- The paper demonstrates that a frozen DINOv3 backbone combined with a minimal MLP decoder delivers state-of-the-art segmentation performance on diverse medical and natural image benchmarks.
- It achieves significant improvements in DSC, IoU, and HD95 metrics on datasets like TN3K, Kvasir-SEG, and MSD, outperforming more complex models.
- The efficient design with only 2.21M trainable parameters and 53 FPS inference makes SegDINO ideal for real-time, resource-constrained applications.
SegDINO: Efficient Medical and Natural Image Segmentation with DINOv3
Introduction
SegDINO presents a segmentation framework that leverages the representational power of a frozen DINOv3 Vision Transformer (ViT) backbone, coupled with a lightweight multi-layer perceptron (MLP) decoder. The motivation is to address the inefficiency and parameter overhead of existing segmentation approaches that adapt foundation models, particularly in resource-constrained or real-time settings. The design is predicated on the hypothesis that the rich, multi-scale features of DINOv3 can be effectively exploited for dense prediction tasks without the need for heavy, multi-stage decoders or complex upsampling modules.
Architecture and Methodology
SegDINO's architecture is characterized by a strict separation between a frozen, self-supervised DINOv3 encoder and a minimal, trainable decoder. The encoder processes the input image into patch tokens at multiple transformer layers, capturing both low-level and high-level semantics. Features from selected layers are upsampled to a common spatial resolution and channel width, concatenated, and then passed to a lightweight MLP head for mask prediction.
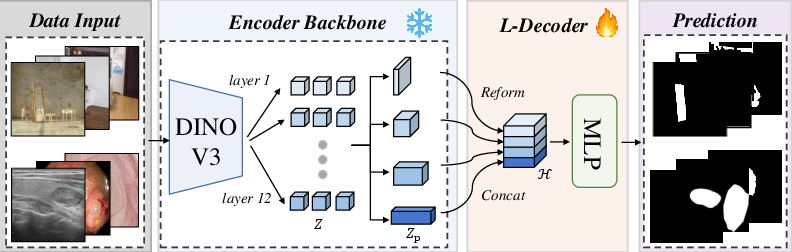
Figure 1: SegDINO couples a frozen DINOv3 with a lightweight decoder for efficient segmentation. Multi-layer features from different depths are upsampled, aligned, and concatenated, then passed to a super light MLP head to produce the final segmentation mask.
Key implementation details include:
- Frozen DINOv3-S Backbone: Only the decoder is updated during training, ensuring stability and efficiency.
- Multi-level Feature Extraction: Features are extracted from the 3rd, 6th, 9th, and 12th transformer layers, providing a rich multi-scale representation.
- Feature Alignment and Concatenation: All features are upsampled and channel-aligned before concatenation, following a reform strategy similar to prior ViT-based segmentation pipelines.
- Lightweight MLP Decoder: The decoder is a shallow MLP, minimizing trainable parameters and computational cost.
This design enables efficient adaptation of foundation model features to segmentation tasks, with the decoder acting as a simple, domain-specific mapping from foundation features to dense predictions.
Experimental Evaluation
SegDINO is evaluated on six benchmarks: three medical (TN3K, Kvasir-SEG, ISIC) and three natural image datasets (MSD, VMD-D, ViSha). The evaluation protocol uses standard metrics: Dice similarity coefficient (DSC), IoU, HD95 for medical images, and IoU, accuracy, Fβ, MAE, BER, S-BER, and N-BER for natural images.
Medical Image Segmentation
SegDINO achieves the highest DSC, IoU, and lowest HD95 across all three medical datasets. For example, on TN3K, SegDINO attains a DSC of 0.8318, outperforming TransUNet by +3% in DSC and +3.6% in IoU, while reducing HD95 by over 5 points. On Kvasir-SEG and ISIC, similar improvements are observed, with SegDINO consistently outperforming both convolutional and transformer-based baselines.
Natural Image Segmentation
On the MSD mirror segmentation dataset, SegDINO surpasses the next-best method by over 5% in IoU and Fβ. On VMD-D, it achieves a 19% relative gain in IoU over VMD-Net. On ViSha, SegDINO leads in all metrics, including a 2% improvement in Fβ and the lowest BER, S-BER, and N-BER.
Efficiency Analysis
SegDINO demonstrates a favorable trade-off between segmentation accuracy, parameter count, and inference speed. With only 2.21M trainable parameters, it achieves state-of-the-art performance on Kvasir-SEG and VMD-D. The inference speed reaches 53 FPS, outperforming most transformer-based models and approaching the efficiency of convolutional architectures.
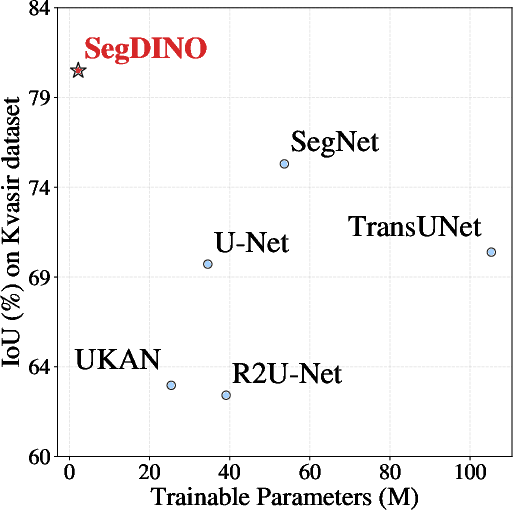
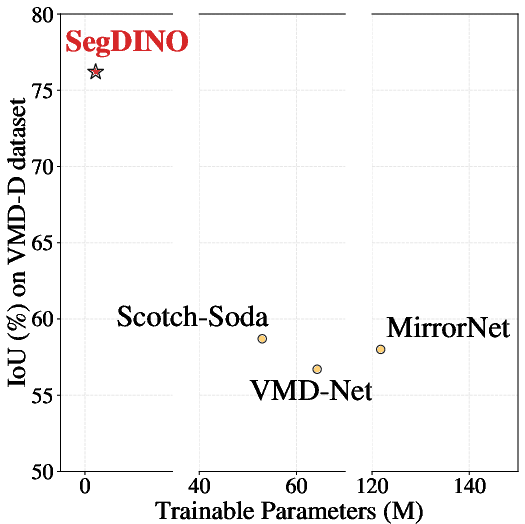
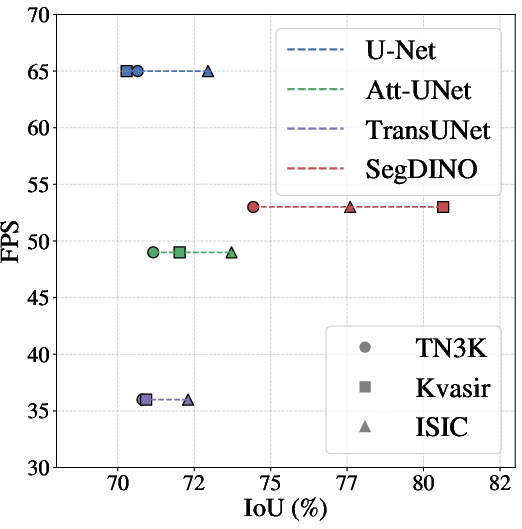
Figure 2: Overall performance and efficiency comparisons across different datasets.
Discussion and Implications
The results substantiate the claim that a frozen, self-supervised ViT backbone, when paired with a carefully designed lightweight decoder, can outperform more complex and parameter-heavy segmentation models. This finding challenges the prevailing assumption that high segmentation accuracy necessitates either end-to-end fine-tuning of large encoders or the use of elaborate decoders for multi-scale feature fusion.
Key implications include:
- Practical Deployment: The low parameter count and high inference speed make SegDINO suitable for edge devices, real-time applications, and scenarios with limited computational resources.
- Transferability: The approach demonstrates that foundation model features, even when frozen, are sufficiently expressive for a wide range of segmentation tasks, provided the decoder is appropriately designed.
- Simplicity vs. Performance: The strong numerical results indicate that decoder simplicity does not inherently limit segmentation performance, provided that the encoder's features are sufficiently rich and multi-scale.
However, freezing the encoder may limit adaptability to highly domain-specific or out-of-distribution data, particularly in medical imaging where rare pathologies may not be well represented in the pretraining corpus. Further, the ablation of feature selection strategies and decoder design could yield additional insights into the robustness and generalizability of the framework.
Future Directions
Potential avenues for future research include:
- Partial Encoder Fine-tuning: Investigating the trade-off between efficiency and adaptability by selectively fine-tuning deeper layers of the encoder for highly specialized domains.
- Dynamic Feature Selection: Learning to select or weight features from different transformer layers based on the target domain or task.
- Generalization to Other Foundation Models: Extending the lightweight decoding paradigm to other self-supervised or multimodal vision backbones.
- Integration with Prompt-based Segmentation: Exploring hybrid approaches that combine prompt-based segmentation (e.g., SAM) with lightweight decoders for task-specific adaptation.
Conclusion
SegDINO establishes a new standard for efficient image segmentation by demonstrating that a frozen DINOv3 backbone, coupled with a minimal MLP decoder, can achieve state-of-the-art results across diverse medical and natural image benchmarks. The framework's efficiency, simplicity, and strong empirical performance have significant implications for the deployment of segmentation models in practical, resource-constrained environments. The findings motivate further exploration of lightweight adaptation strategies for foundation models in dense prediction tasks.