- The paper introduces VISTA-Bench, a benchmark that evaluates vision-language models’ capability to understand visualized text compared to pure-text input.
- Using 1,500 curated samples, the study reveals significant accuracy drops—up to 40 points—due to challenges like small font sizes and rendering artifacts.
- The findings imply that advanced OCR integration and unified multimodal tokenization are crucial to bridge the modality gap in real-world applications.
Evaluating Vision-LLMs with VISTA-Bench: Modality Gaps in Visualized Text Understanding
Introduction
VISTA-Bench ("VISTA-Bench: Do Vision-LLMs Really Understand Visualized Text as Well as Pure Text?" (2602.04802)) introduces a systematic benchmark for evaluating vision-LLMs (VLMs) on their capacity to comprehend visualized text—text rendered as pixels within images—compared to pure-text input. While VLMs demonstrate impressive performance across pure-text queries, their real-world applicability hinges on robust processing of embedded textual cues commonly present in images. VISTA-Bench exposes a key limitation: a persistent and significant modality gap, wherein VLMs that excel at pure-text queries exhibit degraded performance on equivalent information presented as visualized text.
Figure 1: Humans naturally integrate text embedded in context, while standard VLM evaluation restricts language to discrete token streams; modality gaps arise when language is visually rendered.
Modality Gap and its Diagnosis
Extensive evaluation on over 20 VLMs reveals that models suffer substantial accuracy degradation when transitioning from pure-text input to their visualized-text counterparts. This modality gap is exacerbated by perceptual difficulty, such as small font sizes or atypical handwritten styles. Notably, even semantically identical questions yield lower accuracy when rendered as visualized text rather than discrete tokens. Models with strong OCR capabilities, e.g., Qwen3-VL-8B-Instruct, mitigate but do not eliminate the gap; models with weaker OCR, such as LLaVA-OneVision-7B, experience sharply reduced performance.

Figure 2: Comparative evaluation of VLMs on text versus visualized text input, illustrating consistent performance drops for the visualized modality.
Qualitative attention analysis confirms that rendering artifacts and perceptual complexity drive these failures: attention maps of models with disparate OCR abilities highlight that rendering-related errors dominate when content is pixel-based, regardless of pure-text reasoning proficiency.

Figure 3: Attention visualization for models with varying OCR robustness under different rendering configurations, revealing perceptual bottlenecks.
Benchmark Construction and Capability Taxonomy
VISTA-Bench consists of 1,500 rigorously curated samples, encompassing multimodal perception, multimodal reasoning, multimodal knowledge, and unimodal knowledge tasks. Each sample pairs pure-text and visualized-text queries, enabling direct comparison under controlled rendering protocols (e.g., anchoring font, DPI, layout). The benchmark stratifies abilities along inherent modality dependence (visual, textual) and cognitive dimensions (perception, reasoning, knowledge), further subdivided into fine-grained dimensions such as spatial reasoning, attribute perception, and cross-instance association.
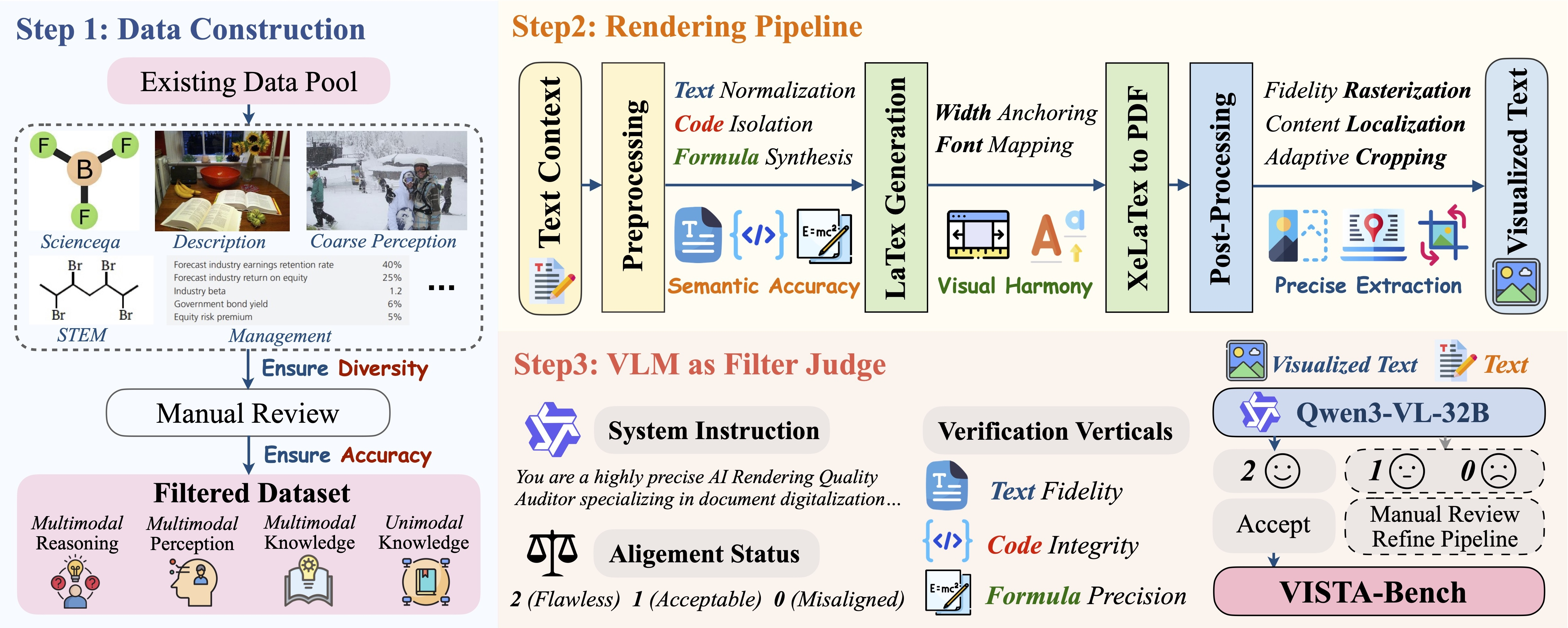
Figure 4: Benchmark construction pipeline involving data curation, high-fidelity rendering, and precision verification for visualized text.
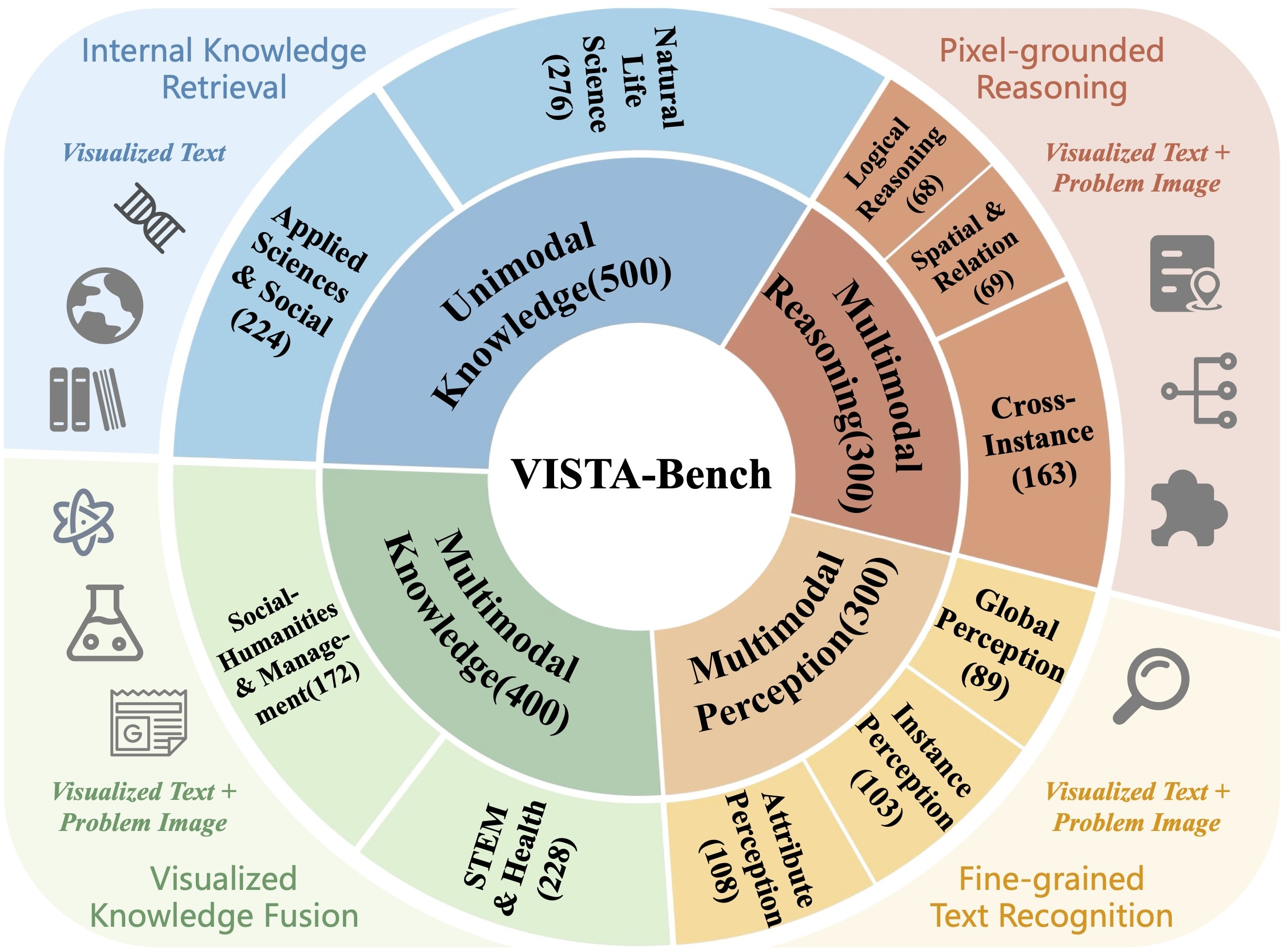
Figure 5: Taxonomy of ability dimensions in VISTA-Bench, distinguishing inherent modality factors and cognitive skills across 10 principal capabilities.
Rendering Sensitivity and Model Robustness
Experiments dissect how perceptual factors—font size, font style—impact model robustness. Small font sizes (e.g., 9pt) or handwritten fonts (Brush Script MT) lead to sharp accuracy drops, even for top-performing VLMs; clean, easily legible renderings attenuate the gap, occasionally producing parity or outperformance of visualized text over pure text. These effects are consistently observed across the model suite.
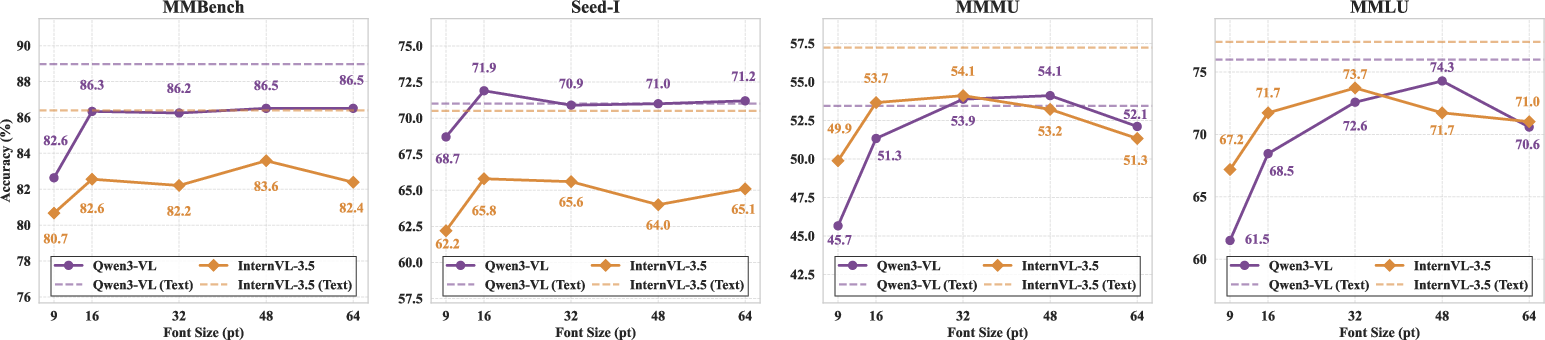
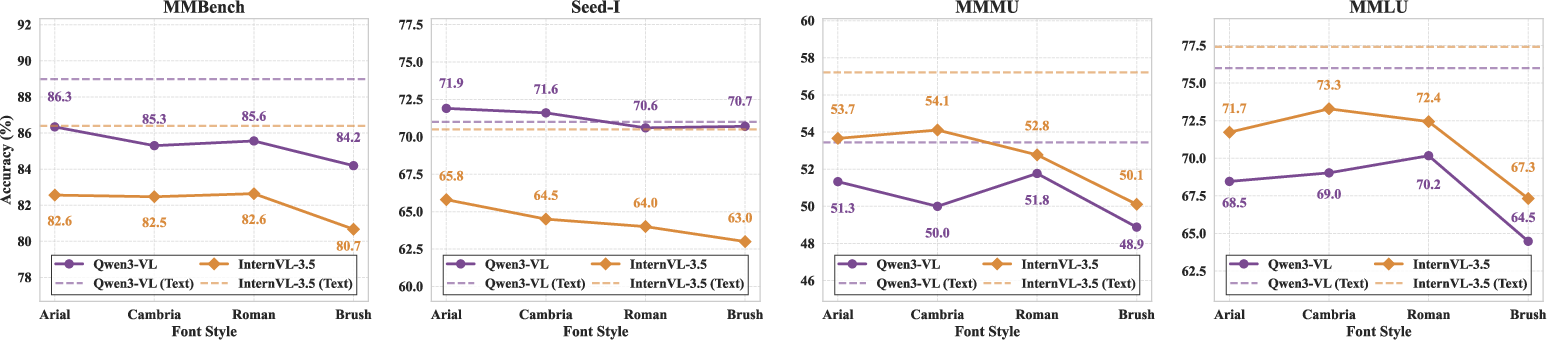
Figure 6: Performance variation as a function of font size and style; accuracy declines are pronounced in perceptually challenging settings.
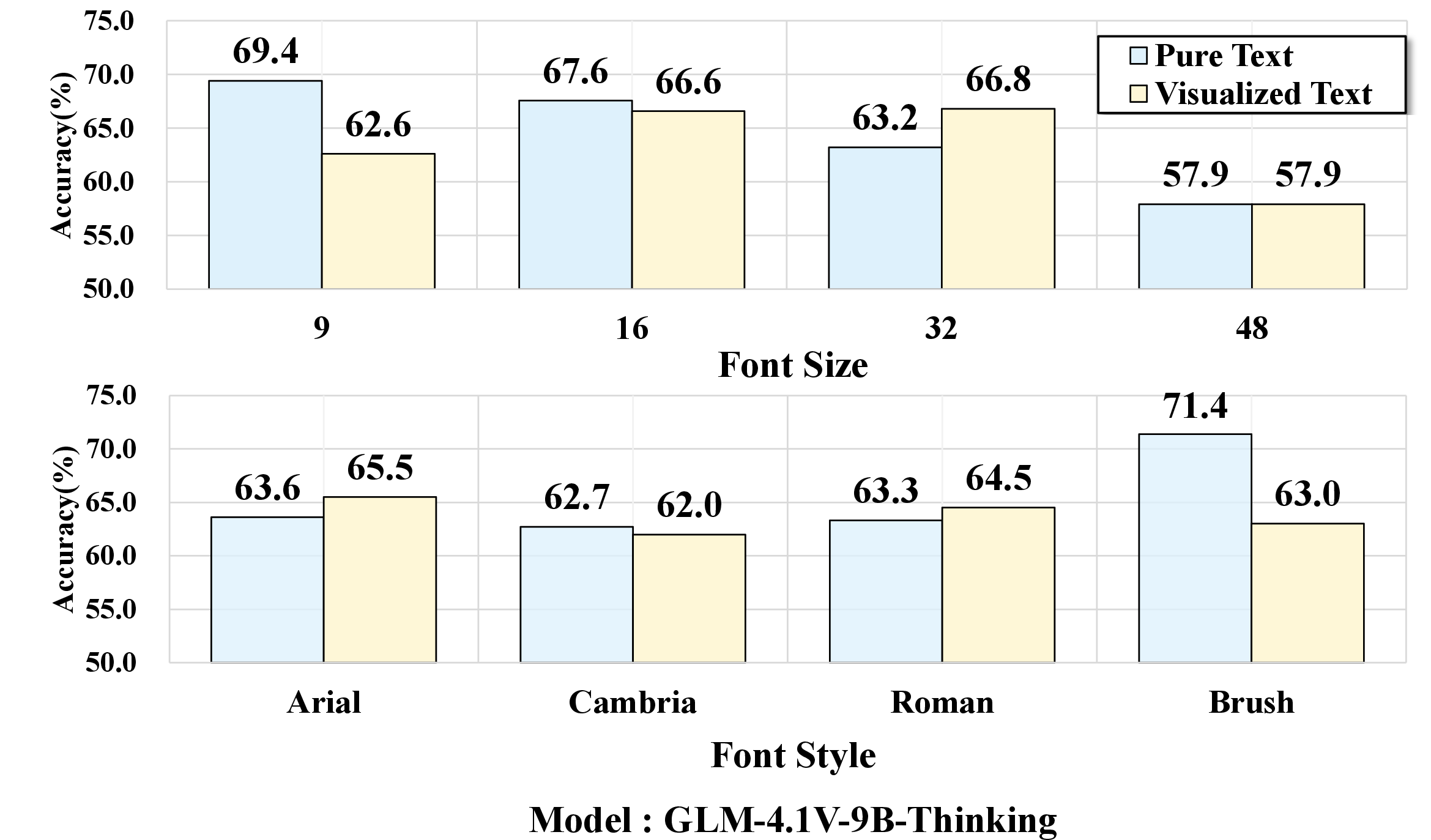
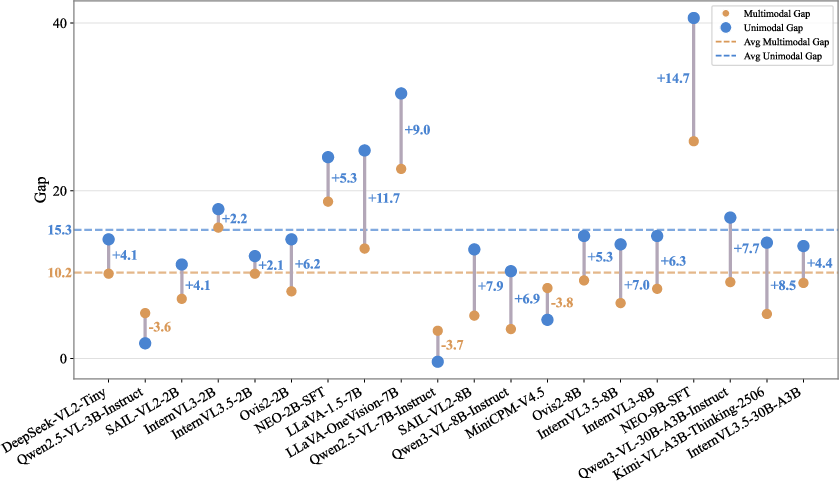
Figure 7: Sensitivity to rendering artifacts across benchmarking models, highlighting vulnerability to font and layout variation.
Prompt design also modulates accuracy: longer or instruction-rich prompts reduce the modality gap by guiding attention to salient content, while short or highly structured prompts may degrade answer quality, particularly for models sensitive to input nuances.
Evaluation Results and Cross-Task Trends
Across multimodal tasks, perception is relatively robust to visualized text, while reasoning and knowledge application are markedly impaired. Unimodal knowledge tasks—relying exclusively on pixel-based evidence—represent a stress test for OCR and text-perception capabilities, with accuracy gaps as large as 40 points for some models. Only a select set of models, e.g., GLM-4.1V-9B-Thinking and MiMo-VL-7B-SFT, approach parity, suggesting native OCR is not sufficient and further architectural adaptation or targeted training is required.
Multimodal context partially alleviates the modality gap, as the surrounding visual evidence helps ground interpretation and constrains plausible answers. However, perceptual errors remain the primary bottleneck, as revealed by gap analysis across multimodal and unimodal streams.
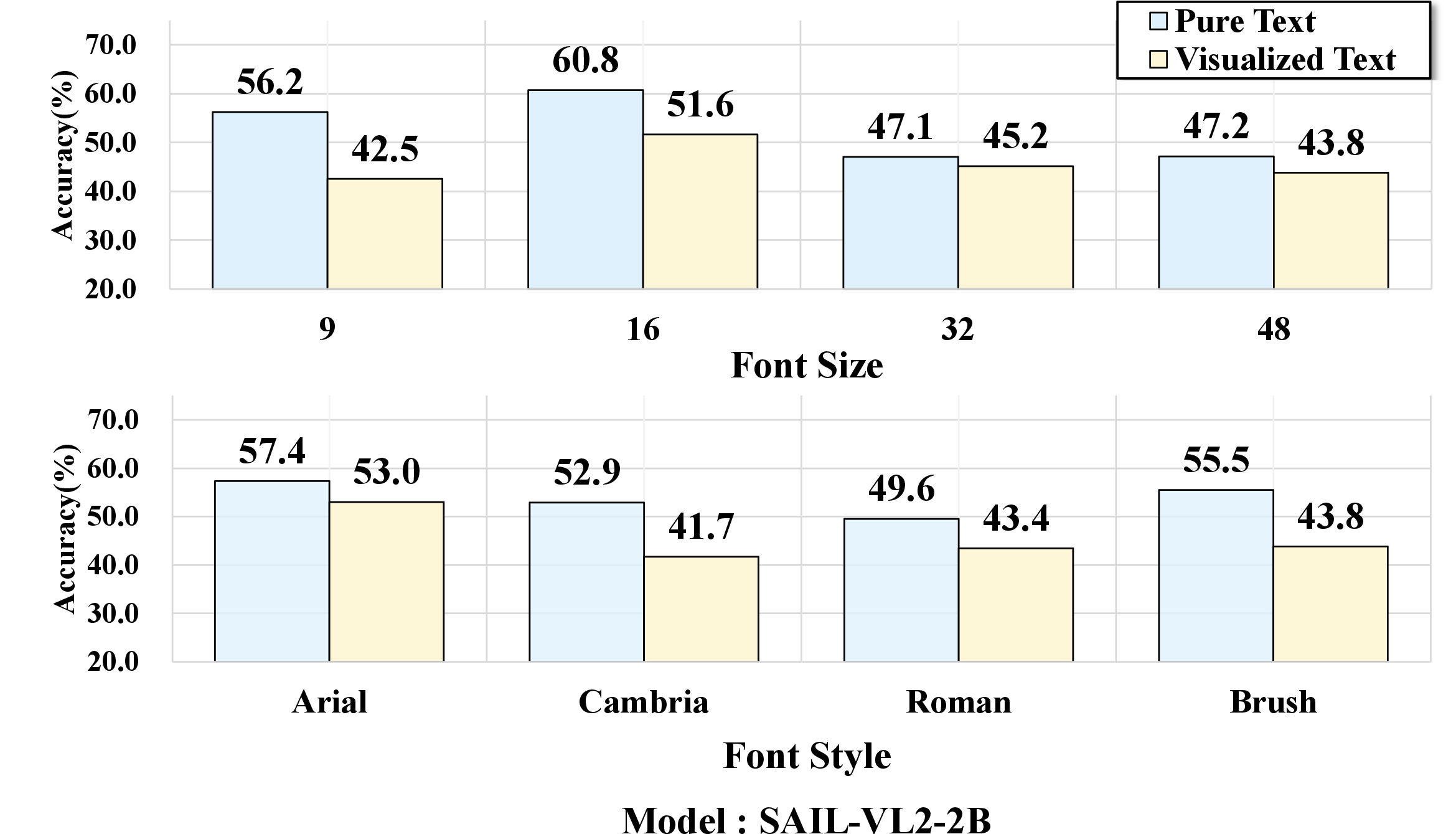
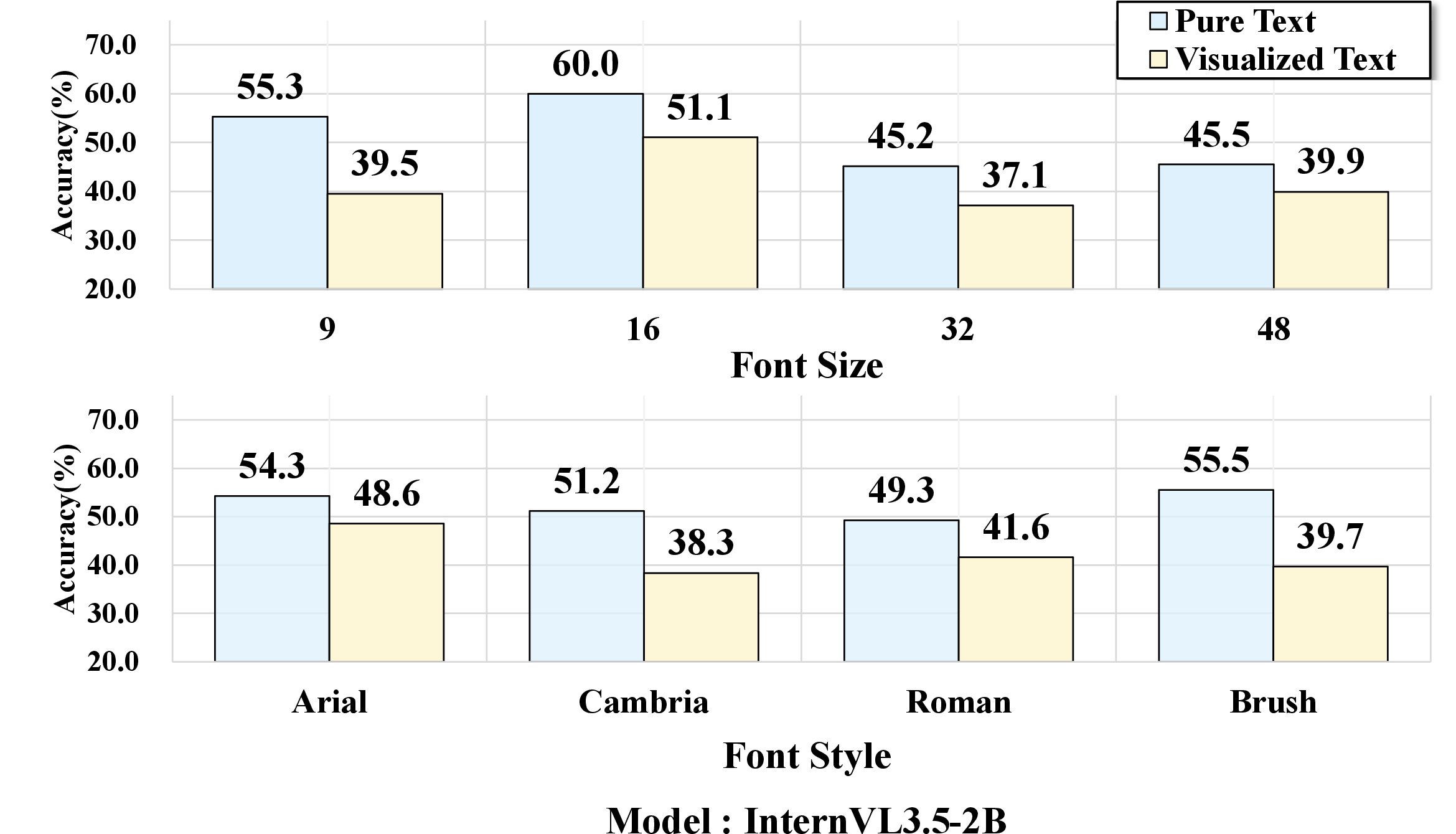
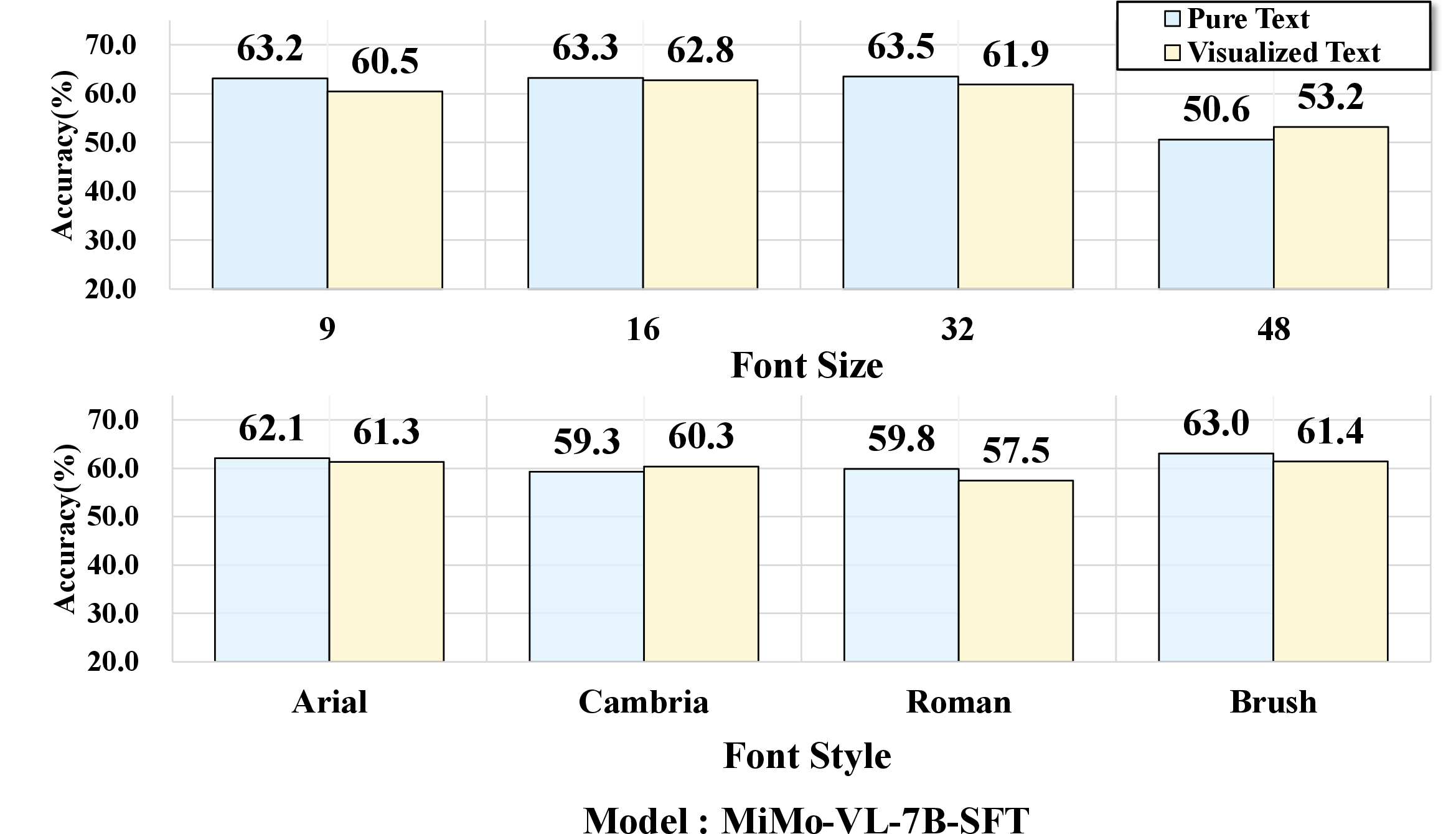
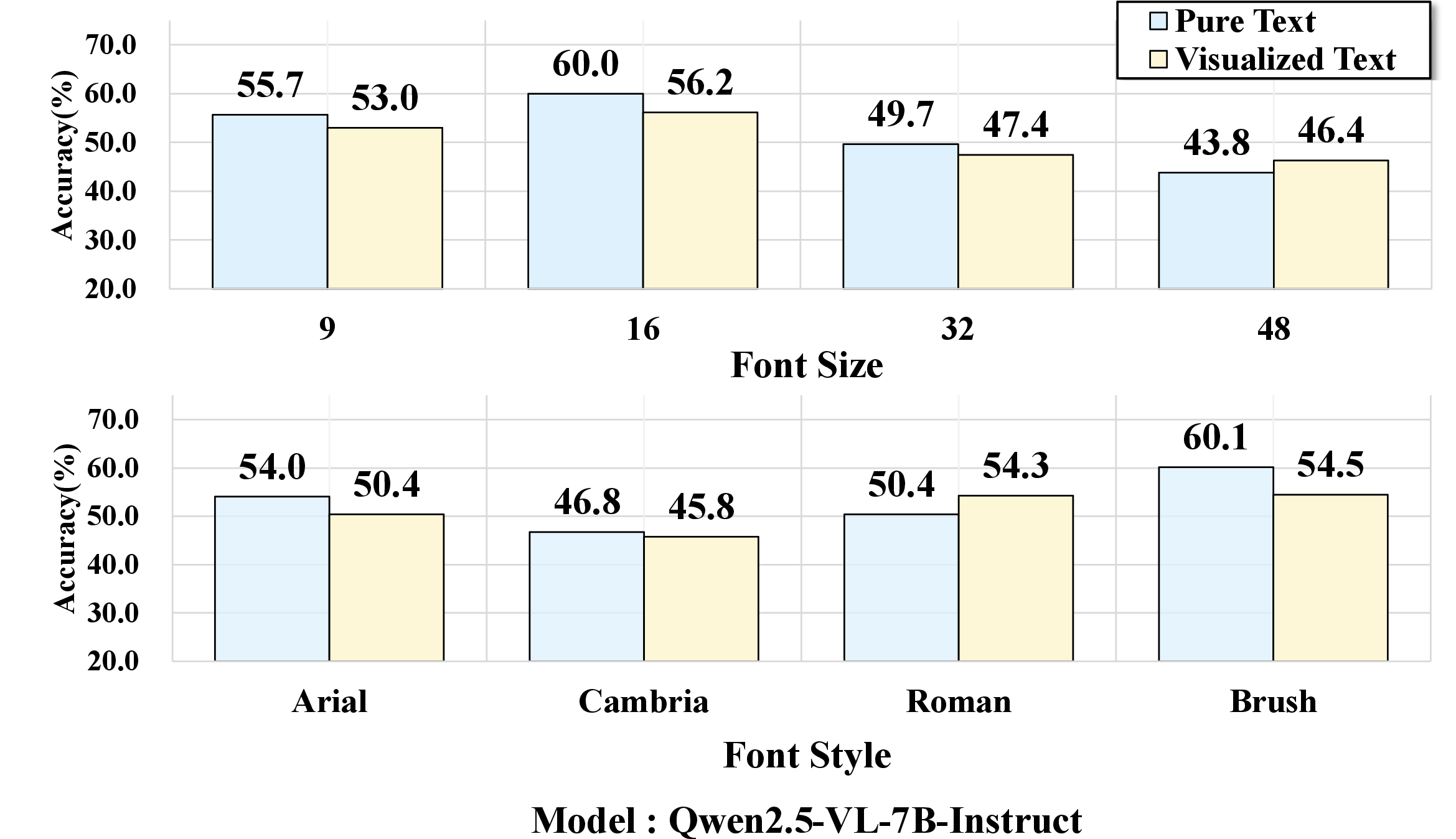
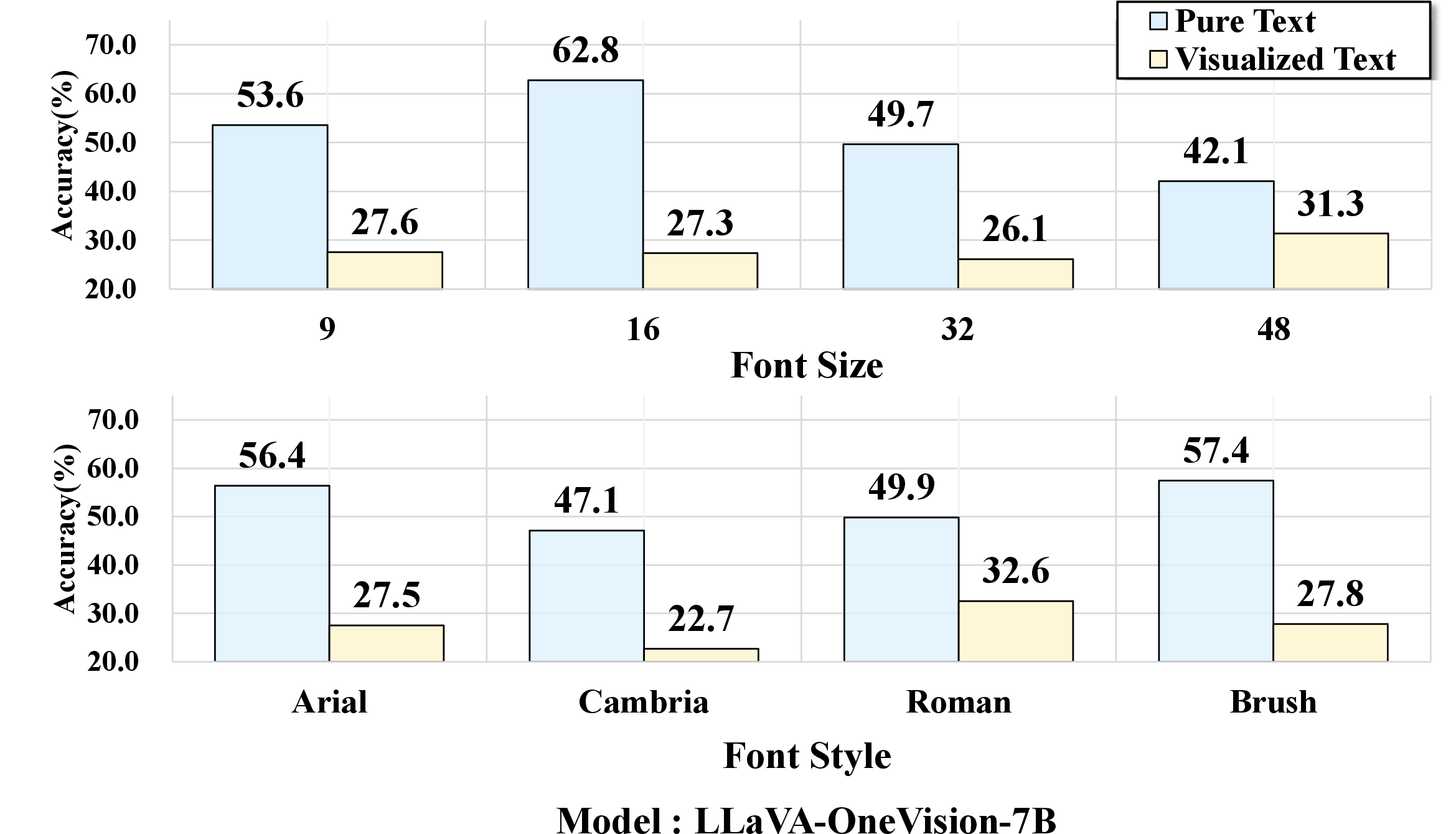
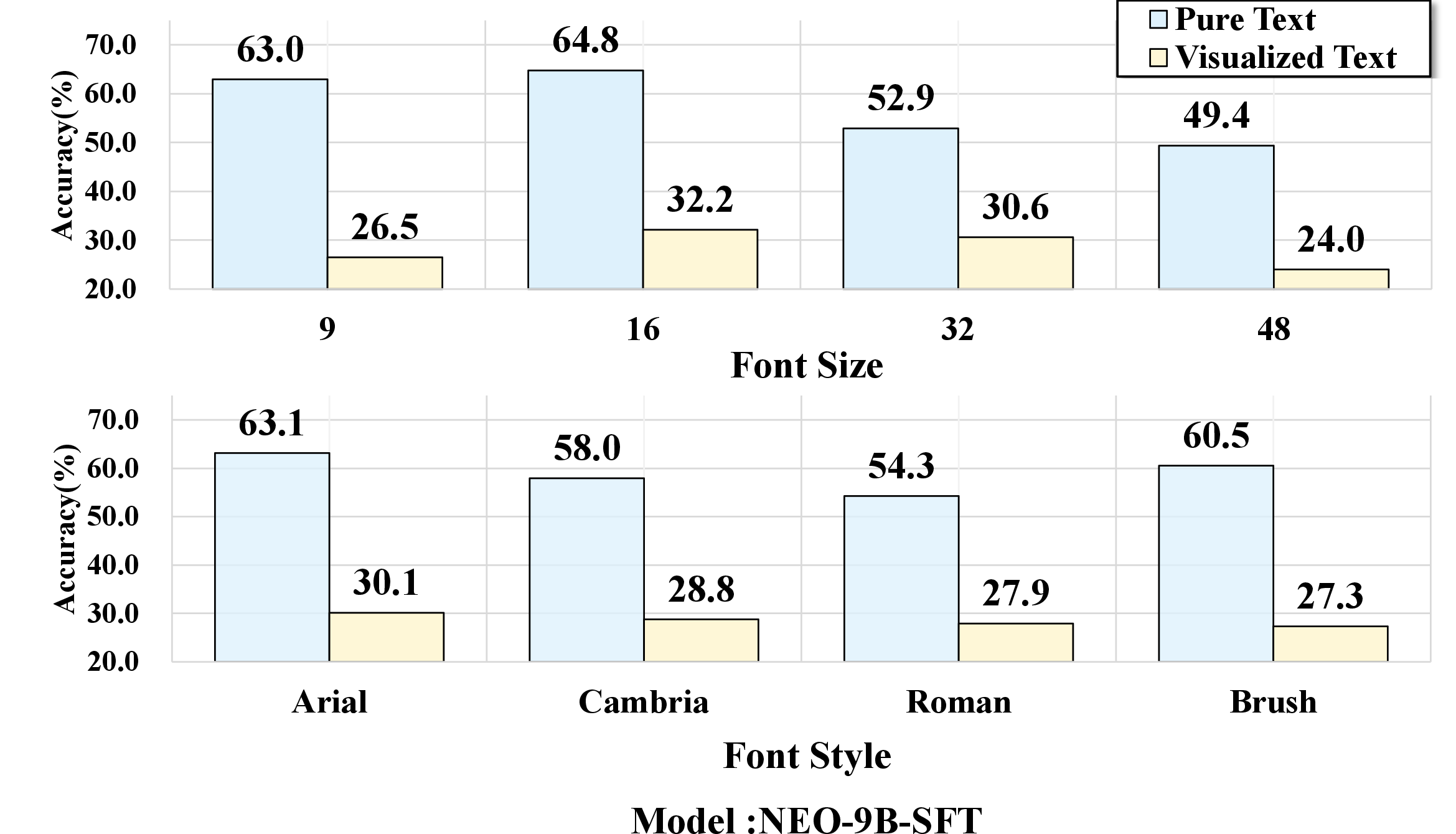
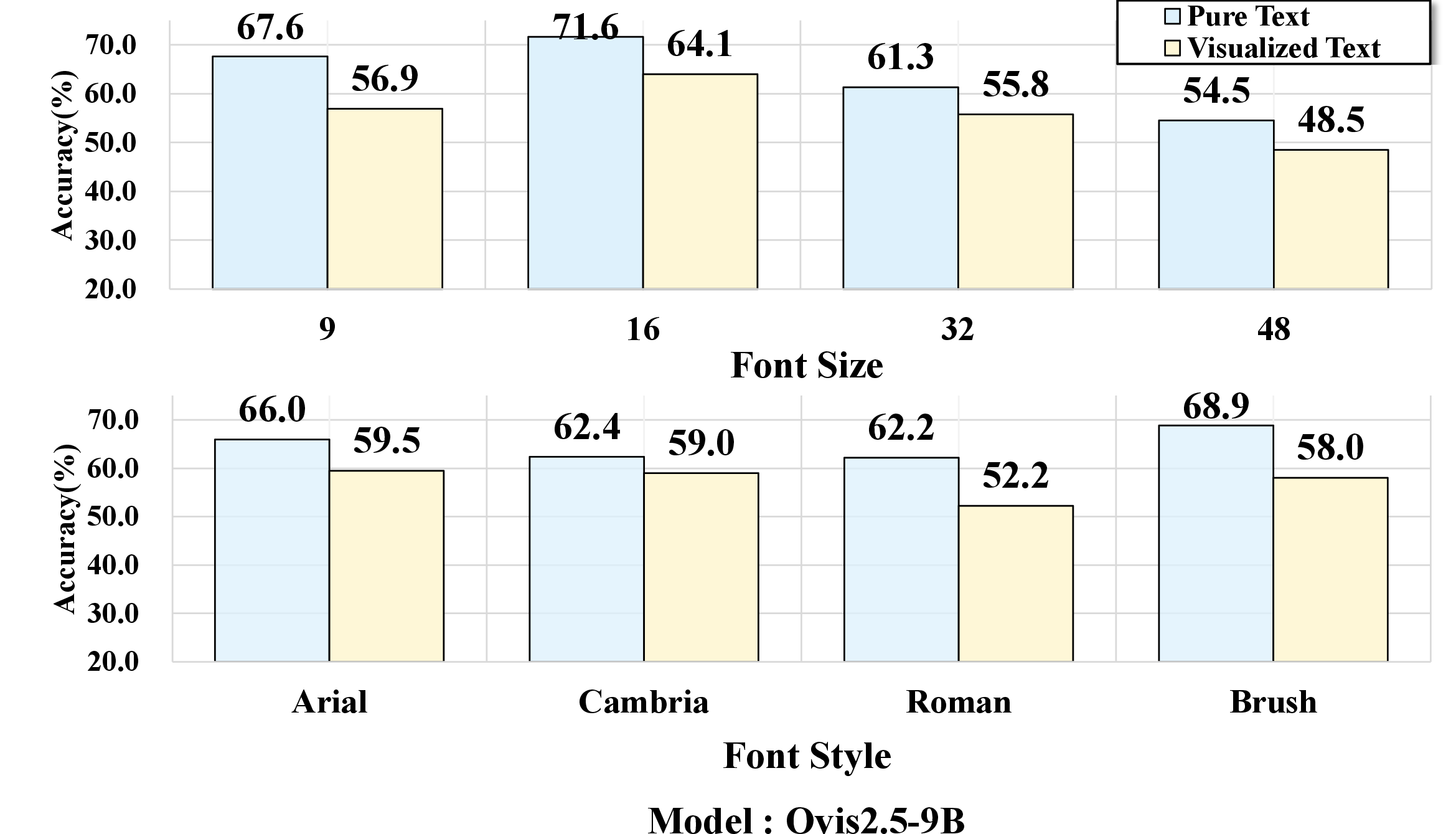
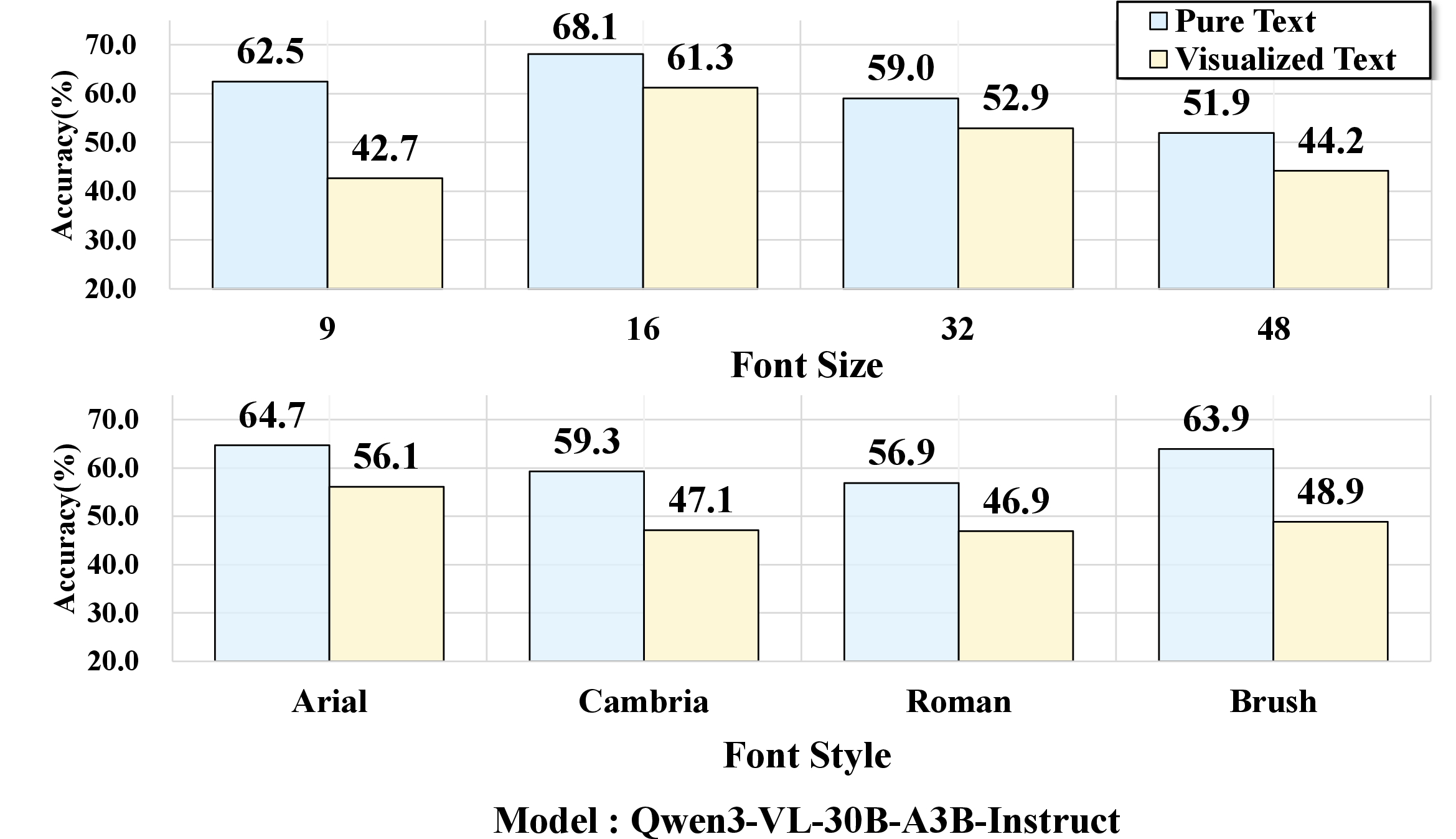
Figure 8: Rendering sensitivity study across eight representative VLMs, showing consistent trends in modality gap amplification.
Practical and Theoretical Implications
The empirical findings from VISTA-Bench highlight several foundational challenges for unified multimodal representation learning:
- Perceptual robustness: Robust OCR is necessary but insufficient; models must generalize across diverse renderings, font variations, and layout artifacts.
- Unified tokenization: Advancing toward architectures where language presented as pixels and as tokens are seamlessly integrated without performance loss is crucial for real-world deployment.
- Benchmark-driven development: The decoupling of question and context, and the provision of matched pure-text and visualized-text formats, enables granular diagnosis of visual grounding and modality transfer limitations.
The benchmark also motivates exploration of generative evaluation paradigms, where models must not only recognize but produce visualized text in context. Early experiments with Qwen-Image-Edit demonstrate that generation-based assessment is tightly coupled to underlying visualized-text understanding and layout control.

Figure 9: Example of successful answer generation in a visualized-text region by Qwen-Image-Edit; correctness hinges on robust layout production.
Future Directions
Advancing VLMs to overcome the modality gap entails both architectural and data-centric strategies:
- Integration of sophisticated perceptual modules capable of handling degraded, compressed, or noisy text rendering.
- Training on large-scale, diversified visualized-text data encompassing realistic document layouts, scientific formulas, and code artifacts.
- Design of unified multimodal tokenization protocols that minimize information loss when shifting between symbolic and pixel-based linguistic representations.
- Incorporation of cross-modal generative and discriminative paradigms for more thorough benchmarking.
Conclusion
VISTA-Bench establishes a principled, multi-domain evaluation suite for vision-LLMs under visualized-text conditions, revealing persistent modality gaps and sensitivity to rendering complexity. These findings underscore the necessity for perceptually robust architectures and unified representation learning able to bridge the divide between tokenized and pixel-based language. Moving forward, VISTA-Bench will serve as a foundational resource in advancing multimodal systems toward genuine real-world comprehension and integration across diverse linguistic modalities.