- The paper introduces a unified autoregressive transformer that processes a single token sequence of image patches, text, and task tokens for early multimodal fusion.
- It employs a Chain-of-Perception with Fourier-based encoding to precisely predict spatial coordinates, sizes, and segmentation masks in dense scenes.
- The architecture achieves state-of-the-art performance on dense vision-language benchmarks and enhances OCR accuracy with efficient scaling and robust training.
Motivation and Architectural Innovations
Traditional dense grounding and open-vocabulary segmentation systems employ modular encoder-decoder architectures with separate vision backbones and task-specific decoders, motivated by the need to disentangle visual feature extraction from task prediction. This separation fosters complexity—task-specific fusion blocks, query matching, post-processing—but impedes scaling and early cross-modal fusion. Falcon Perception fundamentally revisits this paradigm: it proposes a single dense autoregressive transformer that processes a unified token sequence of image patches, text, and task-specific tokens with hybrid attention masking (bidirectional for vision, causal for text/task tokens). This design enables early fusion across modalities, avoids late fusion bottlenecks, and supports variable-length autoregressive instance generation leveraging lightweight specialized heads for continuous spatial outputs.
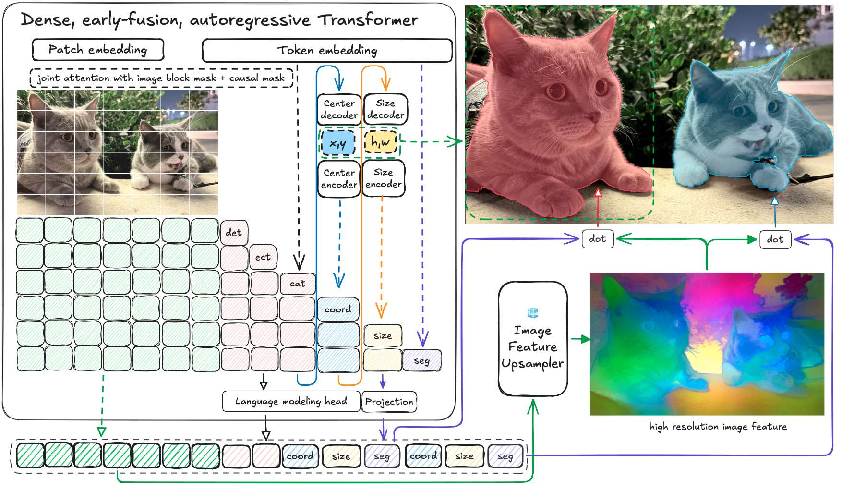
Figure 1: Falcon Perception Architecture: unified token stream, autoregressive prediction of instance properties, Fourier embedding for spatial tokens, and parallel mask generation via dot-product and upsampling.
A notable architectural choice is the "Chain-of-Perception": object prediction proceeds in a fixed sequence (<coord> → <size> → <segm>), forcing explicit spatial localization conditioning before mask generation. Coordinates and sizes are encoded and decoded via Fourier features to circumvent spectral bias, facilitating precise spatial grounding. Segmentation masks are generated via dot product between the <segm> token and image features, upsampled at high resolution through content-aware mechanisms, obviating the need for complex Hungarian matching or point-based mask queries.
Perception Benchmark and Capability Profiling
Existing referring segmentation benchmarks (RefCOCO/+/G-Ref) exhibit performance saturation and lack sufficient semantic granularity to disentangle failure modes. Falcon Perception introduces PBench, a hierarchical evaluation benchmark systematically organizing samples across five complexity levels:
- Level 0: generic object class recognition
- Level 1: fine-grained attribute/subtype binding
- Level 2: OCR-driven identification
- Level 3: spatial/layout grounding
- Level 4: relational/interaction reasoning
Each level isolates a dominant capability with prompts constructed to avoid cross-level cues, enabling rigorous capability profiling. Additionally, PBench includes a "Dense" split stressing long-context autoregressive generation in crowded scenes, evaluating stability across variable instance counts up to K∼600.
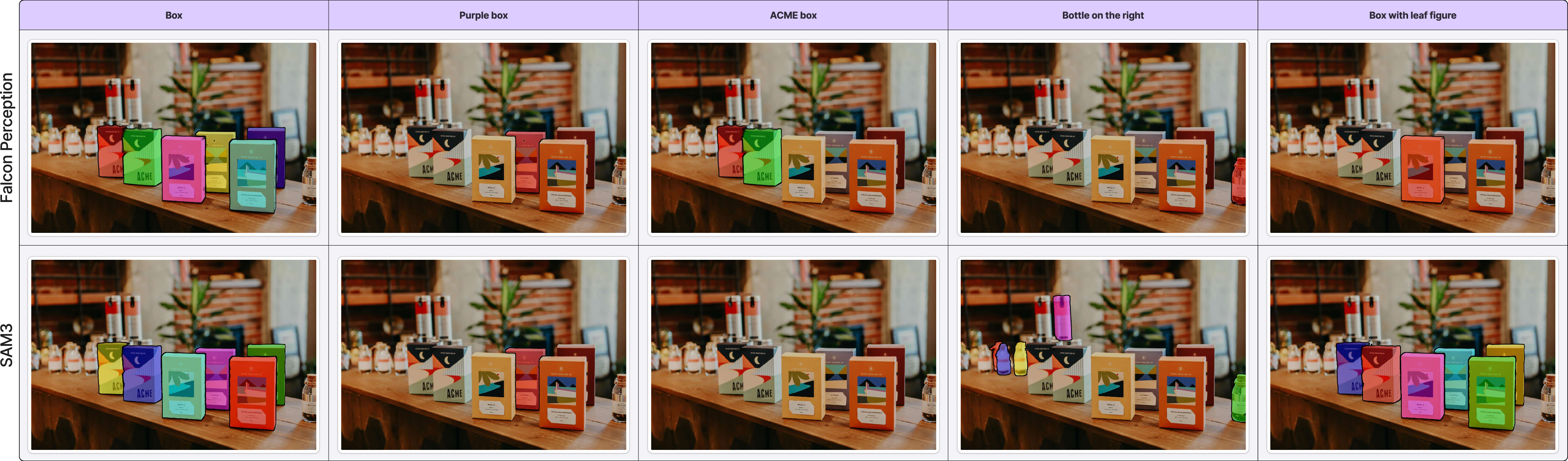
Figure 2: Prompt progression isolating compositional capabilities across PBench levels from generic to relational.
Training Pipeline and Data Curation
Falcon Perception training proceeds in two phases. Multi-teacher distillation initializes the backbone from DINOv3 (local vision features) and SigLIP2 (open-vocab language alignment), yielding robust spatial representations effective for downstream dense prediction. Perception training then fine-tunes the chain-of-perception sequence objective (<coord><size><seg>) across a massive, highly curated dataset of 54M images with structured positive/negative expressions and 570M masks. Data annotation relies on clustering, VLM-assisted listing, negative mining, ensemble consensus (SAM3/Qwen3/Moondream*), and human verification for semantic granularity and reliability.
Specialized training recipes implement adaptive attention maskings for in-context listing and task alignment, explicit positive/negative balancing, raster ordering for instance sequences, and global loss normalization across ranks to mitigate statistical biases from variable image and instance counts.
Numerical Results and Analytical Findings
Open-vocabulary Segmentation and Crowdedness
Falcon Perception surpasses previous state-of-the-art on SA-Co for mask quality, achieving 68.0 Macro-F1 vs 62.3 for SAM 3, and demonstrating strong improvements on food, sports, and attribute subtasks. The presence calibration gap (Image-Level MCC) is architectural: while SAM3’s fixed-query decoder natively handles empty-class prediction, Falcon Perception’s autoregressive approach requires explicit negative modeling. Notably, with targeted sampling and GRPO-style RL post-training, Falcon Perception recovers a substantial MCC improvement.
Performance scaling with image resolution is pronounced on dense/crowded splits—a “phase transition” at 10242 shows 15× pmF1 improvement, confirming that spatial details are prerequisite for dense grounding (Figure 3).
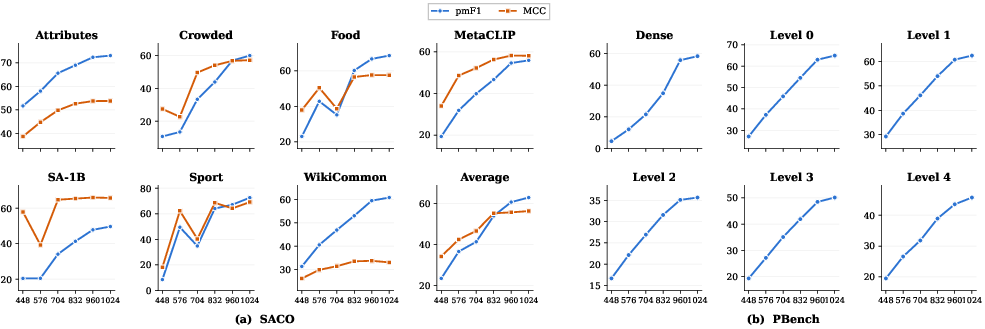
Figure 3: Resolution scaling: pmF1 and MCC in crowded tasks exhibit abrupt improvement with increased resolution.
Fixed high-resolution resizing further enhances crowded scene performance, outperforming adaptive resizing for small images (Figure 4).
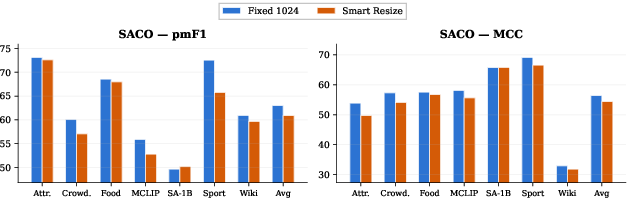
Figure 4: Fixed resizing strategy yields consistently higher performance, especially for crowded instances.
PBench Capability Analysis
Falcon Perception achieves major gains over SAM3 and larger VLMs in higher-complexity levels: +9.2 F1 on attributes, +13.4 on OCR-guided, +21.9 on spatial understanding (Level 3), and outperforms Qwen3-VL-30B in “Dense” crowded segmentation, despite being ∼15× smaller.

Figure 5: Qualitative comparison: Falcon Perception maintains compositional mask quality across complexity levels, outperforming modular late-fusion baselines.
Sampling and Maximum Likelihood Distribution
Autoregressive sampling uncovers latent capability: Pass@k increases performance in “hard” scenes, with cgF→0 scores jumping from 34.7 (baseline) to 54.3 (Pass@8), approaching SAM3’s best with only light RL/sampling tuning (Figure 6).

Figure 6: Deteministic vs sampled predictions: sampling enables recovery of rare and fine-grained instances otherwise missed by greedy decoding.
OCR Extension: FalconOCR
The Falcon Perception architecture is re-purposed for OCR tasks as FalconOCR, a compact 300M parameter stack trained from scratch for English document parsing, formula recognition, and HTML table serialization. The two-stage pipeline (PP-DocLayoutV3 + document element cropping) supports modular element-level OCR, and yields competitive accuracy on olmOCR (80.3%) and OmniDocBench (88.64), outperforming Gemini 3 Pro, DeepSeek OCR v2, and GPT 5.2, while rivaling much larger commercial systems (Figure 7, Figure 8, Figure 9, Figure 10).
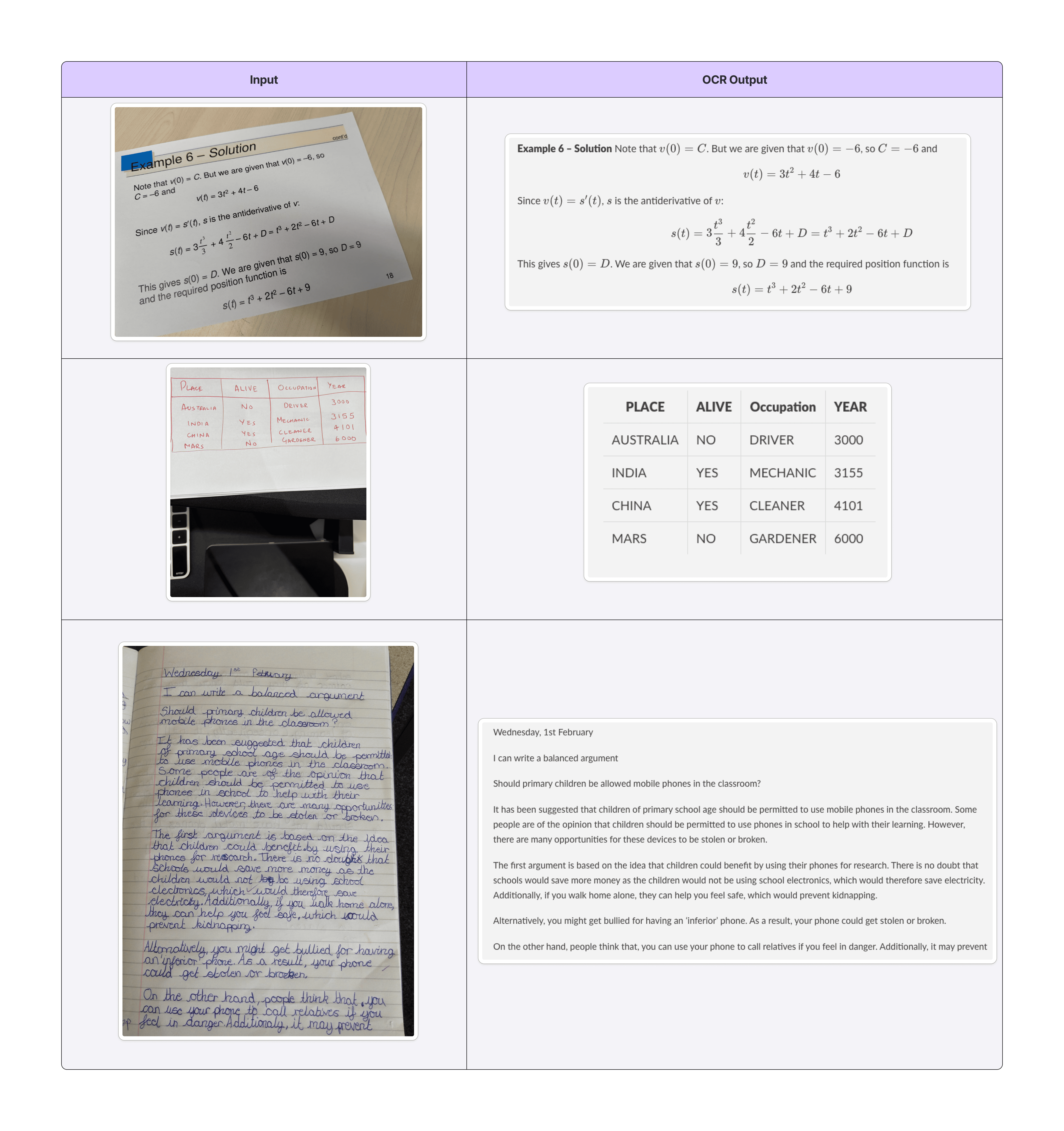
Figure 7: Example OCR output for formulas, tables, and handwriting across diverse document scans.
Theoretical and Practical Implications
Falcon Perception demonstrates that early fusion, unified token stream, and autoregressive generation are sufficient for dense grounding, spatial, OCR, and relational reasoning—late fusion and modular post-hoc interfaces are not strictly necessary. The architecture offers a clean scaling interface: context length, sampling, and sequential task tokens govern grounding complexity and dense output cardinality. RL-style post-training and sampling-based selection exploit multi-modal bimodal distributions to extract fine-grained or rare instances, mirroring “bitter lesson” trends in LLMs.
For practical deployment, FalconOCR achieves high efficiency (3000 tokens/sec) on commodity GPUs, making it feasible for large-scale document digitization with competitive accuracy.
Speculation and Future Directions
Further improvements are likely to stem from:
- Enhanced data mixtures: interleaved vision-language, text-only, and challenging compositional prompts.
- RL post-training for better calibration and candidate selection.
- Longer-context training for crowded scenes.
- Integration with risk-based objectives and sampling for multi-candidate evaluation and uncertainty quantification.
- Extension to multilingual and cross-domain dense grounding via architecture-agnostic scaling.
Conclusion
Falcon Perception establishes the viability of a unified early-fusion dense transformer for open-vocabulary segmentation, spatial grounding, compositional reasoning, and document OCR. The architecture’s simplicity and flexibility enable robust scaling and efficient inference, outperforming larger modular systems and providing strong compositional capacity across benchmarks. The future trajectory points toward data-centric improvements, RL-style post-training, and compositional task autoregression for dense multi-modal grounding and document understanding at scale.