- The paper introduces PRISM, which decomposes lengthy prompts into multiple representations to enable detailed and coherent scene synthesis.
- The methodology leverages energy-based diffusion and compositional factorization to improve spatial relationships and attribute fidelity, yielding measurable performance gains.
- The approach retains pretrained model knowledge while effectively generalizing to longer, descriptive prompts, overcoming traditional context window limitations.
Compositional Prompt Decomposition for Robust Long-Text-to-Image Generation
Motivation and Limitations of Existing Approaches
Long-form text-to-image (T2I) generation remains fundamentally constrained by the context window and training regime of current diffusion-based models, which overwhelmingly rely on concise, caption-style text pairs. As the input complexity increases to descriptive paragraphs, standard T2I models fail to capture fine-grained objects, spatial relationships, and intricate scene attributes. Previous strategies have attempted to bridge this gap through fine-tuning on long captions or projection-based mapping, but these approaches either generalize poorly to longer prompts or sacrifice semantic fidelity due to informational bottlenecks (Figure 1).
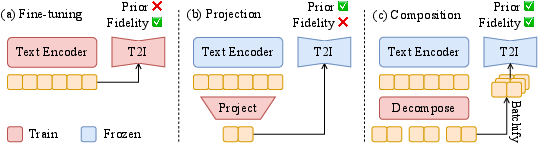
Figure 1: Comparative illustration of fine-tuning, projection, and compositional decomposition approaches for long-text-to-image generation.
The core challenge is out-of-distribution generalization: maintaining high alignment to detailed prompts not seen during training, without catastrophic forgetting or information loss. The paper introduces "Prompt Refraction for Intricate Scene Modeling" (PRISM), grounded in compositional generative modeling and energy-based diffusion concepts, as a solution to this problem.
Methodological Framework: PRISM and Compositional Generation
PRISM leverages compositionality in generative modeling by decomposing a long prompt encoding into multiple constituent representations, each capturing distinct aspects of the paragraph. The decomposition is achieved via a lightweight, trainable module tuned in an unsupervised manner, directly optimizing the extracted representations for composite scene synthesis (Figure 2).

Figure 3: Semantic components extracted from a long prompt, merged during denoising to render the full paragraph.

Figure 2: PRISM architecture with learnable decomposition modules, independent denoising per component, and energy-based composite merging.
Diffusion models are treated as composable EBMs by summing their conditional noise predictions at each denoising step, forming a composite score that guides generation towards images satisfying all constituent prompt factors. PRISM exploits this compositionality without modifying the underlying T2I network, enabling robust out-of-distribution synthesis and preservation of pretrained knowledge.
Two decomposition module implementations are discussed:
- Querying Transformer for bidirectional text encoders (T5, FLUX).
- LoRA-adapted causal LLMs for models like Qwen-Image, tuning the encoder to output constituent representations directly.
Experimental Evaluation and Quantitative Results
Comprehensive experiments are conducted across diverse architectures (Stable Diffusion-1.5, Qwen-Image) using the DetailMaster benchmark, which targets intricate scene generation with average prompt lengths exceeding 280 tokens. PRISM-SD1.5 consistently outperforms competing long-text-to-image methods across character presence, attribute fidelity, spatial relations, and scene attributes. PRISM's integration with advanced reward tuning further amplifies performance, highlighting its compatibility and plug-and-play nature.

Figure 4: PRISM-generated outputs display superior capture of semantic details and spatial relationships versus other long-text methods.

Figure 5: PRISM enhances SOTA T2I models—LLM encoder-equipped baselines fail to render full paragraph detail; compositional decomposition recovers intricate scene elements.
Key numerical results include:
- PRISM-SD1.5 achieves a 7.4% mean improvement over baseline methods for prompts exceeding 500 tokens on DetailMaster.
- PRISM-Qwen improves base Qwen-Image character presence by 6.38% and significantly boosts attribute and spatial relation metrics.
- DenScore, PickScore, and VQAScore evaluations confirm strong image-to-text alignment and human preference scores.
Generalization and Compositionality
Critically, PRISM demonstrates robust generalization as prompt length increases, maintaining high semantic fidelity and prompt adherence where fine-tuning and projection methods degrade sharply (Figure 6, Figure 7).

Figure 6: PRISM retains performance across increasing prompt lengths, outperforming fine-tuning and projection methods outside training distribution.

Figure 7: PRISM continually integrates additional details as prompts expand, with compositional decomposition preventing overwrite and maintaining all scene elements.
Ablation studies reveal the benefit of increased decomposed component count (N): finer granularity leads to more semantically decoupled generations, reduced coupling, and enhanced generalization (Figure 8). Non-compositional and sentence-splitting baselines confirm substantial performance degradation, demonstrating the necessity of learned compositional factorization and energy-based conjunction as opposed to naive linguistic splits.

Figure 8: Semantic decoupling and compositional factorization visualized for varying component counts.
Implementation Considerations and Extensibility
PRISM retains domain compatibility, with constituent prompt representations explicitly tuned to the pretrained T2I model's expected input. Integration with existing reward models and fine-tuning methods is straightforward and results in additive gains. Inference and training are scalable—batch compositional operations mitigate computational overhead through parallelism.
Additional module designs, notably from ELLA, are inherited with modifications to prevent query mode collapse and maintain integrity of factorized representations. PRISM's inference latency increases sublinearly relative to component count, enabling practical deployment on current hardware.
Model tuning via reward models provides further improvements in alignment and human preference scores, confirming compositional generation's synergy with downstream preference optimization.
Practical and Theoretical Implications
From a practical standpoint, PRISM substantially shifts the landscape for long-text prompt following in generative vision models, enabling pre-trained T2I models to process arbitrarily long, descriptive paragraphs without retraining or knowledge loss. This directly addresses the bottlenecks in data scarcity for long-caption pairs and the inherent limitations of fixed context windows.
Theoretically, PRISM validates compositional generative modeling as a robust solution for out-of-distribution synthesis and compositional generalization. By factorizing complex conditional distributions, the approach aligns with contemporary energy-based and product-of-experts frameworks, offering an extensible methodology for text, vision, and multimodal generative tasks.
Future directions include adaptive component granularity for efficiency, explicit spatial control during composition, and scaling decomposition modules to exploit advanced LM architectures. Integrating compositionality with more expressive spatial and temporal constraints may further augment scene consistency and user control.
Conclusion
PRISM introduces a compositional decomposition methodology for long-text-to-image generation, leveraging pretrained model expertise and energy-based diffusion compositionality. The approach achieves superior semantic fidelity, generalization, and prompt compliance across diverse architectures and benchmarks. Empirical results underline strong quantitative gains in prompt alignment and human preference, with robust flexibility and extensibility. The compositional paradigm is validated as a fundamental strategy for overcoming context length bottlenecks in T2I models and facilitating high-fidelity, detailed scene synthesis from descriptive paragraphs.