- The paper introduces a novel student-teacher pipeline that distills sparse LLM supervision into a refined encoder for high-precision topic modeling.
- Methodology leveraging range-bound binary comparisons and embedding similarity yields superior discriminative capacity and cluster purity over methods like BERTopic.
- PRISM achieves cost-effective, deployable semantic clustering without continued LLM dependency, enabling accurate tracking of nuanced narratives in resource-constrained environments.
PRISM: LLM-Guided Semantic Clustering for High-Precision Topics
Introduction and Motivation
PRISM (Precision-Informed Semantic Modeling) addresses the limitations of contemporary topic modeling approaches—specifically, their inability to distinguish subtle, domain-specific nuances in textual data at scale. While BERT-based and LLM-augmented methods offer rich semantic embeddings, their inference cost, latency, and reliance on generative models at deployment hinder practical use, especially on web-scale corpora or in resource-constrained settings. PRISM introduces a novel student-teacher semantic clustering pipeline that efficiently distills sparse LLM supervision into a tuned, deployable encoder, enabling fine-grained topic discovery with no LLM dependence at inference.
Methodology
PRISM's architecture starts with a large corpus CText. The framework samples pairs (or sets) of texts, which are labeled via LLMs (teacher model L) using either generative similarity prompts or high-capacity embedding comparisons. These labels are leveraged to fine-tune a pre-trained sentence encoder S0—typically all-mpnet-base-v2—into a domain-specialized student model S. Fine-tuning is conducted using CoSENT loss, shown empirically to outperform contrastive methods for the constructed binary comparison and similarity datasets.
Clusters are then generated via thresholded community detection in the student embedding space. Unlike approaches that force all data into partitions, PRISM allows for unassigned singletons, crucial for maintaining topic purity in highly granular narrative discovery. Clustering threshold τ can be set manually or optimized via validation sets labeled by the teacher.
Comparison of Sampling and Training Strategies
The efficacy of PRISM depends heavily on the choice of teacher queries and dataset construction. Three principal approaches are explored:
- Full-range Binary Comparison (FR): Random sampling of text pairs labeled by a generative LLM as semantically equivalent or distinct.
- Range-bound Binary (RB): Restricts pairs to where the initial student encoder is uncertain, driving learning towards ambiguous or closely related content.
- Embedding Similarity: Utilizes high-capacity embedding models to generate similarity scores directly, constructing larger and denser training triplets.
Empirical results show that RB comparisons yield the largest improvement in discriminative capacity for the student encoder, as evidenced by AUC gains (see Table \ref{tab:auc_results} in the original). Notably, fine-tuned PRISM student encoders match or exceed the teacher's embedding model on downstream evaluation.
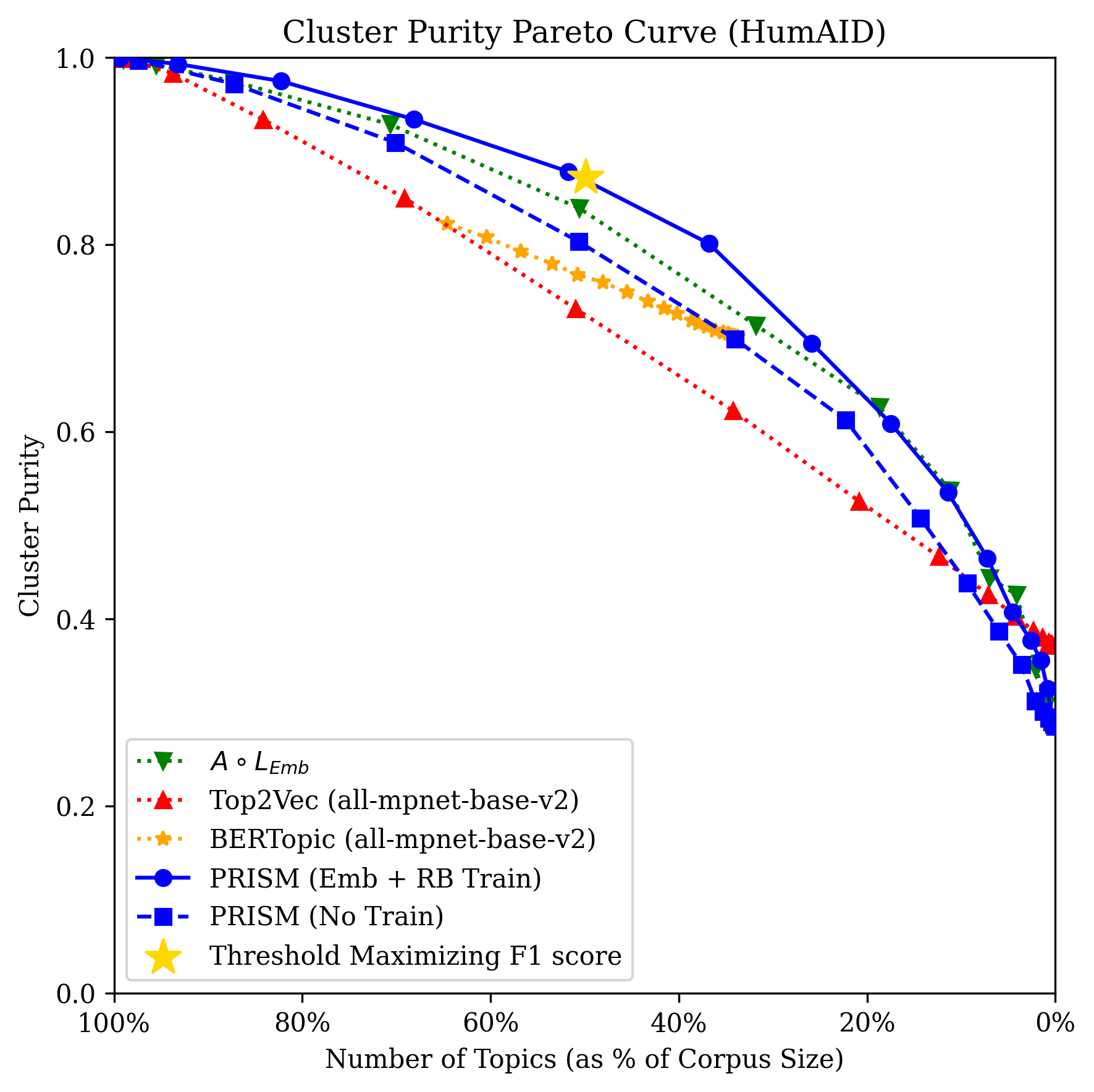
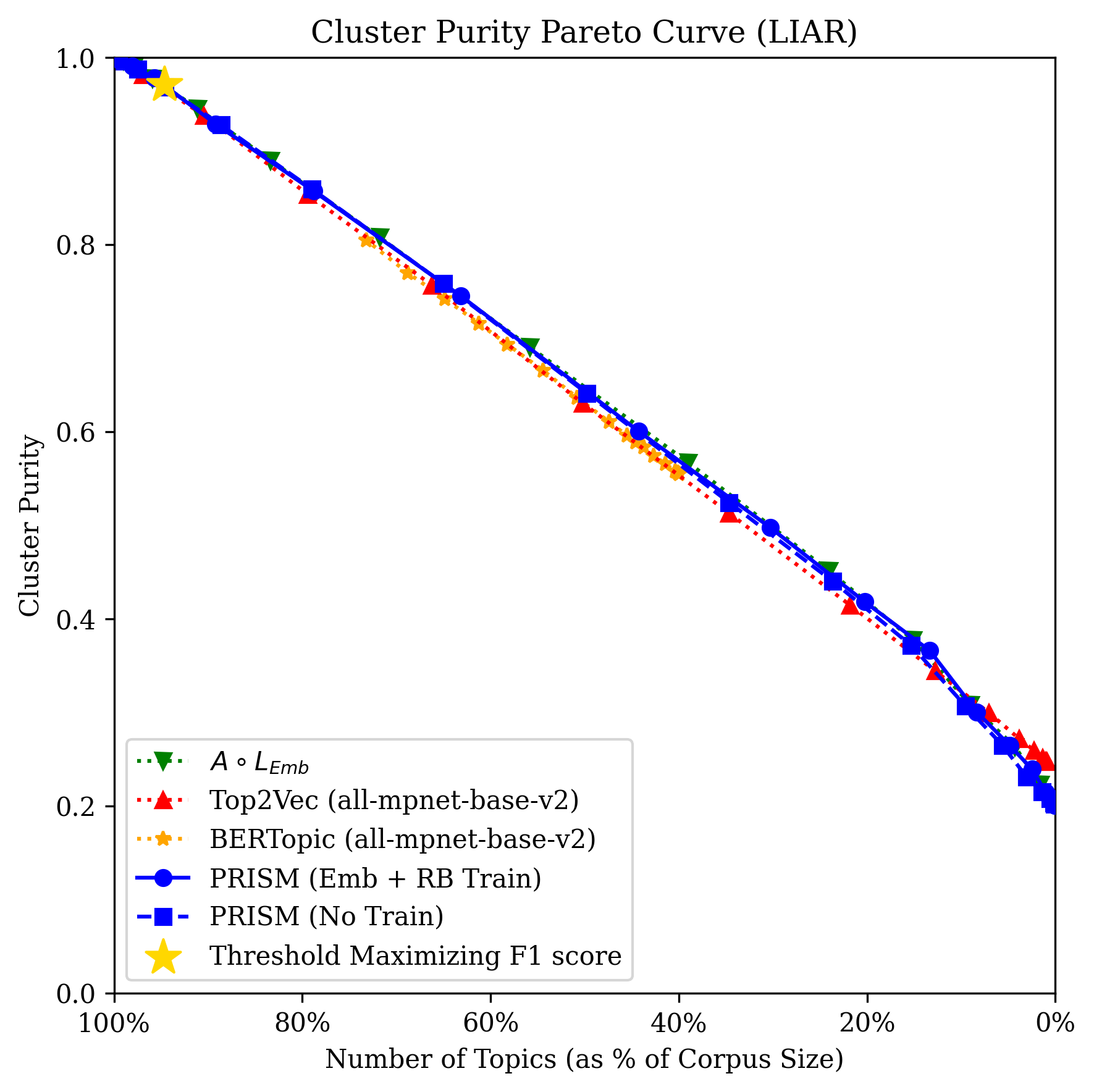
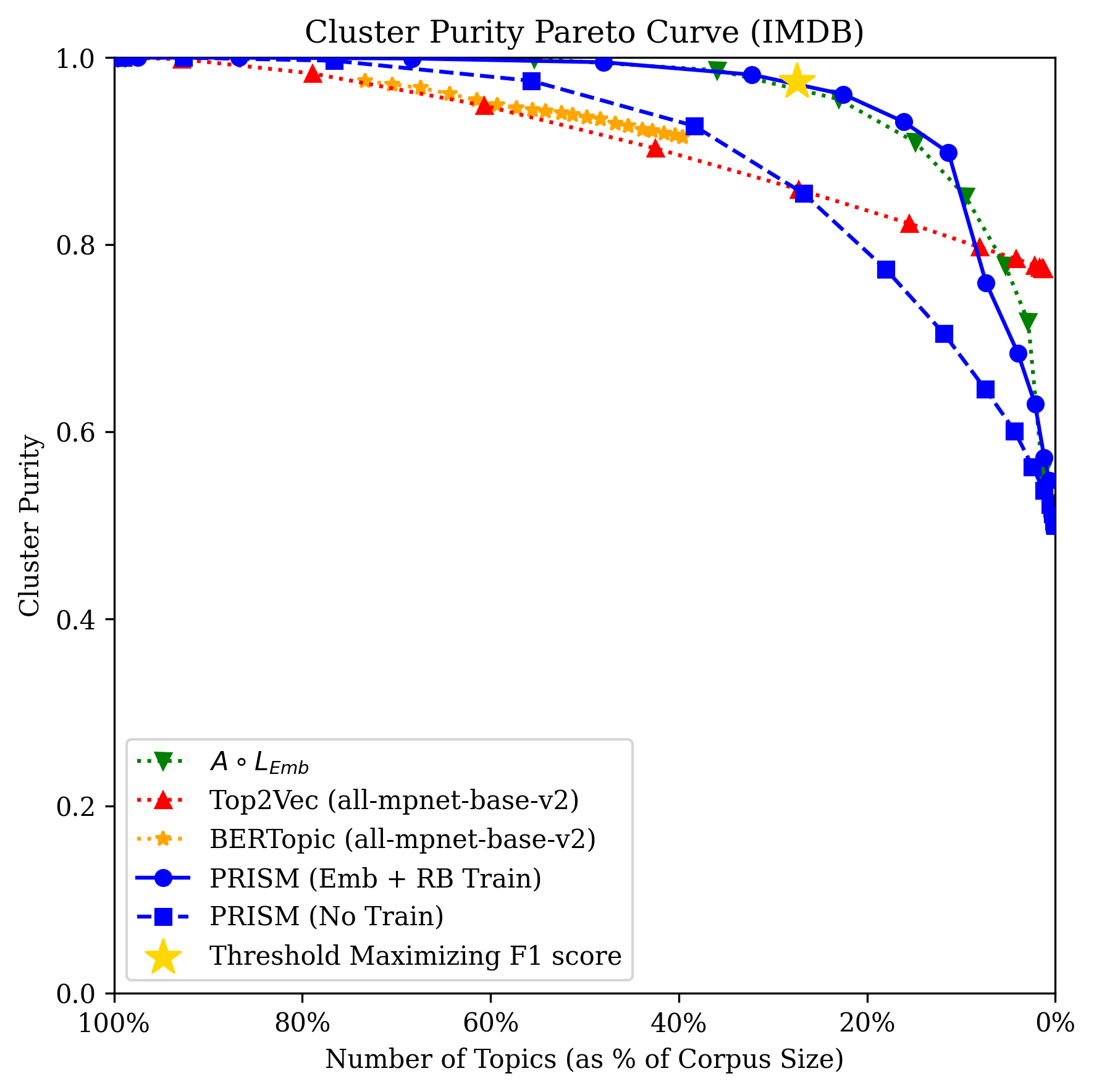
Figure 1: HumAID Corpus Pareto curve illustrating the trade-off between cluster purity and the number of clusters, with PRISM advancing the frontier in topic separability.
Experimental Evaluation
PRISM is evaluated against semantic clustering baselines (Top2Vec, BERTopic) and direct clustering on teacher-provided embeddings across three diverse corpora:
- HumAID: 77K disaster-related tweets, annotated for disaster narratives.
- LIAR: Short political statements with truth labels.
- IMDB: Movie reviews with sentiment (positive/negative).
Cluster quality is measured using cluster purity (majority voting against human/intended labels), and aggregate performance is assessed as area under the Pareto curve (AUPC), quantifying each model’s ability to maintain high purity across varying cluster granularities.
Across all datasets, PRISM fine-tuned on both RB and embedding similarity samples strictly dominates BERTopic, and outperforms Top2Vec except in extremely fine partitions. Importantly, PRISM surpasses clustering directly on LLM-based embeddings—demonstrating that knowledge distillation and optimal training set construction can yield in-domain representation superior to the teacher, but at a fraction of the inference cost.
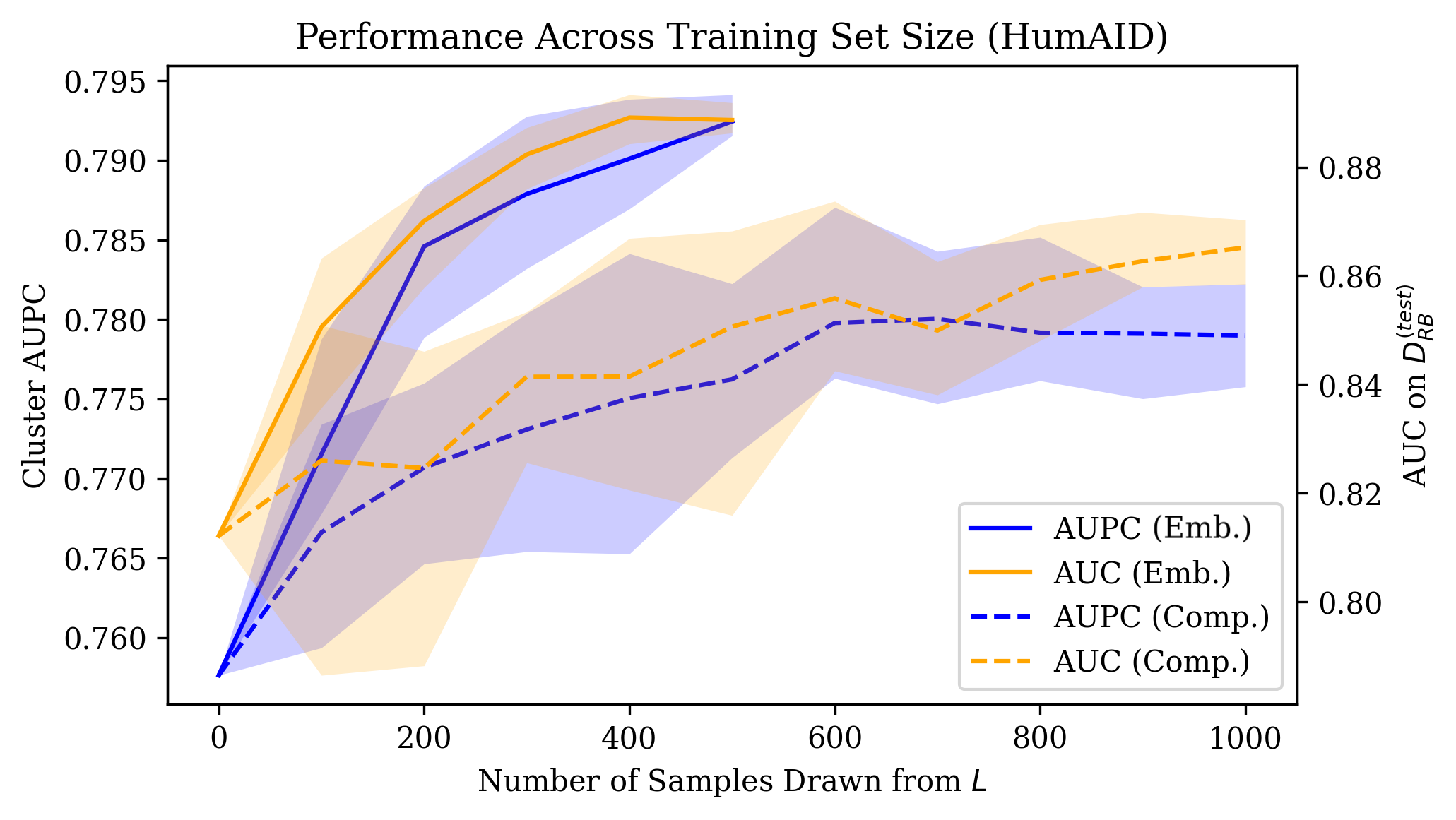
Figure 2: AUC and AUPC progression on HumAID as a function of training set size, highlighting the rapid asymptotic gains from both comparison and embedding supervision.
Implications and Future Directions
The practical implication of PRISM is clear: LLM-level topic resolution is attainable in resource- or latency-constrained applications with modest LLM labeling overhead and no inference-time API dependency. This enables domain-precise tracking of fine-grained narratives on the web—an essential requirement in areas such as disinformation detection, crisis response, and policy analysis—without prohibitive compute or cost.
Theoretically, PRISM reinforces the power of targeted knowledge distillation and supports recent findings that LLMs serve as near-optimal annotators for complex semantic tasks. The method’s strong numerical results confirm that careful curation of training pairs (active, range-bound sampling) and joint use of diverse LLM assets accelerate both representation compression and specialization.
Potential future directions include:
- Active Learning: Real-time query selection or dataset bootstrapping, leveraging PRISM's flexible architecture for continuous domain adaptation.
- LLM Signal Enrichment: Incorporation of richer supervision, such as LLM-extracted rationales or open-weight model activations, to further boost embedding specificity.
- Domain Applications: Extension to diachronic or cross-lingual corpora, and integration into analytic pipelines for computational social science.
Conclusion
PRISM introduces an interpretable, high-precision topic modeling pipeline that synthesizes LLM supervision and efficient student-teacher adaptation, yielding in-domain clustering quality beyond baseline embedding or LLM-guided clustering approaches. By strategically selecting and distilling sparse LLM-labeled comparisons, PRISM provides scalable, locally deployable models capable of semantically discerning even nuanced narratives without post-deployment LLM dependency. This framework establishes a performant and economically viable path forward for web-scale, high-resolution textual analysis and tracking.