- The paper introduces a novel diffusion-based framework that employs symmetric contrastive learning and latent interpolation for continuous, disentangled facial expression editing.
- The paper presents the FFE dataset of 60,000 images and the FFE-Bench benchmark, enabling multi-dimensional evaluation of identity consistency and edit controllability.
- The paper demonstrates superior performance with significantly improved editing accuracy, reduced semantic confusion, and robust identity preservation against competing methods.
Fine-Grained Facial Expression Editing via PixelSmile
Introduction
PixelSmile addresses fundamental challenges in controllable facial expression editing, notably the underlying semantic entanglement between expression categories and the limitations imposed by discrete supervision. Existing diffusion-based and identity-consistent generation models, while highly capable in visual realism and overall editing, struggle with precise, fine-grained, and linearly-controllable manipulation—particularly when expression categories have intrinsic semantic overlap. PixelSmile introduces (1) the FFE dataset with continuous affective annotation, (2) the FFE-Bench benchmark for rigorous multi-dimensional evaluation, and (3) a diffusion-based framework leveraging symmetric contrastive learning and flow-matching-based latent interpolation for disentangled, identity-consistent expression editing.
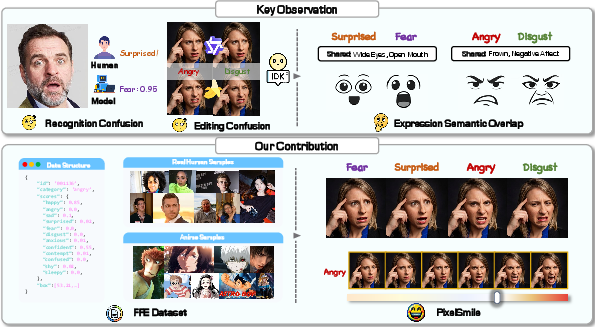
Figure 1: Inherent expression overlap causes systematic confusion for annotators, recognition, and generative models; PixelSmile resolves this via continuous supervision and symmetric training, shown schematically alongside the FFE dataset and framework.
A key insight from the analysis is that facial expressions constitute a continuous, overlapping manifold, rather than strictly separable categories. Human raters, classifiers, and generative models all suffer confusion (e.g., fear vs. surprise, anger vs. disgust), exacerbated by rigid, one-hot supervision and discrete-labeled datasets. To resolve structured confusion, PixelSmile introduces the FFE dataset: 60,000 curated images (real and anime) varying expression intensity for the same identity, annotated with 12-dimensional continuous score vectors via VLMs and validated with human oversight. This continuous annotation captures semantic overlap and enables systematic study of fine-grained editing and disentanglement.
FFE-Bench, built atop FFE, introduces precise metrics:
- Mean Structural Confusion Rate (mSCR): Quantifies confusion between overlapping pairs.
- Harmonic Editing Score (HES): Fuses expression score with identity similarity, requiring both for a high score.
- Control Linearity Score (CLS): Evaluates whether expression intensity follows a linear response to editing coefficients.
- Editing Accuracy: Measures top-1 expression correctness.
These metrics specifically address the limitations of legacy benchmarks that could not measure either controllability or disentanglement adequately.
The PixelSmile Framework
PixelSmile is a parameter-efficient framework built on a Multi-Modal Diffusion Transformer (MMDiT) with LoRA adaptation. It combines two crucial mechanisms:
- Latent Interpolation in Text Space: Linear interpolation occurs between "neutral" and target expression text embeddings. The interpolation coefficient α allows continuous scaling of expression intensity. Supervision (score matching) ensures visual intensity aligns with the chosen α, while extrapolations beyond α=1 are possible.
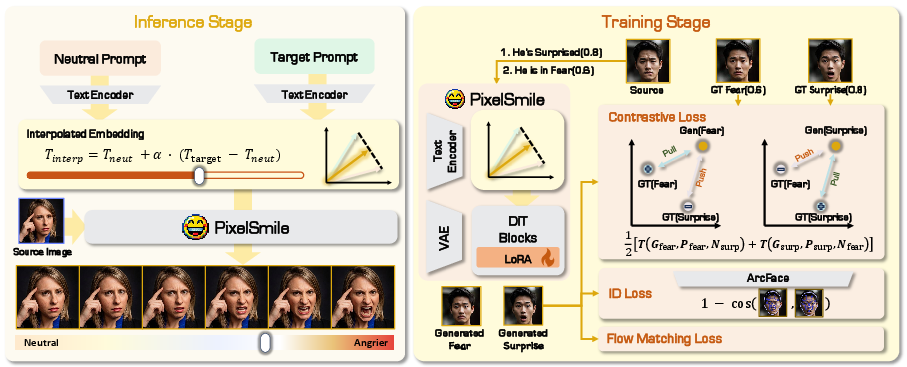
Figure 2: The method interpolates between neutral and target expression embeddings for continuous control and utilizes symmetric joint training to separate confusing pairs while preserving identity.
- Symmetric Joint Training: For each confusing category pair, symmetric contrastive objectives are employed—alternating which sample is the positive/negative in the triplet loss. This symmetric design reduces directional bias and directly separates entangled categories in the learned representation. An identity loss (ArcFace-based) regularizes the system against identity drift, especially at high intensities.
Quantitative results highlight PixelSmile's strong improvements in editing accuracy, disentanglement, and linear controllability, while maintaining identity consistency.
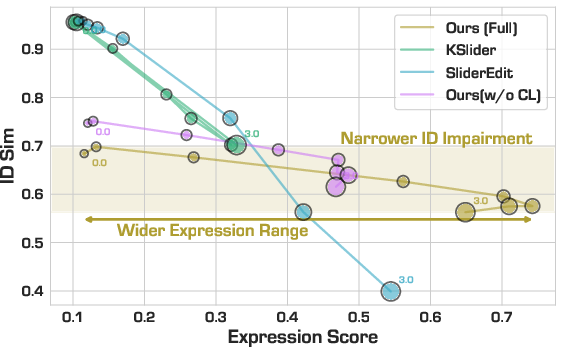
Figure 3: PixelSmile achieves a superior trade-off: wider range of expression manipulation at high identity fidelity compared to baselines.
Experimental Results
General Editing Comparison
On FFE-Bench, PixelSmile achieves the lowest mSCR (0.0550 vs. Nano Banana Pro 0.1754, GPT-Image 0.1107) and highest editing accuracy for basic expressions (0.8627). Competing models either preserve identity but weaken edit strength (e.g., Seedream, Qwen-Edit), or create visible change with identity drift (e.g., GPT-Image). Baselines with negative control linearity scores or rapid identity drop do not achieve meaningful controllability.

Figure 4: PixelSmile yields clearer, more discriminable expression edits than general-purpose systems, which degrade on strong or ambiguous edit instructions.
Linear Control Baselines
With respect to controllability, only PixelSmile achieves strong, monotonic expression editing across the entire intensity spectrum without sacrificing identity—CLS-6 of 0.8078 and HES of 0.4723 are best-in-class. Prior latent-slider methods either exhibit negligible expression modulation (to maintain identity) or cause sharp identity collapse at high intensities.

Figure 5: Smooth, monotonic expression control by PixelSmile, without unstable transitions or identity degradation, for both "happy" and "surprised".
Ablation Studies
Ablation demonstrates:
- Removal of identity loss drastically increases identity drift (altered hair, skin, etc.) at strong intensities.
- Removing contrastive loss or symmetric structure eliminates category disentanglement, reverting edits to the source identity or causing severe confusion.
- Alternative triplet losses (Hinge, Log-Ratio) trade off edit/identity: InfoNCE is optimal for balancing both.
- Replacing FFE with MEAD (discrete, less diverse) reduces all key metrics, establishing FFE’s importance for disentangled, controllable editing.

Figure 6: Without identity regularization, high-intensity edits alter persistent features; PixelSmile (full) preserves these reliably.
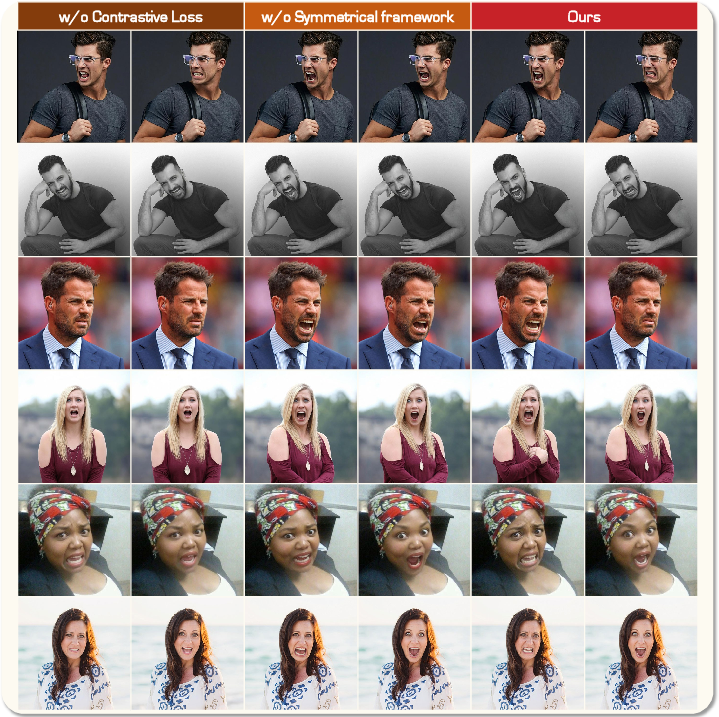
Figure 7: Without contrastive or symmetric loss, structural confusion persists—PixelSmile achieves distinct edits for overlapping classes.
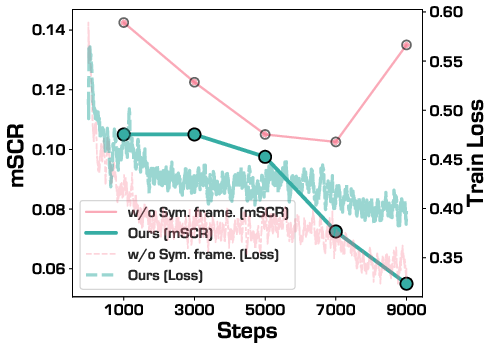
Figure 8: Symmetric training—though slightly slower to converge—consistently yields lower confusion rates (lower mSCR) than the asymmetric variant.
User Study and Expression Compositionality
User studies confirm machine metrics: PixelSmile is rated highest for edit continuity and, nearly as strongly, for identity preservation; competitors trade off one for the other.
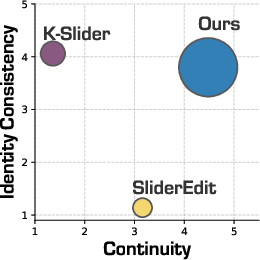
Figure 9: Human annotators rate PixelSmile highest for balancing smooth editability with identity retention.
Beyond single expressions, PixelSmile supports compositional editing—blending multiple basic emotions yields plausible compound expressions, with nine out of fifteen pairwise blends succeeding in perceptual tests.

Figure 10: PixelSmile supports smooth blending of multiple emotive categories, producing coherent compound expressions.
Implications and Future Directions
Practically, PixelSmile establishes a scalable, extensible pipeline for high-quality, linearly-controllable and disentangled facial editing, with robustness to domain (real, anime) and expression complexity. Theoretically, it validates symmetric contrastive learning and continuous affect space as foundations for further development, with impact for affective computing, personalized media synthesis, and fine-grained expression transfer.
Potential future developments include:
- Extension to video and 4D avatars (temporal/3D disentanglement)
- Multi-modal editing combining expression, age, and other attributes along continuous manifolds
- Integration with large, multimodal foundation models for joint vision-language understanding and closed-loop human feedback
- Real-time editing and adaptive user-in-the-loop systems for creative industries
Conclusion
PixelSmile, together with its FFE dataset and FFE-Bench protocol, provides a structured, data-centric, and methodologically rigorous platform for fine-grained, compositional facial expression editing. Symmetric supervision, flow-matching latent control, and continuous annotation jointly eliminate longstanding obstacles of semantic confusion and nonlinear or identity-destroying edits. This research establishes new trajectories for affective modeling and high-precision visual editing under both research and applied contexts.