- The paper resolves the reproducibility gap by reverse engineering in-distribution tool schemas for gpt-oss-20b.
- It introduces the Harmony Agent that natively manages message serialization, reducing token usage in coding benchmarks.
- Reproduction of published results confirms that performance gaps arise from harness mismatches rather than model limitations.
Technical Analysis of "In harmony with gpt-oss" (2604.00362)
The paper addresses the critical reproducibility gap for the coding-centric Mixture of Experts LLM, gpt-oss-20b, specifically in the context of SWE Verified and AIME25 benchmarks. It identifies two primary sources of irreproducibility: proprietary agent harnesses and incomplete tool sets. Published results for gpt-oss-20b cannot be replicated by independent parties because OpenAI withheld details of the harness and precise tool schemas used during evaluation, leading to substantial score deltas when models are run in alternative environments. This non-trivial harness/configuration dependence distorts comparative assessments and impacts practitioner adoption.
The authors dissect the in-distribution tool priors of gpt-oss-20b, revealing the model's strong tendency to invoke tools from its training distribution even when those are undefined at inference time—a behavior traced to encoding priors, not hallucinations. Notably, apply_patch is persistently called for code edits, mirroring Codex-era system tools. Through systematic log analysis, targeted sampling, bootstrap confidence intervals, and cross-referencing text mentions with empirical tool calls, the true operational tool inventory is reconstructed. The core tools in repo_browser are print_tree, search, and open_file, alongside container.exec and apply_patch. Aliases are subsumed when proper definitions are supplied. Schema robustness is established: 100% of tool calls yield valid JSON; parameter presence statistics isolate confabulated arguments from canonical schemas.
Harmony Agent: Native Harness Implementation
The study implements a Harmony Agent—a harness that natively serializes and parses interaction messages in the Harmony format, bypassing lossy conversion to OpenAI Chat Completions. This decisively resolves format mismatch; tool definitions are injected once at session start rather than being redundantly transmitted per turn, leading to marked token savings and fidelity to the model’s intended input distribution.
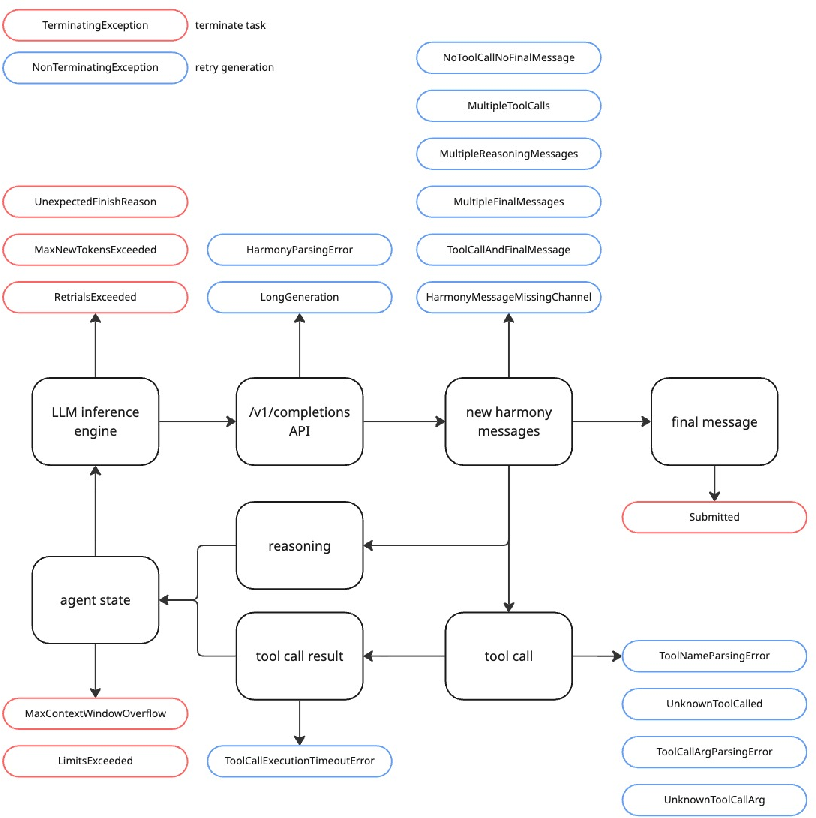
Figure 1: The Harmony agent architecture, detailing message tokenization, channel-based routing, and tool execution feedback.
The Harmony Agent orchestrates conversation flows using designated channels (analysis, commentary, final) and explicit message delimiters. Tool invocation and subsequent output integration are handled seamlessly, and error states are categorized and managed via a fine-grained exception system that supports aggressive recovery for transient errors and prompt halting for unrecoverable terminations. The harness architecture is a direct implementation of OpenAI’s Harmony cookbook, maximizing compatibility.
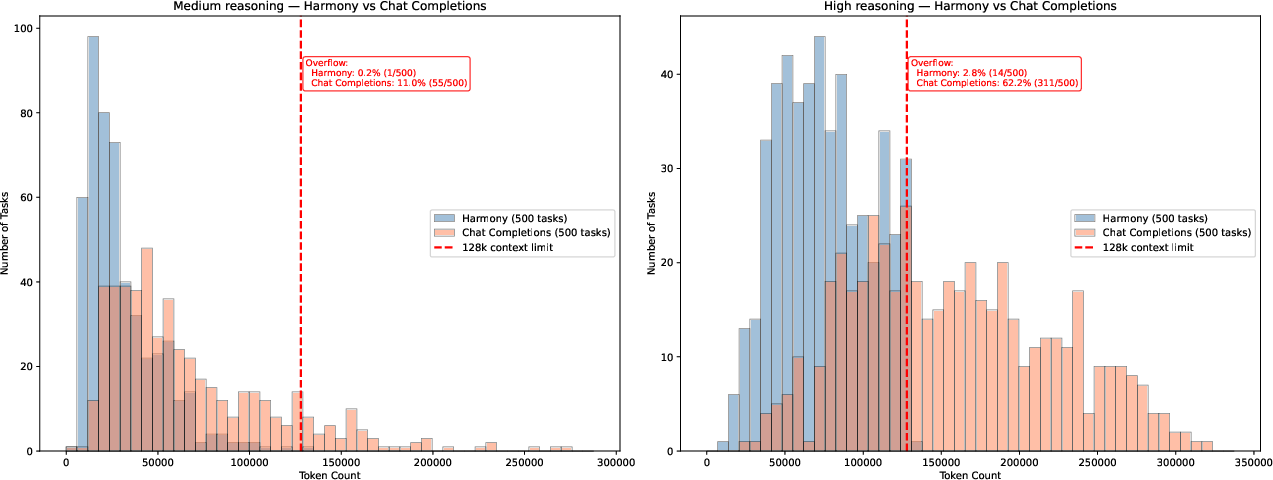
Figure 2: Comparison of token consumption between Harmony and Chat Completions formats, demonstrating efficiency of Harmony for high-context tasks.
Empirical analysis shows that Harmony format achieves considerably lower token usage than Chat Completions, especially relevant in high-context coding benchmarks where tool schemas inflate the prompt.
Reproduction of Published Results
Using the Harmony Agent, the authors obtain scores matching OpenAI publications: 60.4% on SWE Verified HIGH (vs. 60.7%), 53.3% MEDIUM (vs. 53.2%), and 91.7% on AIME25 with tools (vs. 90.4%), all within bootstrap confidence intervals. This constitutes the first independent confirmation of the published gpt-oss-20b numbers under a transparent, open harness, ruling out model deficiencies as the cause of prior underperformance. Explicit context window management is applied, with retries upon overflow exceptions; further context compacting is suggested as future work. The metric "pass@1" is used throughout, aligning with OpenAI methodology.
Practical and Theoretical Implications
The findings demonstrate that leaderboard gaps—such as the 36-point drop for gpt-oss-120b on SWE Verified—can be attributed to harness/tool mismatches, not intrinsic model limitations. This has immediate relevance for practitioners: deploying frontier LLMs for coding in agentic settings mandates harnesses and tool schemas congruent with the training distribution. Theoretical implications are broad: evaluation harness design and reproducible tool inventories are now first-order variables in LLM benchmarking.
Furthermore, the study substantiates that encoding tools in the correct message role (system vs. developer) is vital for invocation reliability, providing actionable guidance for interface design. The methodology for tool discovery is generalizable to other models trained with proprietary setups.
Speculation on Future Developments
The paper's methodology points toward harmonized open-source harness standards for automated agentic evaluation, essential for measuring coding and reasoning capabilities without noise from infrastructural artifacts. As LLMs expand context windows and tool affordances, scalable harnesses like Harmony Agent will become pivotal for robust benchmarking. There is a clear need for community-driven harness repositories and comprehensive tool catalogs for each released model.
Long-term, models may require meta-learning of harness and tool affordance distributions to generalize reliably across a wider array of real-world agentic pipelines. The approach also suggests future benchmarks should explicitly fix harness formats and tool schemas to remove confounding variance.
Conclusion
"In harmony with gpt-oss" establishes that published coding agent benchmarks are only meaningful when evaluated under native harness and in-distribution tools. The authors' Harmony Agent implementation and reverse engineering of tool schemas close the reproducibility gap for gpt-oss-20b, showing that poor leaderboard performance is an artifact of infrastructural mismatch. These results advocate for open harness standardization and transparent tool inventories as prerequisites for rigorous LLM benchmarking, with direct impact on both deployment practices and research evaluation protocols.