analyses: aside from an anecdotal case study and a limited ablation, there is no systematic breakdown of failure modes (e.g., multi-hop chains, entity linking errors, temporal confusion).
- Baseline parity on prompts and retrieval context is unclear: the pipeline’s prompt engineering and context formatting changes may not be applied symmetrically to baselines, potentially confounding comparisons.
- No robustness tests under distribution shift: performance under noisy ASR transcripts, OCR errors, low-quality images, or domain shifts is untested.
Trust, safety, and governance
- Privacy and compliance are unaddressed: long-term memory stores potentially sensitive data; there is no discussion of data minimization, access control, redaction, right-to-be-forgotten, or auditability.
- Security against malicious memories/prompt injection is not evaluated: mechanisms to sanitize stored content and prevent model exploitation via retrieved text/images are absent.
- Calibration and abstention are missing: the system does not estimate uncertainty or detect when retrieved context is insufficient, risking hallucination or overconfident errors.
- Data integrity and provenance are only lightly touched: a timestamp corruption incident was auto-repaired, but broader guarantees (checksums, provenance chains, consistency checks) are not established.
Directions requiring concrete follow-up experiments
- Quantify KG impact via controlled ablations (with/without KG; varying hop counts and decay ) and report extraction/resolution accuracy vs. end-task gains.
- Stress-test retrieval at scale (≥10M MAUs) with online indexing, concurrent reads/writes, and measure latency, throughput, and retrieval quality under load.
- Evaluate alternative fusion/ranking (learned re-rankers, cross-encoder reranking, MMR/diversification) vs. set-union, across diverse query types and corpora.
- Study adaptive token budgeting policies (e.g., bandit or RL-based) and threshold selection across LLM backbones and tasks.
- Assess novelty filtering errors by sweeping thresholds and measuring downstream recall loss, especially on temporally repetitive but important information.
- Test multilingual, multimodal (audio/video) tasks with explicit pipelines for transcription, segmentation, and cross-modal grounding to the KG.
- Run user studies and live-agent A/B tests to validate usefulness, robustness, and user trust over long periods, including memory editing and deletion workflows.
- Introduce and evaluate security/guardrail layers (prompt sanitization, content moderation, retrieval-time filters) against adversarial or toxic content.
- Perform cost/energy audits for both inference and autoresearch phases; explore distillation (e.g., smaller local LLMs for KG/summary) to reduce operating costs.
Practical Applications
Immediate Applications
Below are concrete use cases that can be deployed today by adapting the Omni-SimpleMem architecture, its hybrid retrieval and pyramid expansion strategy, and the accompanying autonomous research workflow.
- Enterprise copilots with durable multimodal memory (software, customer support, sales/CRM)
- What: Upgrade existing RAG/chat assistants to remember and retrieve prior tickets, emails, call transcripts, screenshots, and meeting notes as Multimodal Atomic Units (MAUs), using selective ingestion (VAD for audio, CLIP for images) to cut storage and noise, hybrid FAISS+BM25 set-union retrieval to improve recall, and pyramid expansion to control token costs.
- Tools/workflows: FAISS/OpenSearch+BM25; CLIP-based novelty gating; MAU store with hot/cold tiers; Neo4j/OpenCypher for optional knowledge graph; prompt templates that place constraints before the question; parallel retrieval with read-only indices.
- Assumptions/dependencies: PII/PHI compliance (GDPR, HIPAA), enterprise data connectors (email/CRM/CCaaS), model/API availability and cost control, token budget enforcement, logging for audit.
- Contact center QA and agent assistance (customer support)
- What: Ingest call recordings with VAD-based filtering, extract summaries and entities, retrieve similar prior cases via set-union hybrid search, and progressively reveal evidence during live assistance or QA review.
- Tools/workflows: Streaming ASR, VAD, BM25 over summaries, FAISS over embeddings, graph expansion around “customer” and “issue” entities, pyramid expansion tuned to latency SLAs.
- Assumptions/dependencies: Real-time latency budgets; robust ASR; careful thresholding to avoid over-collection; privacy policies for voice data.
- Personal knowledge management with multimodal capture (daily life, productivity)
- What: A “memory vault” that captures chats, photos, whiteboard snapshots, voice notes, and webpages; de-duplicates with novelty filters; stores as MAUs; retrieves via hybrid search; and expands from summaries to originals on demand.
- Tools/workflows: Mobile capture app; CLIP-based photo deduplication; embeddings+BM25; on-device hot store, cloud cold store; local fallback embeddings when APIs fail.
- Assumptions/dependencies: Opt-in data collection; encrypted storage and secure sync; configurable retention; mobile compute limits (may require batching).
- Researcher and student assistants for long-horizon projects (academia, education)
- What: Ingest papers, figures, lecture videos, lab notes; build a lightweight knowledge graph of concepts/authors/datasets; answer cross-session questions with graph-augmented retrieval and multi-hop MAU synthesis.
- Tools/workflows: PDF parsing and figure captioning; concept/entity extraction via LLM+JSON; graph neighborhood expansion; progressive retrieval constrained by course/project token budget.
- Assumptions/dependencies: Citation-aware prompts; institution data policies; LLM extraction quality on scientific text.
- E-discovery and case memory for legal teams (legal)
- What: Manage depositions (audio), exhibits (images/PDFs), and emails as MAUs; filter redundant scans; use hybrid retrieval plus graph links (person–event–document) to assemble evidence chains.
- Tools/workflows: OCR+BM25; FAISS over case embeddings; Neo4j/Gremlin queries for provenance; deterministic retrieval rules and full trace logs.
- Assumptions/dependencies: Chain-of-custody requirements; strict access controls; jurisdiction-specific retention; reproducibility and auditability.
- Financial advisor and account memory (finance)
- What: Persist client preferences, risk notes, document snapshots, and KYC interactions as MAUs; retrieve prior commitments and portfolio rationales; enforce token budgets with pyramid retrieval during client chats.
- Tools/workflows: CRM integration; BM25 for policy terms; FAISS for semantic recall; entity resolution for client aliases; prompt constraints placed before user queries.
- Assumptions/dependencies: Regulatory compliance (SEC, FINRA); explainability/audit; data residency; guardrails for advice generation.
- Engineering productivity memory (software development)
- What: Persist design docs, PR discussions, incident reports, architecture diagrams; link entities (service, owner, incident) in a graph; retrieve similar incidents and decisions with set-union hybrid search.
- Tools/workflows: GitHub/GitLab/Jira connectors; code+doc embeddings; BM25 on ADRs; graph expansion around services; pyramid expansion to stay within CI/CD token budgets; parallel retrieval in build bots.
- Assumptions/dependencies: Private repo access; IP policies; indexing cadence; noise control from auto-generated logs.
- Knowledge-graph-augmented enterprise search (cross-industry)
- What: Add entity-relation extraction and bounded h-hop expansion to existing enterprise search for better multi-hop questions (e.g., “Which supplier impacted Q3 shipments via the July port closure?”).
- Tools/workflows: LLM entity extraction with resolution; graph scores with decay; merge graph-linked MAUs with hybrid search results; deterministic expansion rules.
- Assumptions/dependencies: Ontology design; extraction costs; entity resolution thresholds tuned per domain.
- RAG best-practice upgrades: set-union hybrid retrieval and pyramid expansion (software)
- What: Adopt set-union merging of dense and BM25 results (retain dense order, append sparse uniques) and pyramid expansion (summaries → details → raw) with explicit token budgets as drop-in improvements to existing RAG stacks.
- Tools/workflows: Minor retriever changes; token-budget schedulers; score thresholds for expansion.
- Assumptions/dependencies: Embedding quality; appropriate summary granularity; task-appropriate thresholds.
- Self-healing and auto-tuning for AI ops (software, MLOps)
- What: Integrate the paper’s autonomous repair patterns—e.g., detect API auth failures and auto-switch to local embeddings; detect output-format mismatches; revert versions after degradations; run metric-gated experiments on dev subsets.
- Tools/workflows: CI/CD hooks; versioned experiment runner; watchdogs for dependency/runtime exceptions; small dev slices for rapid evaluation; acceptance criteria (≥0.5% metric lift).
- Assumptions/dependencies: Clear scalar metric; safe rollback; sandboxed execution; change governance.
- Low-latency parallel retrieval in production (software)
- What: Use read-only FAISS/BM25 indices and multi-worker retrieval to increase throughput (3.5× observed) without sacrificing accuracy.
- Tools/workflows: Thread-safe index servers; batched similarity search; asynchronous context assembly.
- Assumptions/dependencies: Memory footprint for indices; backpressure handling; horizontal scaling.
Long-Term Applications
The following opportunities are high-impact but require further research, integration work, domain validation, or regulatory readiness.
- Longitudinal clinical memory assistant (healthcare)
- What: Unify EHR notes, imaging, lab trends, device telemetry, and patient messages as MAUs; novelty-filter redundant imaging frames; graph-link problems, meds, and events; answer multi-hop clinical queries with progressive evidence expansion.
- Potential products: Clinical copilot with explainable, provenance-attached answers; population-level recall for rare cases.
- Assumptions/dependencies: HIPAA-compliant pipelines; rigorous validation, bias and safety audits; on-prem or private-cloud LLMs; robust entity normalization to medical ontologies (SNOMED, RxNorm).
- Lifelong memory for embodied agents and robots (robotics)
- What: On-device selective ingestion of video/audio; MAUs as compact episodic memory; graph-linked maps of places/objects/tasks; pyramid expansion for task planning and failure recovery.
- Potential products: Service robots that recall prior failures or user preferences; warehouse/factory agents with persistent skills.
- Assumptions/dependencies: Edge compute constraints; efficient encoders; reliable novelty gating in dynamic scenes; safety certification.
- Federated, privacy-preserving organizational memory (enterprise, policy)
- What: Department-level MAU stores with shared knowledge-graph overlays and differential privacy; cross-team retrieval via graph bridges without raw data egress.
- Potential products: “Memory mesh” for regulated industries; zero-trust graph queries with auditable trails.
- Assumptions/dependencies: Federation standards; privacy tech (DP, HE, secure enclaves); identity/entitlement models; interop across vector/graph stores.
- Memory-centric agent operating system (software)
- What: Treat MAU memory as a first-class OS service for agent ecosystems—unified APIs for selective ingestion, hybrid retrieval, pyramid expansion, and KG reasoning—enabling plug-and-play agent tools.
- Potential products: Memory OS layer for agent platforms; marketplace of ingestion/graph plugins.
- Assumptions/dependencies: Standardization of MAU schema and APIs; ecosystem buy-in; performance SLOs.
- Regulatory-grade provenance and audit for AI decisions (finance, legal, public sector)
- What: Deterministic retrieval pipelines with graph-anchored citations that support ex post audits and “right to explanation,” including evidence-level expansion trails and versioned prompts.
- Potential products: Compliance dashboards; automated audit packs; FOIA-ready discovery tools.
- Assumptions/dependencies: Immutable logs; time-stamped MAUs; legal acceptance of AI-generated summaries; reproducible inference.
- Cognitive prosthetics and digital memory companions (daily life, accessibility)
- What: Assistive agents that help users recall events, commitments, and faces using multimodal memory; privacy-first on-device summarization with cloud cold storage.
- Potential products: Memory aids for aging populations or cognitive impairments; family history assistants.
- Assumptions/dependencies: Strong privacy and consent UX; on-device models; safety guardrails to avoid false memories.
- Cross-agent shared memory for complex workflows (software, manufacturing, logistics)
- What: Multiple specialized agents contribute MAUs and consume a shared KG to coordinate multi-hop tasks (procure → schedule → ship → service).
- Potential products: Agent swarms with persistent shared context; timeline-aware orchestration.
- Assumptions/dependencies: Conflict resolution and memory ownership; ACLs; consistency across concurrent writes.
- Sector-specific MAU ontologies and evaluation suites (academia, standards)
- What: Community-driven MAU schemas and KG relation sets for domains (biomed, law, education), plus standardized long-term memory benchmarks with scalar metrics to enable autoresearch loops.
- Potential products: Open benchmarks; certification suites; reference implementations.
- Assumptions/dependencies: Consortium governance; labeled datasets; sustainable funding for maintenance.
- Continual, autonomous improvement loops in production (MLOps, software)
- What: Extend AutoResearchClaw-style pipelines to continuously propose, test, and deploy memory/retrieval/prompt changes on shadow traffic with safety gates and automatic rollback.
- Potential products: “Autoresearch for production” platforms; guardrailed A/B/n for agent stacks.
- Assumptions/dependencies: Robust offline-to-online validation; change management; kill-switches; unbiased metrics.
- Privacy-preserving on-device multimodal memory (mobile, IoT)
- What: Local MAU creation and retrieval with occasional encrypted sync; on-device novelty filtering and small-footprint embeddings; energy-aware pyramid expansion.
- Potential products: Offline-capable personal assistants; smart cameras with contextual recall.
- Assumptions/dependencies: Efficient encoders; storage and power limits; secure key management.
- Education-at-scale tutors with durable student models (education)
- What: Tutors that maintain student knowledge graphs over months (concept mastery, misconceptions, artifacts), retrieving prior proofs/drafts and tailoring new problems with progressive evidence expansion.
- Potential products: Course copilots; accreditation-ready learning records.
- Assumptions/dependencies: Alignment with curricula and assessments; privacy protections for minors; fairness and accessibility audits.
Notes on feasibility and transferability
- Metric alignment: The paper shows that including full dialogue text can inflate token-overlap F1; in production, prefer user-centric metrics (task success, latency, cost) and human evaluation where needed.
- Model and cost constraints: Pyramid expansion and hybrid search reduce costs but still depend on LLM pricing/latency; local embeddings can mitigate outages/cost spikes.
- Data quality and extraction: Knowledge-graph gains hinge on reliable entity/relation extraction and resolution; domain-specific ontologies improve robustness.
- Governance and audit: Deterministic retrieval rules, versioned prompts, and full logs are essential for regulated settings.
- Interoperability: Standardizing the MAU schema and retrieval APIs will ease integration with existing vector DBs, search engines, and graphs.
Glossary
- Ablation study: A controlled removal of components to assess their individual impact on performance. "Table 2 presents an ablation study on LoCoMo"
- Agentic tree search: An LLM-driven exploration method that organizes decisions in a tree, enabling systematic trial and refinement without human-authored templates. "eliminating human-authored templates through agentic tree search."
- AutoML: Automated methods for exploring model and hyperparameter spaces without manual intervention. "traditional AutoML to explore effectively."
- AutoResearchClaw: A 23-stage autonomous research pipeline used to iteratively hypothesize, implement, and evaluate system improvements. "We deploy AutoResearchClaw~\citep{liu2026autoresearchclaw}, a 23-stage autonomous research pipeline,"
- BM25: A classic probabilistic ranking function used in information retrieval to score document relevance to a query. "BM25 scoring over MAU summaries yields keyword-matched candidates"
- Bounded neighborhood expansion: Graph traversal limited to a fixed number of hops to gather related entities around query seeds. "performs bounded neighborhood expansion within hops."
- CLIP: A vision-LLM that produces image-text embeddings suitable for measuring visual-semantic similarity. "For vision, CLIP embeddings are compared across consecutive frames to detect scene changes;"
- Dense retrieval: Retrieval based on vector similarity in embedding space rather than keywords. "dense retrieval via FAISS"
- Distance-decayed relevance: A scoring scheme that reduces entity relevance by its graph distance from query seeds. "distance-decayed relevance $r_{\mathcal{G}(v) = \beta^{d(v, \mathcal{V}_q)} \cdot \text{conf}(v)$"
- Embedding similarity: Measuring closeness between items based on their vector representations. "retrieves them via embedding similarity"
- Entity resolution: The process of merging different mentions of the same real-world entity to avoid graph fragmentation. "To prevent node fragmentation, entity resolution merges entities whose hybrid similarity, combining cosine similarity over name embeddings with Jaro-Winkler string similarity, exceeds a threshold."
- Entity-relation triples: Structured (subject, relation, object) facts extracted from text to populate a knowledge graph. "producing entity-relation triples."
- FAISS: A library for efficient nearest-neighbor search in high-dimensional spaces used for vector retrieval. "Dense retrieval uses FAISS with all-MiniLM-L6-v2 embeddings (384d);"
- h-hop search: Graph search that considers nodes within h edges from a starting node. "graph (-hop) search via set-union merging"
- Hot storage / cold storage: A two-tier memory design where small, frequently accessed metadata live in fast storage and large raw assets are kept in slower storage. "hot storage keeps summaries, embeddings, and temporal/graph metadata for fast retrieval, while cold storage keeps large assets (images, audio, video) and is accessed lazily through ."
- Hyperparameter optimization: Systematic search methods for selecting hyperparameters to improve model or system performance. "Hyperparameter optimization methods \citep{bergstra2011tpe,falkner2018bohb} efficiently navigate continuous and categorical spaces,"
- Jaccard overlap: A set similarity measure used here to identify near-duplicate texts. "Jaccard overlap with recent summaries filters near-duplicates."
- Jaro-Winkler string similarity: A string distance metric tailored for short strings and typographical differences, used for entity matching. "Jaro-Winkler string similarity"
- Knowledge graph: A graph of typed entities and relations that captures structured knowledge extracted from memories. "maintains a knowledge graph "
- Multimodal Atomic Units (MAUs): Compact, searchable memory records that couple summaries/embeddings with links to raw multimodal content. "Signals that pass the novelty filter are encapsulated as Multimodal Atomic Units (MAUs)"
- Neural Architecture Search: Automated exploration of neural network design spaces to find performant architectures. "Neural Architecture Search~\citep{hutter2019automl,zoph2017nas,liu2019darts} automates model design"
- Novelty-Based Filtering: Pre-ingestion filtering that discards redundant inputs by estimating informational novelty per modality. "Novelty-Based Filtering."
- Pyramid mechanism: A staged retrieval approach that expands from brief summaries to full details and raw content under budget constraints. "The pyramid mechanism then progressively expands the content"
- Prompt engineering: Crafting and structuring prompts to improve LLM performance on specific tasks. "prompt engineering (+188\% on specific categories)"
- Score-based re-ranking: Reordering retrieved items using combined scores; noted here to harm performance compared to union merging. "score-based re-ranking (the standard approach) disrupts semantic ordering and degrades performance."
- Set-union merging: A retrieval fusion strategy that preserves dense rankings and then appends sparse-only results. "A key discovery of the autonomous pipeline is set-union merging"
- Sparse keyword matching: Retrieval based on term matching rather than embeddings, typically using inverted indexes. "sparse keyword matching via set-union merging"
- Token budget: A fixed limit on the number of tokens allowed in the LLM context during retrieval/generation. "under a token budget B"
- Top-k: Selecting the k highest-scoring items in a ranked list for further processing. "for the top- candidates"
- VAD: Voice Activity Detection, which detects speech segments to filter out silence in audio streams. "VAD speech probability gates retention to reject silence;"
Collections
Sign up for free to add this paper to one or more collections.