- The paper demonstrates that classical optimizers excel in fixed hyperparameter spaces while LLMs, with agentic code editing and sufficient scale, approach similar performance.
- The study employs a controlled experimental protocol on nanochat, evaluating convergence speed, out-of-memory failures, and validation bits-per-byte metrics.
- The research introduces Centaur, a hybrid optimizer that integrates CMA-ES state sharing with LLM reasoning to improve search dynamics and reduce computational costs.
Comparative Analysis of LLM and Classical Hyperparameter Optimization on Unconstrained Search Spaces
Introduction and Motivation
LLMs have demonstrated agentic capabilities, including direct code editing, leading to investigations into their utility for hyperparameter optimization (HPO) tasks that have traditionally relied on classical algorithms. The paper "Can LLMs Beat Classical Hyperparameter Optimization Algorithms? A Study on autoresearch" (2603.24647) addresses the question of whether LLMs, as autonomous agents, can outperform established HPO methods such as Covariance Matrix Adaptation Evolution Strategy (CMA-ES), Tree-structured Parzen Estimator (TPE), and SMAC in real-world model training settings. The study utilizes the autoresearch benchmark, where LLMs can edit the training code directly in an unconstrained space, and contrasts their performance with classical optimizers operating over both fixed and agentic search spaces. Furthermore, the paper introduces Centaur, a hybrid optimizer integrating the internal state of CMA-ES with LLM reasoning, and systematically evaluates the scaling behavior, reliability, and search dynamics of all approaches within a controlled experimental regime.
Experimental Protocol
The evaluation is conducted on nanochat, a 50M-parameter LLM trained on FineWeb, with the goal of minimizing validation bits-per-byte (val_bpb). The search space includes 14 hyperparameters, auto-extracted via Abstract Syntax Tree (AST) parsing, minimizing manual curation. Each HPO run is strictly budgeted to 24 hours of GPU time (three seeds per method), and includes a penalty protocol for out-of-memory (OOM) failures by assigning a worst-case val_bpb of 100.0, ensuring that infeasible configurations are appropriately discouraged during optimization. For LLM-based methods, Qwen3.5-27B and Qwen3.5-0.8B are used in both fixed and code-editing agentic settings, while classical methods leverage established implementations in Optuna.
Classical optimizers exhibit clear superiority within a fixed, well-defined hyperparameter space, with both faster convergence and better final val_bpb compared to pure LLM methods. CMA-ES and TPE consistently find optimal configurations more efficiently, maintaining lower OOM rates and reliably learning to avoid infeasible regions—capabilities LLMs fail to replicate despite access to full trial history. Notably, several fixed-space LLM methods underperform even random search, confirming that current LLMs (even at 27B scale) do not leverage search trajectory information as effectively as classical algorithms unless their agentic, code-editing capabilities are engaged.
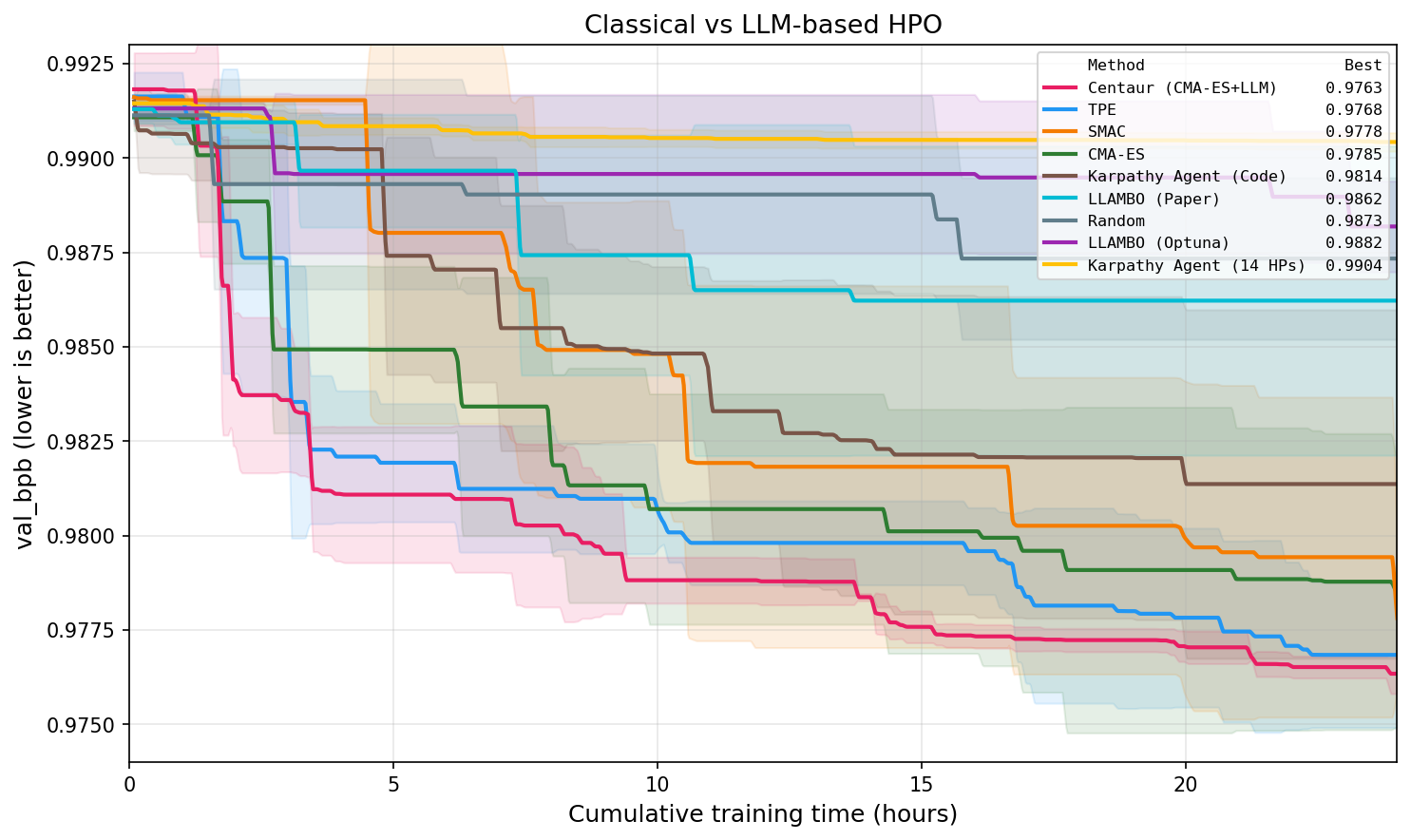
Figure 1: Best validation bits-per-byte (mean ± std across 3 seeds) of HPO algorithms versus cumulative training time, showcasing the faster and superior convergence of classical optimizers and the Centaur hybrid relative to pure LLM-based methods.
This result holds across multiple metrics and seeds; the best classical methods (TPE, SMAC, CMA-ES) converge to val_bpb <0.9785, while fixed-space LLM approaches (e.g., LLAMBO) trail with mean best around $0.9862$ (Qwen3.5-27B). High OOM rates are observed for state-tracking LLM methods (up to 61%), highlighting their inability to consistently internalize optimization constraints compared to explicit-state classical optimizers.
Unconstrained Agentic Optimization and Model Scaling
When the LLM agent is permitted to directly edit the training source code (Karpathy Agent (Code)), the performance gap with classical algorithms narrows significantly, though classical methods still consistently reach better configurations faster. Importantly, unconstrained agentic optimization appears fundamentally sensitive to LLM model size: the 0.8B variant is insufficient, while 27B achieves competitive results in code-editing mode; however, increasing model size confers no benefit (and may mildly degrade performance) for fixed-HP optimization.
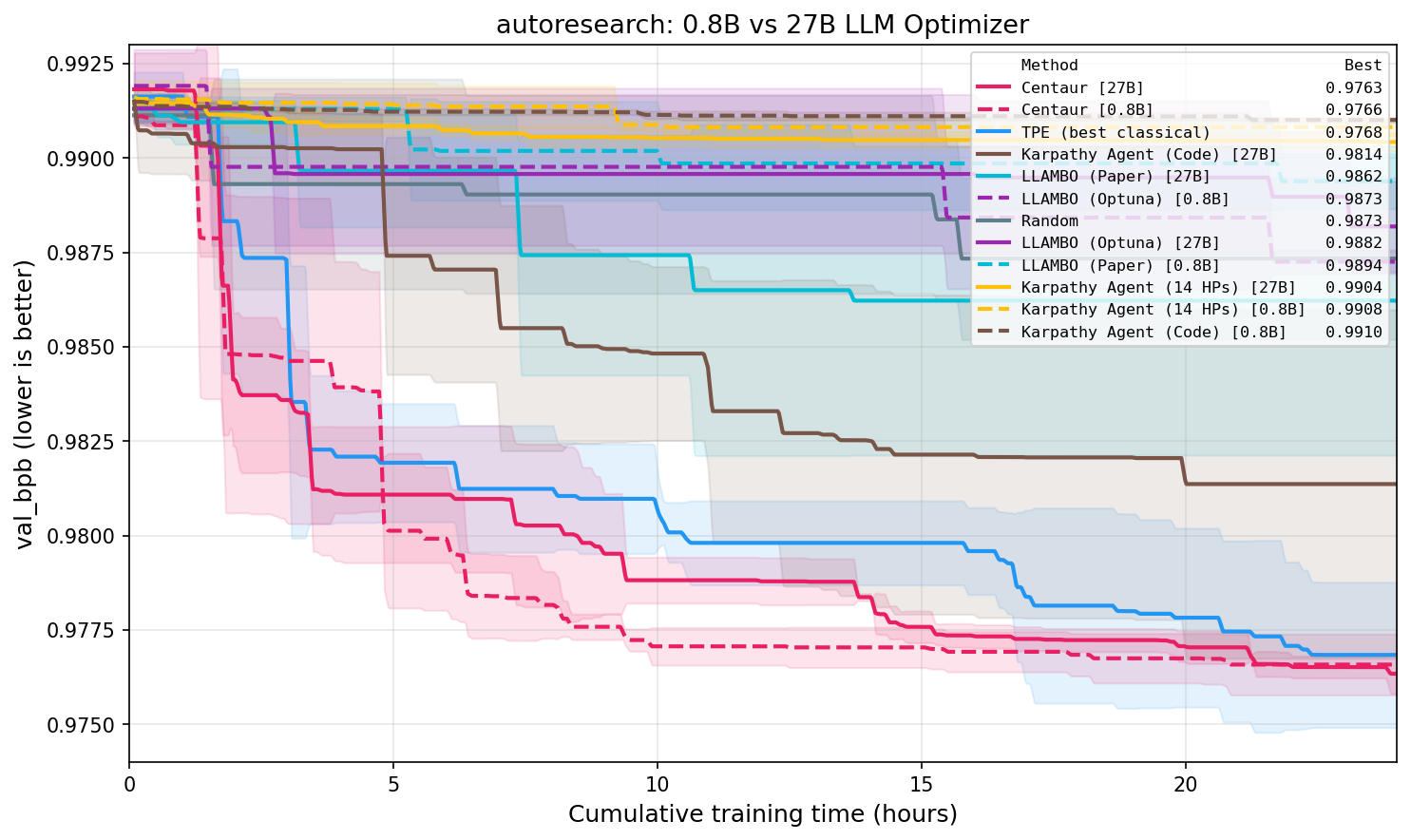
Figure 3: Comparison of Qwen3.5-27B and 0.8B as LLM optimizers (wall-time); only the 27B model matches agentic code-editing performance, while both are adequate for hybrid fixed-space optimization.
This observation establishes a clear dichotomy: strong foundation model capabilities are required for unconstrained, agentic optimization, but are superfluous (and potentially inefficient) when the LLM is merely perturbing suggestions within a bounded configuration space defined by a classical optimizer.
Centaur: Hybridization of CMA-ES and LLM Reasoning
Centaur is proposed as a tightly-coupled hybrid optimizer where CMA-ES explicitly shares its mean vector, step-size, and covariance matrix with the LLM on a controlled fraction of trials. The LLM then proposes refined configurations, nearly always overriding CMA-ES’s proposal (100% of the time for 27B, 95% for 0.8B). All results, LLM-modified or CMA-ES-proposed, feed back into CMA-ES’s state updates, closing the optimization loop and preserving the exploration-exploitation tradeoff inherent to classical ES.
Centaur outperforms all solo and other hybrid methods, with the best mean best val_bpb at $0.9763$ (0.0005 std) for the 27B variant, slightly exceeded by the 0.8B variant under specific ablation settings. The stability provided by combining domain knowledge induction from the LLM with explicit optimization state from CMA-ES leads to consistently lower variance across seeds, improved incumbent-tracking, and robust OOM avoidance. The fraction of LLM-powered trials is critical: excessive reliance on the LLM (e.g., LLM ratio r>0.5) leads to performance degradation, especially at 27B scale.
Practical and Theoretical Implications
The findings have notable implications:
- LLM code-editing agents attain near-parity with classical HPO only when allowed unconstrained, agentic operation and run at sufficient scale (≥27B), but do not surpass state-of-the-art classical search when restricted to fixed spaces.
- Hybridization, specifically high-frequency information sharing from CMA-ES to the LLM with proportionally limited LLM-driven updates, can match or exceed classical methods at reduced computational cost, with smaller LLMs sufficing when paired with strong classical optimizers.
- OOM avoidance and reliable state-tracking are more detrimental to optimization trajectory than marginal improvements in search diversity, indicating the value of explicit constraint modeling.
- Fixed search space methods benefit minimally from increased LLM scale with open-weight models, suggesting diminishing returns unless code-editing behaviors are deployed.
Future Outlook for LLMs in AutoML
These results suggest that powerful, frontier LLMs may eventually outperform classical optimizers in agentic, unconstrained search spaces, provided advances in context tracking and exploration-exploitation balancing. The study identifies several future work directions:
- Benchmarking agentic LLM optimizers with even larger or more capable models in code-editing scenarios,
- Co-evolving search spaces and configurations by integrating code-editing agents with classical optimizers,
- Generalizing the hybrid Centaur philosophy to other classical base optimizers or to broader domains beyond language modeling.
Conclusion
The paper systematically demonstrates that, under controlled compute budgets and constraints, classical HPO algorithms such as CMA-ES and TPE remain superior to LLM-based agents within fixed configuration spaces. Unconstrained code-editing LLMs notably approach classical HPO performance, but require large model scales to be viable. Hybrid methods—exchanging information-rich optimizer state with the LLM at carefully tuned frequencies—emerge as the most effective paradigm, bridging model-based and agentic reasoning. This line of research provides a rigorous comparative framework for future AutoML systems that seek to judiciously combine classical search with the domain-informing capabilities of LLMs, paving the way for next-generation agentic AutoML methodologies.