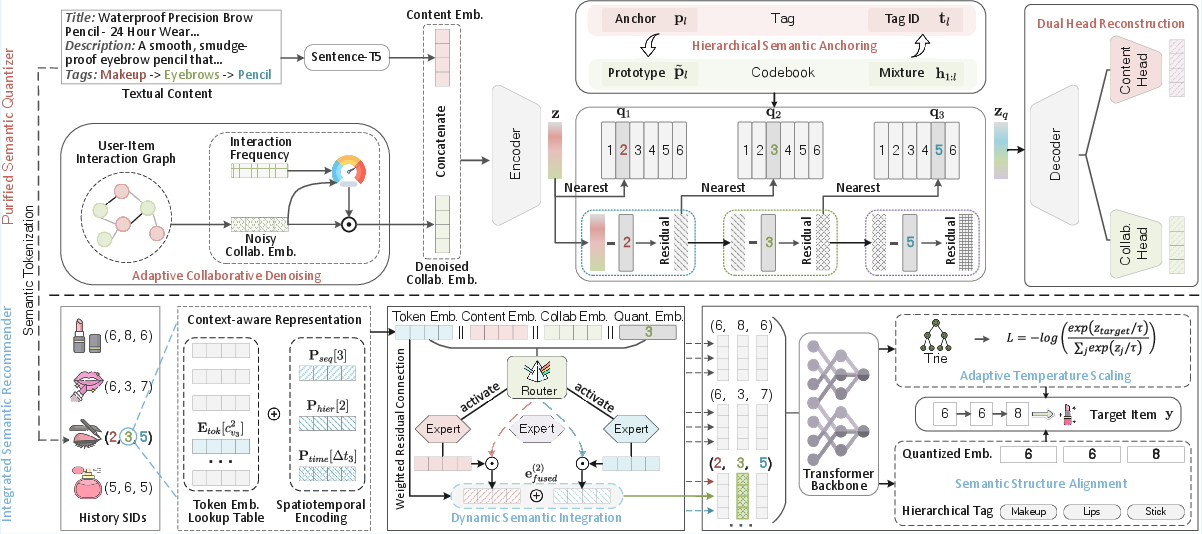
- The paper introduces PRISM, which integrates a Purified Semantic Quantizer and an Integrated Semantic Recommender to address codebook collapse and lossy representations.
- It employs adaptive collaborative denoising and hierarchical semantic anchoring to build robust, noise-tolerant codebooks while preserving detailed semantic nuances.
- Empirical results on Amazon datasets demonstrate superior Recall@K, NDCG@K, and efficiency compared to existing generative recommendation models.
Purified Representation and Integrated Semantic Modeling for GSR
Introduction and Motivation
Recent advances in Generative Sequential Recommendation (GSR) have shifted the classical "retrieve-and-rank" framework to one that leverages autoregressive generation over discrete item representations ("semantic IDs" or SIDs), drawing inspiration from progress in LLMs. This formulation allows for robust knowledge sharing and improved semantic reasoning by capturing item relations with hierarchical discrete codes. However, significant obstacles remain for lightweight generative frameworks:
- Impure and unstable semantic tokenization introduces codebook collapse, where most items are bucketed into a small range of codes, causing ambiguous representations and poor discrimination.
- Lossy and weakly structured generation arises from exclusive reliance on quantized SIDs, severely limiting fine-grained nuance and disrupting the logical consistency of generated recommendations.
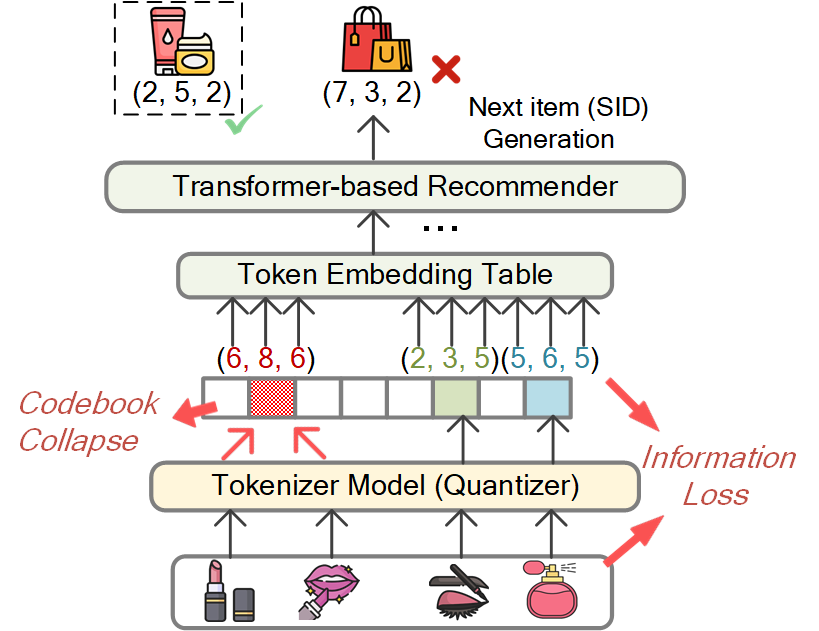
Figure 1: Two fundamental challenges in existing GSR: (a) codebook collapse, resulting in indistinguishable item codes; (b) information loss due to coarse discrete SIDs.
PRISM Framework Overview
To address these challenges, PRISM (Purified Representation and Integrated Semantic Modeling) establishes a two-stage generative recommendation architecture:
Technical Contributions
Purified Semantic Quantizer
The PSQ innovatively tackles item representation degradation by combining:
- Adaptive Collaborative Denoising (ACD): A gating mechanism selectively retains reliable collaborative signals (e.g., high-frequency interactions) and suppresses noise, supervised by interaction frequency statistics for optimization stability.
- Hierarchical Semantic Anchoring (HSA): Category tags guide residual quantization with multi-level semantic priors, ensuring each token level in the codebook aligns with a specific semantic granularity and enforcing hierarchical structure.
- Dual-Head Reconstruction (DHR): Parallel reconstruction objectives for content and collaborative modalities counteract gradient imbalance, ensuring both semantic facets are preserved in the quantized space.
Codebook collisions are globally deduplicated post hoc via a discrete optimal transport formulation using Sinkhorn-Knopp, thus ensuring a bijective item-to-SID mapping without semantic degradation.
Integrated Semantic Recommender
The ISR module is responsible for restoring fine-grained details lost by quantization and ensuring semantic-valid generation:
- Dynamic Semantic Integration (DSI): Implements a Mixture-of-Experts (MoE) router to flexibly combine context-enriched SID embedding with content/collaborative features and depth-specific projections for each position in the SID hierarchy.
- Semantic Structure Alignment (SSA): Imparts a structural regularizer by obligating the decoder's hidden states to regress not only the discrete codebook latent (ql(tgt)) but also hierarchical item tags, ensuring both category and fine structure are retained in autoregressive predictions.
- Adaptive Temperature Scaling (ATS): Generation temperature is modulated according to Trie-branching density at each position, thus balancing exploration and confidence depending on the semantic granularity and reducing prediction ambiguity in dense branches.
Empirical Results
Overall Effectiveness
Across four Amazon datasets (Beauty, Sports, Toys, CDs), PRISM sets new state-of-the-art results in both Recall@K and NDCG@K, outperforming both traditional discriminative and other generative models (notably TIGER, EAGER, LETTER, ActionPiece), particularly with pronounced gains in highly sparse regimes and on challenging datasets like CDs.
Robustness to Sparsity
When segmenting by item popularity, PRISM demonstrates superior robustness on "long-tail" (low-frequency) items. Competing methods such as TIGER cannot maintain unique SID assignments in these sparse regions due to codebook collapse, while ActionPiece's advantage is primarily attributable to model width rather than improved semantic discrimination. PRISM achieves a strict Pareto improvement, preserving high accuracy for both popular and long-tail items.
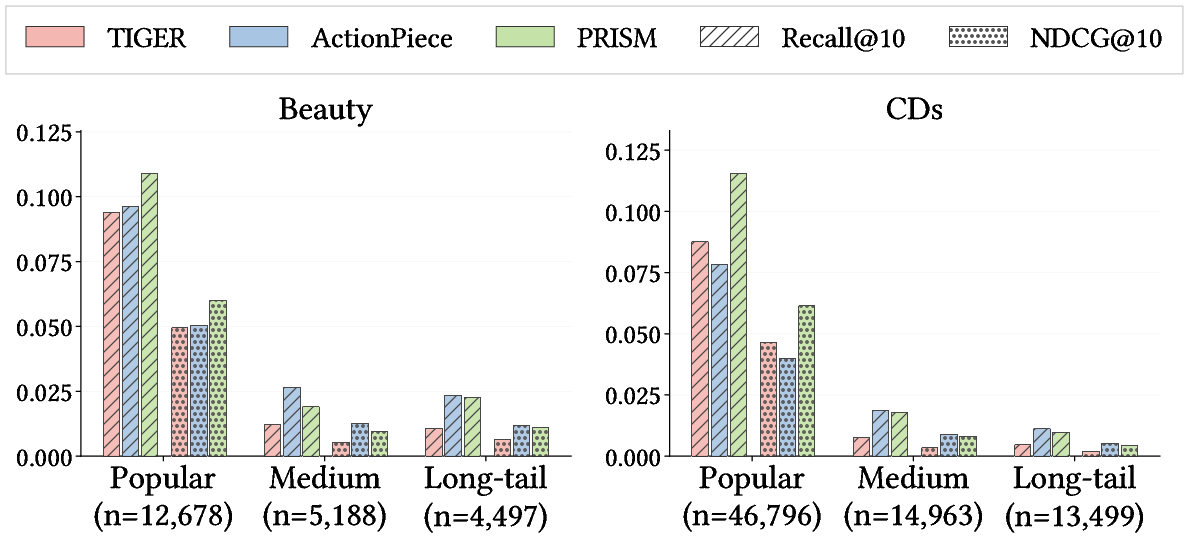
Figure 3: PRISM achieves substantial gains across item popularity groups, especially under sparsity.
SID Discretization Quality
Ablations highlight the importance of each component in SID quality:
- Full PRISM achieves a codebook perplexity of 248.5/256 and minimizes collision rate to 1.79%, far superior to TIGER (PPL 84.2, CR 31.57%) and other baselines.
- Removing HSA, ACD, or DHR increases code collisions and decreases uniform codebook usage, confirming the necessity of coordinated denoising, semantic anchoring, and balanced reconstruction.
Latent Space Visualization
t-SNE projections of the codebook and item embeddings confirm PRISM's ability to establish well-separated, hierarchically ordered codebook spaces and produce item embeddings clustered according to semantic categories. This contrasts sharply with the collapsed, entangled structures exhibited by baseline models.
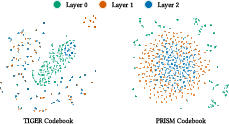
Figure 4: t-SNE visualization—PRISM's codebooks exhibit concentric hierarchical structure, unlike TIGER's collapsed embeddings.

Figure 5: t-SNE visualization—item embeddings from PRISM align with distinct semantic categories, demonstrating strong discriminative capability.
Efficiency Analysis
Efficiency benchmarks indicate PRISM maintains minimal activated parameter count (~5.5M) and low inference latency (<30ms on largest datasets), in contrast to competitors requiring 3–4× larger backbones to approach similar accuracy, particularly in high-sparsity settings.
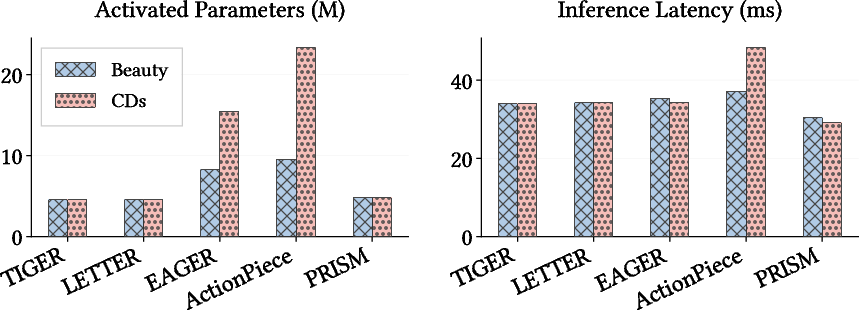
Figure 6: PRISM achieves the best efficiency-performance trade-off with low inference latency and compact model size.
Theoretical and Practical Implications
PRISM demonstrates that robust GSR does not require brute-force scaling but arises from:
- Fine-grained purification of heterogeneous signals through adaptive noise filtering.
- Tight semantic guidance via hierarchical anchoring in codebook learning.
- Dynamic feature integration, supplementing lossy codes with context-aware semantics during generation.
- Precise structural alignment to guarantee logical consistency in autoregressive recommendation.
These results suggest a path forward for scalable, efficient, and interpretable GSR even under extreme catalog sparsity, and provide a template for further integration of symbolic priors and structure-aware objectives in generative recommendation paradigms.
Conclusion
PRISM (Purified Representation and Integrated Semantic Modeling) offers a comprehensive solution to long-standing limitations in lightweight generative sequential recommendation. By enforcing semantic purity and structural robustness at every layer of the architecture, it establishes new benchmarks in both recommendation quality and efficiency, with compelling evidence of scalability and discriminative capacity even in data-scarce environments. Future developments may explore further generalization of purified codebook learning, reinforcement-based structure alignment, and extension to multi-modal or interactive recommendation settings.