- The paper presents a two-stage training method using latent perturbation and post-training decoder alignment to robustify image tokenizers for generative tasks.
- It introduces the novel pFID metric, which correlates more strongly with generative performance than traditional reconstruction metrics.
- Empirical results show that RobusTok improves structural consistency, color fidelity, and generative FID across autoregressive and diffusion models.
Robust Image Tokenization via Post-Training: An Analysis of "Image Tokenizer Needs Post-Training" (2509.12474)
Introduction
The paper "Image Tokenizer Needs Post-Training" addresses a critical and underexplored issue in the design and deployment of image tokenizers for generative models: the distributional discrepancy between reconstruction and generation tasks. While most prior work has focused on optimizing tokenizers for reconstruction fidelity, this work demonstrates that such tokenizers often underperform in generative settings due to their lack of robustness to out-of-distribution (OOD) latent tokens encountered during sampling. The authors introduce RobusTok, a two-stage tokenizer training scheme that explicitly targets this robustness gap, and propose a novel evaluation metric (pFID) that better correlates with generative performance than traditional reconstruction metrics.
Discrepancy Between Reconstruction and Generation
The core insight is that the latent token distributions encountered during reconstruction (i.e., autoencoding) and generation (i.e., autoregressive or diffusion-based sampling) are fundamentally different. During reconstruction, the decoder always receives ground-truth tokens, whereas during generation, it must decode from tokens sampled by the generator, which are often OOD relative to the training distribution. This mismatch leads to degraded generative quality, even for tokenizers with high reconstruction fidelity.
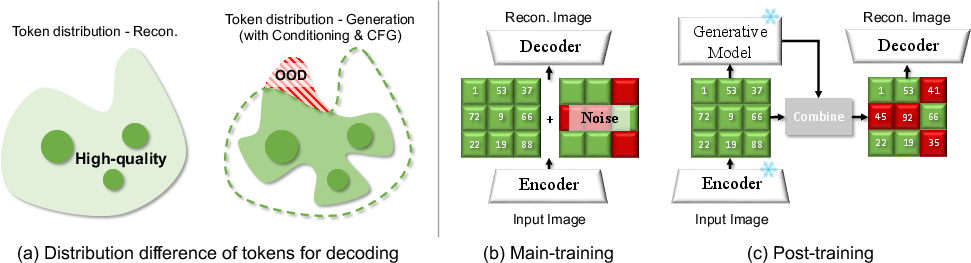
Figure 1: Discrepancy between reconstruction and generation tasks imposes a latent token distribution difference; RobusTok addresses this via latent perturbation during main-training and alignment in post-training.
RobusTok: Two-Stage Training for Robust Tokenization
Main-Training: Latent Perturbation
RobusTok's main-training phase introduces a plug-and-play latent perturbation strategy. By randomly replacing a proportion of latent tokens with their top-δ nearest neighbors in the codebook, the decoder is exposed to synthetic OOD tokens, simulating the errors encountered during generative sampling. This process is controlled by three hyperparameters:
- Perturbation rate (α): Fraction of tokens perturbed per image.
- Perturbation proportion (β): Fraction of images in a batch subjected to perturbation.
- Perturbation strength (δ): Number of nearest neighbors considered for replacement.
An annealing schedule is used to gradually reduce perturbation intensity, balancing robustness and reconstruction quality.
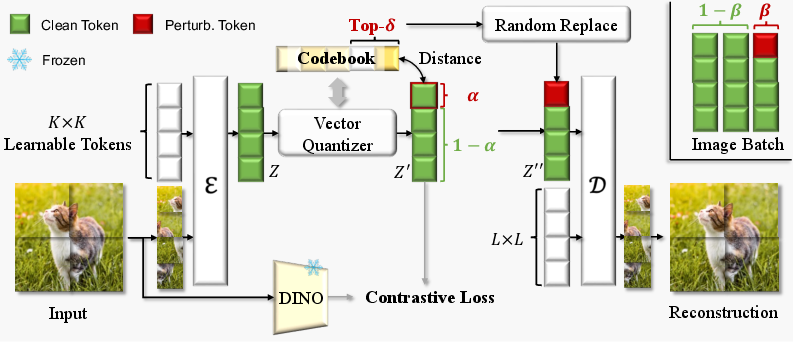
Figure 2: RobusTok overview: ViT-based encoder/decoder, latent perturbation, and DINO-based semantic supervision.

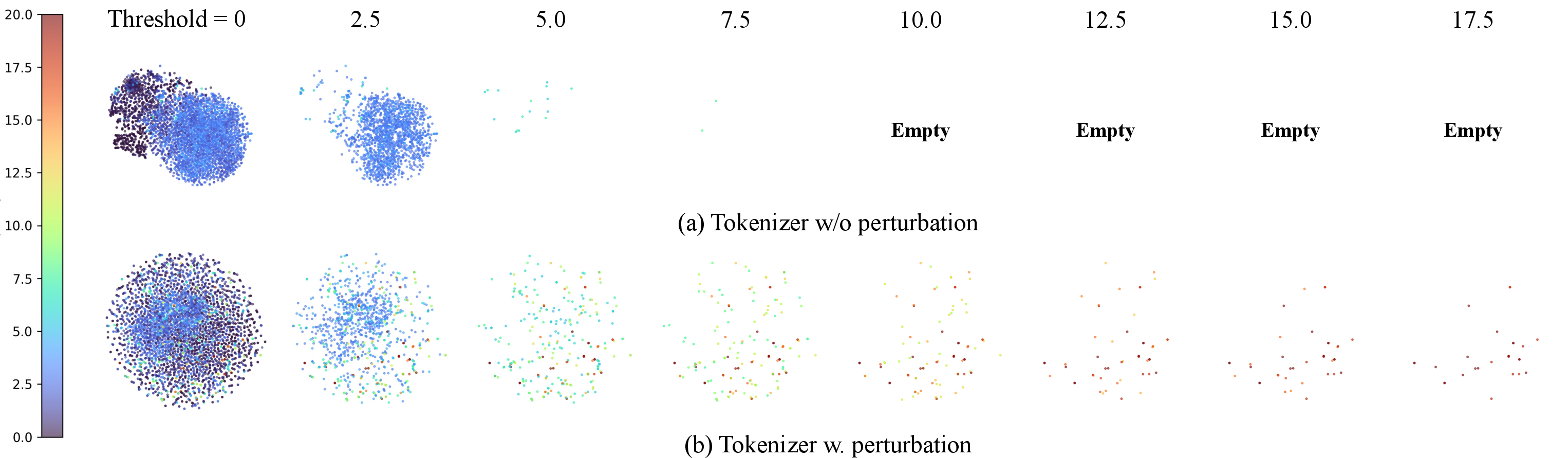
Figure 3: Visualization of reconstructions under perturbation: RobusTok maintains semantic fidelity, unlike traditional tokenizers.
Post-Training: Decoder Alignment
Despite improved robustness, a residual gap remains between synthetic perturbations and real generator-induced errors. The post-training phase addresses this by freezing the encoder and quantizer, and fine-tuning the decoder on latents produced by a well-trained generator. The preservation ratio (σ) interpolates between ground-truth and generated tokens, facilitating a smooth transition and effective supervision.

Figure 4: Generated images under varying σ for autoregressive (left) and diffusion (right) models, illustrating the effect of preservation ratio.
Evaluation Metrics: pFID and Its Correlation with Generative Quality
The authors introduce perturbed FID (pFID), which measures the FID between reconstructions from perturbed latents and the original images. Unlike reconstruction FID (rFID), pFID is highly correlated with generative FID (gFID), providing a more reliable proxy for downstream generative performance.
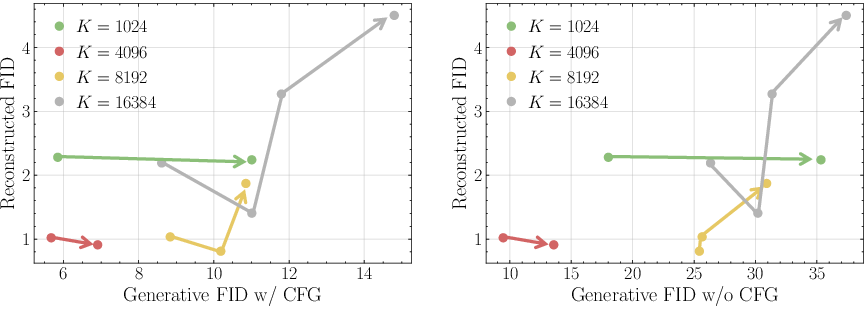
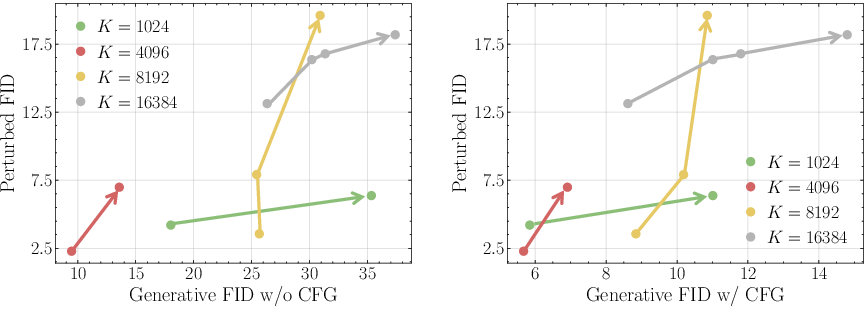
Figure 5: pFID-gFID correlation across tokenizers; pFID aligns with generative quality, unlike rFID.
Empirical Results and Ablations
RobusTok achieves a gFID of 1.60 with a ∼400M parameter generator, further reduced to 1.36 after post-training—establishing a new state-of-the-art under this parameter budget. The improvements are consistent across both autoregressive and diffusion-based generators, and for both discrete and continuous tokenizers.

Figure 6: 256×256 ImageNet generations before (top) and after (bottom) post-training, showing OOD mitigation, color fidelity, and detail refinement.
Ablation studies reveal:
Qualitative Analysis
RobusTok's robustness is evident in both quantitative metrics and qualitative outputs. Generated images exhibit improved structural consistency, color accuracy, and detail, particularly in challenging OOD scenarios. The latent space is more semantically clustered, facilitating both compression and generalization.

Figure 8: Visualization of 256×256 ImageNet class images generated by RobusTok.

Figure 9: Post-training recovers structural and color fidelity in failure cases.
Implications and Future Directions
This work demonstrates that reconstruction-optimized tokenizers are insufficient for high-fidelity image generation. Robustness to OOD latents—explicitly targeted via perturbation and post-training—is essential. The proposed pFID metric provides a practical tool for tokenizer selection without expensive generator training.
Theoretically, this suggests that the latent space for generative modeling should be constructed with both reconstruction and generation in mind, potentially motivating new quantization and regularization strategies. Practically, the plug-and-play nature of RobusTok's training scheme enables its adoption in a wide range of generative pipelines, including those based on transformers, diffusion, and hybrid models.
Future research may explore:
- Adaptive or learned perturbation schedules.
- Joint training of tokenizers and generators with adversarial or contrastive objectives.
- Extension to multimodal and cross-domain generative tasks.
- Integration with large-scale foundation models for unified vision-language generation.
Conclusion
"Image Tokenizer Needs Post-Training" provides a rigorous analysis and practical solution to the overlooked problem of distributional mismatch in image tokenization for generative models. By introducing a two-stage training scheme and a robust evaluation metric, the work sets a new standard for tokenizer design and evaluation, with significant implications for the scalability and fidelity of future generative systems.