- The paper presents OmniSch, a novel benchmark with extensive multimodal annotations to enhance visual grounding and graph inference on PCB diagrams.
- The benchmark leverages an automated EDA engine-based annotation pipeline to generate detailed instance-level and spatial metrics, exposing limitations in current model detection and attribution.
- Experimental results reveal that existing LMMs struggle with fine-grained spatial, textual, and relational reasoning, underscoring the need for hybridized architectures.
OmniSch: A Multimodal PCB Schematic Benchmark for Structured Diagram Visual Reasoning
Introduction
OmniSch presents a unified large-scale benchmark targeting the structured visual reasoning required for machine understanding of real-world Printed Circuit Board (PCB) schematic diagrams. The construction and interpretation of machine-readable, spatially weighted netlist graphs from dense, annotated schematic diagrams remain largely unsolved by current LMMs and vision systems, despite real-world EDA workflows relying critically on such representations. Existing datasets are limited in scope, diversity, annotation richness, and complexity, often focusing on didactic or highly synthetic analog circuits. OmniSch addresses these gaps by furnishing comprehensive multimodal annotations and tasks that span instance-level grounding, semantic/structural reasoning, and graph construction.
Benchmark Design and Dataset Structure
OmniSch comprises 1,854 high-fidelity schematic diagrams sampled from real-world open-source PCB designs, annotated at multiple granularities: entity localization (symbols, pins), text instance linking, net aliasing, pin-to-pin topology, and layout-derived spatial metadata. Each image is augmented with 109.9K symbol instances, 245.4K pin annotations, and 423.4K text region-to-entity mappings, supporting richly supervised evaluation of compositional and relational visual reasoning.
Annotations and ground truth are generated via a custom EDA rendering engine that synthesizes images and simultaneously exports pixel-aligned attributes, in contrast to labor-intensive and inconsistent manual pipelines.
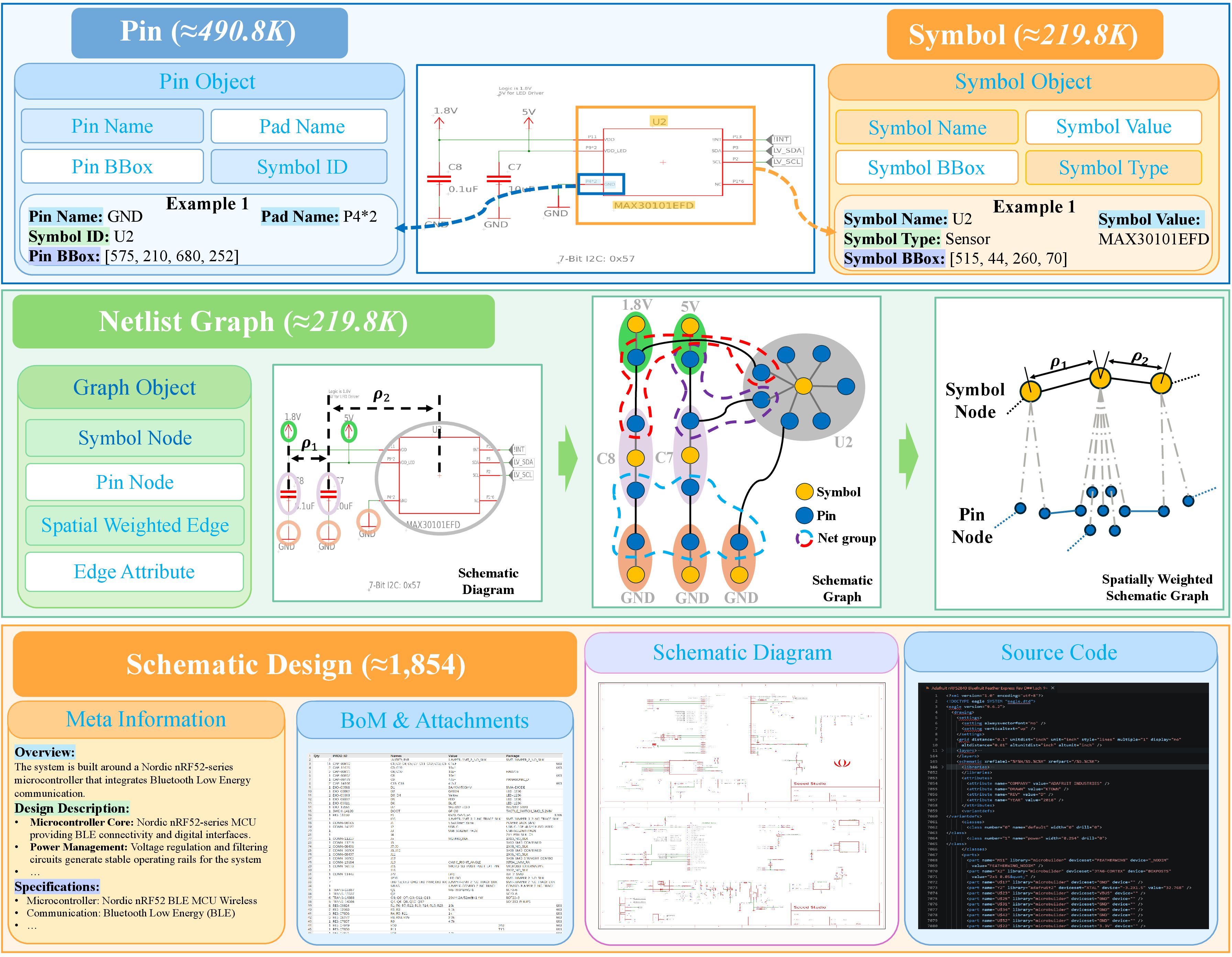
Figure 1: Schematic overview of the OmniSch benchmark, illustrating the diverse spectrum of annotated circuit entities and graph-based relationships.
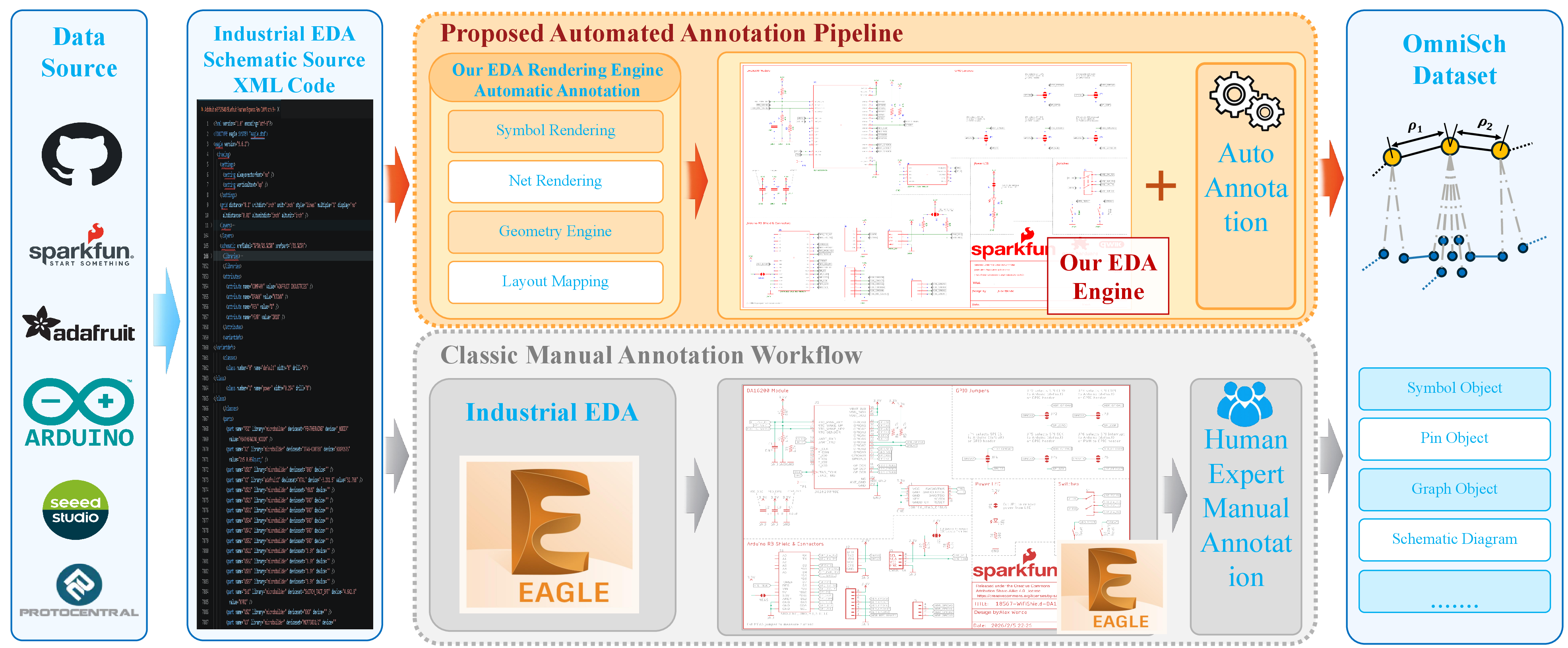
Figure 2: Data annotation paradigms—OmniSch leverages EDA engine-based automated annotation, surpassing slow, inconsistent manual labeling.

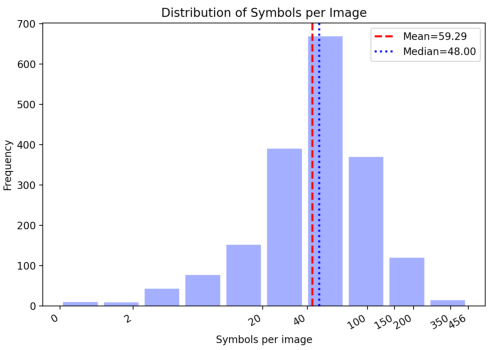
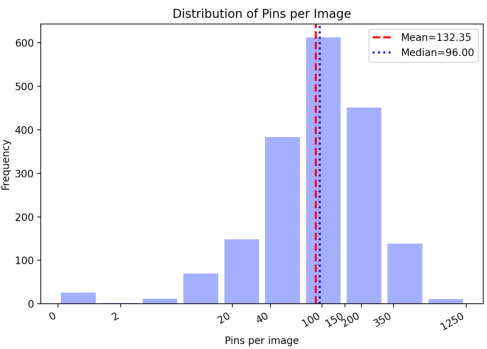
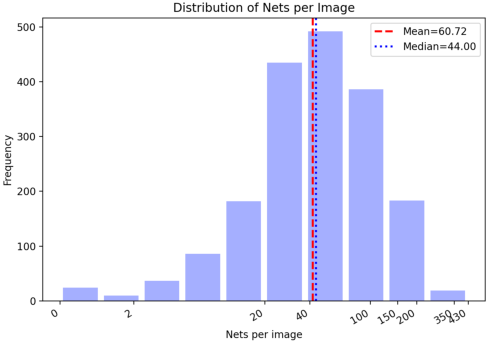
Figure 3: Statistical measures for OmniSch reveal diversity in symbol count, pin count, net complexity, and domain coverage.
Key OmniSch tasks include:
- Visual grounding: localizing, classifying, and attributing schematic entities and texts.
- Diagram-to-graph mapping: parsing global electrical connectivity as heterogeneous attributed graphs.
- Geometry-aware reasoning: incorporating layout-derived spatial weights on connections.
- Tool-augmented agentic reasoning: enabling external tool invocation for adaptive visual search, recognition, and local grounding.
Evaluation Protocols and Metrics
OmniSch employs a rigorous, structured evaluation methodology. Instance detection leverages F1 for symbol/pin localization. Semantic attribute matching requires exact string equivalence, reflecting the strictness demanded by netlist-generation tasks. Connectivity and graph metrics use F1 and edge set IoU post node alignment (via Hungarian matching), with both semantic-aware and structure-aware alignment variants to disentangle performance on textual vs. relational cues. Kendall’s τ quantifies layout-preserving fidelity of predicted graphs, rewarding models that respect schematic spatial organization.
Model Assessment and Analysis
LMM and Baseline Benchmarking
A spectrum of SOTA LMMs was benchmarked: GPT-5.2, Claude-Opus-4.6, Gemini 2.5/3.1, Qwen3-VL, LLaMA-4-Maverick, among others. Classical CV pipelines (YOLO11, PaddleOCR) serve as deterministic vision baselines.
End-to-end results reveal fundamental limitations in current models:
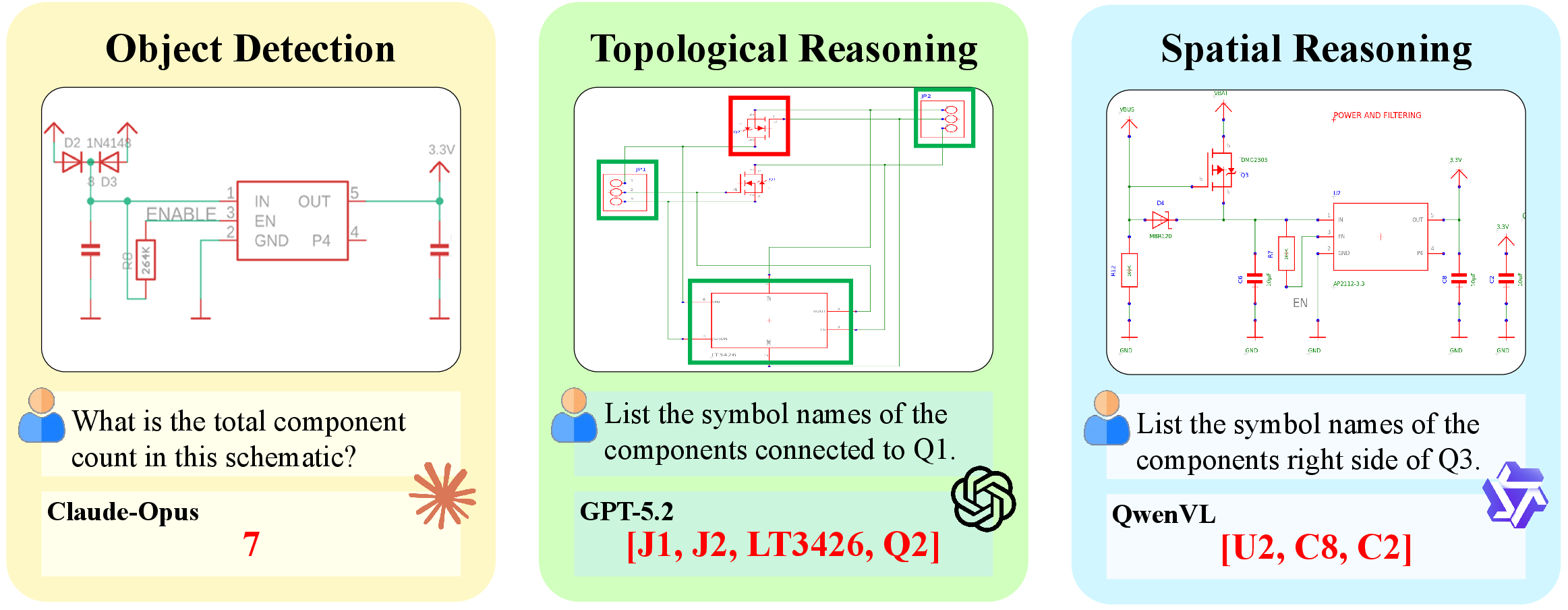
Figure 4: LMMs exhibit pronounced failures in visual grounding, component detection, and connective reasoning when analyzing structured schematics.
- Detection: On real schematics, Gemini 2.5-Flash attains the highest symbol F1 (0.706), but pin detection lags substantially (0.441), reflecting the difficulty of discriminating small, semantically loaded primitives.
- Attribution: Pin name and pad recognition remain low (<0.55 across most models), with textual attribute extraction presenting a recurring failure point.
- Graph Structure: Despite moderate F1 at detection, all models exhibit low graph IoU (e.g., Gemini 2.5-Flash at 0.195), demonstrating a bottleneck at topology inference.
- Spatial Reasoning: Only Gemini 3.1-Pro achieves competitive Kendall’s τ values, suggesting sensitivity to spatial arrangement is model-specific and not aligned with detection accuracy.
Incorporating external perception tools (e.g., external detectors for region proposals, agentic window control for zoom/pan) considerably improves attribute and connectivity scores across commercial and open-source LMMs. For example, Gemini-3.1-Pro-Preview outperforms others in tool-augmented settings, reflecting the effectiveness of explicit region-focused perception for schematic parsing.
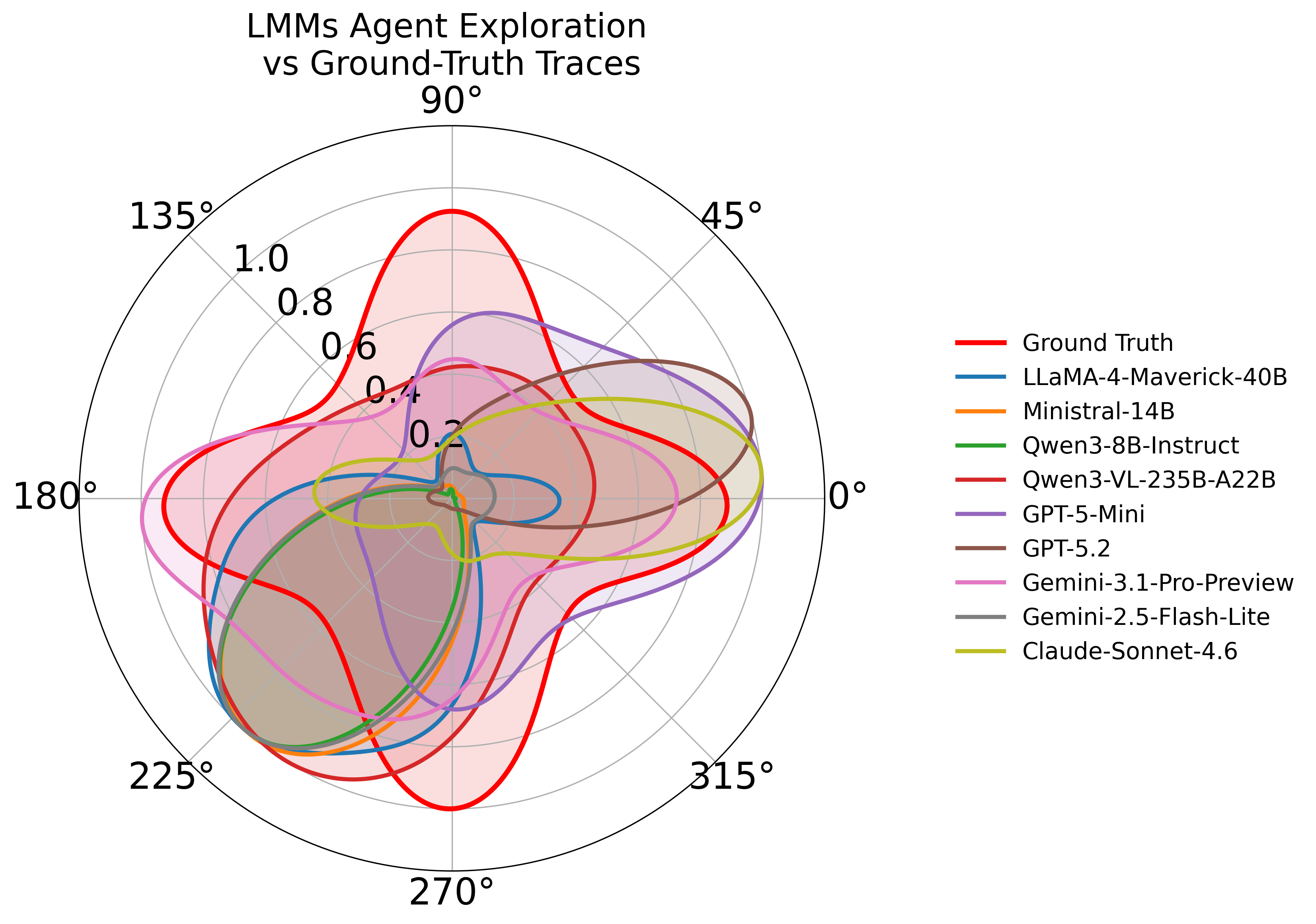
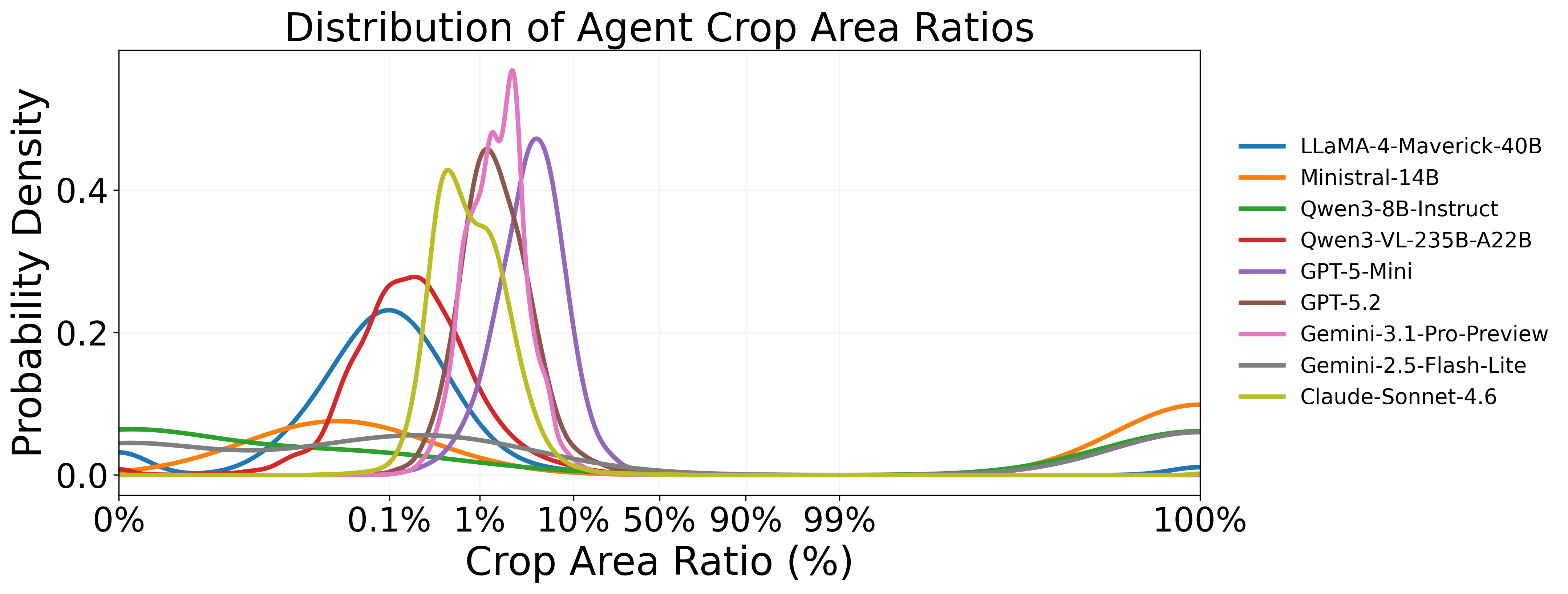
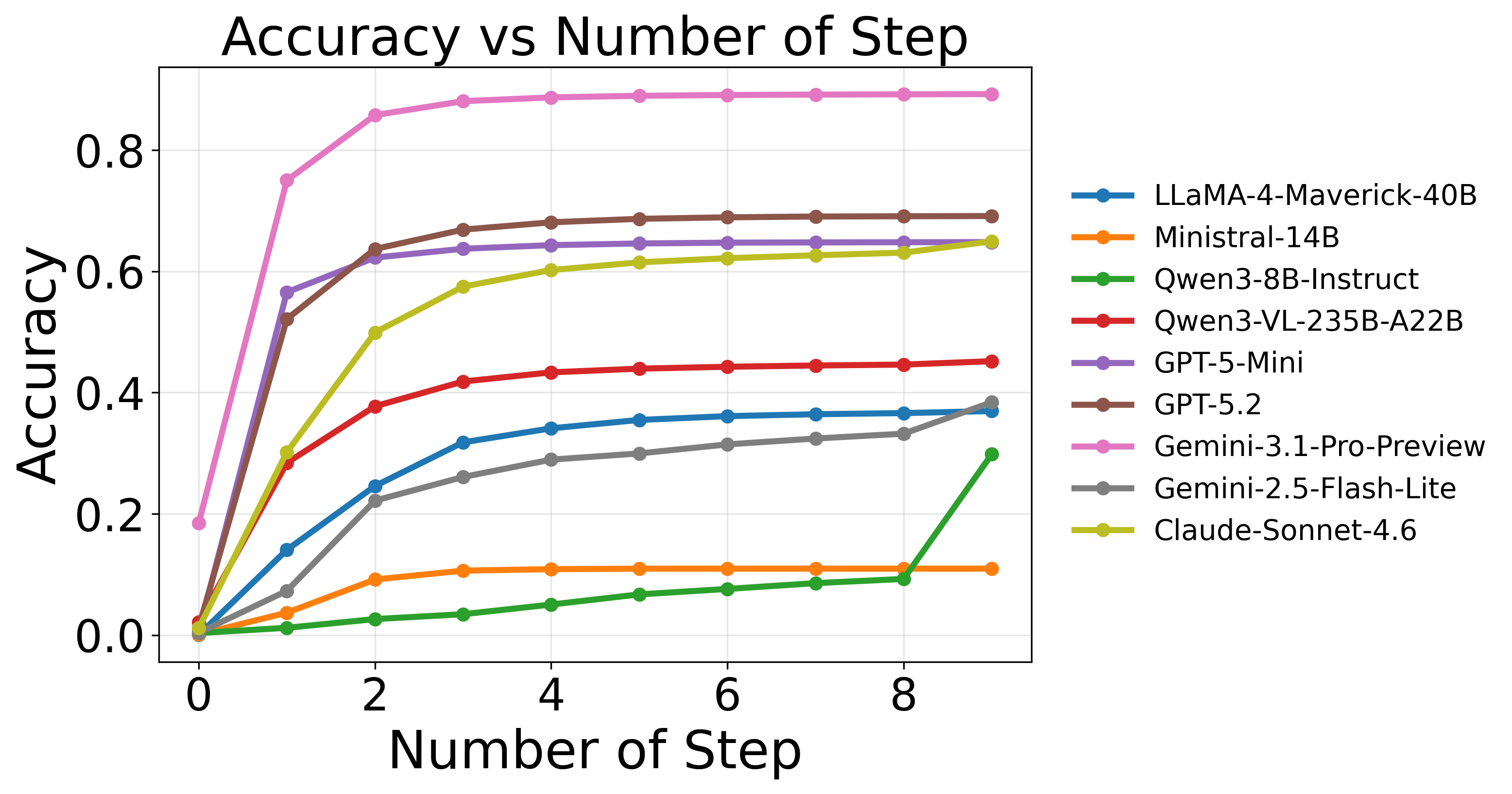
Figure 5: Comparative analysis of net-name tracing reveals model-dependent variability in search strategy and labeling consistency.
Key Findings
- Textual dependence: Most LMMs over-rely on symbol and net text; removing or perturbing text drastically reduces detection and relation performance, especially for Gemini and LLaMA models. In contrast, Claude models retain relatively higher performance, indicating partial compensation via visual structure.
- Topology Reasoning Gap: Improvements in few-shot or instruction-based prompting enhance local recognition (detection, attribute F1), but do not propagate to better global graph alignment—indicating an inherent architecture/execution disconnect for multi-hop, compositional relational reasoning.
- Fine-Grained Perception: Sub-symbolic entities (pins, small text) are systematically overlooked or misattributed; explicit region cropping/agentic tool invocation is essential for improvements.
- Net Name Entanglement: Associating net names with the correct visual/geometric wire trace is especially weak, reflecting unsolved integration of OCR, visual parsing, and graph induction modules within LMMs.
Implications and Future Directions
OmniSch exposes systematic deficiencies in end-to-end schematic-to-netlist understanding by both LMMs and classical pipelines. From a systems and method perspective, these findings have direct implications:
- Effective grounding of dense, compositional diagrams will require hybridized pipelines—combining explicit perceptual detectors with large-scale, multimodal sequence models, with tight integration of graph induction and spatial information flow.
- Benchmark complexity must be increased: Legacy datasets with small circuits or minimal text are not predictive of real-world deployment. Richer annotations, such as those in OmniSch, are essential for meaningful benchmarking and architectural improvement.
- Improved agentic/action learning: Enabling models to autonomously decide on visual search strategies (e.g., iterative zoom/pan, explicit sub-region focus) is critical for scaling LMM capabilities to dense technical artifacts.
- Theoretical Limitations: High-level language-centric prompting or instruction finetuning, without inductive architectural changes, appears insufficient for comopsitional structured reasoning—suggesting the need for new multimodal architectures that better factor graph and spatial constraints.
Conclusion
OmniSch constitutes a rigorous, multi-granular benchmark targeting the real-world demands of schematic diagram visual reasoning, with an emphasis on graph-structured target representations. The dataset, annotation pipeline, and analysis protocols set a new bar for the evaluation of LMM and multimodal systems in EDA-relevant contexts. The systematic model deficits revealed by extensive experiments highlight the need for architectural and algorithmic advances integrating vision, language, spatial reasoning, and graph induction. OmniSch is well-positioned to drive future progress by providing a principled, reproducible standard for comprehensive multimodal diagram understanding.
Citation: "OmniSch: A Multimodal PCB Schematic Benchmark For Structured Diagram Visual Reasoning" (2604.00270).