- The paper introduces a data-driven Dirichlet prior for LDA by leveraging corpus statistics to enhance topic coherence.
- It replaces the traditional symmetric prior with an empirically-informed, asymmetric parameter using PPMI, diffusion maps, and GMM clustering.
- Experimental results demonstrate improved interpretability and category separation across diverse datasets, including text and single-cell RNA-seq data.
PRISM: Corpus-Intrinsic Priors for Topic Modeling
Introduction
PRISM ("PRIor from corpus Statistics for topic Modeling") introduces a data-driven, corpus-intrinsic initialization strategy for Latent Dirichlet Allocation (LDA). The method leverages empirical word co-occurrence statistics to construct an informed, asymmetric Dirichlet prior over topic-word distributions, completely eschewing external semantic knowledge or pretrained embeddings. The premise is that structural signals available in the target corpus can yield substantial improvements in topic coherence and interpretability, especially in domains where external knowledge or pretrained resources may be misaligned or absent. The paper positions PRISM as a bridge between classical probabilistic models, renowned for transparency and extensibility, and the empirical strength demonstrated by recent embedding-based and neural topic models.
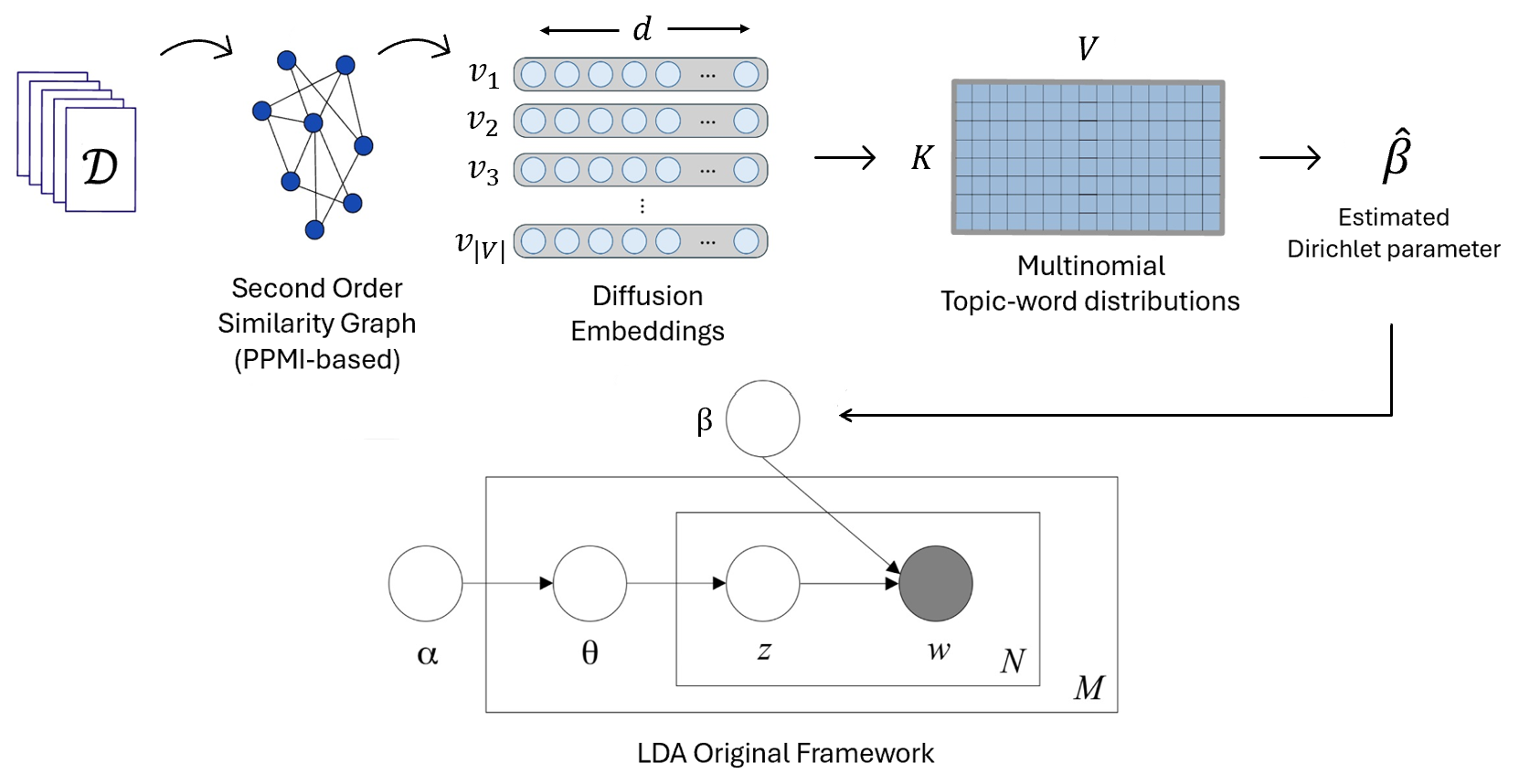
Figure 1: PRISM overview. Corpus-based word similarity is estimated via PPMI and cosine, used to construct a graph and derive diffusion-map embeddings, which are clustered to form a semantically-rich Dirichlet prior for LDA.
Methodology
PRISM augments the LDA framework by providing a non-uniform, vector-valued Dirichlet parameter β^ for topic-word distributions, estimated directly from corpus-internal statistics.
Construction of the Corpus-Derived Prior
- PPMI Similarity Graph: Words are embedded in a similarity space defined by the positive pointwise mutual information (PPMI) between pairs, with cosine similarity capturing indirect associations.
- Diffusion Maps: The resulting similarity graph is nonlinear-embedded via diffusion maps, extracting dense, low-dimensional word representations that encode corpus-driven semantic structure and indirect associations across the vocabulary.
- GMM Clustering: These embeddings are softly clustered via a Gaussian Mixture Model (GMM) with K components (topics), producing probabilistic word-to-topic assignments.
- Multinomial Topic-Word Estimation: Bayes’ rule and corpus unigram statistics are used to infer p(w∣z) for each word-topic pair, producing soft, empirically-grounded topic-word distributions.
- Dirichlet Parameter Estimation: The method-of-moments is employed to estimate a full vector Dirichlet prior β^ based on the constructed topic-word distributions.
PRISM simply replaces the conventional, fixed Dirichlet prior in LDA (often a symmetric scalar or a hand-tuned vector) with β^ at initialization, leaving the generative story and inference algorithm unaltered.
Experimental Results
PRISM is evaluated on five benchmark text corpora of varying size and domain, as well as in the context of single-cell RNA sequencing data for gene program discovery.
Textual Topic Modeling Benchmarks
Quantitative evaluation involves the cv coherence metric, normalized pointwise mutual information (NPMI), and the Word Intrusion Detection (WID) interpretability task—benchmarked against classical (MALLET, NMF), neural (ProdLDA, ETM), and recent SOTA methods leveraging external embeddings (BERTopic, FASTopic, Contextual-Top2Vec).
Main Results:
PRISM outperforms the widely-used MALLET LDA baseline across all major metrics and datasets. The most salient gains are as follows:
- Achieves best cv coherence on 20NewsGroup, M10, and TrumpTweets, second best on BBC and DBLP, frequently matching or surpassing embedding-dependent baselines.
- In the WID interpretability task, PRISM attains the highest accuracy among corpus-intrinsic models and is highly competitive with embedding-based methods, particularly on longer-text domains.
- NPMI improvements, though more modest, are consistent and robust.
The following comparison of top-10 words per topic on the BBC dataset visually illustrates the superior category alignment and lower topical impurity achieved by PRISM over both an embedding-based model (BERTopic) and a neural probabilistic baseline (ProdLDA):
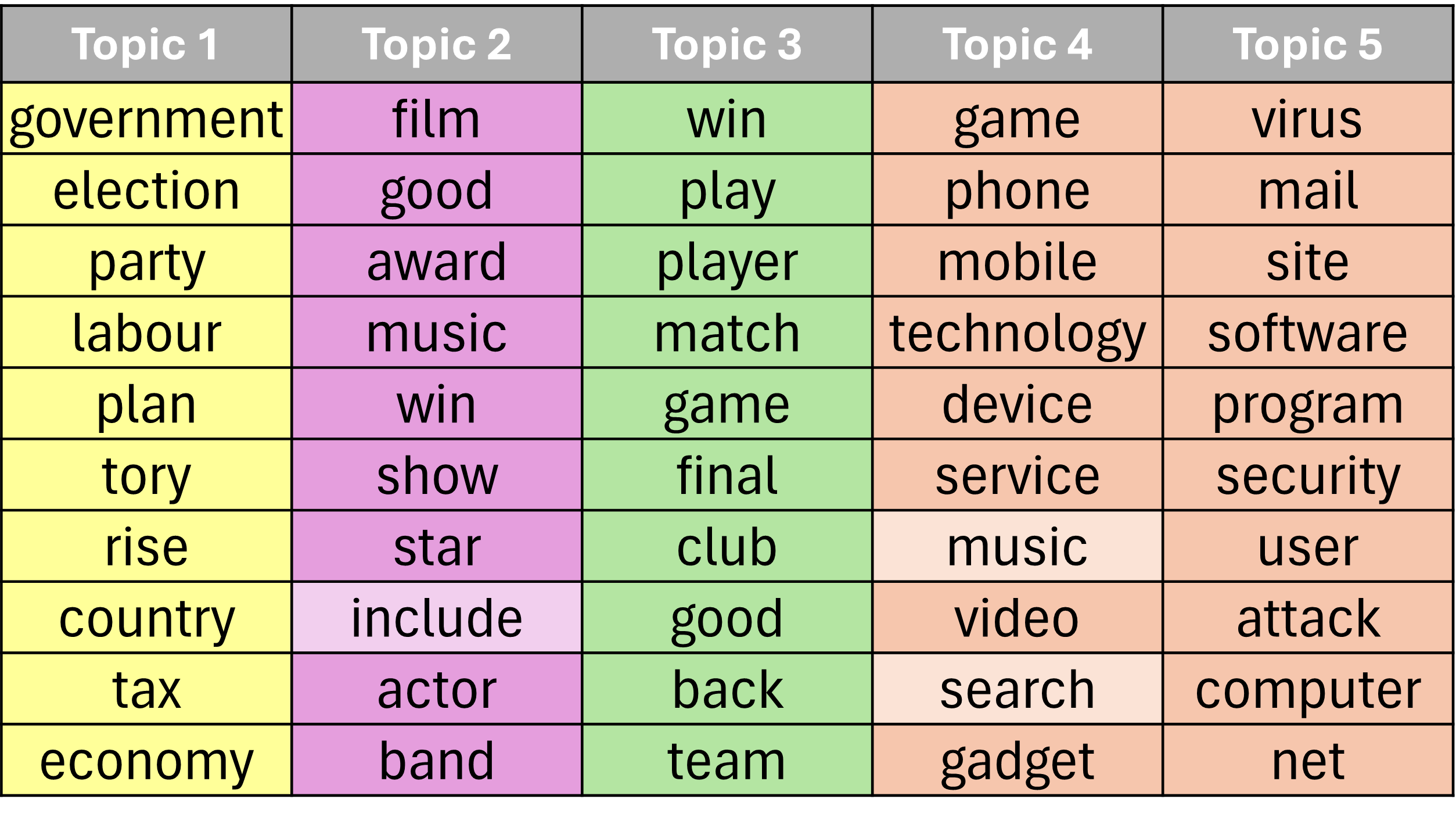
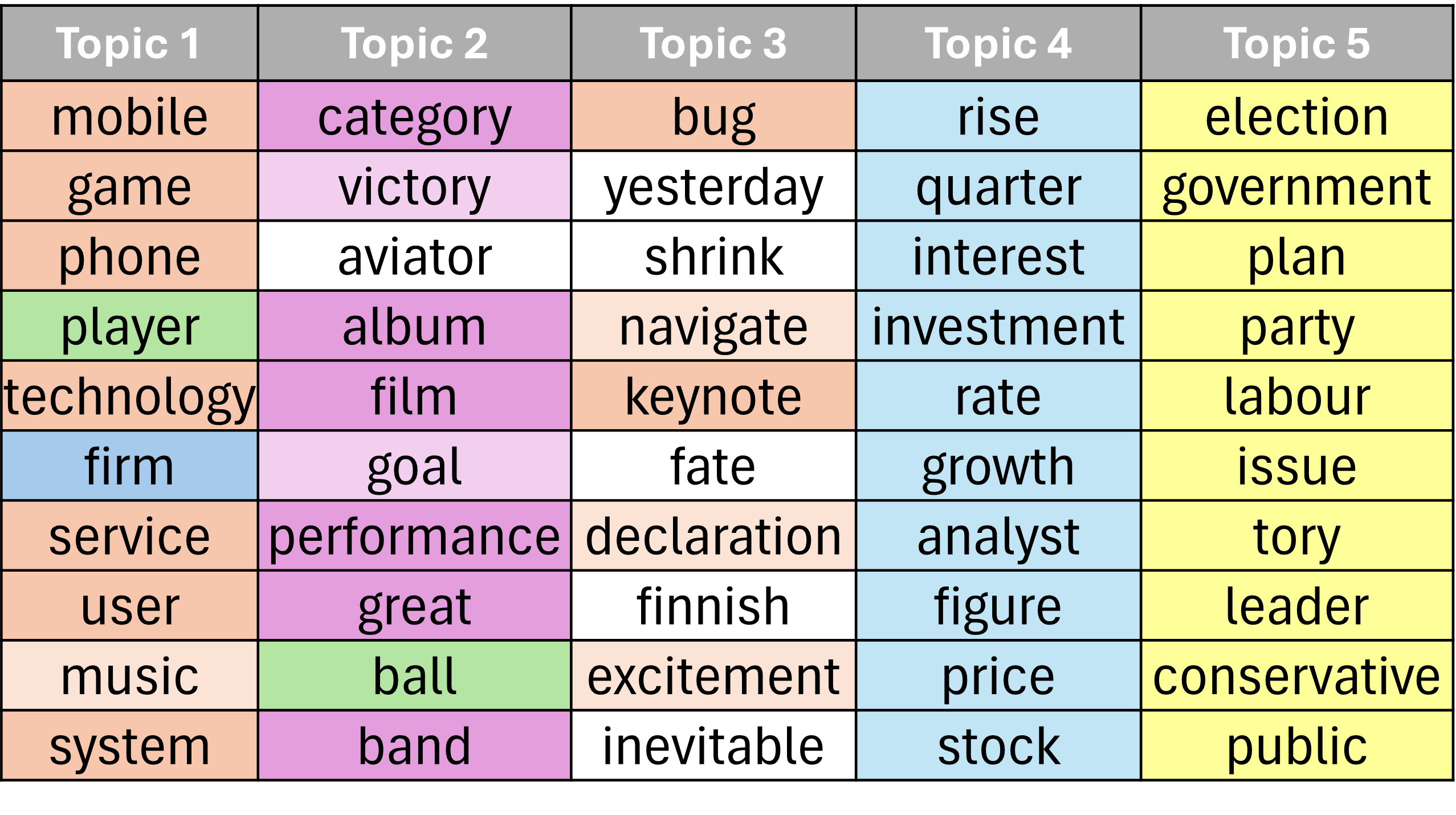
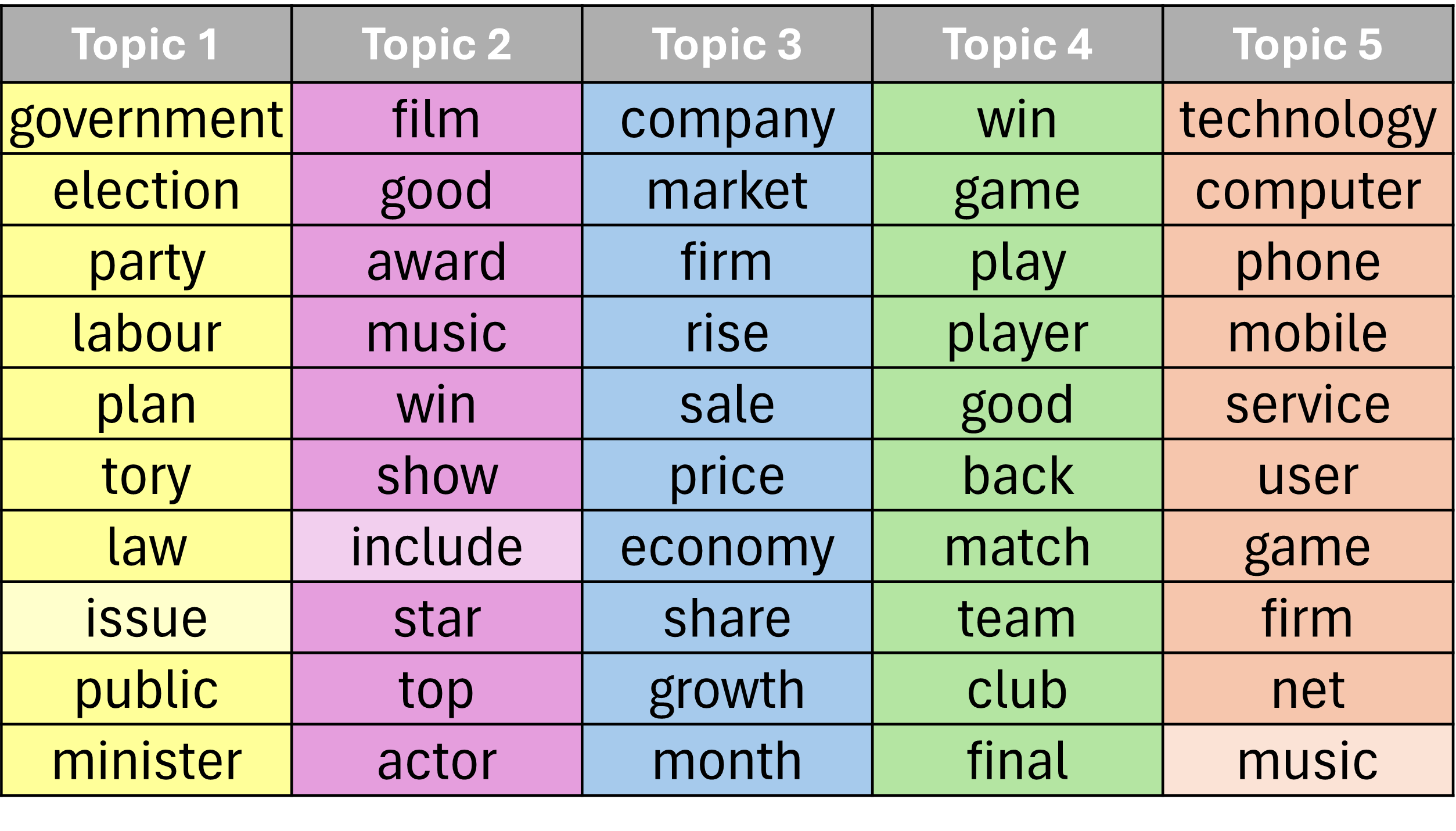
Figure 2: Top-10 words per topic on BBC (K=5): PRISM exhibits distinctly interpretable topics closely matching ground truth, compared to BERTopic and ProdLDA.
In the scientific domain (M10), PRISM more effectively separates gene- and protein-related topics, demonstrating sharper topical granularity and semantic disentanglement than BERTopic and MALLET.
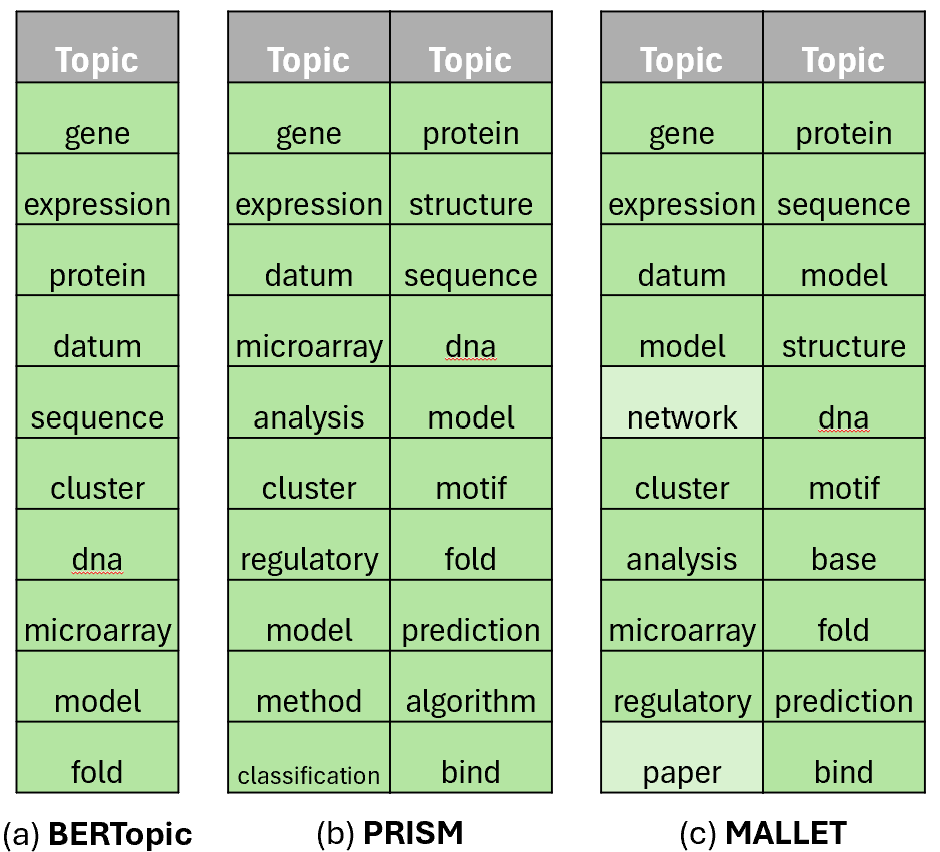
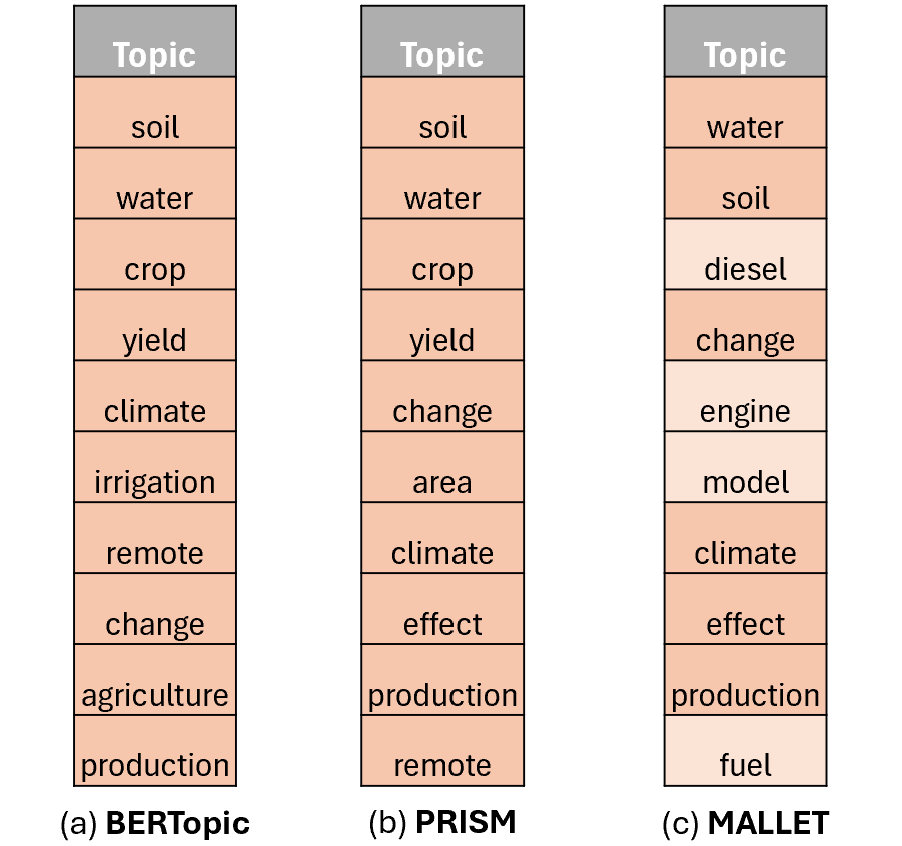
Figure 3: Top-10 words for biology topics in M10, highlighting distinct separation of gene and protein themes by PRISM.
Qualitative Interpretability
The qualitative analysis confirms the strong numerical results, with PRISM frequently recovering all target semantic categories with minimal off-topic bleeding. Non-corpus-informed models tend to exhibit overlapping or poorly separated topics, or fail to recover entire classes, particularly under resource constraints or in short/noisy corpora.
Application to Biological Data
PRISM is evaluated on single-cell RNA-seq expression matrices, with cells as documents and genes as words. The objective is to uncover coherent gene programs (analogous to biological processes) from high-dimensional count data, a task in which external semantic priors are often unreliable due to the incomplete annotation of biological function.
Findings:
- PRISM outperforms the standard MALLET LDA implementation on interpretability and gene set enrichment strength, and is competitive with or exceeds single-cell–specific factorization models (scHPF, cNMF).
- LLM-based scoring of topic gene sets indicates higher biological coherence with PRISM than with all classical text topic models.
These results underscore the generality of corpus-intrinsic priors for program discovery in domains characterized by sparse or idiosyncratic external knowledge.
Discussion and Implications
PRISM's advancements rest on the hypothesis that semantic structure intrinsic to the corpus carries enough information to substantially improve interpretable topic recovery, narrowing the empirical distance to externally supervised models. PRISM maintains the transparency, extensibility, and statistical rigor of classical generative models, while yielding strong empirical performance and eliminating reliance on potentially misaligned or unavailable pretrained resources.
Practical implications:
- PRISM is immediately practical in any corpus where external knowledge is lacking or untrusted, or where opacity in model initialization is undesirable.
- The computational overhead is moderate and dominated by one-time spectral embedding; overall training time approximates standard LDA workflows, substantially outpacing transformer-based pipelines such as BERTopic.
Theoretical implications and future directions:
- The corpus-driven estimation of the entire Dirichlet prior invites extensions to document-topic priors (α), hierarchical models, and adaptive K inference.
- Future work may explore the synthesis of PRISM-style priors with modern neural variational topic models, and their deployment in emerging multidisciplinary datasets where canonical semantic representations do not yet exist.
Conclusion
PRISM operationalizes the notion that a semantically informative, empirically-derived Dirichlet prior can notably enhance the coherence and interpretability of probabilistic topic models. By remaining agnostic to external embeddings and focusing on the intrinsic geometry of word co-occurrence, PRISM achieves or approaches SOTA performance across diverse tasks and domains, with direct applicability to both traditional textual corpora and biologically complex single-cell data. This approach opens new avenues for leveraging corpus-intrinsic structure in probabilistic modeling without sacrificing computational tractability or interpretability.

