3D-RE-GEN: 3D Reconstruction of Indoor Scenes with a Generative Framework
Abstract: Recent advances in 3D scene generation produce visually appealing output, but current representations hinder artists' workflows that require modifiable 3D textured mesh scenes for visual effects and game development. Despite significant advances, current textured mesh scene reconstruction methods are far from artist ready, suffering from incorrect object decomposition, inaccurate spatial relationships, and missing backgrounds. We present 3D-RE-GEN, a compositional framework that reconstructs a single image into textured 3D objects and a background. We show that combining state of the art models from specific domains achieves state of the art scene reconstruction performance, addressing artists' requirements. Our reconstruction pipeline integrates models for asset detection, reconstruction, and placement, pushing certain models beyond their originally intended domains. Obtaining occluded objects is treated as an image editing task with generative models to infer and reconstruct with scene level reasoning under consistent lighting and geometry. Unlike current methods, 3D-RE-GEN generates a comprehensive background that spatially constrains objects during optimization and provides a foundation for realistic lighting and simulation tasks in visual effects and games. To obtain physically realistic layouts, we employ a novel 4-DoF differentiable optimization that aligns reconstructed objects with the estimated ground plane. 3D-RE-GEN~achieves state of the art performance in single image 3D scene reconstruction, producing coherent, modifiable scenes through compositional generation guided by precise camera recovery and spatial optimization.








Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces 3D-RE-GEN, a system that can turn a single photo of an indoor scene (like a living room) into a complete 3D scene you can edit and use in video effects or games. Unlike many earlier tools, it builds proper 3D objects with textures, puts them in the right places, and also creates the background (the room itself), so everything fits together and looks physically believable.
What questions are they trying to answer?
The authors focus on three simple questions:
- From just one picture, can we rebuild a full 3D room with separate, editable objects?
- Can we handle hidden parts of objects (for example, the back of a chair that isn’t visible) in a smart, context-aware way?
- Can we place objects so they look physically correct (for example, sitting on the floor, not floating) and match the photo’s perspective?
How does their method work?
Think of the system like a careful craftsperson rebuilding a room from a single snapshot. It follows a step-by-step plan and uses several specialized AI tools together.
The pipeline at a glance
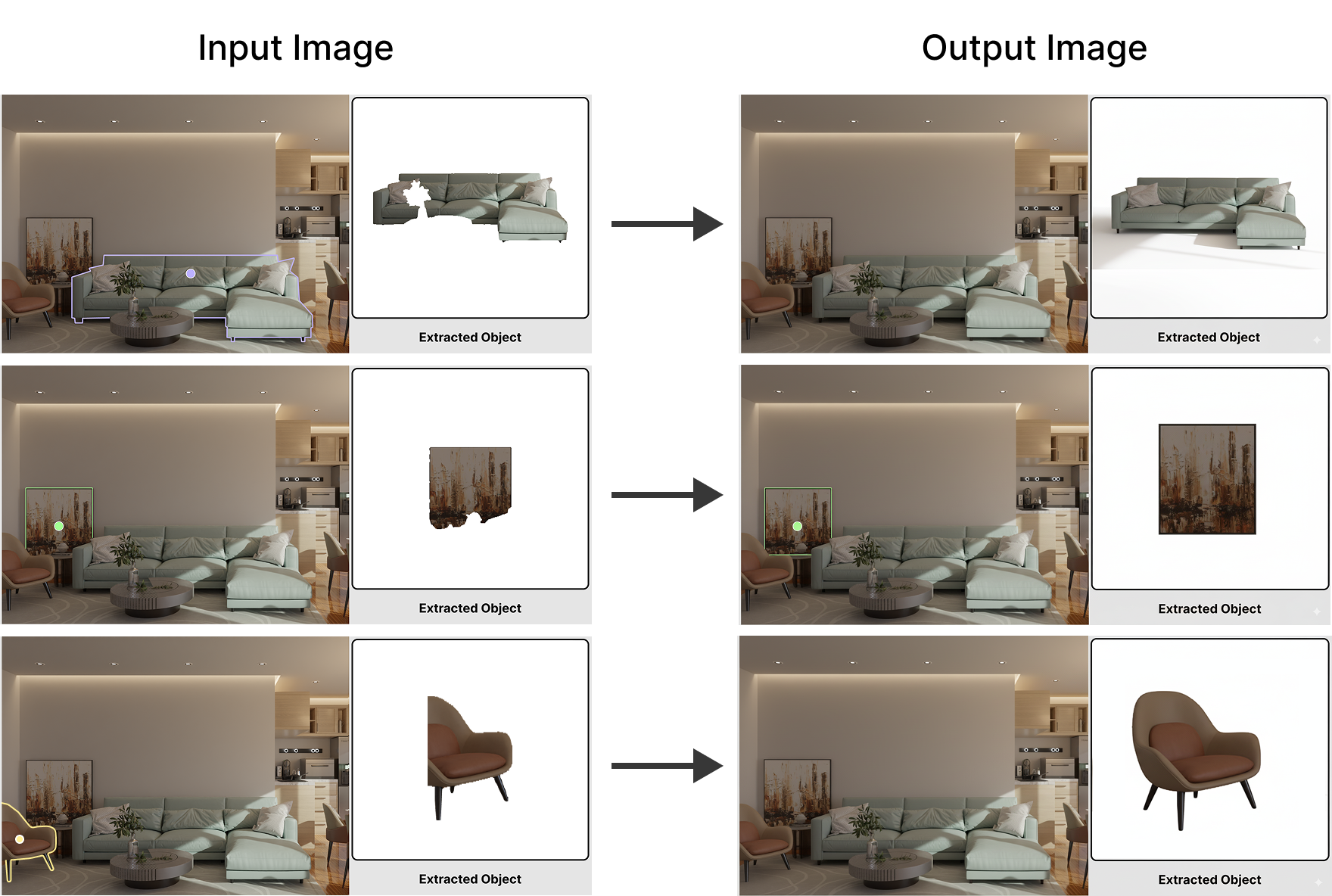
- Find and cut out objects: The system detects each object in the photo (like a table, chair, or lamp) and makes accurate masks for them.
- Fill in missing parts and clean the image: It uses a smart image-editing trick called Application-Querying (A-Q). Imagine giving an AI a two-panel “app screen”: on the left, it sees the full original room (for context) with the object’s outline; on the right, it sees the cut-out object on a white background. With that context, the AI “finishes” the object, painting in the hidden parts so it looks complete. At the same time, it also removes the object from the original photo to create an “empty room” background.
- Rebuild the camera and the room: The system estimates how the original photo was taken (the camera’s position and angle) and creates a rough 3D point cloud of the scene. Using the “empty room” image helps it reconstruct a clean background and then turn that into a usable 3D mesh of the room.
- Turn each 2D object into a 3D model: For every cleaned-up object image, a 2D-to-3D model generates a textured 3D mesh.
- Place objects into the room correctly: Finally, the system puts every 3D object back into the room. It uses two kinds of checks to line things up:
- 2D check: Does the outline (silhouette) of the 3D object match the object’s shape in the photo?
- 3D check: Do the 3D points from the photo align with the surface of the 3D object?
It also uses the background as a “fence” so objects don’t push through walls.
Two key ideas explained simply
- Application-Querying (A-Q): Instead of asking an AI to “guess” the hidden side of an object from just a tiny cut-out, A-Q shows the full room next to the cut-out. It’s like asking an artist to redraw a blocked part of a chair while letting them look at the whole photo for clues about lighting, style, and perspective. This produces complete, high-quality object images that are perfect for 3D modeling.
- 4-DoF floor alignment: “DoF” means “degrees of freedom,” or ways an object can move. The system uses a special 4-DoF mode for objects that sit on the floor. Imagine sliding a toy on a flat table: it can move left-right and forward-back, spin around vertically, and get slightly bigger or smaller. But it can’t float up or tip unnaturally. By restricting movement to the floor plane, the system keeps furniture grounded and physically believable.
What did they find?
- Better 3D accuracy and layout: In tests, 3D-RE-GEN outperformed two strong research methods on standard 3D metrics. It produced cleaner geometry, better object placement, and fewer “weird” outliers.
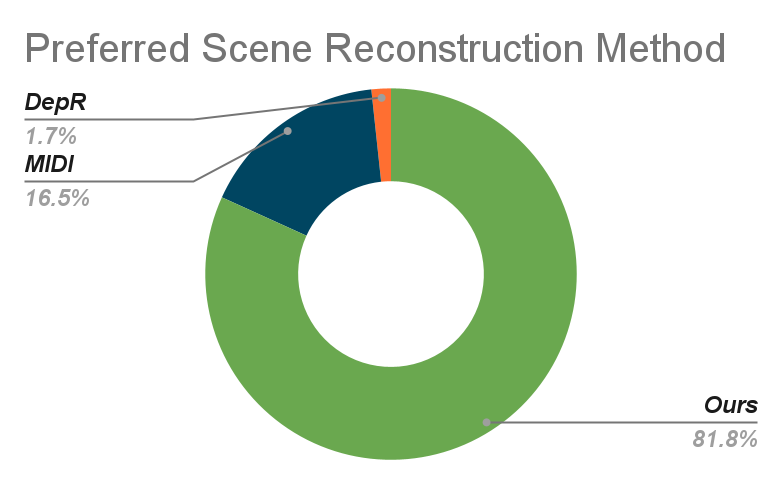
- People preferred its results: In a small study with 59 participants, 81% preferred scenes produced by 3D-RE-GEN, mainly because the layout and composition looked more correct.
- Each new idea clearly helps:
- Without A-Q, objects are often incomplete or look wrong, and the background is missing.
- Without the 4-DoF floor constraint, objects can “float” or drift from the correct perspective.
- With both, scenes look coherent, with grounded furniture and a usable, textured background.
- Production-friendly assets: The output includes a reconstructed background and separate textured meshes for each object, which is exactly what artists need for VFX and games. Lighting and physics also work better because the floor and walls are properly reconstructed.
Why does this matter?
- Speed and accessibility: Building a 3D scene by hand can take days. This system can turn a single image into a usable, editable 3D scene in minutes, dramatically speeding up creative work in film, TV, AR/VR, and games.
- Physical realism: The floor alignment and background creation make scenes more believable, which helps with realistic shadows, lighting, and simulations.
- Modular and future-proof: The system plugs together several existing AI tools. As those tools improve, the whole pipeline can get better without retraining everything from scratch.
- Better creative control: Because it outputs separate objects and a clean background, artists can tweak, move, and reuse assets easily, rather than being stuck with a single baked-in scene.
In short, 3D-RE-GEN shows that combining strong existing AI models with smart guidance—context-aware inpainting and floor-aware placement—can turn a single photo into a high-quality 3D scene that looks right and is ready for real creative work.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, consolidated list of what remains missing, uncertain, or unexplored in the paper, formulated to guide future research efforts.
- Automated mask quality control: The pipeline depends critically on GroundedSAM and manual mask refinement, but provides no automatic QA checks, uncertainty estimates, or recovery strategies for erroneous or incomplete object and floor masks.
- Floor mask derivation: The method requires a floor mask to decide between 4-DoF and 5-DoF models, yet the paper does not specify how the floor mask is obtained or validated, nor how decisions are made when the floor is heavily occluded or visually ambiguous.
- Camera recovery accuracy: VGGT-based camera estimation is central but unvalidated—no per-scene or per-object camera intrinsics/extrinsics error analysis, sensitivity to lens distortion, rolling-shutter artifacts, focal length estimation errors, or robustness to clutter/low light is provided.
- Absolute scale recovery: The evaluation normalizes point clouds to unit scale, obscuring whether the system can recover metric-accurate sizes. How to recover absolute scale reliably from a single image remains an open problem for production workflows.
- Background geometry fidelity: The “empty room” inpainting followed by point-cloud meshing yields a background mesh, but the geometric accuracy (e.g., surface flatness, wall alignment, door/window openings, ceiling height) is not measured against ground truth.
- Background texture/material fidelity: The paper does not evaluate the photometric realism and material correctness (e.g., albedo, roughness, normal maps) of the reconstructed background, despite claiming VFX-readiness.
- A-Q prompt robustness and generality: Application-Querying relies on a UI-style visual prompt for an image-editing model; the paper lacks a formal specification of the prompt design, quantitative robustness tests to prompt variations, and generalization across different editing models or object categories.
- Occlusion severity handling: There is no quantitative study of A-Q performance versus occlusion level (e.g., percent visible), nor failure mode characterization when contextual cues are weak or misleading.
- Object category coverage: The pipeline’s performance on deformable, transparent/reflective, thin-structure, or highly articulated objects (e.g., plants, textiles, glass, mirrors) is untested, raising questions about generalization beyond rigid furniture.
- Pose degrees of freedom limitations: Ground-aligned objects optimize only yaw (no pitch/roll) and uniform scale; this restricts realistic placement for tilted objects, sloped/uneven floors, or items that naturally require non-uniform scaling and full 6-DoF.
- Multi-support surfaces: The 4-DoF planar constraint targets floor contact only; there is no mechanism to detect and align objects to other support surfaces (e.g., tables, shelves, counters), nor to transition between multiple planes within a single scene.
- Inter-object physical reasoning: The optimization includes only a background bounding-box constraint (X/Z), ignoring object–object collisions, contact constraints, and support relationships (e.g., a lamp on a table), resulting in potential interpenetrations and physically implausible layouts.
- Collision handling with background geometry: The background bounding box loss does not prevent intersections with walls or furniture meshes; a general collision/contact penalty with background surfaces is missing.
- Joint scene-level optimization: Objects appear to be optimized individually; the paper does not explore global, joint optimization across all assets to enforce mutual spatial constraints, reduce error accumulation, or improve layout coherence.
- Sensitivity to VGGT point-cloud errors: Target object point clouds are derived by back-projection from VGGT; the pipeline does not quantify sensitivity to noise or misalignment in these point clouds, nor propose mitigation when geometry transformers fail.
- Lighting consistency and estimation: Claims of “consistent lighting” are not backed by an explicit light estimation module or evaluation; there is no measurement of whether reconstructed material/geometry supports realistic relighting in downstream renderers.
- Texture/material evaluation: While textured meshes are produced, there is no quantitative evaluation of texture fidelity (e.g., PSNR/SSIM on textures, material parameter accuracy) or comparisons of different 2D-to-3D generators’ material quality.
- Dataset and benchmark rigor: The evaluation uses hand-picked CGTrader scenes and a small human study (n=59), lacking standardized benchmarks, ablation on diverse public datasets (e.g., 3D-FRONT/ScanNet variants), and statistical significance testing.
- Per-object pose metrics: Metrics are reported at scene level after ICP alignment and normalization; per-object pose error (translation/rotation), contact accuracy, and support classification accuracy are not measured.
- Background accuracy benchmarking: No separate background-only benchmark (e.g., surface normal error, plane detection accuracy, wall/ceiling alignment metrics) is provided to validate the foundation of the scene assembly.
- Outdoor and non-indoor generalization: Despite a single outdoor example, the method is framed for indoor scenes; systematic evaluation for outdoor scenes, multi-room views, large spaces, and complex architectural features is missing.
- Scalability to large scenes: Runtime and memory analysis focuses on ~10 objects; there is no study of scaling to dozens of objects, long-tail categories, or complex clutter, nor strategies for batching/streaming optimization at scale.
- Robustness to domain shifts: The pipeline stitches multiple off-the-shelf components; there is no analysis of robustness to updates in those models, domain shifts (e.g., monochrome, stylized, low-light, motion blur), or fallback strategies when a component fails.
- Reproducibility and release: The paper does not state whether code, prompts, model configurations, and evaluation data are released; without them, reproducing A-Q behavior and scene metrics remains challenging.
- Failure modes and diagnostics: The system lacks automated failure detection, uncertainty reporting, and user guidance when floor detection fails, masks are poor, or optimization gets stuck in local minima.
- Optimization strategy details: Composite loss weights and scheduling are not specified; adaptive weighting, curriculum strategies, and differentiable renderer gradient stability (e.g., silhouette jitter, mesh self-occlusions) are not studied.
- Material and physics for downstream VFX: Although targeting VFX, the pipeline does not estimate physical properties (mass, friction) or validate dynamic stability, nor address material parameter consistency needed for physically based rendering pipelines.
- Multi-view and temporal extension: The approach is single-view; open questions include extending to multi-view inputs, leveraging video for temporal consistency, and improving scale/pose with cross-view constraints.
- Support for complex floor geometry: Plane fitting via RANSAC from target points may fail on non-flat floors, carpets with height variation, steps, or curved surfaces; methods for multi-plane segmentation or non-planar support estimation are needed.
- Non-uniform scale and deformation: Uniform scaling in optimization may be insufficient for assets whose perceived dimensions differ along axes (e.g., perspective distortions); incorporating shape deformation or category priors is unexplored.
- Fairness of baselines: MIDI and DepR are evaluated with their own mask pipelines and without texture in MIDI; fairness and comparability (e.g., harmonized masking, texture handling, identical camera recovery) are not rigorously controlled.
Practical Applications
Immediate Applications
Below are actionable, sector-linked use cases that can be deployed with the paper’s current framework and reported performance characteristics.
- Photo-to-3D scene conversion for previsualization and set dressing (VFX, games)
- Workflow: Import a single reference image; auto-segment assets and background; generate textured meshes; recover camera; assemble in Blender/Unreal/Unity for lighting, shadows, and physics.
- Tools/products: Blender/Unreal plugins, a “Concept-to-Scene” previsualization tool, batch converters for mood boards.
- Assumptions/dependencies: High-quality masks (GroundedSAM) and successful A-Q inpainting; GPU availability (single scene ~7–20 minutes, multi-GPU preferred); licensing/usage rights for source imagery; indoor-centric scenes.
- Rapid environment layout from concept art for indie and AA game pipelines (games)
- Workflow: Use 3D-RE-GEN to create a first-pass, modifiable level from art boards; rely on the 4-DoF alignment to minimize manual grounding fixes; iterate on topology and textures.
- Tools/products: Asset importers producing .obj/.fbx with UVs/textures; per-object placement editors; silhouette/point-cloud guided auto-alignment.
- Assumptions/dependencies: Object scale is approximate; manual refinement may still be needed; generative assets may hallucinate occluded geometry.
- Camera recovery and matchmoving for compositing (VFX)
- Workflow: Recover camera intrinsics/extrinsics via VGGT; use reconstructed background mesh to anchor CG elements, shadows, and bounces in the original plate.
- Tools/products: “Matchmove from single image” plugin; physical plausibility checks via 4-DoF floor alignment.
- Assumptions/dependencies: Accurate camera recovery depends on background quality; indoor scenes yield best results; failure cases if A-Q prompt not well-formed.
- Virtual staging and decluttering of real-estate photos (real estate, advertising)
- Workflow: Remove foreground objects via A-Q; produce “empty room” background mesh and camera; restage with furniture catalog assets; render marketing visuals.
- Tools/products: Cloud service or broker portal plugin; background-only export; staging presets.
- Assumptions/dependencies: Mask and inpainting quality critical; dimensions are not guaranteed to be metric—requires calibration if scale accuracy is needed.
- Catalog-to-3D asset generation and placement for retail visuals (e-commerce, advertising)
- Workflow: Convert product images to textured meshes; place them into reconstructed scenes while preserving perspective and lighting context.
- Tools/products: “Photo-to-Product-3D” pipeline; web 3D viewers; batch processing tools.
- Assumptions/dependencies: Legal rights to convert catalog images; generative 3D fidelity varies across categories; texture correctness may need QA.
- Synthetic dataset generation for 3D perception research (academia, software)
- Workflow: Use single images to build coherent, labeled indoor scenes (meshes + masks + camera) for benchmarking and training (Chamfer/F-Score/IOU-ready).
- Tools/products: Dataset builder scripts; silhouette and 3D geometric loss supervision exports.
- Assumptions/dependencies: Domain bias toward indoor scenes; geometry is plausible rather than metrically exact; occlusions resolved through generative inpainting (potential hallucinations).
- Context-aware generative editing via Application-Querying prompt construction (software, creative tools)
- Workflow: Adopt the UI-style composite prompt to improve completion of occluded objects and consistent materials/lighting.
- Tools/products: A-Q prompt builder libraries for image editors; “multi-panel prompt” templates and exporters.
- Assumptions/dependencies: Works best with high-quality segmentation and visual context; depends on image-editing model (e.g., Google Image Flash) capabilities and licensing.
- Robotics and simulation scene generation for domain randomization (robotics, simulation)
- Workflow: Create plausible indoor environments quickly for sim testing (Isaac Sim/Gazebo), leveraging physically grounded floor alignment.
- Tools/products: Simulation-ready exports with static collision meshes; procedural perturbation scripts.
- Assumptions/dependencies: Not metrically accurate by default; scaling and material properties require calibration; dynamic affordances not modeled.
- Teaching modules on differentiable rendering and physically constrained optimization (education)
- Workflow: Use the pipeline to demonstrate silhouette/point-cloud losses, differentiable rendering, and 4-DoF planar constraints in classroom labs.
- Tools/products: PyTorch3D-based lab notebooks; ablation exercises (No A-Q, No 4-DoF).
- Assumptions/dependencies: GPU access; familiarity with DCC tools and fundamentals of 3D geometry.
- Claims assessment prototypes for home damage visualization (insurance)
- Workflow: Convert single images of incidents into approximate 3D scenes; annotate damage locations and plan repair visuals.
- Tools/products: Adjuster-facing visualization portal; scene comparison tools pre/post repair.
- Assumptions/dependencies: Reconstructed geometry is approximate; risk of hallucination in occluded regions; careful disclaimers and human-in-the-loop validation needed.
Long-Term Applications
These use cases will benefit from further research, scaling, or development to meet reliability, performance, and compliance requirements.
- Mobile/on-device photo-to-3D with lightweight models (software, consumer apps)
- Potential product/workflow: A smartphone app that reconstructs rooms from a single shot for quick décor planning.
- Dependencies: Replace heavy components (e.g., Hunyuan3D 2.0) with lighter recon models; robust A-Q on-device; privacy-preserving pipelines; energy-efficient inference.
- Multi-view/video integration for metric accuracy and robustness (VFX, robotics, architecture)
- Potential product/workflow: Combine SLAM or structure-from-motion with the compositional pipeline to reduce hallucinations and recover scale.
- Dependencies: Temporal consistency, cross-frame constraints, semantic map fusion; improved plane segmentation beyond floors.
- Outdoor and complex multi-plane generalization (urban planning, public safety, GIS)
- Potential product/workflow: Street-scene reconstruction from a single photo with curb/sidewalk/road plane constraints and multi-surface alignment.
- Dependencies: Generalized 4-DoF-to-n-DoF constraints across sloped surfaces; robust background recovery in cluttered outdoor domains; weather/lighting variability.
- Enterprise-grade digital twin bootstrapping from sparse imagery (AEC/FM, energy)
- Potential product/workflow: Initialize building twins from minimal photography; fill gaps via generative priors; refine with subsequent scans/sensors.
- Dependencies: Metric calibration using known references; semantic labeling (walls/doors/electrical); integration with BIM; scale and material fidelity.
- Automated building-code pre-checks and hazard screening from photos (policy, public safety)
- Potential product/workflow: Approximate geometry extraction to flag potential non-compliance (e.g., clearance, egress) before site visits.
- Dependencies: Metrically accurate reconstructions; standardized thresholds; auditability; regulatory acceptance and liabilities management.
- AR navigation and robot task planning from fast scene bootstraps (robotics, AR)
- Potential product/workflow: Create quick occupancy maps and floor-aware layouts from a single image to seed downstream planners.
- Dependencies: Reliable metric scaling, semantic object classes, contact point estimation beyond a floor plane, dynamic obstacle handling.
- Physics-aware scene editing and interaction modeling (games, simulation)
- Potential product/workflow: Extend from 4-DoF to contact-centric 6-DoF with friction/material models; enable accurate stacking, pushing, and constraints.
- Dependencies: Contact detection/penalty terms in differentiable optimization; material parameter estimation; validation against physical tests.
- Cloud services for large-scale content supply chains (media, e-commerce)
- Potential product/workflow: “Image-to-3D at scale” pipelines for catalog ingestion and scene creation with QA loops and texture normalization.
- Dependencies: Throughput optimization, multi-GPU orchestration, human-in-the-loop verification, IP/licensing compliance.
- Semantics-rich scene understanding for downstream AI (academia, software)
- Potential product/workflow: Use reconstructed scenes to train models on object relations, affordances, and layout reasoning.
- Dependencies: Reliable semantic tagging, standardized datasets, evaluation protocols, cross-domain generalization.
- Cultural heritage digitization from archival photos (museums, policy)
- Potential product/workflow: Approximate reconstructions for exhibits and exploration; integrate with expert curation.
- Dependencies: Uncertain geometry from old/low-quality images; potential necessity of multi-view aggregation; authenticity and provenance concerns.
Cross-cutting assumptions and dependencies
- Domain focus: Current strengths are indoor scenes; outdoor and highly complex geometries require extension.
- Generative uncertainty: Inpainting and object completion may hallucinate; use human-in-the-loop QA for safety-critical or compliance-sensitive applications.
- Scale/metric accuracy: By default, reconstructions are visually plausible rather than metrically exact; add calibration (e.g., known object sizes, fiducials) when needed.
- Compute and licensing: Heavy components (e.g., Hunyuan3D 2.0, Google Image Flash) need sufficient VRAM and may have usage restrictions; alternatives like SPAR3D can lower VRAM but may affect fidelity.
- Data rights and privacy: Ensure proper rights to process images and store generated 3D assets; consider on-prem/cloud policies and anonymization where applicable.
- Workflow integration: Success depends on DCC interoperability (.fbx/.obj + UVs), consistent camera recovery, and robust mask refinement; provide fallback/manual correction tools.
Glossary
- 2D to 3D generative model: A model that converts a single 2D image into a textured 3D object using learned priors. "we pass each image to a 2D to 3D generative model, generating separated and textured objects."
- 3D Geometric Loss (L3D): A loss term that enforces alignment between target 3D points and the surface of a transformed mesh. "These point clouds serve as the ground truth for our 3D geometric loss term "
- 4-DoF: Four degrees of freedom (planar translation, yaw, and uniform scale) used to constrain object placement on a ground plane. "a novel 4-DoF 'planar model'."
- 5-DoF: Five degrees of freedom (3D translation, yaw, and uniform scale) used to place free-floating objects. "alternating between a five degree of freedom (5-DoF) model for free floating objects"
- Ablation study: An experimental analysis that removes components to assess their impact on performance. "Ablation study. Comparing the complete 3D-RE-GEN model against 3D-RE-GEN without ground constraints (No 4-DoF); and against 3D-RE-GEN without Application-Querying model (No A-Q)."
- Application-Querying (A-Q): A GUI-style visual prompting technique that supplies scene context and task specification to an image editing model. "Input and output of the Application-Querying (A-Q) method."
- Back projection: Mapping 2D image regions back into 3D space using the estimated camera to recover corresponding 3D points. "By back projecting these masks into the 3D scene, we effectively stencil "
- Background Bounding Box: A spatial constraint derived from background geometry to prevent object penetration during optimization. "Background Bounding Box Loss ($L_{bbox$)}."
- Bounding Box IoU (BBOX-IOU): The intersection-over-union metric computed on bounding boxes to assess spatial overlap. "Bounding Box IoU (BBOX-IOU)"
- Chamfer Distance (CD): A symmetric distance between point sets used to quantify geometric similarity. "Chamfer Distance (CD)"
- Context Aware Object Inpainting: An inpainting method that leverages full-scene context to complete occluded object segments. "Context Aware Object Inpainting"
- Depth-guided conditioning: Conditioning generation on depth information to improve geometric consistency. "Depth-guided conditioning further enhances geometric consistency"
- Differentiable optimization: Gradient-based optimization over continuous parameters enabled by differentiable objectives. "a novel 4-DoF differentiable optimization"
- Differentiable renderer: A renderer that supports gradient computation with respect to scene parameters, enabling optimization. "a differentiable renderer implemented with PyTorch3D"
- Differentiable rendering: A rendering formulation that propagates gradients through the image formation process. "constrained optimization with differentiable rendering."
- Dice: A segmentation overlap measure used as a loss to compare silhouettes. "Dice and Focal loss to robustly handle class imbalance at object edges."
- F-score: The harmonic mean of precision and recall used to evaluate 3D reconstruction quality. "F-score"
- Focal loss: A loss function that emphasizes hard examples to address class imbalance in segmentation. "Dice and Focal loss"
- Grounded SAM: A text-driven instance segmentation framework combining grounding with the Segment Anything Model. "Grounded SAM \cite{renGroundedSAMAssembling2024} performs text based instance segmentation"
- Hausdorff distance: A metric capturing the maximum deviation between two point sets, highlighting outliers. "The Hausdorff distance~\cite{alibekovAdvancingPrecisionMultiPoint2025}"
- Hunyuan3D 2.0: A large-scale single-image 3D asset reconstruction model producing high-fidelity meshes. "Hunyuan3D 2.0 \cite{zhaoHunyuan3D20Scaling2025}"
- ICP algorithm: Iterative Closest Point algorithm for aligning point clouds via rigid transformations. "aligned using the ICP algorithm \cite{Besl_1992_ICP}"
- Instance segmentation: Pixel-wise segmentation that distinguishes individual object instances. "performs text based instance segmentation"
- Inpainting: Image completion technique that fills missing or occluded regions. "inpainting phase"
- Intersection over Union (IoU): An overlap metric between sets (e.g., masks) used to infer contact or intersection. "compute the 2D Intersection over Union (IoU)"
- LPIPS: Learned Perceptual Image Patch Similarity metric for measuring perceptual image similarity. "LPIPS \cite{huangMIDIMultiInstanceDiffusion2024, mengSceneGenSingleImage3D2025}"
- Meshing algorithm: A method that converts point clouds into polygonal meshes for rendering and simulation. "a meshing algorithm turns the aligned point cloud into a usable mesh"
- Oriented Bounding Box (OBB): A bounding box aligned to an object’s principal axes rather than global coordinates. "Oriented Bounding Box (OBB)"
- PlanarModel: The constrained optimization model enforcing ground-plane alignment with 4-DoF. "Our primary contribution for physically plausible scene assembly is the PlanarModel."
- Point cloud: A set of 3D points representing scene or object geometry. "scene point cloud"
- PyTorch3D: A PyTorch-based library for 3D rendering and geometry processing. "PyTorch3D"
- RANSAC: Robust estimation algorithm for fitting models (e.g., planes) in the presence of outliers. "using a robust RANSAC algorithm"
- RegularModel: The unconstrained 5-DoF pose optimization model used for non-grounded objects. "5-DoF RegularModel"
- Silhouette Loss (Lsilhouette): A loss that matches rendered object silhouettes to segmentation masks. "2D Silhouette Loss ($L_{silhouette$)}."
- SPAR3D: A lightweight single-image 3D reconstruction model alternative to heavier generators. "SPAR3D \cite{huangSPAR3DStablePointAware2025}"
- SSIM: Structural Similarity Index Measure for comparing images based on perceived quality. "SSIM and LPIPS \cite{huangMIDIMultiInstanceDiffusion2024, mengSceneGenSingleImage3D2025}"
- VGGT: A visual geometry transformer used for camera parameter estimation and point cloud reconstruction. "VGGT \cite{wangVGGTVisualGeometry} for camera parameter estimation and point cloud reconstruction."
- Yaw: Rotation around the vertical axis controlling an object’s heading. "1D yaw"
Collections
Sign up for free to add this paper to one or more collections.