Qianfan-OCR: A Unified End-to-End Model for Document Intelligence
Abstract: We present Qianfan-OCR, a 4B-parameter end-to-end vision-LLM that unifies document parsing, layout analysis, and document understanding within a single architecture. It performs direct image-to-Markdown conversion and supports diverse prompt-driven tasks including table extraction, chart understanding, document QA, and key information extraction. To address the loss of explicit layout analysis in end-to-end OCR, we propose Layout-as-Thought, an optional thinking phase triggered by special think tokens that generates structured layout representations -- bounding boxes, element types, and reading order -- before producing final outputs, recovering layout grounding capabilities while improving accuracy on complex layouts. Qianfan-OCR ranks first among end-to-end models on OmniDocBench v1.5 (93.12) and OlmOCR Bench (79.8), achieves competitive results on OCRBench, CCOCR, DocVQA, and ChartQA against general VLMs of comparable scale, and attains the highest average score on public key information extraction benchmarks, surpassing Gemini-3.1-Pro, Seed-2.0, and Qwen3-VL-235B. The model is publicly accessible via the Baidu AI Cloud Qianfan platform.
First 10 authors:
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces Qianfan-OCR, a new “all-in-one” computer system that can read and understand documents from images. Instead of using separate tools to find where text is, read the words, and then make sense of them, Qianfan-OCR does everything in one go. It can turn a picture of a document straight into neatly formatted text (like Markdown), and it can also answer questions about the document, pull out key facts (like names or totals on receipts), understand tables and charts, and more.
What questions did the researchers ask?
The team focused on three big questions:
- Can one model replace complicated, multi-step OCR pipelines and still be fast and accurate?
- Can an “end-to-end” model keep track of layout (where things are on the page) without needing a separate layout tool?
- Can the same model both read text perfectly and understand it well enough to answer questions or extract important information?
How did they build and train the system?
To make this clear, think of Qianfan-OCR as a student learning to read documents:
- It has “eyes” (a vision part) to look closely at high-resolution pages.
- It has a “brain” (a LLM) to write, reason, and follow instructions.
- A small “bridge” connects the eyes and the brain so they understand each other.
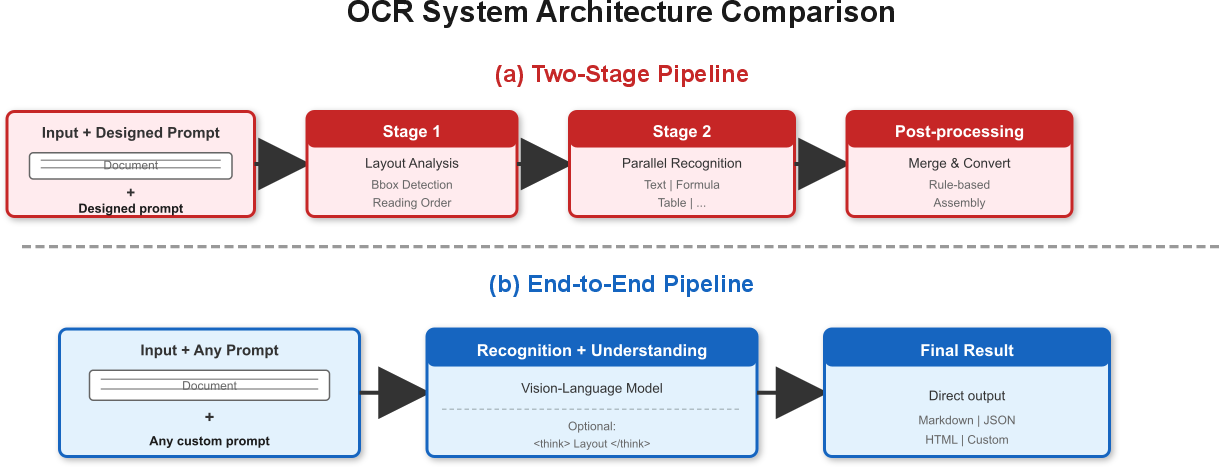
The all-in-one design
- Vision encoder (the “eyes”): It chops a big page into tiles so it can see tiny letters and details (like small fonts and dense tables). This helps it spot things like formulas or small text without losing clarity.
- LLM (the “brain”): A 4-billion-parameter model (think of “parameters” as the brain’s memory and skills). It writes answers, formats output, and reasons about the page.
- Adapter (the “bridge”): A small connector that teaches the vision and language parts to work together smoothly.
In simple terms: the system looks at the page, understands where things are, and writes out what it sees in a clean, structured way.
The “Layout-as-Thought” idea
One problem with end-to-end systems is that they don’t naturally tell you where things are on the page (like where a table or a figure is). Qianfan-OCR fixes this with an optional step called “Layout-as-Thought.”
- When you add a special “think” command, the model first makes a quick “map” of the page:
- It draws imaginary rectangles around elements (these are “bounding boxes”).
- It labels each element (text, table, image, formula, header, etc.).
- It lists them in the order a person would read them.
- Then it produces the final result (like Markdown text) using this map.
Why this helps:
- You can get the exact positions and types of elements if needed.
- On messy pages (like multi-column layouts, mixed text and images, or complicated tables), thinking about the layout first makes the final reading more accurate.
- On simple pages, you can skip this step to be faster.
Training approach (how the “student” learned)
The team trained the model in several steps, like a sports season with different kinds of practice:
- Basic alignment: Teach the eyes and brain to talk to each other on simple tasks.
- OCR foundation: A huge practice phase focused on reading text in many situations (documents, scenes, handwriting, formulas, tables, many languages).
- Special skills: Extra training on complex tables, charts, formulas, key information extraction, and multilingual cases.
- Instructions and reasoning: Teach the model to follow different types of prompts (questions, conversion tasks, and more) and to reason better.
To supply enough practice, they built large, high-quality datasets by:
- Converting real documents into structured formats (like Markdown and HTML for tables).
- Generating lots of realistic tables and charts (including from research papers).
- Creating multilingual pages in many scripts (almost 200 languages).
- Adding realistic “noise” (blur, stains, rotations) so the model can handle messy scans and photos.
They also tested their training recipe and found:
- The big “foundation” training phase is essential.
- Mixing general data with OCR-specific data prevents the model from overfitting and keeps it well-rounded.
- The full 4-stage training plan worked best.
What did they find?
The results show that Qianfan-OCR is one of the best end-to-end document models, with performance that rivals or beats many multi-step pipelines:
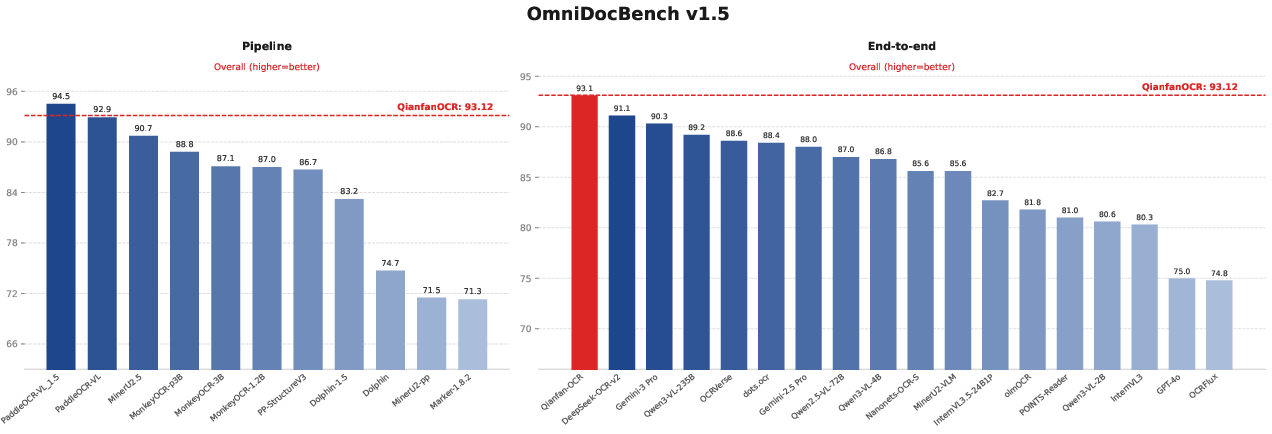
- On OmniDocBench v1.5 (a major test for document parsing), Qianfan-OCR ranked first among end-to-end models (93.12), and even beat several traditional pipelines.
- On OlmOCR Bench (another end-to-end test), it also ranked first among end-to-end models (79.8).
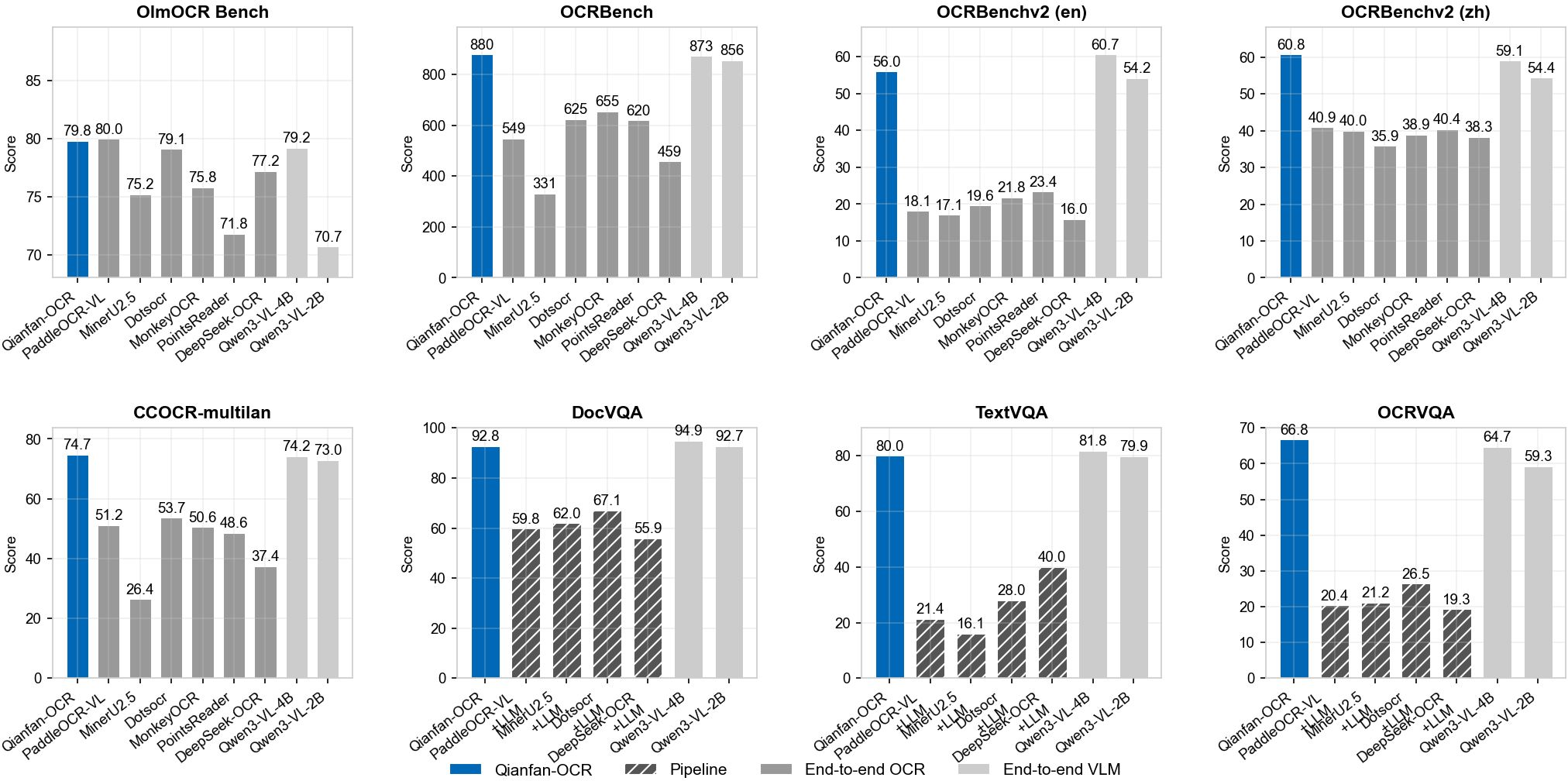
- On general OCR tests (like OCRBench and OCRBenchv2), it scored very well, especially in multilingual settings.
- On document understanding tasks (like answering questions about documents, tables, or charts), it performed strongly—often matching or beating general-purpose vision-LLMs of similar size.
- For Key Information Extraction (pulling specific fields from receipts, forms, etc.), it achieved the highest average scores among the compared systems, including some well-known commercial and open-source models.
About “Layout-as-Thought”:
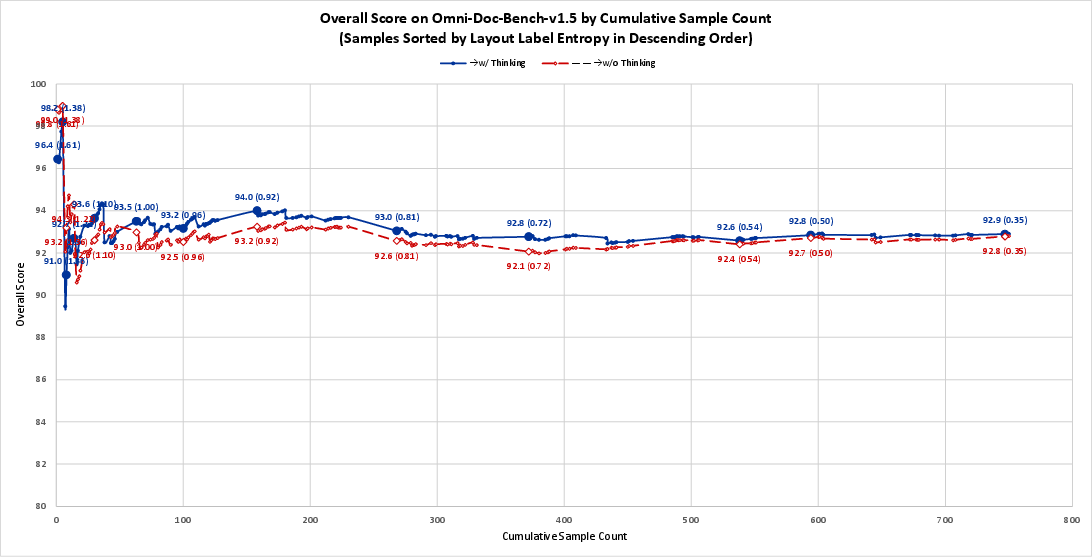
- Turning on the “think” step helps most on complicated pages with mixed content (e.g., pages with text, tables, and figures together).
- On simple pages, the no-think mode is faster and can be slightly better overall.
- In other words: use “think” for messy layouts; skip it for clean pages.
Why this is important:
- Two-stage systems (OCR first, then a separate LLM) often lose the page’s structure (like chart axes, table layout, or reading order). Qianfan-OCR keeps that context, which is crucial for charts, tables, and complex documents.
- In tests that needed chart understanding or academic reasoning, the two-stage pipelines performed poorly, while Qianfan-OCR did very well.
Why does this matter?
- Simpler pipelines, lower costs: Instead of juggling multiple tools (layout detector + text reader + separate AI for understanding), teams can use one model. This reduces engineering complexity and mistakes that happen when one stage fails and affects the next.
- Better layout awareness: With the optional thinking step, users get the best of both worlds—end-to-end convenience plus precise positions and types of elements.
- Broad usefulness: From scanning receipts and contracts to parsing reports, tables, and charts, this model can power document search, data entry, auditing, analytics, and more.
- Real-world readiness: The model handles many languages and messy scans, making it practical for global and varied use cases.
In short, Qianfan-OCR shows that a single, well-trained system can read documents, understand their structure, and answer questions about them—accurately and efficiently. It could make document processing faster, smarter, and easier to deploy for schools, businesses, and apps that deal with lots of paperwork.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, consolidated list of concrete gaps and open questions that remain unresolved and could guide future research:
- Lack of open reproducibility: model weights, full training recipes, and large-scale synthesized/curated datasets (including licenses and provenance) are not released; reproducible training and contamination auditing (e.g., test-set overlap dedup) remain unaddressed.
- Quantitative evaluation of Layout-as-Thought (LoT) as a layout detector is missing: no mAP/IoU-style metrics against human-annotated layout benchmarks (e.g., PubLayNet/DocLayNet); only indirect gains reported on OCR conversion metrics.
- No automatic controller for when to enable LoT: the paper shows LoT helps on high-layout-entropy pages but hurts simpler pages; there is no learned policy, confidence, or heuristic to switch modes per-document/page.
- Latency and throughput are not reported: wall-clock speed, KV cache footprint, and cost comparisons vs. strong pipeline baselines (with and without LoT) are missing; the real-world serving trade-off is unclear.
- Coordinate quantization limits and geometry: bounding boxes are quantized to 0–999 tokens and seem axis-aligned; there is no study on precision loss at high DPI, support for rotated boxes/polygons, or adaptive quantization/tile-local coordinates.
- Multi-page document handling remains underspecified: the architecture and evaluations focus on single images; practical issues like cross-page reading order, references/footnotes, long-context memory, and page-level scheduling are not evaluated.
- Robustness and OOD generalization: despite augmentations, there is limited analysis under severe degradations (extreme blur, glare, occlusion, skew, bleed-through, stamps, heavy handwriting overlap) and realistic mobile capture scenarios.
- Hallucination and reliability: while KIE data construction tries to mitigate teacher hallucinations, there is no systematic measurement of hallucination rates in final outputs (e.g., fabricated text/tables) or calibrations to detect/avoid them.
- Fair baseline design for pipeline comparisons: the two-stage OCR+LLM baselines discard layout/visual signals before reasoning; stronger pipeline variants that pass structured layout (bboxes, table HTML, chart metadata) to the LLM are not studied.
- Error analysis depth: limited breakdown of failure modes by element (e.g., small fonts, math inline vs display, nested tables, rotated/vertical text, figure-caption association); actionable per-category diagnostics are missing.
- Long-context capabilities are not stress-tested: the claimed 32K–131K context window is not evaluated on long multi-page PDFs for fidelity, ordering, and memory/latency scaling.
- Chart understanding supervision quality: synthetic chart descriptions rely on VLM-generated labels; the noise rate, bias, and impact on factual chart reasoning (e.g., subtle trend/correlation) are not quantified.
- Script- and language-specific performance: multilingual coverage is claimed (192 languages) but lacks per-script breakdowns (Arabic shaping/diacritics, Devanagari conjuncts, Thai segmentation, vertical Japanese, mixed CJK + Latin), directionality errors, or ablations on real vs synthetic data.
- Reading order robustness: beyond OmniDocBench R-order edits, there is no targeted benchmark for multi-column/page reading order, figure/table anchoring, and caption association under layout edge cases.
- KIE evaluation granularity: field-level F1 by category (dates, totals, line-items, addresses), spatial grounding accuracy for extracted fields, and robustness to template drift/zero-shot templates are not reported.
- Safety, privacy, and compliance: handling of PII in KIE, redaction support, auditability, and defenses against adversarial prompts in images (e.g., hidden instructions, toxic overlays) are not discussed.
- Scalability and scaling laws: no study of model-size vs. data-size trade-offs (e.g., 1B/7B/13B variants), diminishing returns, or compute-optimal training for document tasks; only limited 8B proxy ablations are provided.
- Tile resolution constraints: the AnyResolution tiling caps visual tokens and resolution; the impact on tiny text, dense tables, and very large pages (e.g., A0 scans) is not characterized; adaptive tiling or zoom-in policies are unexplored.
- Structure preservation limits: while Markdown/HTML are produced, the fidelity of complex constructs (nested lists, cross-references, footnote placement, multi-page tables, math/figure cross-links) needs targeted, standardized metrics and error audits.
- Integration with vector PDFs: the system ignores available vector text/graphics in PDFs; hybrid pipelines that fuse rendered images with native PDF objects (text runs, paths) are not considered.
- Training data mixture ablations at 4B: Stage 3/4 mixture ratios and domain weights are only validated at 8B; their transfer to the 4B model lacks systematic ablation or sensitivity analysis.
- RL and structured rewards: the paper mentions RL in related work but does not explore layout-aware or unit-test rewards (e.g., TEDS, R-order) for improving LoT reasoning and structural fidelity.
- Grounded answerability and uncertainty: no mechanisms to provide calibrated confidence, abstention, or grounding spans/bboxes for answers (especially in KIE/DocVQA), nor evaluations of calibration quality.
- Orientation and script auto-detection: rotation augmentation is used, but no explicit orientation/script detection module or evaluation of failure cases (e.g., mixed orientations on the same page).
- Interoperability and determinism: controlling output determinism for downstream pipelines (e.g., stable HTML schemas, escaping, tokenization) and backward-compatible schema evolution are not discussed.
- Transfer to specialized verticals: performance on domain-specific documents (medical, legal, patents, financial prospectuses) with domain terminology, watermarks, and compliance formatting is not evaluated.
- Adversarial robustness: resilience to adversarial typography (look-alike glyphs, font spoofing), background artifacts, and layout attacks that induce wrong reading order is not assessed.
- Human-in-the-loop editing: the paper does not propose tools/metrics for post-edit costs (keystrokes to correct), nor ways to expose/consume LoT outputs for efficient human correction.
- Bounding-box to text alignment quality: there is no evaluation of token-level alignment errors (off-by-one characters, merged/split lines) that affect downstream extraction and grounding tasks.
- Policy for combining LoT with direct decoding: beyond a binary on/off, hybrid strategies (e.g., selective LoT for detected regions, iterative refinement, self-verification) are not explored.
Practical Applications
Immediate Applications
Below are practical, deployable use cases that can be implemented now, leveraging the paper’s image-to-Markdown conversion, prompt-driven task control, Layout-as-Thought for spatial grounding, strong OCR/KIE benchmarks, multilingual coverage, and public availability on Baidu AI Cloud Qianfan.
- Accounts Payable automation and invoice/receipt parsing — Sector: finance, retail, logistics; Tools/Workflow: “Document-to-Markdown” microservice + KIE templates; extract vendor, line items, taxes, totals; validate with business rules (e.g., unit price × quantity = total); Assumptions/Dependencies: adequate image quality; template variability; enable Layout-as-Thought for multi-column or dense layouts to reduce ambiguities.
- Contract review and legal document summarization with spatial evidence — Sector: legal, compliance; Tools/Workflow: clause extraction and obligation timelines, with bounding boxes for auditability; prompt the model for specific clause types (termination, indemnity, jurisdiction) and sequence in reading order; Assumptions: confidentiality and data governance; non-standard formats benefit from Layout-as-Thought; verify outputs with human-in-the-loop.
- ID/KYC extraction and verification — Sector: fintech, telecom, government services; Tools/Workflow: field extraction (name, ID number, expiry, issuing authority) and bbox grounding for redaction/verification; integrate with downstream liveness checks; Assumptions: multilingual script coverage and RTL handling (Arabic) supported by the model; image quality and glare removal; template variance per jurisdiction.
- Healthcare intake, claims, and EHR digitization — Sector: healthcare and insurance; Tools/Workflow: form field extraction, medical bill table normalization (HTML), standardized coding capture; tie outputs to EHR systems; Assumptions: PHI privacy requirements; clinical abbreviations; rotation augmentation helps non-standard orientations; use reading-order guidance to preserve semantic flow.
- RAG-ready enterprise document ingestion — Sector: software/enterprise search; Tools/Workflow: image-to-Markdown/HTML conversion for chunked indexing; generate precise layout-aware chunks (headers, footers, tables, figures) to improve retrieval quality; Assumptions: ingestion of high-resolution scans (AnyResolution up to 4K); alignment to RAG pipeline schemas; cost/performance budget for large-scale ingestion.
- Data labeling acceleration for OCR datasets — Sector: ML ops, data annotation; Tools/Workflow: use Layout-as-Thought to pre-annotate bounding boxes, element types, reading order; human review and correction to reach gold labels; Assumptions: coordinate special tokens make outputs compact; quality thresholds to minimize correction burden.
- Chart understanding assistant for reports and dashboards — Sector: business intelligence, journalism, research; Tools/Workflow: ChartQA-style prompts for trend, outlier, correlation insights across 11 common chart types; Assumptions: chart types within trained categories; captions or metadata optional; complex charts benefit from > to anchor axes and legends.
Table-to-HTML/CSV normalization with merged cells — Sector: data engineering, audit, finance; Tools/Workflow: convert complex tables (row/column spans) to well-formed HTML then CSV; preserve TEDS structure; Assumptions: real-world table noise handled by synthesis-trained model; use Layout-as-Thought when cell merging or nested headers are present.
- Formula recognition and LaTeX conversion — Sector: education, publishing, scientific workflows; Tools/Workflow: wrap block/display formulas in ; integrate with KaTeX/MathJax; Assumptions: formula CDM-level accuracy on scans; diagrams/formulas interleaved require reading-order reasoning.
- Document QA for policies/procedures manuals — Sector: customer support, HR, operations; Tools/Workflow: DocVQA/TextVQA-style answering; link answers to page coordinates for traceability; Assumptions: documents contain mixed elements; “no-think” for simple layouts to reduce latency; enable <think> for heterogeneous pages.
- Multilingual digitization and translation-ready OCR — Sector: government, NGOs, global enterprises; Tools/Workflow: OCR across 192 languages with RTL detection and reshaping; feed Markdown to MT systems; Assumptions: font renderability; script-specific line breaking; verify accuracy on low-resource scripts.
- Accessibility: reading-order-preserving transcription — Sector: accessibility, education; Tools/Workflow: produce logically ordered Markdown for screen readers, maintaining headers/footers, footnotes; Assumptions: reading-order Edit improvements; Layout-as-Thought helps multi-column newspapers and textbooks.
- Compliance auditing and PII redaction — Sector: finance, healthcare, public sector; Tools/Workflow: KIE rules + bbox outputs to auto-locate fields for redaction masks; audit logs show spatial evidence; Assumptions: reliable element classification; integration with DLP systems; human validation for regulatory-grade trust.
- Mobile scanning and personal finance receipt tracking — Sector: consumer apps; Tools/Workflow: smartphone capture → OCR → categorized expense entries; Assumptions: variable lighting/blur; rotation augmentation improves robustness; device-side preprocessing (denoise, deskew).
- Digitization of historical archives and old scans — Sector: libraries, cultural heritage; Tools/Workflow: OCR and layout restoration for degraded pages; Assumptions: performance on “old scans” category is good but may need human review for preservation-grade accuracy.
- Adaptive inference: auto-toggle Layout-as-Thought — Sector: software platforms; Tools/Workflow: “layout entropy” heuristic to enable <think> only on heterogeneous pages; Assumptions: simple runtime classifier or entropy proxy; reduced latency and cost on simple documents.
Long-Term Applications
These uses will benefit from further research, scaling, integration, or standardization before widespread deployment.
- Layout-grounded, explainable contract comprehension with audit trails — Sector: legal/compliance; Tools/Workflow: standardized evidence artifacts (bbox tokens, element labels, reading-order provenance) for regulatory audits; Assumptions: industry standards for spatial evidence formats; governance and certification frameworks.
- Reconstructing chart data tables from images for reproducibility — Sector: academia, journalism, BI; Tools/Workflow: chart-to-data extraction (axes, scales, points) to regenerate underlying datasets; Assumptions: advanced chart parsing beyond QA; robust handling of composite charts; potential RL or specialized modules.
- Multi-page, multi-document workflow orchestration — Sector: enterprise automation; Tools/Workflow: cross-page reading-order, entity linking, document stitching (contracts + amendments + invoices); Assumptions: sequence modeling across large context windows; memory optimization; schema consolidation.
- Knowledge graph construction from semi-structured corpora — Sector: enterprise KM, research; Tools/Workflow: entity/relation extraction grounded in layout-aware provenance; Assumptions: expanded reasoning for disambiguation; ontology alignment; high-accuracy KIE across diverse templates.
- Edge/on-device private OCR for regulated environments — Sector: healthcare, finance, defense; Tools/Workflow: quantized 4B model with selective <think> to fit memory/latency constraints; Assumptions: hardware acceleration; model compression/QAT; privacy-preserving inference.
- Runtime “layout complexity detector” — Sector: software tooling; Tools/Workflow: classifier that predicts benefit of Layout-as-Thought to auto-route inference; Assumptions: training on entropy/heterogeneity signals; minimal overhead; policy controls for SLA and cost.
- Domain-specialized synthetic data generation as a product — Sector: ML tooling; Tools/Workflow: turnkey generators for tables, forms, charts, multilingual documents to bootstrap OCR/KIE; Assumptions: licensing/usage rights; coverage for niche domains (e.g., customs forms, clinical notes).
- Standardized spatial-grounding APIs and provenance schemas — Sector: software standards, compliance; Tools/Workflow: interoperable bbox token formats (<COORD_0..999>), element taxonomies, layout tags (<layout>...</layout>) for cross-system exchange; Assumptions: community/industry adoption; integration with PDF/HTML standards.
- Automation for regulatory reporting and audit reconciliation — Sector: finance/energy/telecom; Tools/Workflow: KIE + business rules to auto-populate filings; layout-grounded evidence and exception handling; Assumptions: extremely low error tolerance; extensive validation pipelines; human oversight.
- Low-resource language expansion and script-specific robustness — Sector: public sector, NGOs; Tools/Workflow: targeted data augmentation and font coverage; Assumptions: additional datasets and fonts; evaluation on rare scripts; community partnerships.
- eDiscovery with spatial provenance and chain-of-custody — Sector: legal; Tools/Workflow: OCR + layout reasoning to pinpoint relevant passages and preserve spatial traceability; Assumptions: evidentiary standards; secure pipelines; integration with eDiscovery platforms.
- Intelligent redaction and privacy-by-design pipelines — Sector: compliance/security; Tools/Workflow: PII detection with bbox + contextual reasoning (headers/footers, footnotes) to avoid over-redaction; Assumptions: policy tuning; risk scoring; legal review.
- Human-in-the-loop government digitization programs — Sector: policy/public administration; Tools/Workflow: large-scale digitization with model outputs triaged by difficulty; Layout-as-Thought for hard pages; Assumptions: workforce training; procurement and cloud/edge choices; fairness and accessibility mandates.
Cross-cutting assumptions and dependencies
- Deployment and access: the model is publicly accessible via Baidu AI Cloud Qianfan; cloud connectivity, cost controls, and data governance are necessary.
- Input quality: high-resolution imagery (up to 4K) improves results; rotation/denoise/deskew can be required for consumer captures.
- Task control: enable <think> for heterogeneous, complex layouts and disable it for simple pages to balance accuracy and latency.
- Multilingual coverage: while strong across 192 languages, rare scripts and specialized typography may need domain data and validation.
- Trust and compliance: for regulated use cases, incorporate human review, audit logs, and domain-specific rule checks; measure error rates against required standards.
- Integration: align outputs (Markdown/HTML, bbox tokens, labels) with downstream systems (RAG, DLP, ERP, EHR) and standard schemas.
Glossary
- 3D parallelism: Distributed training that combines data, tensor, and pipeline parallelism to scale large models efficiently. "using 3D parallelism (data, tensor, and pipeline parallelism with communication-computation overlap)"
- Ablation study: A controlled evaluation to assess the impact of components or stages by removing or altering them. "Ablation study on multi-stage training effectiveness using Qianfan-VL-8B."
- AdamW: An optimizer that decouples weight decay from gradient-based updates to improve generalization. "AdamW (=0.9, =0.95)"
- Adapter-only training: A fine-tuning approach that updates only small adapter modules while freezing most model parameters. "Stage 1: Cross-Modal Alignment (50B tokens) -- Establishes fundamental vision-language alignment with adapter-only training"
- AnyResolution: A design that dynamically tiles images into patches to handle variable resolutions without fixed-size constraints. "It adopts the AnyResolution design that dynamically tiles input images into 448448 patches"
- Bounding boxes: Rectangular coordinates used to localize elements in images or documents. "bounding boxes, element types, and reading order"
- Catastrophic forgetting: A phenomenon where a model loses previously learned capabilities when trained on new data. "preventing catastrophic forgetting."
- Chart understanding: Interpreting charts’ visual encodings and data to answer questions or extract insights. "chart understanding, document question answering, and key information extraction"
- Context window: The maximum sequence length a LLM can consider at once. "a 32K native context window (extendable to 131K via YaRN)"
- Coordinate special tokens: Dedicated tokens that encode numeric coordinates compactly within the model’s vocabulary. "represented as dedicated special tokens <COORD_0> through <COORD_999>."
- Cross-modal alignment: Learning to align and relate information across different modalities (e.g., vision and language). "cross-modal alignment with adapter-only training"
- DocVQA: A benchmark for document visual question answering that tests understanding of document images. "document understanding tasks such as DocVQA, ChartQA, and CharXiv"
- End-to-end: A single-model approach that directly maps inputs to outputs without separate modular stages. "ranking first among all end-to-end models."
- GELU: A smooth, non-linear activation function often used in Transformer models. "GELU activation"
- Grouped-Query Attention (GQA): An attention mechanism that shares key/value projections across groups of query heads to reduce memory and compute. "Grouped-Query Attention (GQA) with 32 query heads and 8 KV heads"
- GRPO reinforcement learning: A reinforcement learning method (GRPO) used to optimize model outputs based on programmatic rewards. "GRPO reinforcement learning with unit-test rewards."
- Instruction tuning: Fine-tuning a model on instruction–response pairs to improve following user prompts. "Stage 4: Instruction Tuning and Reasoning Enhancement"
- Inter-stage error propagation: Errors from earlier pipeline stages that propagate and degrade performance in later stages. "inter-stage error propagation"
- Key Information Extraction (KIE): Extracting specific structured fields (e.g., names, dates, totals) from documents. "Key Information Extraction (KIE):"
- KV cache: Cached key/value tensors used to speed up autoregressive attention during generation. "reducing KV cache memory by 4 compared to standard multi-head attention"
- Layout analysis: Detecting and classifying document elements and their spatial arrangement. "explicit layout analysis"
- Layout-as-Thought: An optional intermediate phase where the model explicitly reasons about layout before producing final outputs. "Layout-as-Thought"
- Layout label entropy: A measure of the diversity of element types on a page, used to characterize layout complexity. "layout label entropy"
- Multilingual OCR: Optical character recognition that supports multiple languages and scripts. "Multilingual OCR Data Construction:"
- Multi-stage progressive training: A training strategy that builds capabilities through sequential stages with tailored data mixes. "multi-stage progressive training"
- OTSL: An intermediate format used to convert tables for reliable HTML rendering and structure preservation. "OTSL intermediate format"
- Pipeline OCR Systems: Multi-stage systems that separate layout detection and text recognition into distinct modules. "Pipeline OCR Systems."
- Reading order: The sequence in which document elements should be read to preserve semantics. "reading order accuracy"
- Regularizer: A technique to prevent overfitting by constraining the model during training. "acts as an effective regularizer"
- Reinforcement learning: An optimization paradigm where models learn policies via feedback (rewards), beyond supervised signals. "reinforcement learning"
- RMSNorm: A normalization technique that uses root-mean-square statistics to stabilize training. "RMSNorm~\citep{zhang2019root} is used for layer normalization, improving training stability."
- SFT-based training: Supervised fine-tuning on labeled examples to adapt a pretrained model to specific tasks. "scaled SFT-based training on large-scale web documents"
- Spatial grounding: Associating textual outputs with precise locations in an image or document. "spatial grounding results"
- TEDS: A tree-edit-distance-based similarity metric for evaluating table structure reconstruction quality. "structure-sensitive metrics (e.g., table TEDS, reading order accuracy)."
- Transformer layers: Stacked self-attention and feed-forward blocks that form the backbone of many modern models. "The encoder consists of 24 Transformer layers"
- Vision-LLM (VLM): A model jointly trained on images and text to perform multimodal reasoning and generation. "Large VLMs such as Qwen-VL~\citep{bai2023qwen,bai2025qwen2}, InternVL~\citep{chen2024internvl,zhu2025internvl3}, and Gemini"
- VLMEvalKit: A toolkit for standardized evaluation of vision-LLMs across benchmarks. "Our evaluation framework is primarily based on VLMEvalKit~\citep{duan2024vlmevalkit}"
- Visual tokens: Tokenized representations of image patches/features consumed by a LLM. "producing 256 visual tokens per tile."
- YaRN: A technique for extending a model’s context window beyond its native length. "extendable to 131K via YaRN"
Collections
Sign up for free to add this paper to one or more collections.