- The paper proposes TRIMS to optimize DLM decoding trajectories, significantly boosting tokens per step while preserving high accuracy.
- It employs an AR teacher for token difficulty estimation, quantile bucketization, and curriculum-inspired masking to enhance decoding order.
- Experiments on math and coding benchmarks show 2–3× improvements over baselines with minimal additional computation.
Trajectory-Ranked Instruction Masked Supervision for DLMs
Motivation and Context
Diffusion LLMs (DLMs) offer significant architectural flexibility in text generation, leveraging iterative masked denoising to enable bidirectional parallel decoding. While DLMs theoretically promise greater inference throughput and reduced latency compared to autoregressive (AR) decoders, their empirical efficiency is bottlenecked by decoding trajectories—the order in which tokens are revealed during generation. Standard training with sample-agnostic, uniformly random masking does not optimize for this trajectory, resulting in models that often default to local, AR-like or inefficient token reveal orders at inference time. Recent distillation- and RL-based interventions address this mismatch but are encumbered by costly offline trajectory sampling or data curation pipelines.
The TRIMS Framework
TRIMS (Trajectory-Ranked Instruction Masked Supervision) introduces an end-to-end supervised fine-tuning methodology for improving DLM decoding trajectory, with minimal computational overhead. TRIMS circumvents the need for diffusion-based distillation or resource-intensive RL by constructing low-cost and high-signal trajectory supervision via an AR teacher model.
The procedure follows three essential stages:
- Token Difficulty Estimation: An autoregressive teacher is applied in teacher-forcing mode to all tokens in the training set, gathering negative log-likelihood (NLL) as token difficulty scores; these represent the teacher's uncertainty on each prediction.
- Bucketization of Difficulty Signals: The continuous difficulty scores are quantile-discretized into K ordinal buckets. This step induces a partial order over the completion tokens, stratifying them from most to least difficult.
- Trajectory-Aware Masked Fine-Tuning: During MDLM training, the bucket assignments drive a curriculum-inspired masking scheme: for each example, a threshold bucket is sampled, tokens up to the threshold are unmasked as context, while tokens above are masked and directly supervised. The masking probabilities for future and context tokens are set to 0.95 and 0.05, respectively, to maintain robustness.
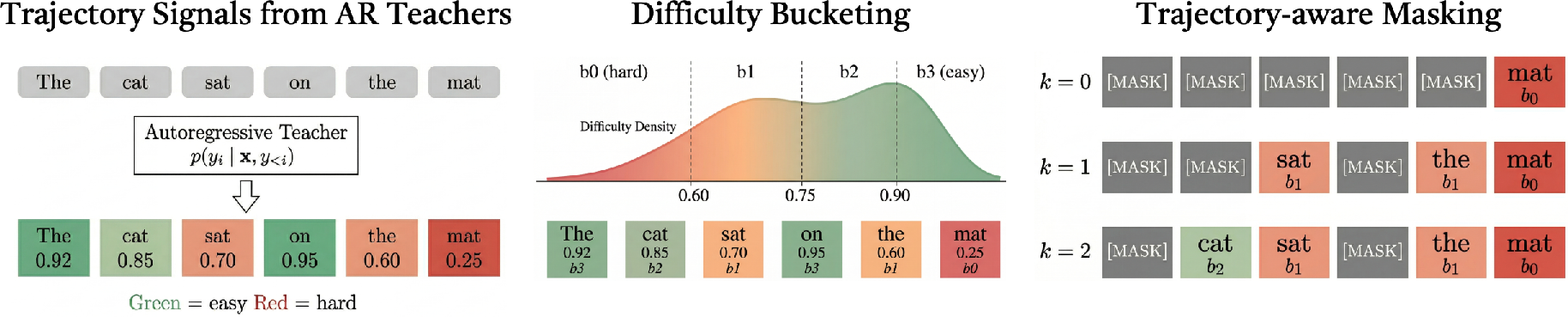
Figure 1: The TRIMS pipeline: AR teacher-based difficulty estimation, quantile bucketing, and staged masking simulate a hard-to-easy decoding curriculum.
Notably, TRIMS modifies only 10% of training batches with the trajectory-aware mask; the remainder follow standard random masking, stabilizing alignment with the initialization distribution.
Experimental Analysis
TRIMS is evaluated on the LLaDA-Instruct and Dream-Instruct open-source DLMs, targeting math (GSM8K, MATH) and coding (HumanEval, MBPP) benchmarks. Performance is measured along two axes: accuracy (solved instances) and parallelism (tokens predicted per step, TPS). Comparison encompasses train-free accelerations (Fast-dLLM, D2F), training-based methods (Fast-dLLM-v2), and distillation-based methods (dParallel, d3LLM). The AR teacher employed for trajectory extraction is Qwen3-8B.
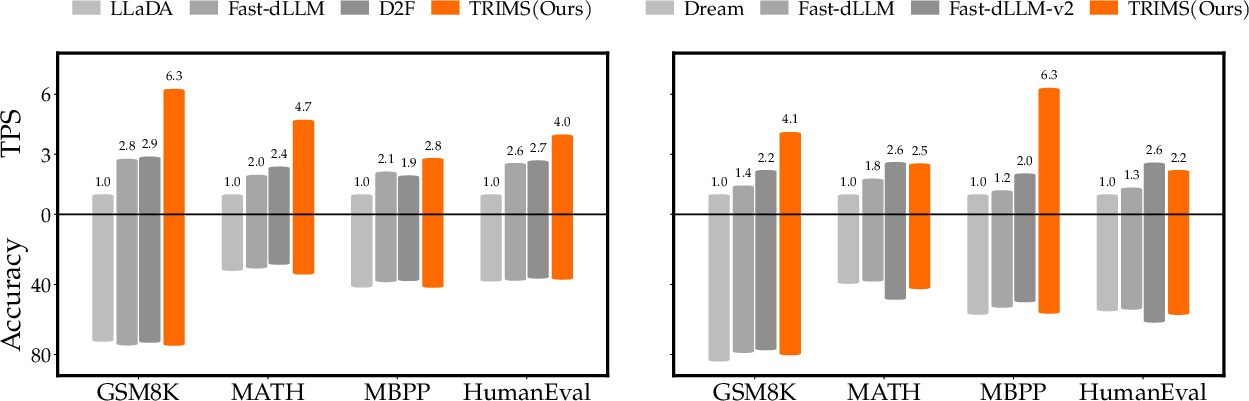
Figure 2: TRIMS markedly improves the accuracy-parallelism trade-off on both LLaDA-Instruct and Dream-Instruct, exceeding distillation-based methods in efficiency.
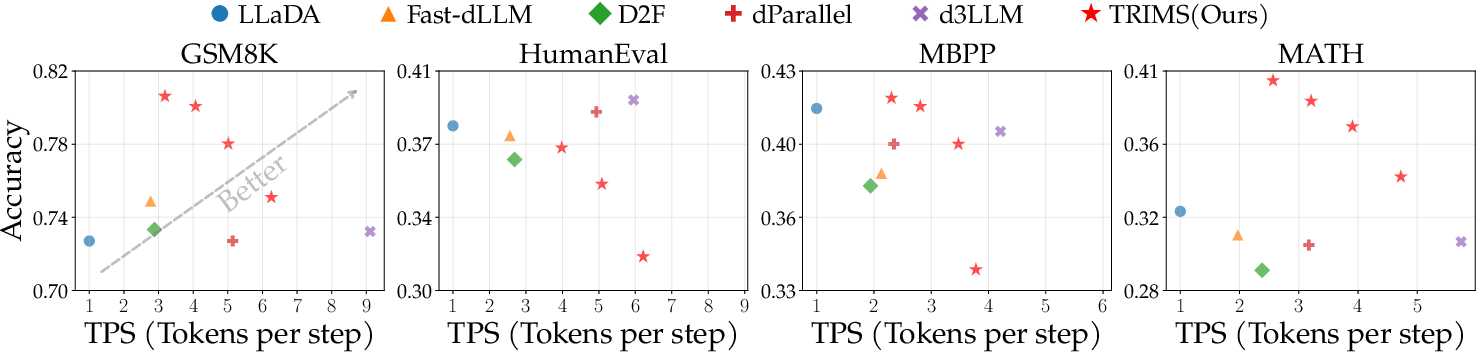
Figure 3: The TRIMS frontier (upper-right) achieves superior accuracy and parallelism on LLaDA-Instruct relative to all baseline methods.
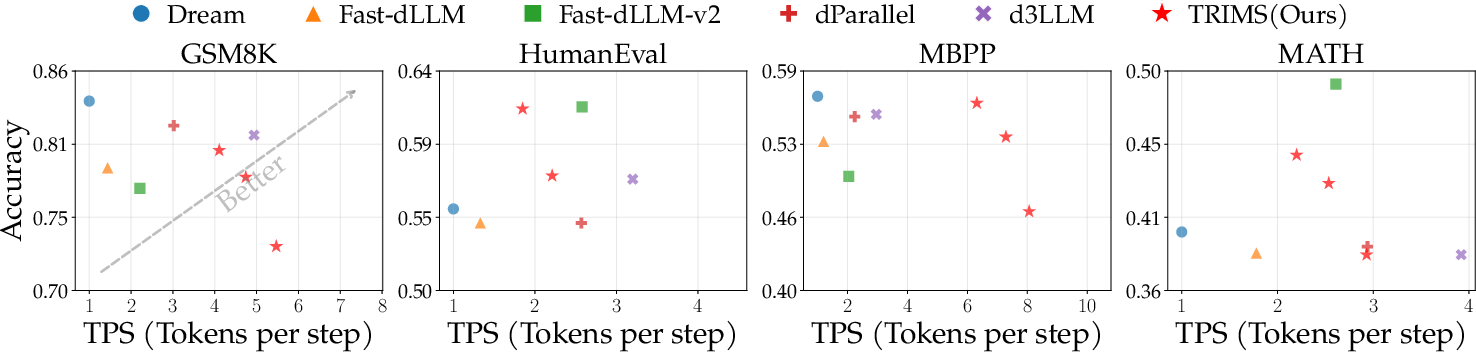
Figure 4: TRIMS outperforms baselines in accuracy-parallelism trade-off on Dream-Instruct.
Summary of Results:
- On GSM8K, TRIMS achieves up to 6.26 TPS on LLaDA and 4.11 TPS on Dream, compared to 1.0–2.8 TPS for non-distilled baselines. Similar multiplicative gains (2×–3×) are observed on other benchmarks.
- Accuracy is maintained or improved over standard and accelerated MDLMs, and TRIMS matches or exceeds distillation-based methods, often with higher efficiency.
- TRIMS achieves comparable performance with only 0.6 GPU hours for AR teacher passes and 1K prompt-completion pairs, whereas distillation methods require up to 287 GPU hours per model and over 90K training examples.
Ablations and Decoding Trajectory Diagnosis
A systematic dissection of TRIMS demonstrates:
- Trajectory Supervision: Injecting any bucket-based masking (random or ordered) improves parallelism, validating the utility of non-uniform mask scheduling.
- Ordering Policy: The hard-to-easy (difficulty-descending) order yields the best trade-off; easy-first and random bucketizations offer diminished but still positive effects.
- Bucket Granularity: Moderate values (K=8) optimize performance, with both too-coarse and too-fine bucketizations exhibiting modest degradation.
- Difficulty Metric: Token NLL slightly outperforms entropy, especially on code, reflecting domain-dependent structural dependencies.
Empirical trajectory analysis confirms that TRIMS-trained models resolve high-NLL tokens earlier, reducing sequence-wide uncertainty more efficiently through iterative denoising.
Implications and Future Directions
TRIMS provides a lightweight, scalable, and hardware-agnostic curriculum supervision mechanism for DLMs. Its decoupling from diffusion-based online curation unlocks streamlined trajectory engineering at low cost, mitigating the train-inference mismatch endemic to current DLM training. The method is compatible with existing masked diffusion architectures with minimal pipeline changes.
Practically, this enables accelerated DLM deployment for production and research scenarios requiring both high-accuracy and low-latency sequence generation, such as code synthesis and advanced mathematical reasoning. Theoretically, it reinforces the perspective that the choice of mask scheduling—especially one aligned with explicit curriculum signals—substantially influences the inductive biases and sample efficiency of iterative sequence models.
Anticipated future work includes scaling TRIMS to larger DLM architectures, exploring richer token-level signals (semantic, structural, or task-specific), and synergizing trajectory-aware supervision with reinforcement-based or hybrid policies for dynamic schedule optimization.
Conclusion
TRIMS substantiates that curriculum-inspired, AR-teacher-driven trajectory supervision for DLMs achieves substantial improvements in the accuracy-parallelism trade-off, matching the effectiveness of resource-intensive distillation-based methods without their associated cost or complexity. These results illustrate the viability and scalability of low-cost trajectory engineering for practical parallel text generation in DLMs (2604.00666).

