Agentic Learner with Grow-and-Refine Multimodal Semantic Memory
Abstract: MLLMs exhibit strong reasoning on isolated queries, yet they operate de novo -- solving each problem independently and often repeating the same mistakes. Existing memory-augmented agents mainly store past trajectories for reuse. However, trajectory-based memory suffers from brevity bias, gradually losing essential domain knowledge. More critically, even in truly multimodal problem-solving settings, it records only a single-modality trace of past behavior, failing to preserve how visual attention and logical reasoning jointly contributed to the solution. This is fundamentally misaligned with human cognition: semantic memory is both multimodal and integrated, preserving visual and abstract knowledge through coordinated but distinct representational streams. We thus introduce ViLoMem, a dual-stream memory framework that constructs compact, schema-based memory. It separately encodes visual distraction patterns and logical reasoning errors, enabling MLLMs to learn from their successful and failed experiences. Following a grow-and-refine principle, the system incrementally accumulates and updates multimodal semantic knowledge -- preserving stable, generalizable strategies while avoiding catastrophic forgetting. Across six multimodal benchmarks, ViLoMem consistently improves pass@1 accuracy and substantially reduces repeated visual and logical errors. Ablations confirm the necessity of dual-stream memory with explicit distraction--hallucination separation, demonstrating the value of error-aware multimodal memory for lifelong and cross-domain agentic learning. Our project page will be available at https://weihao-bo.github.io/ViLoMeo-page.



Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
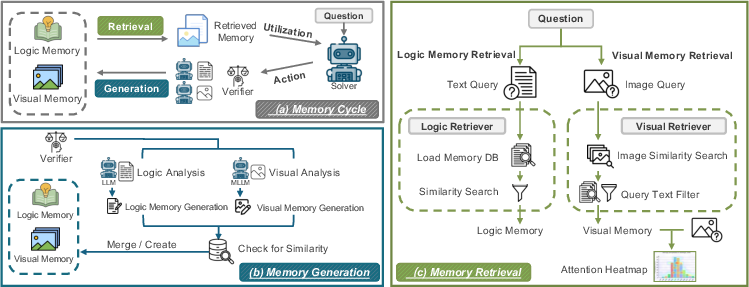
This paper introduces a way for AI models that read both text and images (called “multimodal” models) to learn from their mistakes over time, instead of treating every new problem like the first time. The authors build a special memory system—like two coordinated notebooks—that helps the AI remember:
- where to look in a picture (visual memory), and
- how to reason step by step (logical memory).
By separating and then combining these two kinds of memory, the AI can avoid repeating old mistakes and solve future problems better.
What questions did the researchers ask?
The paper focuses on three simple questions:
- Can AI remember and reuse lessons from past successes and failures instead of starting from scratch each time?
- Do AIs need different kinds of memory for “what to look at” in images versus “how to think” logically?
- Will this kind of memory actually improve accuracy on tough tests, especially ones that mix images and math?
How does their method work?
The big idea: two coordinated notebooks
Imagine a student with two notebooks:
- Visual notebook: tips about what parts of a picture matter and common visual traps (for example, “look at the triangle’s base, not the shadow”).
- Logical notebook: rules and strategies for correct reasoning (for example, “use the base×height formula for the triangle’s area, but only after you’ve identified the base correctly”).
The AI keeps both notebooks and uses them together: one guides attention (where to look), the other guides thinking (how to reason).
The learning loop: try, check, and update
Each time the AI solves a problem with an image:
- Retrieve helpful notes from both notebooks.
- Try to solve the problem using those notes.
- A checker (a “verifier”) sees if the answer is right.
- If it’s wrong, the system figures out what kind of mistake happened:
- Visual mistake (looked at the wrong thing or misread the image)?
- Logical mistake (used the wrong formula or flawed reasoning)?
- It then writes or updates the right notebook with a short guideline.
Over time, the AI’s notebooks “grow and refine,” keeping good, general tips and merging duplicates—like tidying a study guide.
Two kinds of memories, stored differently
- Visual memory: Short, clear tips tied to example images, explaining common visual distractions and how to avoid them (for example, “don’t confuse reflections with edges”).
- Logical memory: Short reasoning rules that fit problem types (for example, “don’t assume a point lies on a perpendicular bisector unless proven”).
Finding the right memory at the right time
Picking the best memory is a two-part search:
- Visual memory retrieval: 1) First match by image similarity (find past images that look like the current one). 2) Then filter by the current question’s text to get the most relevant visual tips. The system can also create “attention maps”—like highlighting the important part of the picture—to point the AI toward the right region.
- Logical memory retrieval: The AI briefly analyzes the question to figure out its topic and reasoning needs (e.g., geometry with areas) and then fetches the best matching rules.
Keeping memory clean and useful
When a new tip looks very similar to an old one, they get merged to avoid clutter. This “grow-and-refine” process helps the AI keep its notes short, sharp, and general, while preventing “forgetting” older, still-useful tips.
What did they find, and why is it important?
Here are the main takeaways:
- Better scores across many tests: On six multimodal benchmarks (including tough math-with-diagrams tests), the method improved how often the first answer was correct. The gains were especially strong for math + image problems (in some cases, up to around 6 points higher).
- Visual mistakes are a big deal: When the system analyzed errors, most were visual—looking at the wrong place, misreading symbols, or mixing up shapes—not purely logical ones. Fixing where to look helped reduce bad reasoning later.
- Both memory types matter: Turning off either visual or logical memory hurt performance. Using both together worked best.
- Small models learn a lot from big models’ memories: A smaller AI did better when using memories created by a stronger AI—like studying from a top student’s notebook—without retraining the small model.
- Domain-specific memory works best: Memories from related tasks helped, but using memories from very different tasks sometimes caused confusion. Task-matched memories gave the best results.
These results matter because they show that better “study habits” (smart memory) can make AIs more reliable and less likely to repeat old mistakes, especially on real-world tasks that need both seeing and thinking.
What does this mean for the future?
- Smarter, steadier learning: AI can improve like a student—accumulating lessons over time instead of starting fresh with each question.
- Fewer “hallucinations”: By tying reasoning to the right parts of an image, the AI is less likely to invent facts or misread diagrams.
- Helpful for education and science: Tasks that combine pictures and reasoning—like geometry diagrams, lab charts, or medical images—stand to benefit the most.
- Sharing knowledge safely: Smaller AIs can borrow well-structured memories from stronger AIs without complicated retraining.
- Next steps: Make visual and logical memory even better at staying separate but coordinated, and create more precise attention tools for tricky diagrams.
In short, the paper shows a practical way to make AI more “agent-like”: it learns from experience, remembers both what to look at and how to think, and gets steadily better at solving multimodal problems.
Knowledge Gaps
Knowledge Gaps, Limitations, and Open Questions
Below is a concise, actionable list of what remains missing, uncertain, or unexplored in the paper—aimed at guiding future research.
- Error attribution fidelity: No quantitative evaluation of how accurately the system assigns failures to the visual vs. logical stream; build a labeled benchmark to measure attribution precision/recall and the impact of misattribution.
- Visual attention mechanism details and efficacy: The method for generating “question-aware attention maps” from keyword cues is under-specified and only modestly helpful on diagram-heavy tasks; compare principled attention methods (e.g., Grad-CAM, saliency, segmenters) and measure localization quality (e.g., IoU, focus overlap).
- Cascading failure causality: The claim that visual errors cause downstream logical hallucinations is supported by ablations but lacks causal evidence; design interventions that selectively correct visual cues to quantify causal effects on logical error rates.
- Memory quality control and robustness: The framework assumes LLM/MLLM-generated guidelines are correct; develop mechanisms for memory auditing (confidence scoring, cross-validation, human-in-the-loop sampling), noise tolerance, and rollback of harmful entries.
- Merge/update policy rigor: The grow-and-refine merge operations rely on static similarity thresholds; provide sensitivity analyses (k, τ values), compare alternatives (learned thresholds, clustering, graph-based consolidation), and quantify detail erosion vs. redundancy removal.
- Memory scalability and efficiency: No analysis of memory growth, retrieval latency, or compute overhead as banks scale; profile time/space costs, index structures (e.g., FAISS/ANN variants), and memory compaction strategies.
- Negative transfer detection and mitigation: Cross-benchmark interference is observed but unmanaged; design domain-aware gating, automatic domain detection, and dynamic routing/blacklisting of memories that degrade performance.
- Task/domain segmentation strategy: Distinct memory banks per benchmark are assumed; explore automatic domain taxonomy induction, continual domain discovery, and unified multi-domain memory with conflict resolution.
- Retrieval robustness to faulty analyses: Logical retrieval depends on LLM-based problem analysis that may be wrong; quantify failure modes and evaluate lightweight or hybrid analyzers (rule-based, few-shot classifiers) for more reliable enrichment.
- Visual retrieval coverage: Two-stage retrieval may miss semantically similar but visually dissimilar cases (style/diagram variations); assess recall across visual styles and incorporate structure-aware features (e.g., keypoint graphs, vectorized diagrams).
- Repeated error reduction metrics: Claims of fewer repeated visual/logical errors are not tied to standardized metrics; define and report repetition rates by error type and the reduction attributable to memory.
- Statistical rigor and reproducibility: Results lack variance, confidence intervals, and significance tests; include multi-run statistics, seed control, and standardized eval scripts to establish robust gains.
- Ground-truth dependence and real-world deployment: The verifier relies on correct answers—often unavailable in practice; explore weak/implicit signals (self-consistency, agreement among solvers, outcome-based validation) for memory updates without ground-truth.
- Privacy and safety of stored traces: Persistent storage of images and reasoning traces raises privacy/bias risks; propose anonymization, PII filtering, access control, and bias audits in memory entries.
- Comparison to parameter adaptation: The plug-in memory approach is not compared to fine-tuning, adapters, or retrieval-augmented training; quantify trade-offs in accuracy, stability, and cost across strategies.
- Attention precision for diagram tasks: Current attention augmentation is coarse; investigate fine-grained spatial guidance (edge/vertex detectors, layout parsing, program-of-vision) and its integration into the solver.
- Quality dependence on memory generators: Memory is generated by large models; evaluate how generator quality affects downstream gains and whether lightweight generators can produce usable memories.
- Multi-agent memory sharing: Cross-model transfer helps smaller models, but protocols for multi-agent memory sharing, deduplication, and conflict resolution are unspecified; design standardized memory schemas and trust scoring for collaborative settings.
- Lifelong learning guarantees: Catastrophic forgetting is claimed to be avoided but not formally measured; track retention/persistence of specific guidelines over long horizons and quantify forgetting/resilience.
- Retrieval thresholds and k-values: No sensitivity analysis for top-k and τ parameters; provide principled selection (validation curves, adaptive selection) and their impact across tasks and models.
- Failure cases in visually complex settings: The verifier struggles when solvers provide poor visual descriptions; develop perception-aware verification (using scene parsing, symbol detection) to reliably extract visual errors despite weak traces.
- Generalization beyond static benchmarks: The framework is tested on independent QA tasks; evaluate on sequential/interactive settings (multi-step, long-horizon) where memory and context evolve over episodes.
- Multilingual and cross-format robustness: Memory schemas, embeddings, and retrieval are text-centric; assess performance across languages and formats (structured diagrams, code, equations), and extend indexing beyond plain text.
Practical Applications
The paper introduces ViLoMem, a plug-in dual-stream memory framework for multimodal LLMs that separates visual distraction errors from logical hallucinations, constructs compact schema-based memories, and uses specialized retrieval (image-text two-stage for visual; precise positioning for logic) with grow-and-refine updates. This reduces repeated errors, improves pass@1 on multiple benchmarks, enables cross-model memory transfer, and supports lifelong multimodal learning without fine-tuning.
Below are actionable applications grouped by deployment horizon. Each item names specific use cases, links to sectors, suggests tools/products/workflows, and notes assumptions/dependencies that affect feasibility.
Immediate Applications
- Memory-augmented multimodal copilots for enterprise technical support (triaging tickets with screenshots, logs, and diagrams)
- Sector: Software/IT services
- Tools/products/workflows: ViLoMem “middleware” for MLLM copilots; question-aware attention overlays that highlight relevant UI regions; dual-stream memory bank seeded with common visual and logical traps in target products
- Dependencies: Access to historical support cases and ground-truth resolutions; embedding services; privacy controls for storing images and traces; threshold tuning for retrieval to avoid irrelevant memory interference
- STEM tutoring systems that learn from student-specific visual and logical mistakes in diagram-based math, physics, and geometry
- Sector: Education/EdTech
- Tools/products/workflows: Student-specific dual-stream memory profiles; autograder-backed verifier; adaptive problem selection using memory schemas; classroom dashboards for error analysis
- Dependencies: Reliable solution checking (ground truth or grader); parental/FERPA-like data protections; domain-aligned memory banks to avoid cross-domain interference
- Document, diagram, and chart understanding for RPA and back-office workflows (forms, schematics, technical drawings)
- Sector: Enterprise automation
- Tools/products/workflows: “Visual trap library” for OCR/chart-reading (e.g., axis misreads, symbol confusion); two-stage retrieval to condition visual guidance on specific task prompts; memory-curation pipelines for each document type
- Dependencies: High-quality inputs (scans/images); consistent annotation or validation signals; integration with existing OCR/IDP systems
- Business intelligence and analytics QA (sanity-checking charts, dashboards, and visual reports to reduce misinterpretation)
- Sector: Finance/BI/Analytics
- Tools/products/workflows: Chart QA copilot; logical memory schemas for statistical reasoning; visual memory for frequent chart pitfalls (log scales, stacked bars, missing legends)
- Dependencies: Clear correctness criteria; access to underlying data for verification; governance to prevent overreliance on memory in ambiguous cases
- Safety and reliability guardrails for multimodal agents (reducing hallucinations via error-aware memory)
- Sector: AI operations (MLOps/LLMOps)
- Tools/products/workflows: Memory audit dashboards; verifier-driven memory updates; benchmark-aligned domain banks; alerting for repeated error patterns
- Dependencies: Comprehensive test suites; LLM-as-a-judge or rule-based verifiers; storage governance and provenance tracking
- Cross-model memory distillation to boost small MLLMs in constrained deployments
- Sector: Model providers/edge deployments
- Tools/products/workflows: Memory export/import interfaces; schema alignment across models; “memory packs” derived from stronger models to bootstrap weaker ones
- Dependencies: Licensing/compliance for cross-model artifacts; compatibility of embeddings; domain match between source and target tasks
- Screen-reading RPA bots with question-aware attention to click the correct UI elements
- Sector: Enterprise automation/IT operations
- Tools/products/workflows: Attention overlays shared with the agent; workflow recipes that pair visual cues with logical task steps
- Dependencies: Stable UI representations; mapping between tasks and UI states; performance constraints for real-time interaction
- Content moderation and misinformation checks for multimodal posts (flagging visual–text inconsistencies)
- Sector: Trust & Safety
- Tools/products/workflows: Hallucination guardrails using visual memory schemas (known illusions, altered content markers); logic schemas for common fallacies
- Dependencies: Policy thresholds; appeals processes; careful handling of ambiguous or satirical content
- Scientific and engineering copilot for diagram-heavy tasks (lab problems, competition-style math, mechanics schematics)
- Sector: Research and engineering
- Tools/products/workflows: Domain-specific memory packs (geometry, circuits, materials); solver workflows integrating dual memory under step-by-step reasoning
- Dependencies: Task-aligned memory banks; reliable ground-truth checking for iterative refinement
- Photo-based consumer assistance (DIY, home improvement, appliance troubleshooting)
- Sector: Consumer apps
- Tools/products/workflows: Mobile assistants that retrieve visual guidelines for common misreads (e.g., mislabeled parts, perspective distortions); attention hints on photos
- Dependencies: Seeding memory with domain-specific traps; variability in user images; lightweight on-device or privacy-preserving memory storage
Long-Term Applications
- Clinical decision support with error-aware visual memory (radiology/pathology) to mitigate perceptual traps and reasoning biases
- Sector: Healthcare
- Tools/products/workflows: Regulated dual-stream memory integrated into clinical workflows; robust verifier using adjudicated labels; audit trails for memory usage
- Dependencies: Large-scale, diverse, labeled medical datasets; rigorous clinical validation; regulatory approvals; strong privacy/security controls
- Autonomous systems that avoid recurring perception mistakes (robots, drones, vehicles) via visual–logic memory coordination
- Sector: Robotics/Autonomous vehicles
- Tools/products/workflows: Real-time memory retrieval with low-latency attention maps; SLAM/scene-understanding integration; safety-case documentation linking memory to risk reduction
- Dependencies: Deterministic latency budgets; certification and safety standards; domain-specific memory construction (weather, lighting, materials)
- AR guidance for technicians and field workers (question-aware attention overlays on equipment during inspection/repair)
- Sector: Industrial/energy/manufacturing
- Tools/products/workflows: AR UIs rendering attention maps; equipment-specific visual schemas; workflows pairing visual cues with procedural logic
- Dependencies: Accurate pose estimation and device calibration; robust on-device memory; occupational safety compliance
- Memory governance, provenance, and standards for external memory artifacts used by AI
- Sector: Policy/Compliance
- Tools/products/workflows: Memory registries, versioning, and provenance chains; disclosure requirements for memory-assisted decisions; conformance tests to detect cross-domain interference
- Dependencies: Industry and regulatory consensus on memory transparency; privacy-preserving storage; auditability and explainability standards
- Cross-organization “error schema” exchanges and marketplaces (shared libraries of visual/logical traps)
- Sector: Software ecosystems/platforms
- Tools/products/workflows: Memory-sharing protocols; domain curation services; incentive mechanisms for high-quality contributions
- Dependencies: IP/licensing models; differential privacy for sensitive domains; schema interoperability across models/vendors
- Training-time continual learning that uses ViLoMem to update model weights (beyond prompt-level memory)
- Sector: AI research and foundation model development
- Tools/products/workflows: Weight-update pipelines informed by memory schemas (curriculum from visual/logic errors); catastrophic forgetting mitigation strategies
- Dependencies: Stable algorithms for integrating external memory into parametric learning; compute budgets; evaluation to avoid overfitting to memory artifacts
- Longitudinal learner models in education that track visual–logical error evolution across years/courses
- Sector: Education
- Tools/products/workflows: Cohort-level analytics; adaptive curricula shaped by class-wide memory; teacher-facing dashboards
- Dependencies: Long-term data retention policies; consent; robust de-identification; interoperability across platforms
- Industrial inspection and anomaly detection with persistent memory of false positives and context-specific visual traps
- Sector: Energy, manufacturing, logistics
- Tools/products/workflows: Inspection copilots; visual memory tuned to equipment/materials; logic schemas for defect classification criteria
- Dependencies: Domain-specific labels; multi-modal sensor fusion; operational safety constraints
- Compliance-ready financial analysis of charts and visual disclosures to reduce misinterpretation risk
- Sector: Finance/regulatory compliance
- Tools/products/workflows: Memory-backed reviewers for investor materials; logic schemas for statistical claims; audit logs of memory usage in decisions
- Dependencies: Access to underlying datasets; regulatory acceptance of memory-assisted review; clear definitions of correctness and materiality
- Multimodal knowledge bases for scientific discovery (integrating visual evidence with conceptual reasoning over time)
- Sector: Academia/Research
- Tools/products/workflows: Lab-specific memory repositories; cross-domain retrieval with task-aligned banks; collaborative error analysis across teams
- Dependencies: High-quality curation; standards for sharing and citing memory artifacts; tools for resolving domain conflicts in retrieval
Notes on feasibility across applications:
- ViLoMem depends on reliable verifiers or ground-truth signals to attribute errors and update memory. In settings lacking explicit labels, proxy signals (LLM-as-a-judge, rule-based checks) are required and may introduce noise.
- Domain alignment is critical: cross-domain memories can cause interference; task-specific banks and retrieval thresholds must be tuned.
- External memory introduces governance needs (privacy, security, provenance, auditability), especially when storing images and traces.
- Real-time applications (robotics, AR, autonomous systems) require optimized retrieval and attention map generation under strict latency constraints.
- Cross-model memory transfer improves weaker models but relies on schema compatibility and licensing/compliance for shared artifacts.
Glossary
Abstractive Models: Abstractive models generate new text that captures the essence of input data rather than repeating specific phrases verbatim. "Yet despite their growing capability, current MLLMs approach each problem de novo—solving every query in isolation, repeatedly re-deriving the same insights and re-committing familiar errors."
Attention Maps: Visual overlays that highlight regions in an image considered important for a specific task, improving model focus. "To achieve question-aware attention, we generate cross-modal attention maps guided by keywords (previously observed visual mistakes), enabling the model to highlight regions associated with known error patterns relevant to the current question."
Catastrophic Forgetting: A phenomenon where a model forgets previously learned information upon learning new content, often seen in sequential learning tasks. "Following a grow-and-refine principle, ViLoMem avoids the detail erosion caused by iterative rewriting by filtering similar error patterns and using tailored add/skip and retrieval strategies to incrementally accumulate multimodal semantic knowledge."
Hallucination Errors: Errors where a model generates information that is syntactically plausible but factually incorrect or unrelated to the input. "This indicates visual attention errors directly cause downstream logical hallucinations that create a cascading failure pattern."
Hub-and-Spoke Architecture: A model structure wherein multiple feature-specific modules (spokes) are integrated by a central module (hub) for unified processing. "Inspired by this architecture, our AI system implements an error-aware multimodal semantic memory, where visual and logical error patterns are stored in separate modality-specific modules."
Interference: A degradation in model performance due to conflicting information, often seen in cross-domain learning. "Ablation studies confirm that both memory streams are essential and complementary, exhibiting heterogeneous effects across benchmarks--task-aligned domains benefit from shared memory, whereas mismatched domains can lead to interference."
Multimodal LLMs (MLLMs): LLMs capable of understanding and generating insights from multiple data modalities, such as text and image. "Multimodal LLMs (MLLMs) have achieved impressive progress in scene understanding, visual question answering, and complex scientific problem solving."
Perceptual Cues: Visual or sensory information used by models to understand and differentiate features in data. "Although recent memory-augmented models attempt to mitigate this by storing past interactions, these memories capture only high-level logical summaries while discarding the visual grounding and perceptual cues essential for multimodal reasoning."
Trajectory-Based Memory: A type of memory storage focused on recording the sequence of steps a model takes during problem-solving. "Existing memory-augmented agents mainly store past trajectories for reuse."
Visual Attention Errors: Mistakes arising from incorrect focus or interpretation of visual information, impacting subsequent reasoning steps. "This indicates visual attention errors directly cause downstream logical hallucinations that create a cascading failure pattern."
Visual Distraction Patterns: Identifiable elements in visual data that divert attention from relevant information and cause errors. "It separately encodes visual distraction patterns and logical reasoning errors, enabling MLLMs to learn from their successful and failed experiences."
Collections
Sign up for free to add this paper to one or more collections.

