WorldGrow: Generating Infinite 3D World
Abstract: We tackle the challenge of generating the infinitely extendable 3D world -- large, continuous environments with coherent geometry and realistic appearance. Existing methods face key challenges: 2D-lifting approaches suffer from geometric and appearance inconsistencies across views, 3D implicit representations are hard to scale up, and current 3D foundation models are mostly object-centric, limiting their applicability to scene-level generation. Our key insight is leveraging strong generation priors from pre-trained 3D models for structured scene block generation. To this end, we propose WorldGrow, a hierarchical framework for unbounded 3D scene synthesis. Our method features three core components: (1) a data curation pipeline that extracts high-quality scene blocks for training, making the 3D structured latent representations suitable for scene generation; (2) a 3D block inpainting mechanism that enables context-aware scene extension; and (3) a coarse-to-fine generation strategy that ensures both global layout plausibility and local geometric/textural fidelity. Evaluated on the large-scale 3D-FRONT dataset, WorldGrow achieves SOTA performance in geometry reconstruction, while uniquely supporting infinite scene generation with photorealistic and structurally consistent outputs. These results highlight its capability for constructing large-scale virtual environments and potential for building future world models.







Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper introduces WorldGrow, a computer system that can create huge, never‑ending 3D worlds that look realistic and make sense to explore. Think of building a giant virtual city or a whole building that keeps expanding as you walk—WorldGrow makes that possible by creating the world piece by piece while keeping everything connected and believable.
What questions does the paper try to answer?
The authors focus on three big challenges:
- How can we generate very large 3D environments that can keep growing without hitting a limit?
- How can we keep the geometry (shapes and structures) and appearance (textures and colors) consistent across all parts of the world?
- How can we use powerful 3D tools that are good at making single objects (like a chair) to instead make full scenes (like an entire room, house, or city)?
How does WorldGrow work?
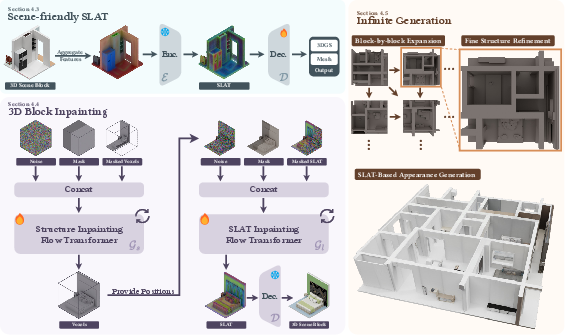
To explain the method, imagine building a world like you build with LEGO: one block at a time, making sure each new block fits perfectly with the ones already placed. WorldGrow does this with four key ideas.
1) Training data: slicing scenes into blocks
- The team takes real 3D scenes (for example, house interiors) and cuts them into many small, well‑aligned “blocks,” like floor tiles.
- They create two kinds of blocks:
- Coarse blocks: larger tiles that are good for planning the overall layout (where rooms and hallways go).
- Fine blocks: smaller tiles that are good for adding detailed shapes and textures (like furniture edges and floor patterns).
This gives the system examples to learn how to build both the big picture and the fine details.
2) A scene‑friendly 3D “language” (SLAT) that avoids mistakes
- WorldGrow uses a compact 3D representation called a structured latent (you can think of it as a short recipe that describes a 3D block).
- Standard versions of this representation were trained on single objects, which can cause problems in busy scenes (like colors bleeding between a wall and a sofa, or messy edges).
- The authors fix this in two ways:
- Occlusion‑aware features: when something blocks the view of something else (like a table blocking part of a chair), the system handles it more carefully, so features don’t get mixed up.
- Retrained decoder for scenes: they retrain the part that turns the recipe back into 3D, so it understands blocks with edges and boundaries, avoiding “floaters” or broken seams between blocks.
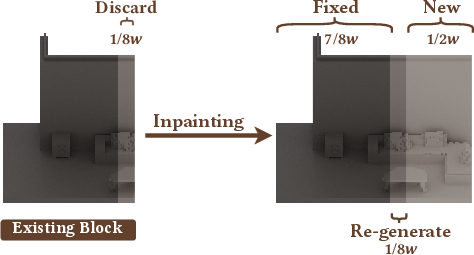
3) 3D block “inpainting”: filling in missing pieces
- Inpainting means filling in a missing area using the surrounding context—like finishing a jigsaw puzzle by looking at the pieces around the hole.
- For each new block, the system looks at the neighboring blocks (left, above, and top‑left), then fills in the missing space so the new block matches perfectly with its neighbors.
- The model works in two passes:
- First, it predicts the structure (where surfaces should be).
- Second, it adds the appearance (colors and textures).
- It uses overlapping borders between blocks—like a sliding window that overlaps—to keep seams smooth and transitions natural.
4) Coarse‑to‑fine generation: sketch first, then detail
- Step 1: Lay out the big structure with the coarse model (like sketching a floor plan).
- Step 2: Refine with the fine model (like painting in texture and small shapes).
- This two‑step process keeps the global layout logical while the details still look crisp and realistic.
What did they find, and why is it important?
The authors tested WorldGrow on a large dataset of 3D houses and compared it with other methods. Here’s what stood out:
- Better geometry: Walls, floors, furniture, and room layouts fit together more accurately than other systems.
- Better appearance: Textures and colors look more realistic and stay consistent when you move around the scene.
- Seamless growth: The world can keep expanding block by block without obvious seams or glitches.
- Scales to very large scenes: They show worlds with up to 19×39 blocks (about 1,800 square meters) that still look coherent.
- People prefer it: In user studies, participants rated WorldGrow higher for structure, detail, appearance, and continuity.
- Practical performance: It’s relatively fast and memory‑efficient—about 20 seconds per block on a single high‑end GPU, and a 10×10 indoor scene in about 30 minutes—faster than some alternatives.
Why this matters:
- Big, consistent 3D worlds are essential for video games, VR/AR, movies, and architecture.
- They’re also crucial for training “embodied” AI agents that learn by moving around and interacting with the world.
What’s the bigger impact?
WorldGrow shows a practical path to building huge, coherent 3D environments automatically. This can:
- Speed up content creation for games and films.
- Provide endless, varied training grounds for AI agents that need to learn navigation, planning, and interaction.
- Push forward “world models,” where AI learns from simulated worlds that feel real and never run out of space.
The authors also note future directions:
- Expanding vertically (more floors and full buildings, not just on a flat plane).
- Training with larger and more diverse datasets (especially outdoor scenes).
- Adding more control, like telling the system “put a kitchen here” or “make a park there” using natural language.
In short, WorldGrow combines strong 3D generation smarts with a clever block‑by‑block, sketch‑then‑detail strategy, making it possible to grow realistic 3D worlds without limits.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise, actionable list of what remains missing, uncertain, or unexplored in the paper, to guide future research.
Data, training, and evaluation
- Lack of standardized benchmarks for “infinite” 3D scene generation: no widely accepted metrics for continuity, loop closure consistency, or long-range drift beyond local block metrics and user studies.
- Limited quantitative evaluation for very large worlds: results shown up to 19×39 blocks, but no stress testing at much larger scales (e.g., hundreds or thousands of blocks), no drift/consistency curves vs. expansion distance, and no loop-closure tests (e.g., returning to an origin).
- Sparse evaluation for outdoor domains: only qualitative results on UrbanScene3D; no quantitative geometry or perceptual metrics, nor cross-domain generalization analysis.
- Embodied-AI suitability not quantitatively assessed: no measurements of traversability (e.g., free-space ratio, path success rate, SPL), reachability graphs, or collision statistics in generated scenes.
- No analysis of scene layout validity against functional/semantic priors (e.g., room-type adjacency matrices, door connectivity, minimum clearance rules), beyond qualitative examples.
- Visual evaluation depends heavily on rendered blocks and user studies; no standardized measures of multi-view consistency across long camera trajectories or off-context viewpoints.
- Fairness of comparisons to geometry-only baselines: FID/CLIP reported on white-textured renders may disadvantage geometry-only methods; an agreed-upon protocol is missing.
- Limited ablations on masking/inpainting regimes: no sensitivity study on mask shapes, sizes, overlap ratios, or different context topologies (beyond quadrant masking), which could affect boundary continuity.
- Dataset curation bias is unquantified: slicing thresholds (e.g., ≥95% occupancy), manual filtering, and Blender-based intersection may bias content toward dense, clean blocks; no study of how curation choices influence generalization/diversity.
Methodological limitations
- Expansion restricted to the XY plane: no support for vertical (Z-axis) growth; multi-story buildings, mezzanines, and terrain elevation changes remain unsolved.
- Local-only context during block growth: inpainting uses immediate neighbors (left/top/top-left); no global planning or memory to enforce long-range structural coherence, symmetry, or periodicity over large extents.
- Overwrite-at-boundary strategy: discarding and re-generating overlapping 1/8-width regions may introduce content instability and non-determinism; no analysis of persistence or temporal consistency when repeatedly revisiting boundaries.
- Fixed-size, axis-aligned rectangular tiling: no adaptive/resolution-aware block sizing, rotation, or irregular tiling to follow semantic or architectural boundaries (e.g., rooms, streets, parcels).
- Limited conditioning/control: experiments use a fixed generic text prompt; no support demonstrated for floorplans, style tags, semantic layout graphs, or programmatic constraints (e.g., “bedroom next to bathroom”).
- Absence of semantic understanding: no room/asset labels or semantics are generated; cannot query or edit scenes at semantic granularity.
- Scene-friendly SLAT remains geometry/appearance-decoupled and object-derived: no unified geometry-appearance latent (e.g., UniLat3D-style) integration evaluated for improved efficiency or fidelity at scene scale.
- Occlusion-aware feature aggregation and decoder retraining are introduced, but the approach still relies on object-centric priors; it is unclear how well SLATs capture complex scene occlusion, thin structures, or clutter at large scales.
- Limited context encoding in inpainting: concatenation of noisy latents, binary masks, and partial latents may be insufficient for capturing rich cross-block dependencies; alternatives (cross-attention to larger context windows, memory tokens, or hierarchical context maps) are unexplored.
- No explicit constraints for physical/architectural plausibility: collision avoidance, minimum clearance, connectivity through doors, structural support, and manifoldness/watertightness are not enforced or measured.
- Materials and rendering realism under-specified: no PBR/material parameter generation, illumination control, or global lighting consistency; the output representation used for long-run interactive rendering is not fully characterized.
Scalability, efficiency, and system aspects
- Inference cost scales linearly with number of blocks; no amortization, caching, or streaming mechanisms are proposed for interactive or real-time world growth.
- Memory/time scaling beyond 10×10 blocks is not profiled; no GPU/CPU trade-off analysis, distributed inference strategy, or batching techniques for large-scale deployment.
- No mechanism for loop closure or global correction (SLAM-like refinement) to mitigate cumulative errors after long expansions.
- No deduplication/anti-repetition mechanism: risk of mode repetition or tiling artifacts is not analyzed; no diversity metrics reported across large worlds or repeated generations.
- No editing and re-generation pipeline: local edits (e.g., user moves a wall) and their propagation to neighboring blocks are unsupported; incremental updates without full re-generation are not addressed.
Generalization and robustness
- Cross-dataset/domain generalization missing: models are primarily trained and evaluated on curated 3D-FRONT; robustness to different distributions (e.g., ScanNet, Matterport3D, large outdoor CAD/GIS) is unknown.
- Robustness to noisy or incomplete training scenes untested: how sensitive are learned priors to imperfect meshes, sparse textures, or real-world sensor artifacts?
- Style and cultural diversity are not studied: interiors and urban forms vary globally; no experiments on transferring or controlling stylistic distributions, nor on mixed-domain training.
- Failure modes under OOD prompts/contexts not characterized: although textual conditioning is minimal, future semantic conditioning will need robustness checks (e.g., rare room types, unusual layouts).
Embodied AI utility and downstream integration
- No proof-of-use in embodied tasks: navigation, exploration, mapping, or planning agents are not benchmarked to quantify how generated worlds affect learning or generalization.
- Dynamics and interactivity are absent: no support for movable objects, agents, or time-varying scenes; integration with physics engines or simulation frameworks remains unexplored.
- Lack of scene graphs or affordance annotations: generated worlds are not accompanied by semantics needed for task planning, affordance learning, or object-goal navigation.
Open research directions
- Vertical and multi-level generation: algorithms for Z-axis growth, stair/shaft placement, multi-story constraints, and terrain-aware outdoor synthesis.
- Global layout planning: hybrid approaches that couple local inpainting with a global planner (e.g., graph/transformer over block indices) for long-range coherence and loop closure.
- Semantic and constraint-based control: conditioning on floorplans, programmatic constraints, scene graphs, or LLM-generated plans; interactive editing with consistency-preserving updates.
- Unified geometry-appearance-material modeling: joint latent spaces with PBR materials and lighting control; consistent illumination across large worlds.
- Robust, scalable evaluation: metrics for continuity, loop closure, drift, traversability, and multi-view consistency over long trajectories; public benchmarks and protocols for “infinite” 3D generation.
- Efficiency and deployment: streaming generation, on-the-fly caching, distributed inference, and real-time expansion suitable for games/VR/robotics.
- Dataset scale and diversity: large curated scene-block corpora across indoor/outdoor domains with semantics and constraints; studies on curation bias and generalization.
Practical Applications
Overview
The paper introduces WorldGrow, a block-wise, coarse-to-fine framework for generating infinite 3D worlds with coherent geometry and photorealistic appearance. It adapts object-centric 3D generative priors (Structured Latents, SLAT) to scene blocks via occlusion-aware feature aggregation and a retrained decoder, and extends scenes using a 3D block inpainting mechanism with overlapping context windows. Evaluations show state-of-the-art geometry and visual fidelity on 3D-FRONT and stability during long-run expansion, with preliminary results on outdoor urban scenes.
Below are practical applications derived from these findings, organized into immediate and long-term categories.
Immediate Applications
These are deployable now with the methods, tools, and performance demonstrated in the paper.
- Procedural level design and rapid world prototyping for games and VR/AR [sector: gaming, software, XR]
- Use WorldGrow as a “layout-first, detail-later” world builder to auto-generate large, traversable indoor environments; export meshes/SLAT-decoded assets into engines (Unity/Unreal) for blocking, exploration, and gameplay iteration.
- Potential tools/workflows: WorldGrow Editor plugin (seed → coarse structure → fine refinement → texture decoding), block inpainting API for incremental extension, engine-side collider generation.
- Assumptions/dependencies: GPU resources (~13 GB peak; ~20 s/block), PBR/material conversion and physics colliders, domain-specific fine-tuning for stylistic control, current focus on XY expansion and indoor data (3D-FRONT).
- Embodied AI training environments for navigation, planning, and world-model research [sector: robotics, AI/ML]
- Generate large-scale, coherent worlds to train and evaluate embodied agents (e.g., long-horizon navigation, map-building, planning) without manual modeling; leverage “expansion stability” for benchmarking.
- Potential tools/workflows: Synthetic data engine (multi-view rendering + ground-truth geometry), curriculum generation via block-by-block growth, Habitat-like integration for agent evaluation.
- Assumptions/dependencies: Physics colliders and traversability checks required; minimal semantic conditioning in current implementation (generic text prompt); domain randomization may be needed for sim-to-real transfer.
- Film/VFX previsualization, set blocking, and camera path testing [sector: film/VFX]
- Rapidly synthesize extensive interior sets with coherent layouts for previs, camera studies, and lighting tests; swap details quickly via inpainting rather than rebuilding scenes.
- Potential tools/workflows: Blender import, camera path generation over consistent multiview renders, coarse-to-fine iteration to align blocking and art direction.
- Assumptions/dependencies: Style control limited; requires material and lighting adaptation; quality depends on training dataset domain.
- Interior design and real-estate staging ideation [sector: AEC, real estate]
- Produce multiple layout variants for apartments/houses; use coarse stage to explore structural arrangements and fine stage to preview textures/furnishings.
- Potential tools/workflows: CAD/glTF export, Blender-to-BIM bridge, inpainting to replace rooms/furniture without redrawing.
- Assumptions/dependencies: Domain-specific furniture/style priors; current XY-only growth (no multi-story); needs adherence checks to real-world dimensions and code constraints.
- 3D scene completion and scan repair via block inpainting [sector: AEC, cultural heritage, 3D scanning]
- Fill missing regions in partial scans by masking and inpainting blocks with context-aware geometry and texture synthesis; reduce manual cleanup.
- Potential tools/workflows: Scan-to-block slicing (paper’s Blender Boolean pipeline), masked inpainting with structure-first then latent decoding.
- Assumptions/dependencies: Fine-tuning on scanned data improves fidelity; accurate masks and alignment required; edge artifacts reduced by overlap but still need QA.
- Synthetic data generation for 3D vision research [sector: academia]
- Generate large, diverse, label-rich datasets (multi-view renders + meshes) for training 3D reconstruction, SLAM, layout estimation, and segmentation models.
- Potential tools/workflows: Render pipelines with fixed viewpoints, metrics such as FID/CLIP for quality gating, distribution-matched sampling (as in paper’s evaluation).
- Assumptions/dependencies: Licensing for training data and derived assets; domain bias from 3D-FRONT; semantic annotations may need external tooling.
- Early-stage urban streetscape ideation (block-level) [sector: urban planning, XR]
- Adapt the pipeline to UrbanScene3D-like data for plausible streetscapes and neighborhood blocks suitable for walkable demos and basic path-planning tests.
- Potential tools/workflows: Scene slicing of city meshes, coarse-to-fine generation of block sequences, walkability overlays.
- Assumptions/dependencies: Outdoor datasets and priors required; dynamic traffic and vertical layering not included; limited policy constraints.
- World-model agent benchmarking and reproducible evaluation suites [sector: academia, AI/ML]
- Use the block-by-block growth and overlap design to create standardized benchmarks that test long-run coherence, drift, and continuity for agents learning world models.
- Potential tools/workflows: Expansion stability metrics (outer-region evaluation), reproducible seeds and growth patterns, agent challenge tasks with increasing spatial extents.
- Assumptions/dependencies: Agreement on benchmark protocols; compute for large environments; limited semantic control in current setup.
Long-Term Applications
These require additional research, scaling, semantic control, vertical expansion, or integration with physics and policy constraints.
- City-scale, dynamic autonomy simulation (AV/robotics) [sector: robotics, transportation]
- Generate photorealistic, semantically annotated, and dynamic urban environments (traffic, pedestrians, weather/time-of-day) for long-horizon autonomy training.
- Potential tools/products: WorldGrow-Drive (city-scale generator + traffic/physics engine), streaming world server, domain randomization suites.
- Assumptions/dependencies: Large outdoor datasets, robust semantic control via LLMs/scene graphs, physics integration (vehicles, collisions), validated realism for safety-critical training.
- Multi-story and vertical expansion for complete buildings and campuses [sector: AEC, XR]
- Extend growth along the Z-axis to synthesize multi-level buildings with stairways/elevators and inter-floor coherence; campus-scale compositions with vertical constraints.
- Potential tools/products: Multi-level generator with “floor-by-floor” controls, BIM export, code-compliance checks.
- Assumptions/dependencies: New data curation for vertical structures, multi-level constraints (e.g., egress), stronger structural priors.
- Semantically controlled, code-compliant building generation (LLM + constraints) [sector: architecture, policy/regulation]
- Integrate LLMs to specify room types, adjacencies, accessibility, egress, and building codes; enforce constraints during structure generation.
- Potential tools/products: Code-aware prompt-to-world pipelines, rule engines for ADA/fire codes, compliance validators.
- Assumptions/dependencies: Reliable constraint satisfaction mechanisms, rich semantic datasets, human-in-the-loop review.
- Persistent, personalized metaverse/worlds-as-a-service [sector: consumer XR, software]
- Offer on-demand infinite worlds with user preferences (style, layout, themes), collaborative multi-user experiences, and continuous content streaming.
- Potential tools/products: WorldGrow Cloud (scalable generation/streaming), profile-driven world personalization, moderation tools.
- Assumptions/dependencies: Scalable inference and streaming (edge/cloud), content moderation, user safety and privacy policies.
- Digital twins for facility planning, maintenance, and energy modeling [sector: energy, AEC, operations]
- Generate high-level geometry and refine materials to feed energy simulation tools (HVAC, daylighting), maintenance training, and layout optimization.
- Potential tools/products: WorldGrow-to-BIM/IFC converter, energy simulation adapters (EnergyPlus), maintenance training scenarios.
- Assumptions/dependencies: Accurate materials and physical properties, calibration to real buildings, integration with simulation engines.
- Emergency response and safety training simulators [sector: public safety, defense]
- Create diverse, evolving indoor scenarios for evacuation planning, hazard response, and search-and-rescue training at scale.
- Potential tools/products: Scenario generators with hazard injects, physics-based smoke/fire modules, evaluation analytics.
- Assumptions/dependencies: Dynamic event modeling, realism validation, coordination with training authorities and safety standards.
- World-model training infrastructure for open-ended agents [sector: AI/ML]
- Use infinite, coherent environments to study long-horizon reasoning, memory, and planning; scaffold curriculum via controlled growth patterns and semantics.
- Potential tools/products: Curriculum APIs (growth schedules, task injection), unified geometry+appearance latent models for efficiency (e.g., UniLat3D integration).
- Assumptions/dependencies: Larger, more diverse datasets, semantic controllability, compute scaling and efficient streaming.
- Real-time and mobile deployment for AR experiences [sector: mobile/XR]
- Optimize inference for consumer GPUs/edge devices to enable on-device generative AR worlds and context-aware inpainting.
- Potential tools/products: Quantized/accelerated models, progressive streaming, tile-based refinement.
- Assumptions/dependencies: Model compression, latency control, battery/thermal constraints.
- Marketplace and tooling ecosystem for generative scene assets [sector: software, creator economy]
- Commercialize WorldGrow as SDK/CLI with block inpainting, scene slicing, and coarse-to-fine pipelines; integrate with DCC tools (Blender, Maya) and game engines.
- Potential tools/products: Asset repair tools, world-seeding services, licensing/attribution workflows.
- Assumptions/dependencies: IP/licensing frameworks for generated content, cost control for cloud inference, integrations with existing pipelines.
- Generalized 3D content repair for scanning apps and robotics mapping [sector: software, robotics]
- Provide robust, domain-adapted inpainting to fill occlusions or missing map regions in SLAM/photogrammetry outputs while preserving consistency across tiles.
- Potential tools/products: On-device repair modules, ROS integration, confidence scoring.
- Assumptions/dependencies: Domain adaptation across sensors and environments, reliability metrics, user oversight.
Glossary
- 1-NNA (1-Nearest Neighbor Accuracy): A distribution similarity metric that measures overfitting by checking how often a sample’s nearest neighbor comes from the same set. Example: "we report three standard distribution-based metrics (MMD, COV, and 1-NNA) computed using both Chamfer Distance (CD) and Earth Mover's Distance (EMD)."
- 3D block inpainting: Completing missing 3D regions of a scene block using surrounding context to ensure continuity. Example: "we develop a 3D block inpainting pipeline to ensure robust and context-aware completion of missing blocks during iterative extension."
- 3D Gaussian Splatting (3DGS): A 3D representation/rendering technique using collections of Gaussian primitives for efficient, high-quality view synthesis. Example: "3D Gaussian Splatting (3DGS)\cite{3dgs}"
- 3D-FRONT: A large-scale dataset of indoor scenes used for 3D generation and reconstruction research. Example: "Evaluated on the large-scale 3D-FRONT dataset, WorldGrow achieves SOTA performance in geometry reconstruction"
- AdamW: An optimizer that decouples weight decay from the gradient update to improve training stability and generalization. Example: "using AdamW~\cite{adamw} with a learning rate of 0.0001"
- aliasing: Visual artifacts caused by insufficient sampling or discretization, leading to jagged or inconsistent appearance across views. Example: "they often suffer from geometric inaccuracies and appearance inconsistencies (e.g, aliasing or distortion)"
- Chamfer Distance (CD): A geometric distance between point sets measuring reconstruction accuracy by averaging nearest-neighbor distances. Example: "computed using both Chamfer Distance (CD) and Earth Mover's Distance (EMD)"
- CLIP score: A perceptual similarity measure using CLIP embeddings to assess alignment between images and semantics. Example: "compute perceptual metrics including CLIP score and FID variants"
- Coarse-to-fine generation: A strategy that first produces global layout at low resolution and then refines local details at higher resolution. Example: "a coarse-to-fine generation strategy that ensures both global layout plausibility and local geometric/textural fidelity."
- COV (Coverage): A distribution metric that measures the fraction of reference samples matched by generated samples. Example: "we report three standard distribution-based metrics (MMD, COV, and 1-NNA)"
- DINOv2: A self-supervised vision transformer model providing robust features for 3D encoding/decoding. Example: "with DINOv2 features~\cite{dinov2}"
- Earth Mover’s Distance (EMD): A metric that measures the minimal cost to transform one point set distribution into another. Example: "computed using both Chamfer Distance (CD) and Earth Mover's Distance (EMD)"
- Embodied AI: AI agents that act within environments via perception and control, often requiring navigation and interaction. Example: "embodied AI systems"
- Flow matching loss: A training objective aligning model predictions with the velocity field that transports noise to data along a continuous path. Example: "Both generators are optimized using a flow-matching loss:"
- Flow Transformer: A transformer model that learns to reverse a continuous noising process for structure and latent generation. Example: "Each stage uses a flow Transformer~\cite{flow2}"
- Fréchet Inception Distance (FID): A perceptual distribution metric comparing generated and real image features via Gaussian statistics. Example: "the perceptual Fréchet Inception Distance (FID)~\cite{fid}"
- Hadamard product: Element-wise multiplication between tensors or vectors. Example: " denotes the Hadamard product"
- LPIPS (Learned Perceptual Image Patch Similarity): A learned metric correlating with human perception of image similarity. Example: "LPIPS"
- MMD (Maximum Mean Discrepancy): A kernel-based statistical test measuring distance between two distributions. Example: "we report three standard distribution-based metrics (MMD, COV, and 1-NNA)"
- Occlusion-aware feature aggregation: A feature projection/aggregation method that accounts for visibility to reduce artifacts in cluttered scenes. Example: "we incorporate an occlusion-aware strategy during feature aggregation."
- Occupancy volume: A volumetric grid indicating which voxels are occupied, often compressed to a latent token set. Example: "a compressed occupancy volume."
- PointNet++: A deep architecture for learning hierarchies of features on point clouds, used here for 3D evaluation features. Example: "with PointNet++~\cite{pointnetpp} following the protocol in \cite{point-e}"
- Radiance fields: Continuous volumetric representations that model color and density to render novel views (e.g., NeRF). Example: "radiance fields~\cite{nerf}"
- SDEdit: A structure-preserving editing technique that denoises a noisy input to refine content while keeping coarse structure. Example: "inspired by SDEdit~\cite{sdedit}"
- SLAT (Structured LATents): A sparse 3D latent representation linking features to voxel positions for geometry/appearance generation. Example: "Structured LATents (SLAT)"
- Sparse voxel grids: Voxel representations storing only active (occupied) voxels to reduce memory and computation. Example: "encodes object shapes into sparse voxel grids"
- SOTA (State of the Art): The best reported performance among contemporary methods. Example: "achieves SOTA performance in geometry reconstruction"
- Structured Latent Representation: The formulation of linking latent features to spatial positions for 3D decoding. Example: "Structured Latent Representation."
- Trilinear interpolation: A method for upsampling 3D grids by interpolating values along three spatial axes. Example: "via trilinear interpolation"
- Triplane extrapolation: Extending a scene by predicting neighboring triplane features to synthesize adjacent content. Example: "employs triplane extrapolation to synthesize neighboring blocks."
- Triplanes: A 3D representation that factorizes features into three orthogonal 2D feature planes for efficient rendering. Example: "triplanes~\cite{eg3d,blockfusion}"
- TUDF (Truncated Unsigned Distance Field): A signed-distance-style field clipped to a truncation threshold for robust geometry modeling. Example: "Truncated Unsigned Distance Field (TUDF)~\cite{udf,tudfnerf,lt3sd}"
- UDFs (Unsigned Distance Fields): Functions giving the distance to the nearest surface without sign, used for geometry representation. Example: "UDFs~\cite{udf,tudfnerf,lt3sd}"
- VAE (Variational Autoencoder): A generative model with an encoder/decoder that learns a latent distribution for reconstruction. Example: "a Transformer-based variational autoencoder (VAE)~\cite{vae}"
- Voxel: A volumetric pixel representing a value on a 3D grid. Example: "active voxel centers "
- World Models: Generative models of environments enabling agents to plan and learn through simulated interaction. Example: "developing World Models and embodied AI systems"
Collections
Sign up for free to add this paper to one or more collections.