- The paper introduces a training-free pipeline that extends object-centric models to generate town-scale 3D scenes from a single image.
- It employs overlapping patch-wise flow and under-noised iterative SDEdit to ensure seamless spatial consistency and enhanced geometric fidelity.
- The method demonstrates strong qualitative and quantitative gains against baselines, with up to 87% win rates in human evaluations and improvements in SSIM, LPIPS, and PSNR metrics.
Extend3D: A Training-Free Pipeline for Town-Scale 3D Generation
Introduction
Extend3D introduces a training-free architecture for large-scale 3D scene generation from a single image, leveraging pre-trained object-centric 3D generative models and addressing the limitations posed by predefined, fixed-size latent representations. The framework targets the core challenges of scalability, spatial consistency, and alignment between 2D image conditions and the resulting 3D structures, producing high-fidelity, coherent town-scale outputs.
The pipeline consists of two major phases: sparse structure generation and structured latent generation, orchestrated by the novel mechanism of overlapping patch-wise flow. Furthermore, it integrates advanced initialization and optimization strategies—most notably, iterative under-noised SDEdit and 3D-aware objectives—ensuring that geometrical and textural fidelity is preserved and enhanced across arbitrarily extended spatial domains.
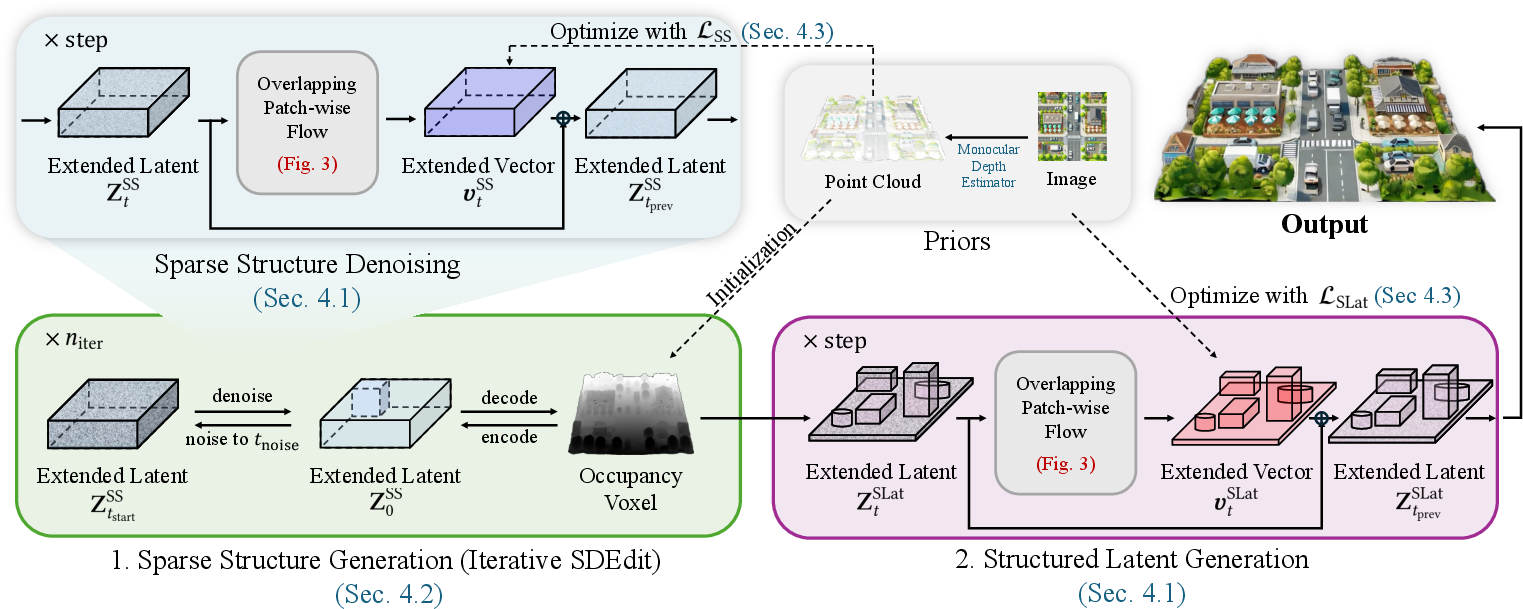
Figure 1: Overall pipeline of Extend3D. The method uses overlapping patch-wise flow for both sparse structure and structured latent generation, initializing structure with a depth estimator and iteratively refining occluded areas.
Overlapping Patch-Wise Flow for Latent Extension
Central to Extend3D is the parallel, coupled generation of overlapping sub-latent patches. The extended latent tensor in the x and y dimensions is divided into overlapping patches, each of which is processed by the object-centric model conditioned on locally cropped image regions. The denoising paths of adjacent patches are coupled via a merge operation that averages overlapping regions, thus preserving local and global consistency and mitigating seam artifacts common in prior approaches reliant on outpainting or sequential sub-scene composition.
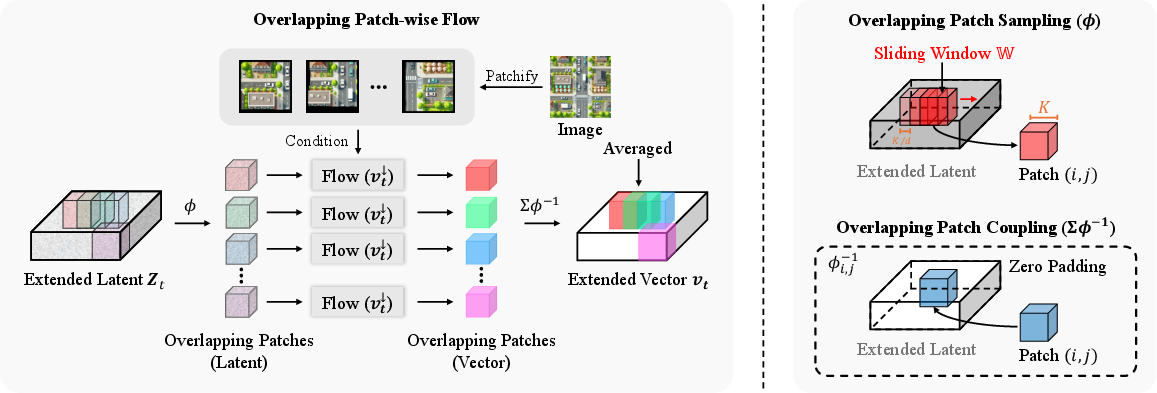
Figure 2: The overlapping patch-wise flow divides the extended latent into patches, processes them, and merges them with couplings at the boundaries to ensure seamless generation.
Compared to previous scene generation approaches, this mechanism produces more consistent and artifact-free large-scale scenes, enabling extension to resolutions and domains unattainable with standard fixed-latent models.
Structural Prior Initialization via Under-Noised SDEdit
A significant challenge in scaling object-centric models to large scenes is maintaining spatial alignment with the conditioning image and avoiding degenerate solutions (e.g., vanishing floors, incoherent object orientation). Extend3D initializes the 3D structure using monocular depth estimation (MoGe-2), voxelized to seed the latent tensor. However, as depth estimation fails in occluded regions, direct use would yield incomplete or artifact-ridden reconstructions.
To address this, Extend3D employs an under-noised variant of SDEdit, performing iterative partial noise addition and aggressive denoising relative to the standard SDEdit schedule. This "under-noising" approach treats unobserved or missing geometry as noise, promoting plausible, data-consistent completion during refinement.
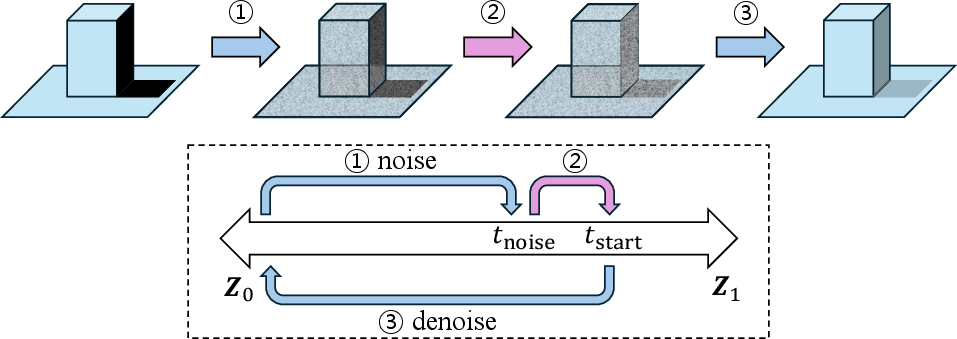
Figure 3: Under-noising in SDEdit treats structural incompleteness as noise, enabling scene completion mechanisms in the generative prior.
Empirical ablation confirms that under-noising (i.e., denoising from a longer schedule than the noise added) significantly improves 3D completion in occluded regions, providing geometric hypotheses better aligned with the high-level image condition.
3D-Aware Latent Optimization and Objective Functions
During iterative denoising, structured latent optimization is performed at every time step. Extend3D defines two loss functions:
- For the sparse structure, a geometry-preserving adversarial loss ensures occupancy around prior-initialized voxels is preserved.
- For structured latents, a differentiable renderer supervises texture and shape using appearance matching losses (LPIPS, SSIM) between the rendered view and the source image, coupled with geometry terms.
Gradient-based updates (e.g., Adam) on the latent representation at each time step align generative dynamics with prior constraints, compensating for the tendency of object-centric models to default to isolated, unaligned object layouts. This continual optimization during denoising further reduces seams and enhances both macroscale consistency and fine detail reconstruction.
Experimental Results
Qualitative and Quantitative Evaluation
Extend3D demonstrates strong cross-domain generalization, handling a wide variety of images—including synthetic datasets (CarlaSC, UrbanScene3D), internet images, and Google Earth—without training on 3D scenes. The method excels in image faithfulness, structural completeness, and consistency across adjacent scene regions.

Figure 4: Extend3D results (center/right) exhibit superior spatial fidelity, texture, and scene completeness compared to prior models, with architecture, object placement, and details faithfully captured from the input image.
Human preference experiments (n=10) on geometry, faithfulness, appearance, and completeness show Extend3D surpasses Trellis, Hunyuan3D, and EvoScene in all categories, with win rates up to 87%.
Quantitatively, the method achieves improvements in SSIM (0.611), LPIPS (0.240), and PSNR (20.4dB), with geometric fidelity validated by Chamfer Distance (0.0086) and F-score (0.694) on UrbanScene3D, outperforming all baselines.
Ablation studies indicate that each pipeline component—overlapping patch-wise flow, structured initialization with priors, under-noised SDEdit, and per-step 3D-aware latent optimization—substantially contributes to the observed gains.
Large-Scale Scene Generation
Extend3D has been demonstrated on true town-scale scenes, such as entire urban regions captured from Google Earth, generating meshes and Gaussian splats at up to 36× the extent of the original model's generative field. This is accomplished without custom scene-level training, leveraging only object-centric priors and generic monocular cues.
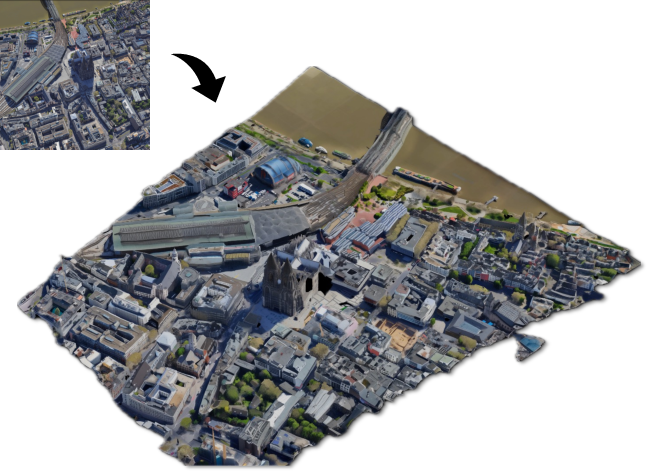
Figure 5: Extend3D reconstructs large-scale urban topologies (here, Köln), retaining structural coherence, with detail and scalability that exceed previous pipelines.
Limitations and Future Directions
While Extend3D substantially advances training-free, image-guided 3D scene generation, limitations persist. Completion of highly occluded or unobserved regions is not always plausible, especially in interior or street-level image domains suffering from vanishing point–induced misalignments. Scene-level optimization of the latent representation is memory-intensive, particularly at maximum spatial extensions, restricting scalability given fixed hardware constraints.
Potential future improvements include direct integration of multi-view geometry cues, diffusion-based hierarchical generative priors, and adaptive, viewpoint-aware latent layouts. Improved occlusion reasoning and further reduction in memory footprint during scene optimization will facilitate extension to even broader scale and application domains (e.g., simulation, content authoring, robotics).
Conclusion
Extend3D constitutes a significant advance in scene-level 3D generation from single images, overcoming longstanding limitations of object-centric models. Through extended latent spaces, overlapping patch-wise flow, robust initialization via monocular priors, under-noised iterative SDEdit, and per-step 3D-aware latent optimization, the method achieves unprecedented quality and scale for training-free, image-guided 3D scene synthesis. The approach offers strong implications for content creation, simulation, and digital twin applications, providing a path forward for scalable, generalizable, high-fidelity 3D generative frameworks.

