OpenResearcher: A Fully Open Pipeline for Long-Horizon Deep Research Trajectory Synthesis
Abstract: Training deep research agents requires long-horizon trajectories that interleave search, evidence aggregation, and multi-step reasoning. However, existing data collection pipelines typically rely on proprietary web APIs, making large-scale trajectory synthesis costly, unstable, and difficult to reproduce. We present OpenResearcher, a reproducible pipeline that decouples one-time corpus bootstrapping from multi-turn trajectory synthesis and executes the search-and-browse loop entirely offline using three explicit browser primitives: search, open, and find, over a 15M-document corpus. Using GPT-OSS-120B as the teacher model, we synthesize over 97K trajectories, including a substantial long-horizon tail with 100+ tool calls. Supervised fine-tuning a 30B-A3B backbone on these trajectories achieves 54.8\% accuracy on BrowseComp-Plus, a +34.0 point improvement over the base model, while remaining competitive on BrowseComp, GAIA, and xbench-DeepSearch. Because the environment is offline and fully instrumented, it also enables controlled analysis, where our study reveals practical insights into deep research pipeline design, including data filtering strategies, agent configuration choices, and how retrieval success relates to final answer accuracy. We release the pipeline, synthesized trajectories, model checkpoints, and the offline search environment at https://github.com/TIGER-AI-Lab/OpenResearcher.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
OpenResearcher, explained simply
What this paper is about (the big idea)
The paper builds a way to train “deep research” AIs—systems that can search, read, and think across many steps—without relying on expensive, unstable live web searches. Instead, it creates a giant offline “mini‑Internet,” then teaches an AI how to research using three simple actions: search, open a page, and find text on the page. This makes training cheaper, repeatable, and easier to study.
What the researchers wanted to find out
In simple terms, they asked:
- How can we create long, realistic research “practice runs” for AIs without using the live web?
- What tools does an AI researcher actually need (search only, or also open and find)?
- How many steps (turns) should an AI be allowed to take before answering?
- Do we need to keep only perfect practice runs, or can “failed” ones help too?
- If the AI finds the right page, is that enough to get the right answer?
How they did it (with easy analogies)
Think of this like building a training library for a student researcher.
- Build the library once (offline)
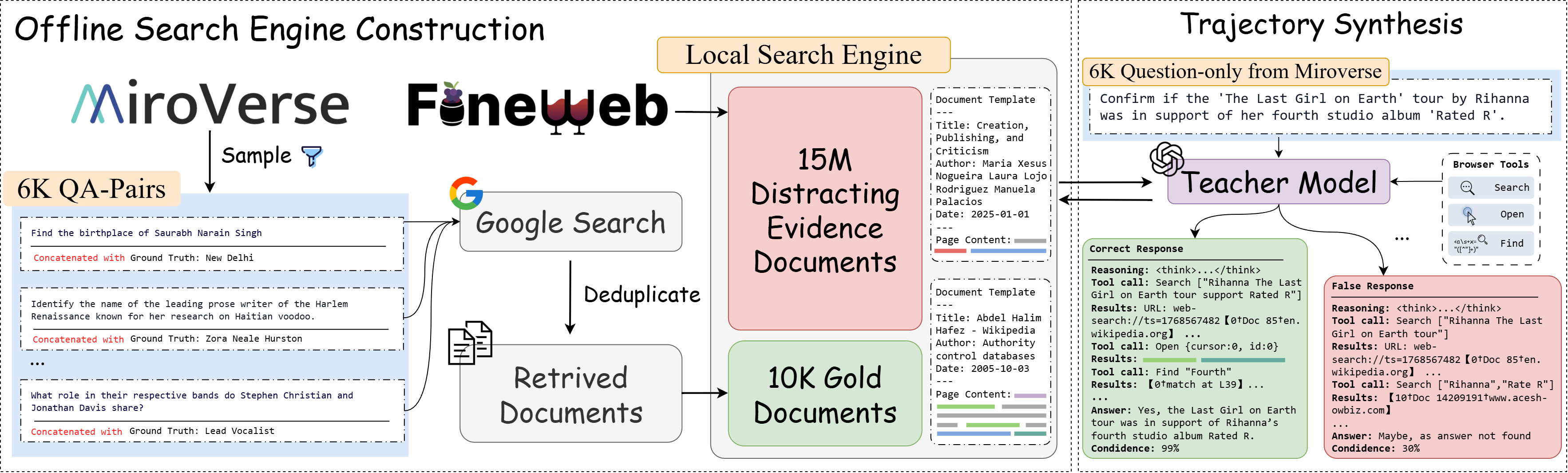
- They started by collecting 15 million web pages (like stocking a huge library).
- For each question they wanted the AI to answer, they did a one-time online search to make sure at least a few “gold” pages with the correct info were inside the library. Think of these as books that definitely contain the answer.
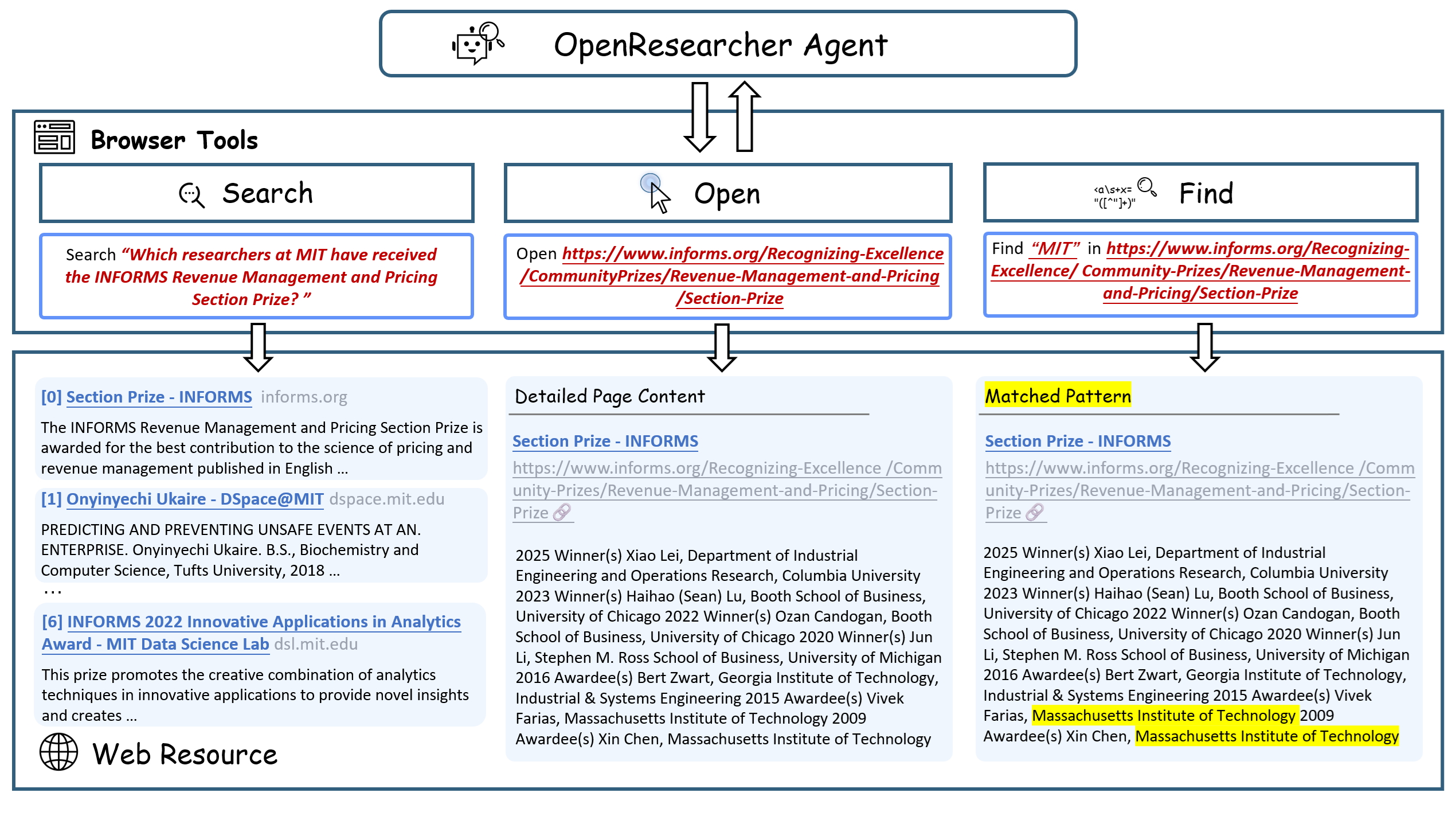
- Give the AI three simple tools (like what you do in real life)
- Search: like asking the librarian for a list of promising books.
- Open: like pulling a book off the shelf to read it.
- Find: like using Ctrl+F or the index to jump to a specific word or name.
- Have a “teacher AI” show the steps
- A large “teacher” model (GPT-OSS-120B) used those tools inside the offline library to answer questions.
- Every research session produced a “trajectory”—a step-by-step record of what it searched, which pages it opened, what it looked for, and the final answer. You can think of each trajectory as a detailed recipe for solving a question.
- They generated over 97,000 of these step-by-step recipes, some with more than 100 tool uses.
- Train a smaller “student AI”
- They fine-tuned a 30-billion-parameter model (the student) on these research recipes so it could learn how to do long, careful research on its own.
Some technical terms, explained:
- Embeddings: turning web pages into numbers so the computer can compare them quickly.
- Index (FAISS): a super-fast card catalog for finding the pages most related to your query.
- Offline: everything runs locally, so it costs almost nothing and gives the same results every time.
- Trajectory: the full sequence of thoughts and actions (search → open → find) the AI took to get the answer.
What they found and why it matters
Main results:
- Strong performance: The trained student model reached 54.8% accuracy on a tough offline benchmark (BrowseComp-Plus), which is a big +34-point jump over the same model before training. It also did well on live web tasks like GAIA and xBench-DeepSearch.
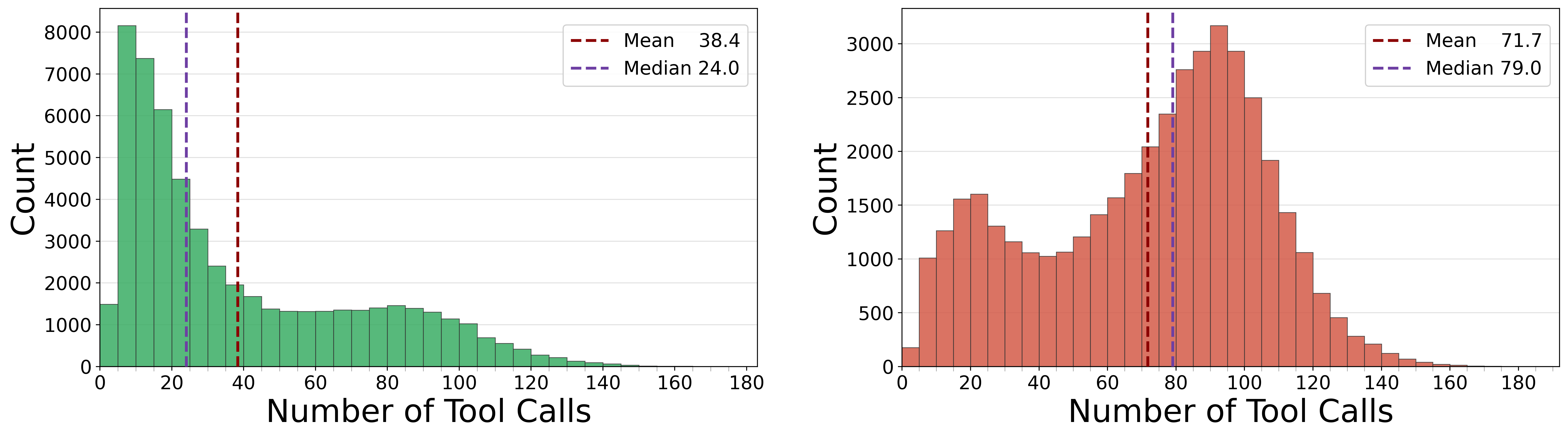
- Long, realistic research: Many practice runs took dozens of steps, and some took over 100 tool calls—much closer to real online research than short, 2–5 step tasks.
- Huge cost savings: Doing millions of searches offline is essentially free, compared to thousands of dollars using online APIs.
- Reproducible and analyzable: Because everything is offline and fixed, they could study the AI’s behavior precisely—when it found the right page, when it opened it, and how that affected the final answer.
Key insights from their analyses:
- The right tools matter:
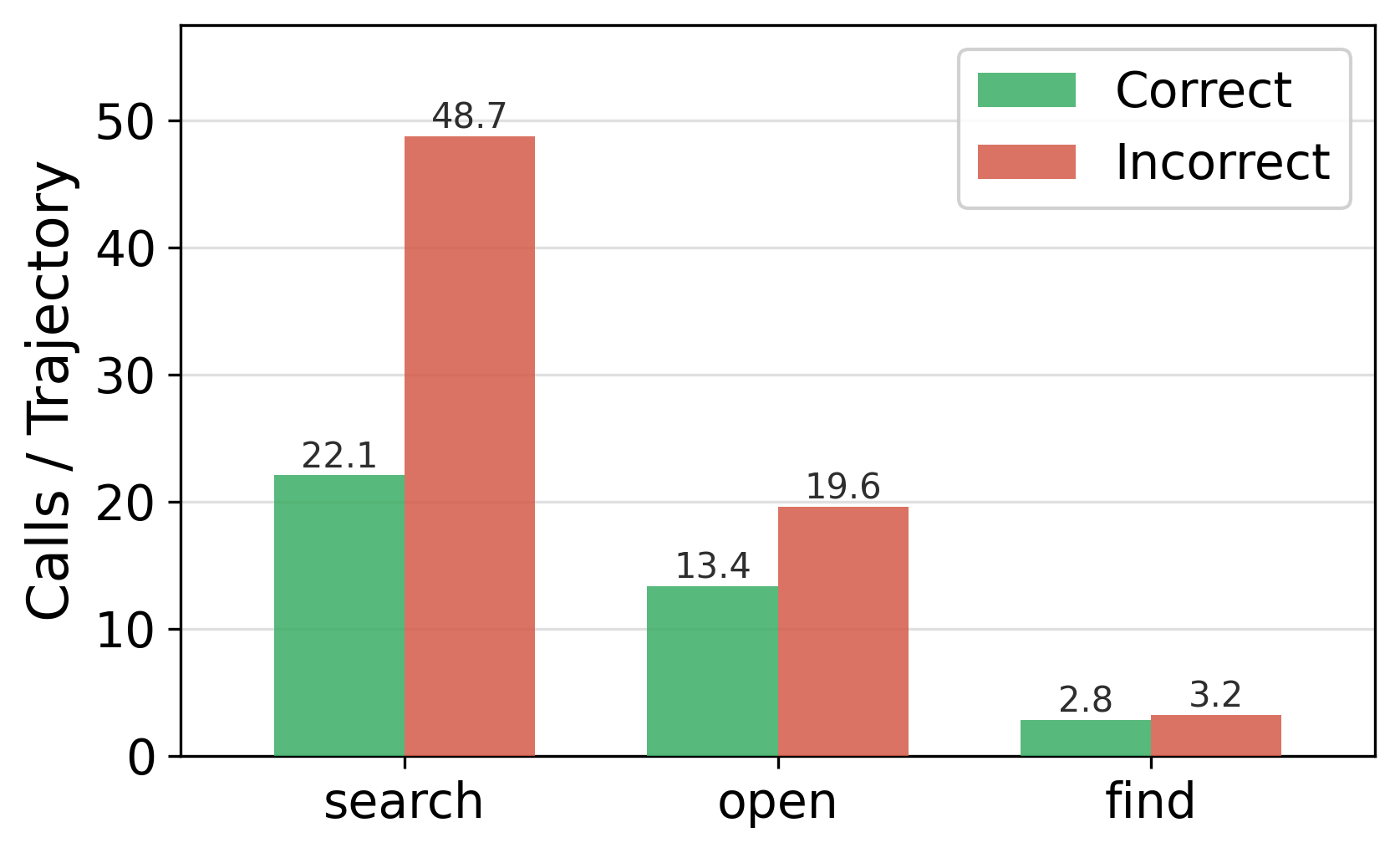
- Search only isn’t enough. Adding Open (read the full page) gives a big boost, and adding Find (Ctrl+F) helps even more.
- Finding the right page isn’t everything:
- Simply seeing the correct page in results doesn’t guarantee the right answer. Opening and locating the exact evidence is much more powerful.
- More steps help—up to a point:
- Letting the AI take more turns improves accuracy until around 100 steps, then it levels off.
- “Failed” practice runs can still teach:
- Training on only correct runs, only incorrect runs, or both made very similar models. Even mistakes teach useful research habits (like how to search and when to stop).
- Bootstrapping the library is essential:
- Adding those “gold” pages at the start was crucial. Without them, performance collapsed—because the AI couldn’t find the needed evidence at all.
Why this is important (the impact)
- Makes deep research training affordable and repeatable: Schools, labs, and startups can now build and share large research datasets and models without huge API bills or unstable results.
- Encourages open science: They released the pipeline, data, models, and the offline environment so others can improve and compare fairly.
- Better understanding of how AI should research: The study shows which tools and settings actually matter, helping future systems become more accurate, efficient, and trustworthy.
- Bridges offline training to real-world use: Even though the student learned offline, it still performed well on live web tasks—showing that careful offline training can transfer to real environments.
In short: OpenResearcher shows how to train research-savvy AIs using a realistic, low-cost offline setup with simple, human-like tools. It not only boosts performance but also helps the community understand and improve how AI should search, read, and think over many steps.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise, actionable list of what remains missing, uncertain, or unexplored in the paper, to guide future research.
- Corpus scale and representativeness
- Limitation: The offline corpus (≈15M FineWeb docs + 10K gold docs) is orders of magnitude smaller than the live web and likely skewed in domain, recency, and quality. Open question: How does performance scale with corpus size and diversity (e.g., 100M–1B docs), recency (freshness), and topic/domain coverage?
- Bias from answer-guided bootstrapping
- Limitation: Gold documents are retrieved using queries that explicitly concatenate the question with the ground-truth answer, creating a distribution where the answer string is likely present verbatim. Open questions:
- To what extent does this induce shortcut behavior (e.g., over-reliance on exact-string “find”)?
- How does quality change if bootstrapping uses weaker hints (paraphrases, partial answers) or answer-agnostic strategies?
- Generalization beyond English text
- Limitation: The pipeline focuses on English, text-only documents. Open questions:
- How does the approach extend to multilingual settings and low-resource languages?
- How to incorporate and evaluate multimodal evidence (tables, figures, PDFs, scanned docs)?
- Retrieval backbone sensitivity
- Limitation: Only one dense retriever (Qwen3-Embedding-8B + FAISS) is evaluated. Open questions:
- How sensitive are results to the retriever model, indexing strategy (chunk size/stride), and ranking pipeline (dense vs. BM25 vs. hybrid, multi-stage reranking)?
- What is the effect of top-K and snippet construction on long-horizon behavior?
- Minimal browser primitives vs. real-world browsing
- Limitation: The toolset includes only search, open, and find; it omits realistic actions such as follow-link, back, scroll, click-element, fill-form, pagination, domain/site scoping, and query operators. Open question: Which additional primitives most improve deep research in dynamic, noisy, or structured pages?
- “Find” as exact string match
- Limitation: In-document evidence localization is an exact string match. Open questions:
- How do fuzzy/semantic in-document search and span extraction affect success on paraphrased or implicit evidence?
- Does exact-match bias emerge because gold docs often contain the literal answer?
- Offline corpus realism and noise
- Limitation: Pages are cleaned/deduplicated and rendered without web noise (ads, cookie banners, paywalls, dynamic JS). Open question: How does injecting realistic noise and navigation frictions impact agent robustness and tool-use strategies?
- Contamination checks and data leakage
- Limitation: There is no systematic audit of potential overlaps between training corpus (FineWeb + bootstrapped gold docs) and evaluation tasks (BrowseComp, GAIA, xbench). Open question: Can a documented contamination analysis (URL/domain overlap, content similarity) clarify true generalization?
- Evaluation breadth and depth
- Limitation: Benchmarks are limited to BrowseComp-Plus (closed-web) and three open-web tasks; no human evaluation of research quality, evidence use, or faithfulness. Open questions:
- How does the agent perform on broader domains (biomed, legal, finance), adversarial distractors, and real user studies?
- Can process-level metrics (evidence attribution, chain-of-thought faithfulness, source credibility) complement accuracy?
- Training on incorrect trajectories
- Limitation: The paper finds similar downstream performance training on correct-only vs. incorrect-only trajectories, but doesn’t inspect error propagation. Open question: Which failure patterns in incorrect trajectories are beneficial vs. harmful to learn, and how can we denoise them (e.g., counterfactual supervision, outcome-conditioned filtering)?
- Long-context SFT dynamics
- Limitation: SFT uses 256K-token pre-packed sequences for only 347 steps on 8×H100; stability and generality of this regime are unclear. Open questions:
- How do training length, curriculum, and packing strategies affect stability and final performance?
- What are the trade-offs between extremely long-context SFT and memory/tool augmentation?
- Absence of RL or process supervision
- Limitation: Only SFT is used; no reinforcement learning, preference/process supervision, or curriculum over horizons. Open questions:
- Do RL from process-level rewards (evidence use, stopping accuracy) or outcome rewards improve long-horizon efficiency and correctness?
- How does curriculum over increasing horizons or difficulty affect learning?
- Turn-budget and efficiency trade-offs
- Limitation: While a sweep shows plateaus beyond ~100 turns, the compute/time costs of longer horizons aren’t quantified. Open question: How to jointly optimize accuracy, latency, and cost (e.g., with adaptive budgeting, early stopping, or planning heuristics)?
- Memory and cross-document aggregation
- Limitation: No explicit external memory or structured note-taking beyond context accumulation; the agent must keep everything in the prompt. Open questions:
- Do memory modules (scratchpads, graph stores) or learned toolchains improve cross-document synthesis and reduce token usage?
- What design best supports revisiting and reconciling conflicting sources?
- Robustness to query drift and reformulation
- Limitation: Failures are attributed to repeated search reformulations, but techniques to mitigate drift (query planning, subgoal decomposition, query audits) are not explored. Open questions: Which query-planning strategies most reduce drift and improve early gold hits?
- Cost accounting and scalability
- Limitation: The cost analysis ignores compute, storage, and indexing overhead (10T tokens is a substantial claim), as well as teacher-model inference cost. Open questions:
- What are end-to-end time/energy/storage costs and throughput limits for corpus construction, indexing, and synthesis?
- How do costs grow with corpus size and horizon length?
- Teacher model dependence and quality
- Limitation: The pipeline relies on GPT-OSS-120B; teacher quality and potential dataset contamination in the teacher are not examined. Open questions:
- How sensitive are outcomes to different teachers (sizes, training data, prompting)?
- Can consensus distillation or multi-teacher ensembles improve trajectory quality and diversity?
- Domain and temporal generalization
- Limitation: The offline corpus is static; no mechanism is proposed for updates while preserving reproducibility. Open questions:
- How to incrementally update the corpus with versioned snapshots to study temporal drift?
- How does performance degrade as queries target emerging or fast-changing topics?
- Multistep reasoning evaluation beyond final answers
- Limitation: Analyses emphasize final-answer accuracy and gold-hit rates, with limited causal attribution. Open questions:
- Can we disentangle retrieval, evidence selection, and reasoning errors with richer instrumentation (e.g., per-step labels, causal intervention studies)?
- How does evidence timing and redundancy affect success?
- Tool-observation design
- Limitation: Snippet structure, length, and ranking are fixed and not analyzed. Open questions:
- How do snippet length, passage segmentation, and reranking affect tool-call counts and success?
- What is the impact of exposing page structure (headings, tables, anchors) to guide “open” and “find”?
- Safety, credibility, and bias
- Limitation: There is no treatment of source credibility, misinformation, or bias in retrieved documents. Open questions:
- Can credibility signals (source authority, cross-source agreement) be integrated into tool use and decision policies?
- How to evaluate and mitigate bias propagation from the corpus and teacher trajectories?
- Link-following and web graph exploration
- Limitation: The agent cannot follow hyperlinks within opened pages; exploration remains query-centric. Open question: What gains arise from a link-following primitive to traverse the web graph, and how should pagination/next-page be modeled offline?
- Seed and reproducibility variance
- Limitation: Pass@k is reported over 16 seeds, but independence and variance decomposition are not explored. Open question: How much trajectory diversity stems from stochasticity vs. true alternative reasoning paths, and how should seeds be set/released for reproducibility?
- Benchmark comparability and prompt standardization
- Limitation: Baselines likely use differing prompts/tooling; fairness of comparisons is unclear. Open question: Can a standardized prompt/tool interface be released for apples-to-apples evaluations across models and settings?
- Licensing and redistribution constraints
- Limitation: Legal and licensing constraints for redistributing web content (FineWeb + bootstrapped pages) are not detailed. Open question: What is the minimal reproducible recipe and metadata needed for others to rebuild the corpus within licensing constraints?
Practical Applications
Immediate Applications
Below are concrete, deployable use cases that can be built now using the released pipeline, datasets, models, and offline search environment.
- Evidence-traceable enterprise research assistant
- Sectors: software, legal, finance, healthcare (non-PHI), energy, manufacturing
- What it does: Runs “search→open→find” across a company’s internal document lakes (wikis, PDFs, RFCs, SOPs, filings) to answer complex questions with explicit passage-level evidence trails and full audit logs of tool calls.
- Tools/products/workflows:
- ResearchOps stack: offline corpus builder (FAISS + Qwen3-Embedding-8B), agent runtime exposing three browser primitives, provenance UI for step-by-step traces.
- “Gold-hit” analytics dashboards to monitor evidence exposure vs. answer correctness.
- Assumptions/dependencies: One-time corpus bootstrapping for coverage; document licensing and data governance; GPUs/long-context inference for 30B models; retrieval quality depends on embeddings and index hygiene.
- Cost-effective trajectory synthesis for custom agent training
- Sectors: AI/ML platforms, research labs, startups
- What it does: Generate high-quality, long-horizon trajectories offline over domain corpora to fine-tune smaller models for deep research tasks without live web costs or rate limits.
- Tools/products/workflows: “Trajectory Generation as a Service” over client corpora; SFT recipe mirroring OpenResearcher (sequence packing to 256K tokens, correctness-agnostic filtering).
- Assumptions/dependencies: Adequate storage/compute; initial coverage ensured by bootstrapped “gold” documents; licenses for teacher models or suitable open teachers.
- Reproducible benchmarking and A/B testing of agent designs
- Sectors: AI evaluation, QA, model governance
- What it does: Use the fixed offline environment to compare agent prompts, tool sets, and turn budgets with stable metrics (accuracy, gold-hit rate, first-hit turn, token usage).
- Tools/products/workflows: “Benchmark-in-a-Box” for BrowseComp-Plus-style testing; CI pipelines that fail builds when evidence exposure or accuracy regresses.
- Assumptions/dependencies: Fixed corpus snapshots; consistent retrieval indexes; controlled seeds for repeatability.
- Compliance-grade audit trails and provenance for regulated workflows
- Sectors: legal (e-discovery), finance (KYC/AML), healthcare (guidelines—not PHI), public sector
- What it does: Produce transparent logs of searches, opened documents, and in-page finds; verify that answers derive from specific evidence.
- Tools/products/workflows: Provenance reports attached to each answer; export of trajectories for auditors; alerting when answers lack open-hit evidence.
- Assumptions/dependencies: Strict access control; data retention policies; offline corpus must include the authoritative sources you need to cite.
- Editorial fact-checking and citation verification
- Sectors: media, publishing, academia
- What it does: Cross-check claims against an offline corpus of standards (e.g., style guides, archives) using explicit open/find steps and provide citations.
- Tools/products/workflows: “Evidence-First” editorial assistant; batch verification of articles with report highlighting missing gold hits.
- Assumptions/dependencies: Corpus freshness; curated high-precision indexes; deduplication to avoid boilerplate contamination.
- Instructional tools for teaching research methods
- Sectors: education, libraries
- What it does: Simulate realistic research workflows (query refinement, source inspection, passage localization) with reproducible outcomes and instructor dashboards.
- Tools/products/workflows: Classroom exercises on BrowseComp-Plus; assignments that grade turn budgets, evidence localization, and final answers separately.
- Assumptions/dependencies: Course-ready corpora; student-accessible hardware; moderation for academic integrity.
- Internal knowledge management and incident investigation
- Sectors: software/DevOps, cybersecurity
- What it does: Multi-step root-cause investigations by iteratively searching runbooks, tickets, logs, and postmortems; highlight exact lines with the “find” primitive.
- Tools/products/workflows: Incident triage assistant with traceable trails; “first gold-hit turn” as a KPI for investigation efficiency.
- Assumptions/dependencies: Log and doc ingestion; embeddings for semi-structured text; privacy policies for sensitive data.
- Product design guidance for agentic UIs and configs
- Sectors: software products, agent tooling
- What it does: Adopt evidence-backed defaults—enable all three tools, budget ~100 turns for hard tasks, and avoid overfiltering training data strictly by final correctness.
- Tools/products/workflows: Agent settings templates; UI elements for document opens and in-page finds; analytics for search drift.
- Assumptions/dependencies: Task difficulty varies; turn budgets trade off latency and cost; monitoring needed to prevent runaway search.
Long-Term Applications
The following opportunities require further research, scaling, integration with live systems, or domain approvals.
- Enterprise-grade deep research platform spanning heterogeneous, sensitive corpora
- Sectors: healthcare (clinical literature/guidelines), finance (regulatory updates), legal (case law), defense OSINT
- What it could do: Unified connectors to large static corpora plus periodic refresh; differential privacy and access controls; hybrid offline-online blending for freshness.
- Tools/products/workflows: Elastic “corpus-of-corpora” with versioned snapshots; scheduled re-indexing; evidence gating for sensitive sources.
- Assumptions/dependencies: Data-sharing agreements; robust PII/PHI handling; hybrid retrieval orchestration.
- Scientific discovery copilots and meta-analysts
- Sectors: biomedicine, materials science, climate science
- What it could do: Long-horizon literature reviews, hypothesis synthesis, and protocol comparisons with audit-ready evidence trails.
- Tools/products/workflows: Domain-tuned embedding models; structured extraction (e.g., outcome measures, sample sizes) combined with find-based verification.
- Assumptions/dependencies: High-recall coverage of paywalled/scientific literature; licensing; domain evaluation standards beyond QA accuracy.
- Regulatory change monitoring and impact analysis
- Sectors: finance, energy, healthcare, public policy
- What it could do: Track evolving rules, identify impacted controls, and produce explainable mappings to internal policies with open/find evidence.
- Tools/products/workflows: Snapshot diffing; “first-hit” timelines for new requirements; audit packages for regulators.
- Assumptions/dependencies: Timely corpus updates; alignment between external rules and internal control taxonomies.
- Next-generation e-discovery and due diligence
- Sectors: legal, M&A, compliance
- What it could do: Long-horizon exploration across millions of documents; measurable evidence exposure prior to assertions; cost/latency controlled by turn budgets.
- Tools/products/workflows: Batching strategies guided by “gold-hit probability”; strategic query reformulation agents to reduce search drift.
- Assumptions/dependencies: Scalable indexing; legal admissibility of AI-aided search; chain-of-custody over evidence.
- OSINT and crisis intel in controlled simulators
- Sectors: government, NGOs, security
- What it could do: Train and evaluate agents in offline snapshots of public sources; transfer policies to live systems while preserving auditability.
- Tools/products/workflows: Synthetic OSINT benchmarks with ground-truth “gold” annotations; red-teaming for disinformation resilience.
- Assumptions/dependencies: Ethical frameworks; domain redaction; careful generalization from offline to live conditions.
- Standards and certifications for agentic research provenance
- Sectors: policy, assurance, AI governance
- What it could do: Define minimum provenance (search/open/find logs), evidence thresholds (open-hit requirements), and reproducible test suites for certification.
- Tools/products/workflows: “Research Agent Audit Kit” derived from OpenResearcher; compliance metrics (e.g., P(correct|open-hit)).
- Assumptions/dependencies: Multistakeholder consensus; mapping to existing assurance regimes (e.g., SOC 2, ISO).
- On-device private research assistants
- Sectors: consumer, SMBs
- What it could do: Local agents running quantized 30B successors over personal knowledge bases (notes, PDFs) with full privacy.
- Tools/products/workflows: Lightweight FAISS on laptops; scheduled corpus updates; UI that walks users through evidence localization.
- Assumptions/dependencies: Efficient quantization and memory-mapped long-context inference; user-friendly corpus bootstrapping.
- Hybrid offline→online agent training loops
- Sectors: AI/ML research
- What it could do: Pretrain policies offline for stability and cost, then fine-tune online for freshness and coverage; incorporate RL with gold-hit rewards.
- Tools/products/workflows: Curriculum starting with offline gold-rich corpora; scheduled online exploration with cost caps.
- Assumptions/dependencies: Safe exploration policies; drift detection between offline and live environments.
- Domain-specific copilots with structured “find”-level guarantees
- Sectors: developer tooling, technical support, industrial operations
- What it could do: Documentation triage and design reviews where each claim must have an in-page anchor; “no anchor, no claim” enforceable policies.
- Tools/products/workflows: IDE plugins surfacing evidence lines; CI gates that reject ungrounded answers; “anchor coverage” metrics.
- Assumptions/dependencies: High-quality documentation; consistent markup for reliable string matches; user acceptance of stricter grounding.
- Safety sandboxes for bias/harm analysis in research agents
- Sectors: AI safety, policy labs
- What it could do: Use fixed corpora to isolate retrieval vs. reasoning failures, run counterfactual corpus edits, and measure fairness of evidence exposure.
- Tools/products/workflows: Corpus perturbation harness; slice-based evaluation (gold-hit by subgroup); publish reproducible safety leaderboards.
- Assumptions/dependencies: Curated datasets with sensitive attributes; ethical review; standardized reporting.
Notes on feasibility drawn from the paper’s findings:
- Corpus coverage is a hard prerequisite (ablation RQ2): plan for one-time online bootstrapping of “gold” documents before offline synthesis or deployment.
- Enable all three tools (search+open+find) for realistic performance and efficiency (RQ4); search-only abstractions underperform and increase token/call costs.
- Set generous but bounded turn budgets (~100 turns) for hard tasks; returns diminish beyond that (RQ3).
- Don’t overfilter training data by final correctness—failed trajectories still teach useful search structure (RQ1).
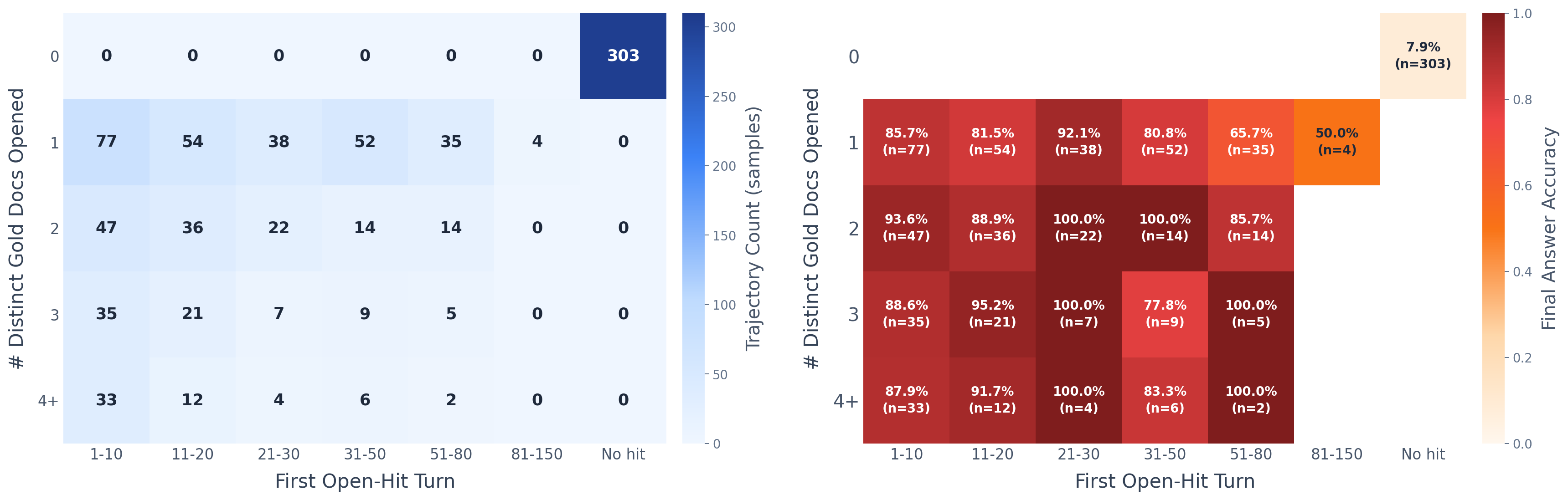
- Evidence exposure (open-hit) is strongly predictive but not sufficient for correctness (RQ5); UX should surface whether gold evidence was actually opened and localized.
Glossary
- Ablation study: A controlled analysis where components or settings are systematically varied to assess their impact. "Ablation Study and Discussion"
- Agentic search systems: LLM-based systems designed to autonomously plan and execute tool-using behaviors for search and reasoning. "Most prior agentic search systems... treat search as a simple document retrieval operation"
- Answer-guided online bootstrapping: A one-time web collection procedure that uses the known answer to construct high-recall queries and fetch supporting documents. "we perform answer-guided online bootstrapping to collect gold documents for each of the 6K QA pairs"
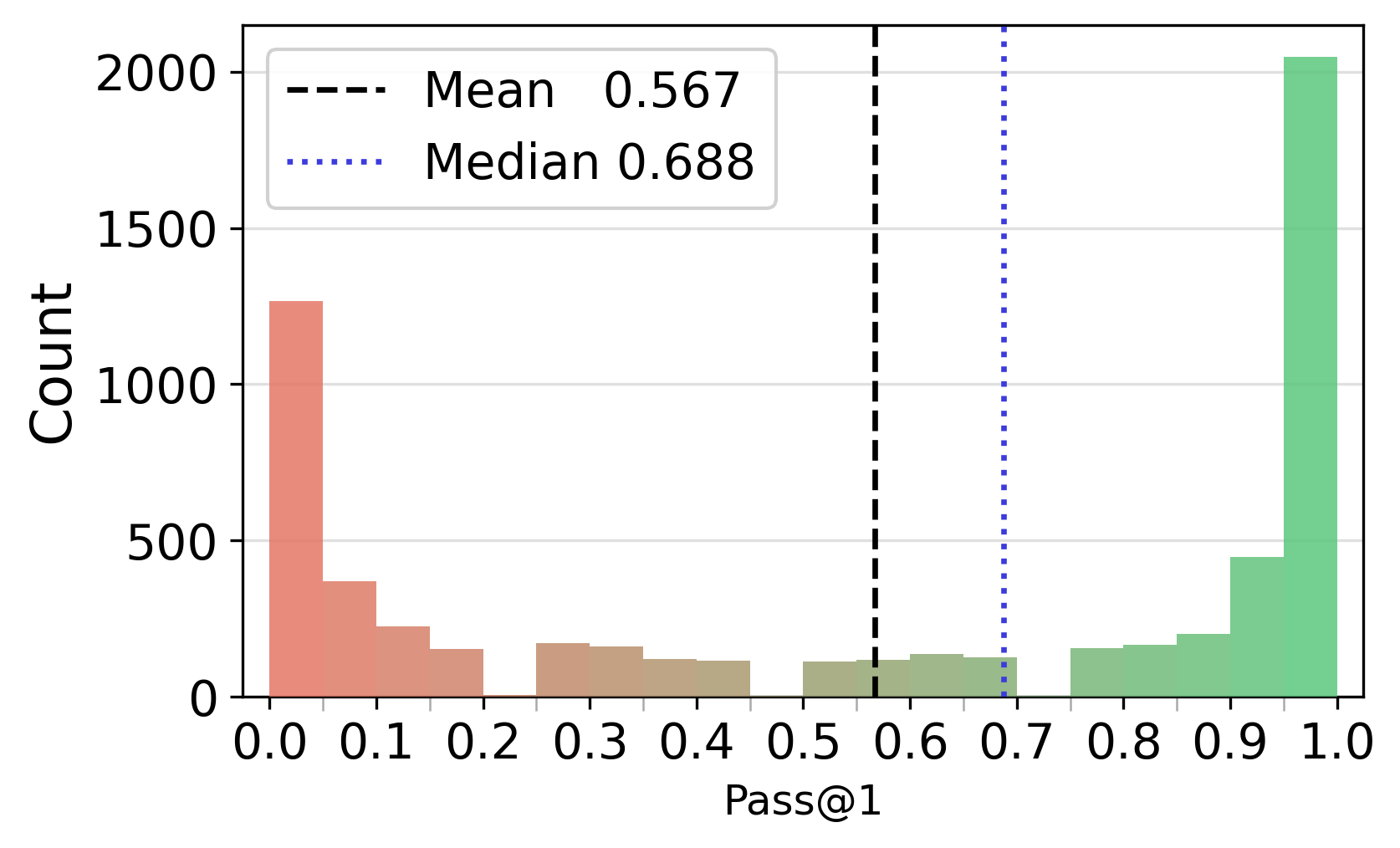
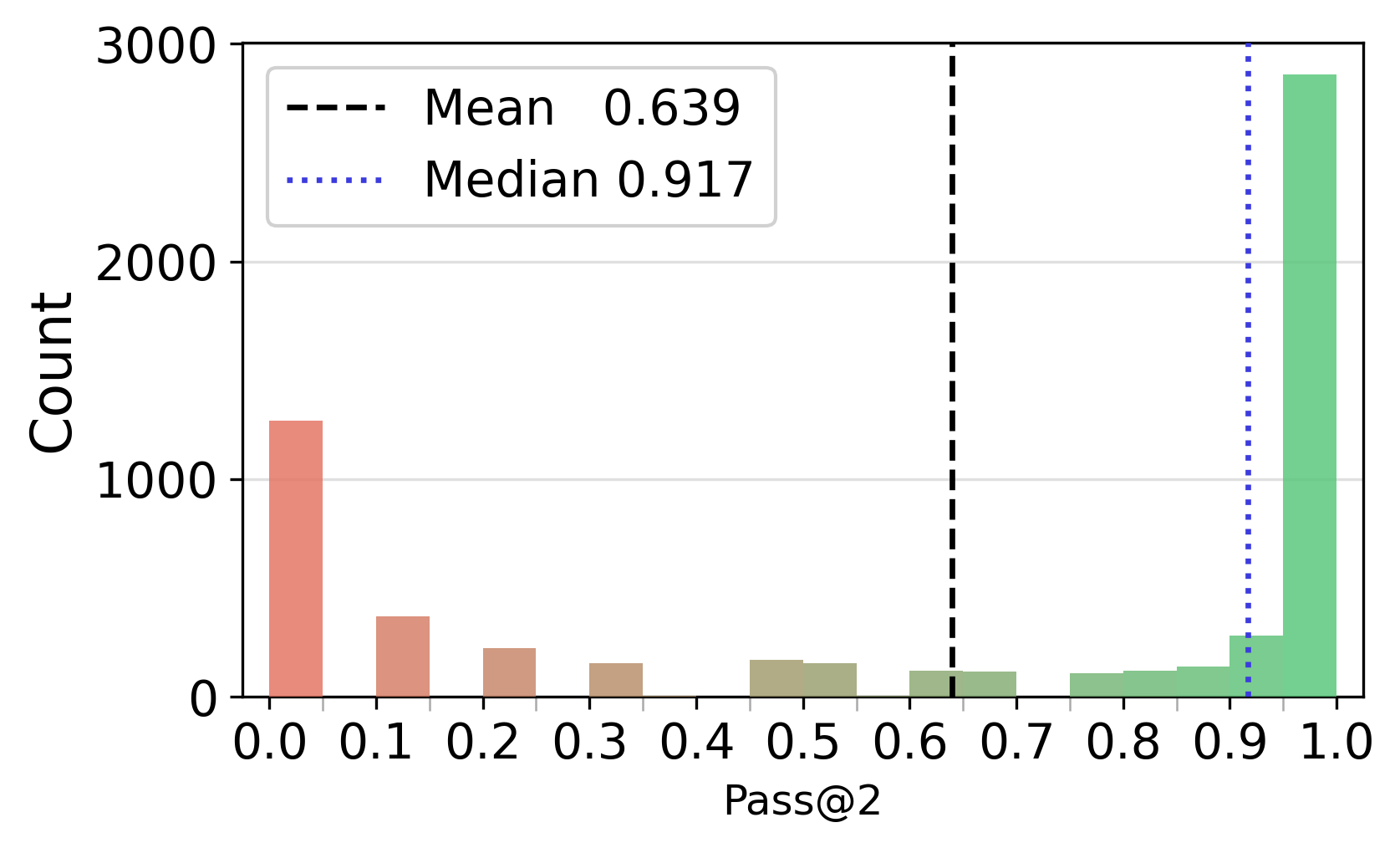
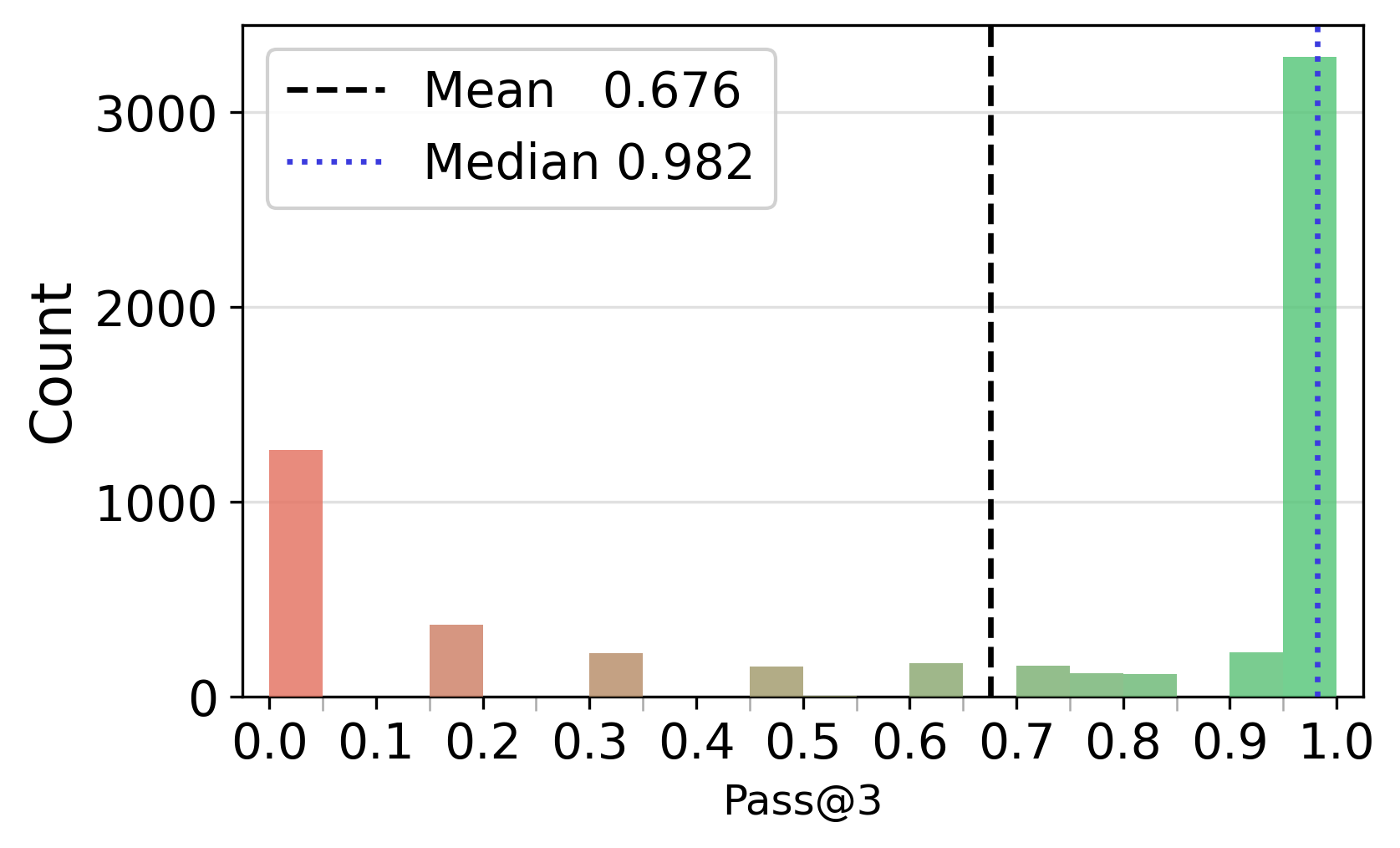
- Bimodal distribution: A distribution with two distinct peaks, indicating two dominant outcome regimes. "failed trajectories follow a broader, bimodal distribution"
- Browser primitives: Minimal, explicit browsing operations exposed to the agent—search, open, and find—for realistic evidence discovery. "three explicit browser primitives: search, open, and find"
- BrowseComp-Plus: A closed-web deep research benchmark used for offline evaluation. "Performance comparison on BrowseComp-Plus."
- Corpus indexing: The process of embedding and organizing documents to support efficient retrieval. "Corpus Indexing."
- Dense retrieval: Retrieval method using vector embeddings to find semantically similar documents efficiently. "efficient large-scale dense retrieval"
- Distractors: Non-gold documents intentionally included in the corpus to simulate real-world noise and complexity. "FineWeb documents act as distractors"
- Evidence aggregation: The process of collecting and integrating information from multiple sources to support reasoning. "interleave search, evidence aggregation, and multi-step reasoning"
- Evidence localization: Precisely finding and grounding relevant facts within a document, often via in-page search. "explicit evidence localization provides additional gains"
- FAISS: A library for efficient similarity search over dense vectors used to index and retrieve documents. "indexed with FAISS"
- FineWeb: A large web-derived corpus used to supply broad coverage and distractor content. "collect 15 million documents... from FineWeb"
- Gold document: A document that contains sufficient evidence to derive the ground-truth answer. "Gold Document Retrieval via Online Bootstrapping."
- Gold-document hit rate: The fraction of trajectories where at least one gold document is retrieved (or opened), used as a diagnostic metric. "drops the gold-document hit rate from 29.54\% to 1.73\%"
- Long-horizon: Involving many steps or tool calls, requiring sustained exploration and reasoning. "long-horizon trajectories"
- Megatron-LM: A distributed training framework for large-scale LLMs. "We adopt {Megatron-LM} as the distributed training framework."
- Multi-hop QA: Question answering that requires reasoning across multiple pieces of evidence. "multi-hop QA"
- Offline search engine: A locally hosted retrieval backend that simulates web search deterministically and at low cost. "construct the offline search engine"
- One-time online bootstrapping: A single upfront phase of live web collection to ensure that answer-supporting evidence exists in the offline corpus. "one-time online bootstrapping"
- Open-hit: An event where a gold document is not only retrieved but also opened by the agent during a trajectory. "no gold-document open-hit"
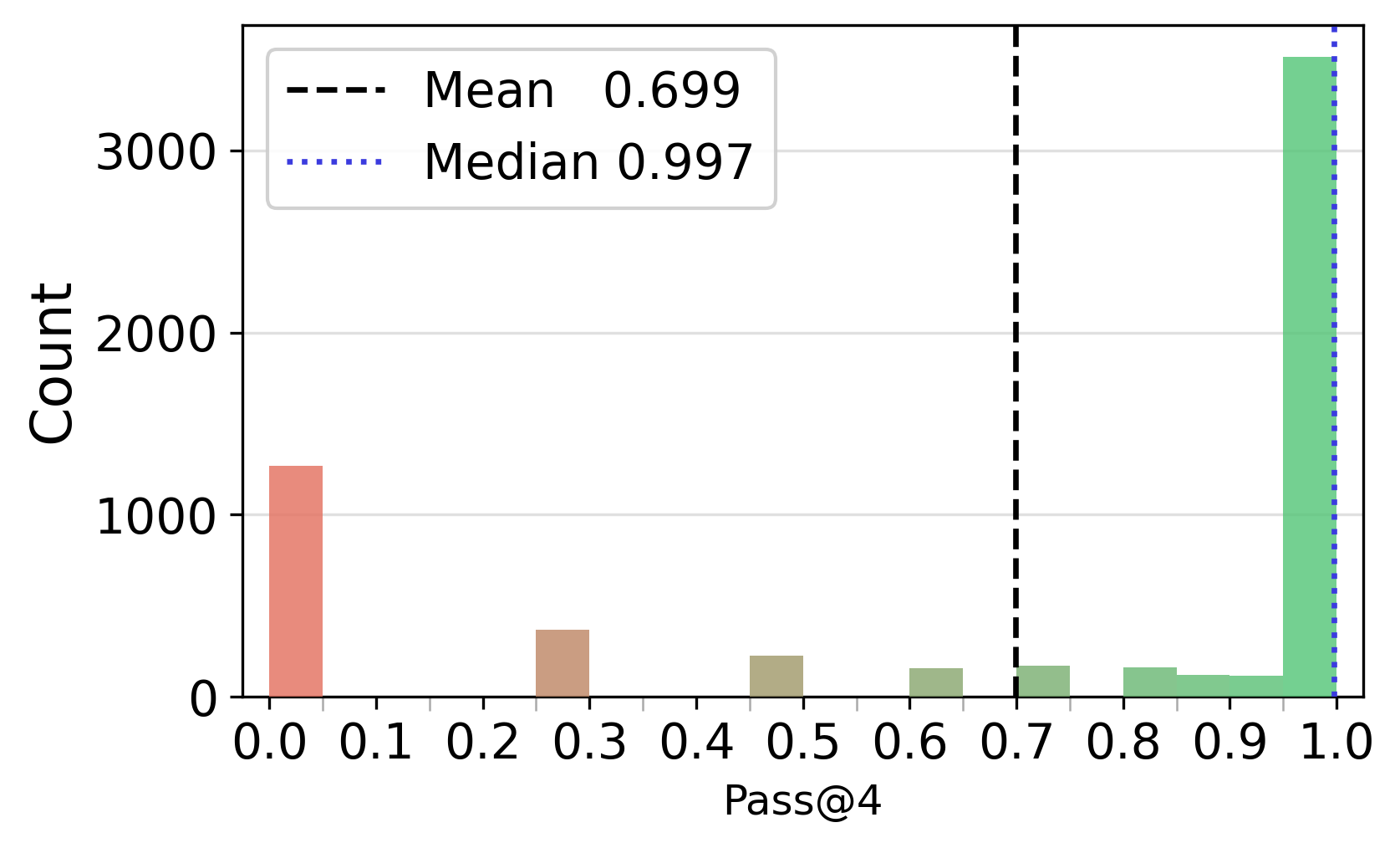
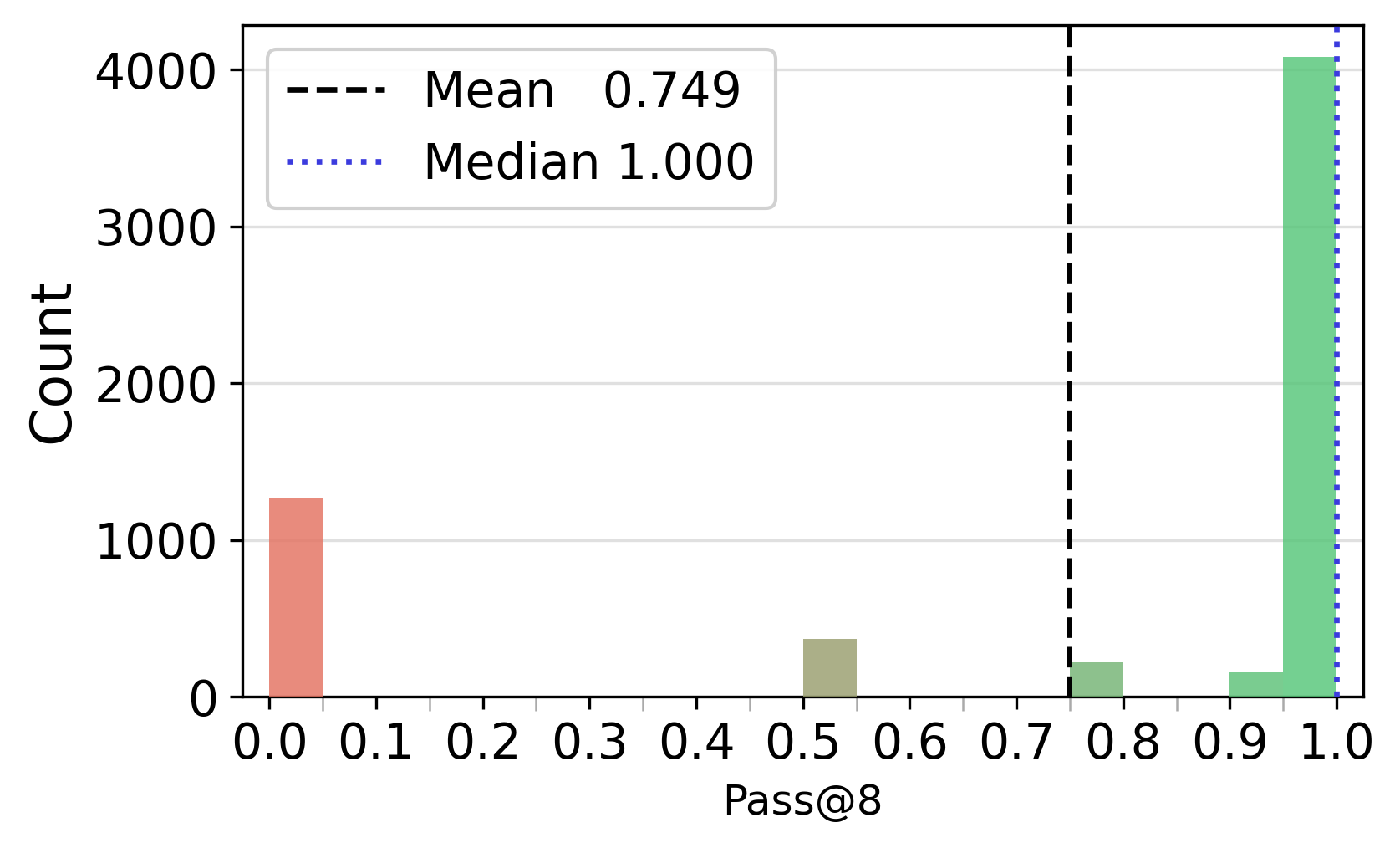
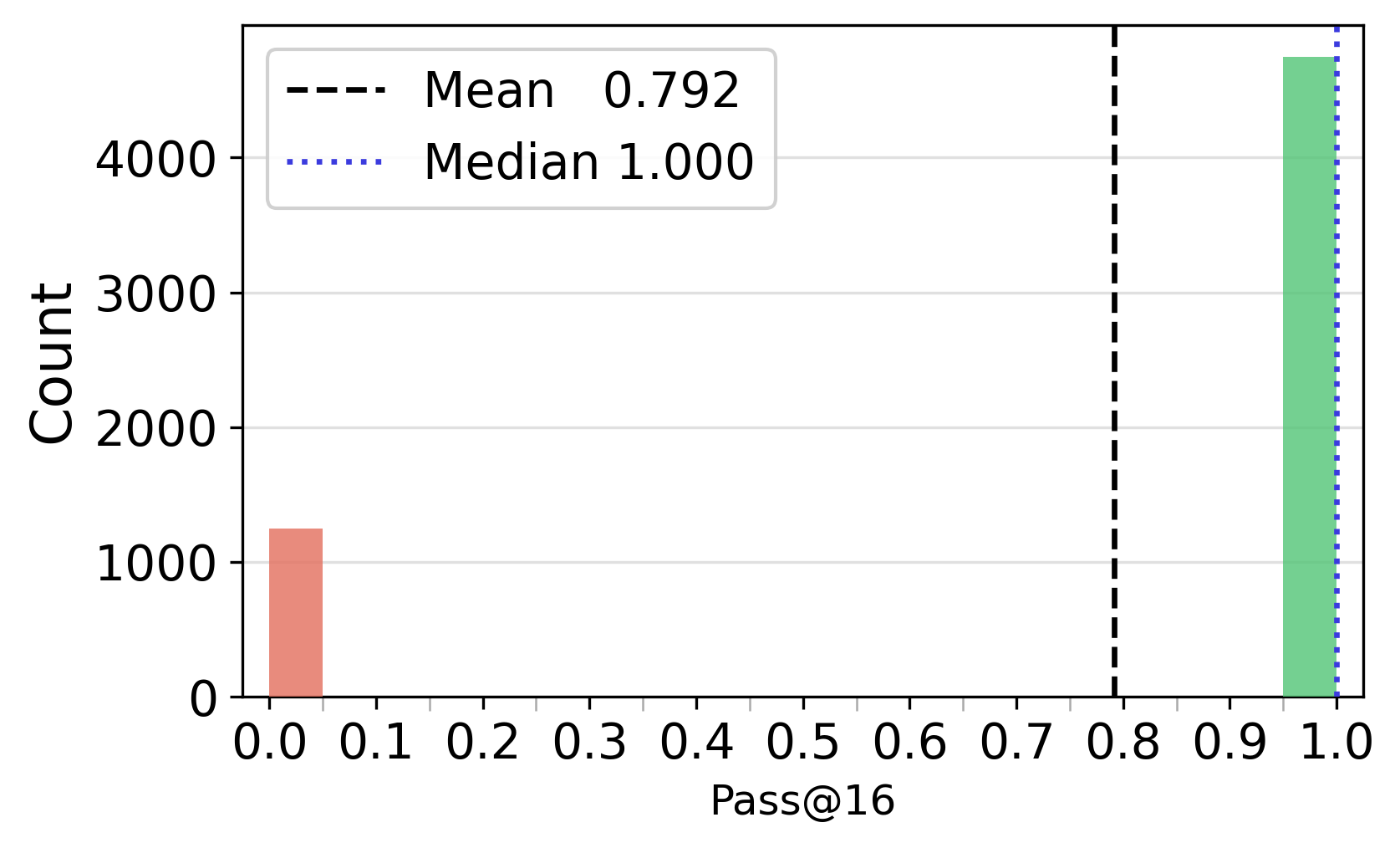
- Pass@: A metric reporting whether at least one of k sampled trajectories solves the problem. "We compute Pass@ over the 16 sampled trajectories per question"
- Qwen3-Embedding-8B: A large embedding model used to vectorize documents for dense retrieval. "Qwen3-Embedding-8B"
- ReAct-style paradigm: An interaction framework where models interleave reasoning (thoughts) and actions (tool calls). "Most deep research agents follow a ReAct-style paradigm"
- Rejection sampling: A data filtering method that retains only desired samples, such as correct trajectories, for training. "applying rejection sampling"
- Search drift: Deviation from productive search paths due to poor query formulation or misdirected iterations. "query formulation and search drift drive the performance gap"
- Serper API: A web search API used during bootstrapping or open-web evaluation. "Serper API"
- Supervised fine-tuning (SFT): Post-training where models learn from labeled trajectories or demonstrations. "supervised fine-tuning (SFT)"
- Teacher model: A stronger model used to generate trajectories that supervise a student model. "With GPT-OSS-120B as the teacher model"
- Turn budget: The maximum number of interaction steps (tool calls) allowed for the agent during a trajectory. "including turn budget"
Collections
Sign up for free to add this paper to one or more collections.