- The paper introduces a coarse-to-fine architecture that uses VRFM and PaddleOCR-VL-0.9B to enhance document parsing efficiency and accuracy.
- It achieves state-of-the-art results on multiple benchmarks, significantly reducing vision tokens and improving throughput.
- The decoupled layout analysis and element recognition stages enable scalable, multilingual document intelligence for diverse applications.
Coarse-to-Fine Visual Processing for Efficient and Accurate Document Parsing
Motivation and Context
The exponential proliferation of digital documents, coupled with their increasing structural complexity and heterogeneity, has accentuated the urgent need for robust, scalable document parsing systems. Fine-grained recognition tasks—such as extracting text, tables, formulas, and charts—require high-resolution image analysis to preserve semantic integrity. However, conventional vision-LLMs (VLMs) incur prohibitive computational costs due to quadratic scaling with image resolution and vision token count, a consequence largely attributed to the substantial redundancy in visual regions (e.g., backgrounds, decorative elements). The paper addresses these inefficiencies by proposing a principled coarse-to-fine architecture that selectively processes semantically relevant regions, optimizing for both accuracy and resource consumption (2603.24326).
Architecture of PaddleOCR-VL
Coarse-to-Fine Pipeline
The PaddleOCR-VL framework crucially decouples document layout analysis from element-level recognition via a hierarchical approach:
- Valid Region Focus Module (VRFM): The coarse stage utilizes a lightweight module to perform region localization, element categorization, and reading order prediction. VRFM leverages a RT-DETR backbone with an integrated pointer network, enabling joint spatial and relational modeling for layout detection and sequencing.
- PaddleOCR-VL-0.9B Vision-LLM: The fine stage applies a compact VLM—PaddleOCR-VL-0.9B—on the valid regions extracted by VRFM, optimizing for element-level recognition (text, table, formula, chart). This eliminates redundant token processing and enables dynamic-resolution input handling, mitigating distortion and hallucination effects inherent in fixed-size or tiled approaches.
The architectural distinction from monolithic end-to-end VLMs is illustrated below.
Figure 1: Coarse-to-fine processing discards visual redundancy, retaining valid regions and substantially reducing vision token cost.
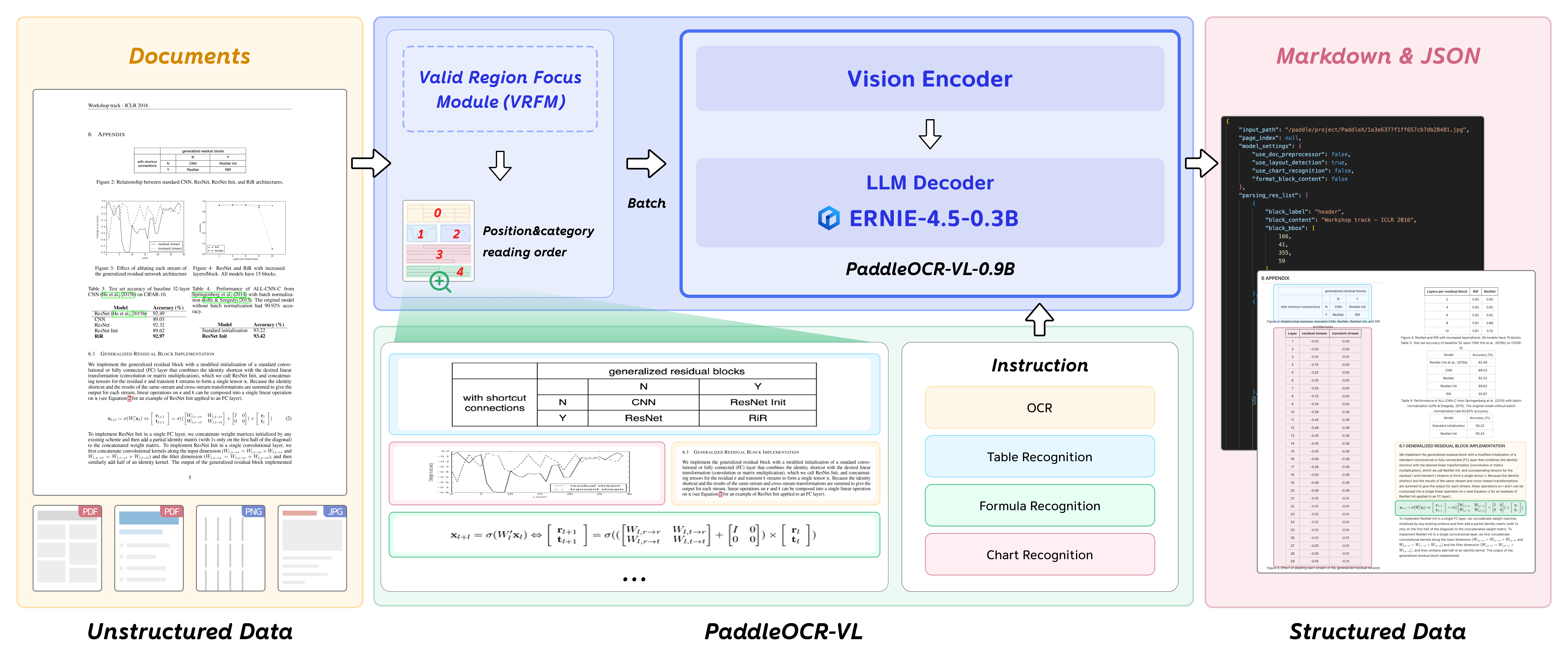
Figure 2: PaddleOCR-VL overview: VRFM extracts regions and predicts reading order; PaddleOCR-VL-0.9B performs precise recognition; outputs are merged into a structured document.
VRFM Design and Role
VRFM performs efficient layout analysis, leveraging region-level features for both spatial localization and relational order prediction.
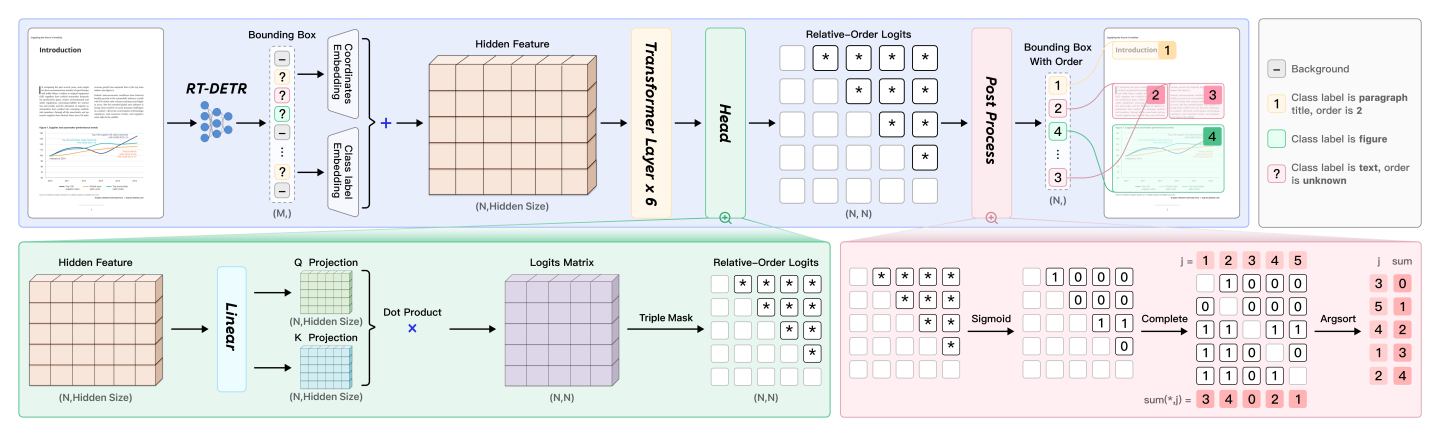
Figure 3: VRFM architecture employing RT-DETR with pointer network for region detection and reading order modeling.
Element Recognition Module
PaddleOCR-VL-0.9B is built on a NaViT-style vision encoder, initialized from Keye-VL, and employs ERNIE-4.5-0.3B with 3D Rotary Positional Encoding (RoPE) for language modeling. This configuration achieves low latency and high accuracy across 109 languages, with explicit support for text, table, formula, and chart recognition.
Data Pipeline and Training
The authors establish a multi-pronged data curation and synthesis pipeline, addressing distributional coverage, annotation noise, and long-tail cases. Over 30M training samples are amassed from open-source, synthesized, web-crawled, and in-house sources; annotation refinement employs expert models and advanced VLMs, with systematic hallucination filtering. Hard cases are actively mined and synthetically generated for underrepresented and difficult content.
Relevant data construction techniques per modality are illustrated:

Figure 4: Multistage pipeline for text data—automatic annotation, synthesis, and hierarchical granularity.

Figure 5: Table data—automatic annotation, mining from public sources, synthesis with randomization.
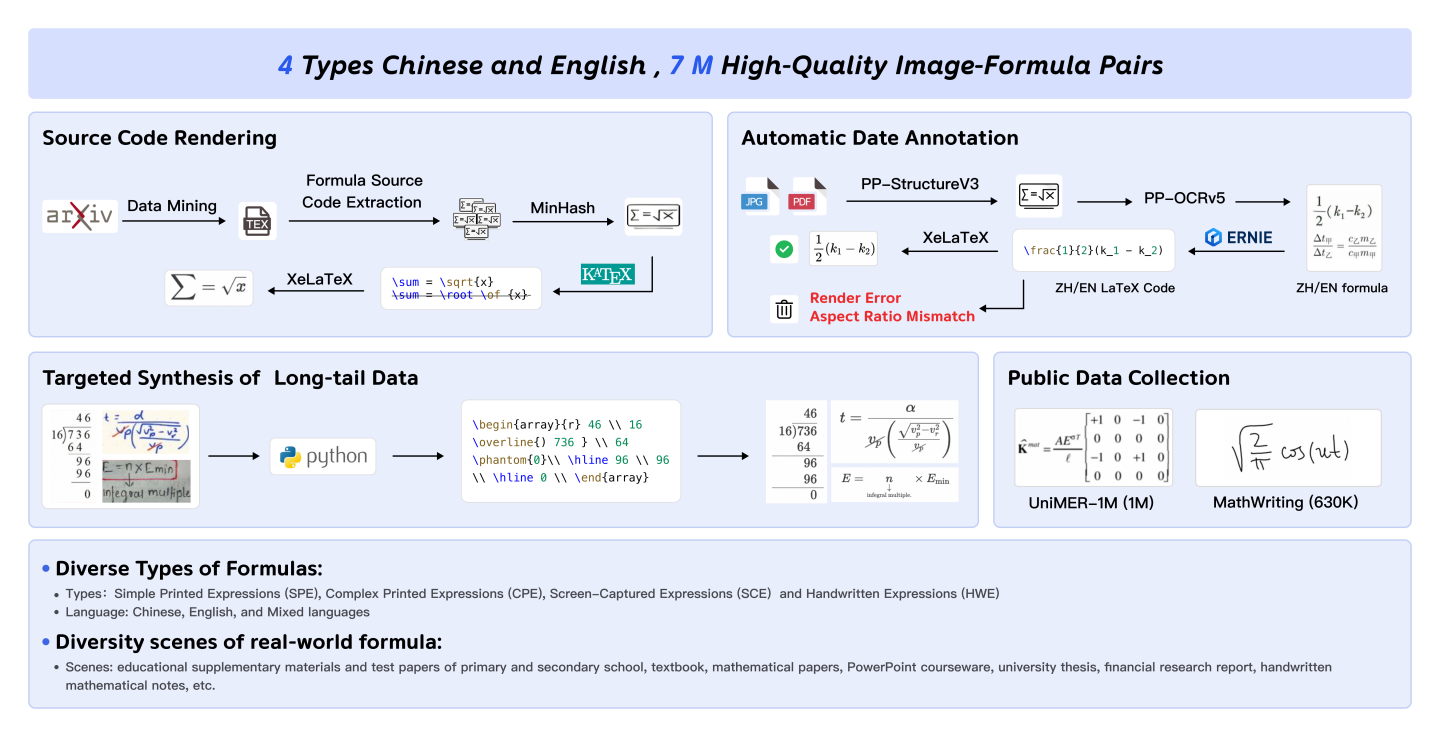
Figure 6: Formula data—source code rendering, automatic annotation, targeted synthesis, public collection.
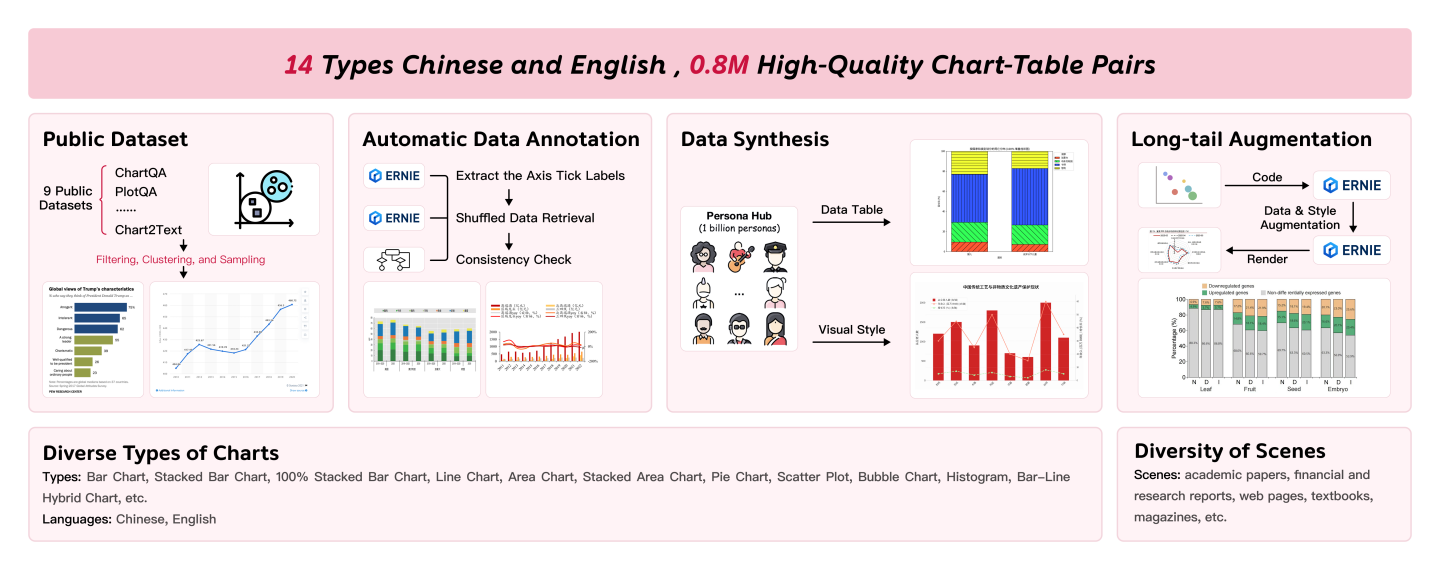
Figure 7: Chart data—public collection, automatic annotation, persona-based synthesis, long-tail augmentation.
The hierarchical decoupling in training—separate optimization for VRFM and PaddleOCR-VL-0.9B—facilitates specialization and improved generalization in both layout analysis and element recognition tasks.
Benchmark Comparisons
On OmniDocBench v1.5 and corresponding element-level block benchmarks, PaddleOCR-VL achieves state-of-the-art (SOTA) results across all key metrics:
- Overall Score: PaddleOCR-VL-L attains an overall score of 92.62, outperforming MinerU2.5 (90.67) and dots.ocr (88.41).
- Vision Tokens: SOTA performance is achieved with significantly fewer tokens (2561 vs. 3256 for MinerU2.5).
- Subtask Metrics: Record lowest Text-Edit distance (0.035), highest Formula-CDM (90.90), best Table-TEDS (90.48) and Table-TEDS-S (94.19), and superior reading order accuracy (0.043).
Contradictory and Strong Numerical Claims:
- Uniform visual token compression degrades layout accuracy in prior work, whereas targeted coarse-to-fine reduction improves both efficiency and recognition quality.
- PaddleOCR-VL achieves >6 point gain in overall metric versus DeepSeek-OCR with comparable token budget.
Inference Efficiency
PaddleOCR-VL demonstrates superior throughput and latency under high-resolution batch processing. It yields a 53% improvement in page throughput and 50% improvement in token throughput relative to MinerU2.5, while substantially reducing VRAM usage.
Qualitative Analysis and Visualization
PaddleOCR-VL is extensively validated across diverse document types, languages, and recognition scenarios:
- Markdown output generation for academic papers, reports, textbooks, notes, certificates, and historical documents confirms its robust layout and reading order handling.
- Multilingual outputs span Latin, Cyrillic, Devanagari, Arabic, and Asian scripts.
- Challenging cases—handwriting, vertical text, complex tables, formulas, and charts—are successfully parsed, revealing strong generalization.

Figure 8: Structured parsing and markdown output for books, textbooks, and academic papers.

Figure 9: Markdown conversion for reports, slides, and exam papers, including chart recognition.

Figure 10: Handling diverse document formats—notes, vertical books, ancient texts.

Figure 11: Parsing heterogeneous content—certificates, newspapers, and magazines.

Figure 12: Robust layout detection across document classes.
Figure 13: Accurate reading order prediction in complex layouts.
Implications and Future Directions
By explicitly modeling and eliminating visual redundancy, the coarse-to-fine paradigm enables high-fidelity document parsing in large-scale, multimodal AI systems while controlling computational overhead. The approach establishes the practical feasibility of deploying VLMs for real-world document intelligence tasks (e.g., training corpora construction for LLMs, retrieval-augmented generation, batch OCR processing).
The decoupled architecture signals a shift from monolithic, end-to-end multimodal pipelines—prone to error accumulation and inefficiency—towards modular systems with specialized layout and recognition submodules. This naturally invites further research on adaptive region extraction, hierarchical multimodal representation learning, and efficient token management for long-form and structurally heterogeneous inputs.
Future developments may focus on:
- Integration with continuous learning and reinforcement protocols for adaptive layout detection.
- Expansion to domain-specific document modalities (e.g., medical, legal, financial).
- Enhanced robustness to adversarial cases and further reduction of computational footprint via hardware-adaptive token strategies.
Conclusion
The paper introduces PaddleOCR-VL, a coarse-to-fine architecture that synchronizes efficient visual region selection and compact element recognition for document parsing. Empirical results demonstrate SOTA performance in both accuracy and throughput, with significant reductions in token and parameter budgets. The modular, hierarchical design and systematic data pipeline establish robust foundations for scalable, multilingual document intelligence. Practical and theoretical implications suggest future research directions in modular multimodal AI, adaptive inference, and document-based information extraction (2603.24326).