- The paper presents a novel Transformer architecture that embeds a heat-kernel based attention bias to enforce spatiotemporal causality and diffusion locality.
- It integrates a FiLM-modulated SIREN decoder with physics-informed token generation to effectively reconstruct nonlinear PDE fields.
- Experimental results show significant error reduction and stable convergence in both 1D heat equation and 2D Navier–Stokes reconstructions, even under noisy conditions.
Motivation and Context
The problem of reconstructing continuous physical fields governed by PDEs from sparse and irregular observations is central to scientific machine learning (SciML), especially when targeting nonlinear systems. Classical physics-informed neural networks (PINNs) enforce PDE constraints as loss-function residuals, but suffer gradient imbalance and instability under data scarcity, and tend to lose physical consistency. Recent operator-learning and Transformer-based frameworks often miss explicit physical causal structure, relying instead on spectral priors or data-driven attention.
This paper introduces the Physics-Guided Transformer (PGT), a neural operator architecture that structurally embeds physical priors directly into the self-attention mechanism via a heat-kernel Green's function–derived additive bias. This architectural design enforces spatiotemporal causality and diffusion locality within the attention computation, moving beyond penalty-based residual regularization.
Model Architecture
PGT combines a physics-guided Transformer encoder with a FiLM-modulated SIREN implicit decoder, tailored for continuous field reconstruction from sparse, irregular observations. Context tokens are generated by projecting sparse measurements along with their coordinates, augmented by a global token. Attention logits in the encoder incorporate a heat-kernel–derived additive bias, encoding the physics of diffusion and causality.
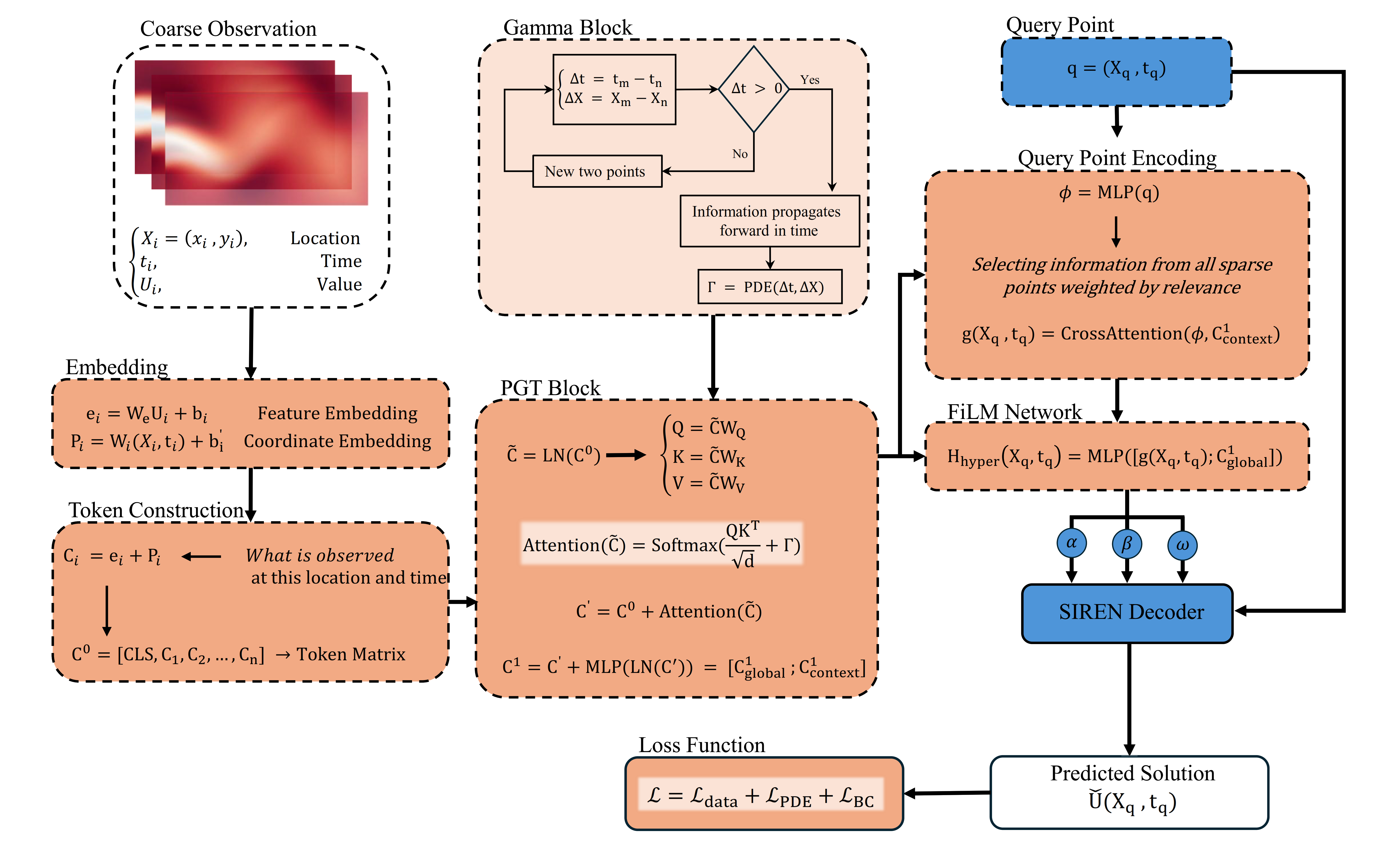
Figure 1: Overview of the PGT architecture, embedding physics-guided biases in Transformer attention for sparse-to-continuous field reconstruction.
At query coordinates, cross-attention retrieves physics-conditioned features, driving an implicit decoder (SIREN) whose spectral response is modulated via FiLM by both global and query-specific context. The decoder thus resolves high-frequency spatial features in the reconstructed field, while being continuously conditioned by the underlying physical dynamics.
The bias matrix Γ is constructed directly from PDE Green's function theory: for parabolic PDEs, e.g., the heat equation, it is the logarithm of the Gaussian heat kernel, enforcing spatial locality and temporal causality; for hyperbolic PDEs, it encodes finite-speed propagation. The effect of the bias is tunable: as physical parameters approach the limits of pure data-driven or strictly local propagation, PGT asymptotes to standard Transformer or nearest-neighbor aggregation, respectively.
Training Objective
PGT is trained with a composite, uncertainty-weighted loss aggregating data fidelity, PDE residual, boundary, and initial condition terms. Learnable uncertainty weights auto-balance the contributions of each source of supervision, obviating manual loss weighting. This enables consistent optimization even under noisy or heterogeneous measurement distributions.
Experimental Results: 1D Heat Equation
In sparse 1D heat equation reconstruction with as few as 100 observations, PGT achieves an absolute L2 relative error of 5.9×10−3—38-fold lower than PINN and over 90-fold lower than SIREN baselines. The error continues to decrease stably as sample counts increase, with monotonic convergence throughout training, in contrast to early plateaus with baselines.
Experimental Results: 2D Navier–Stokes Cylinder Wake
In sparse 2D Navier–Stokes reconstruction (1500 observations), PGT attains dual-optimality: a governing-equation residual of 8.3×10−4 (competitive with best residual-based methods), and a relative L2 error of $0.034$—substantially lower than any method with comparable PDE residual. No baseline achieves both simultaneously. The qualitative reconstruction demonstrates preservation of vortex-shedding and coupled velocity–pressure structures.
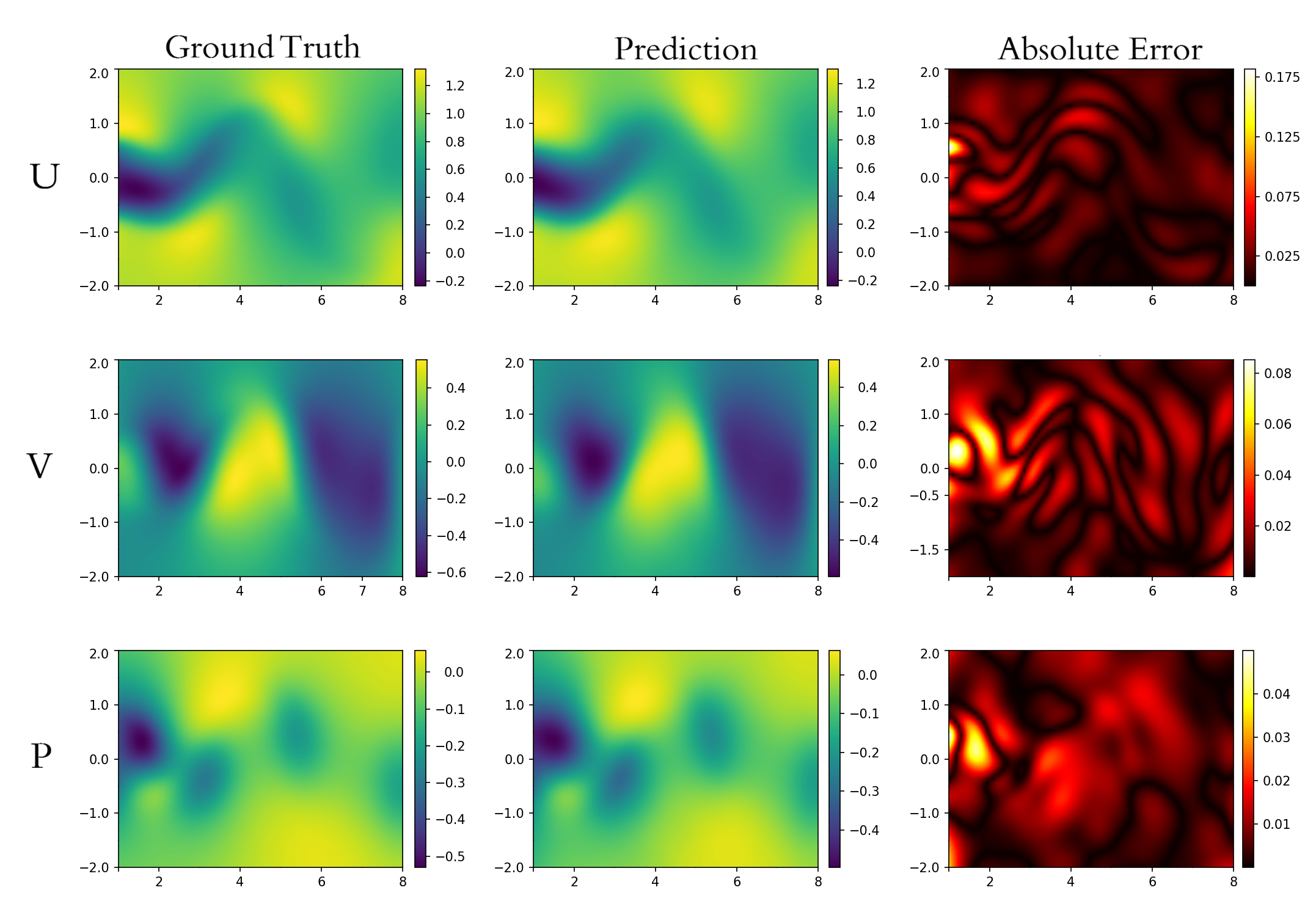
Figure 2: Qualitative comparison of ground truth and PGT-reconstructed u, v, p fields, with error maps confirming accuracy in nonlinear regions.
Training error curves show sustained monotonic decay for PGT, while PINNs and implicit neural representations plateau prematurely.
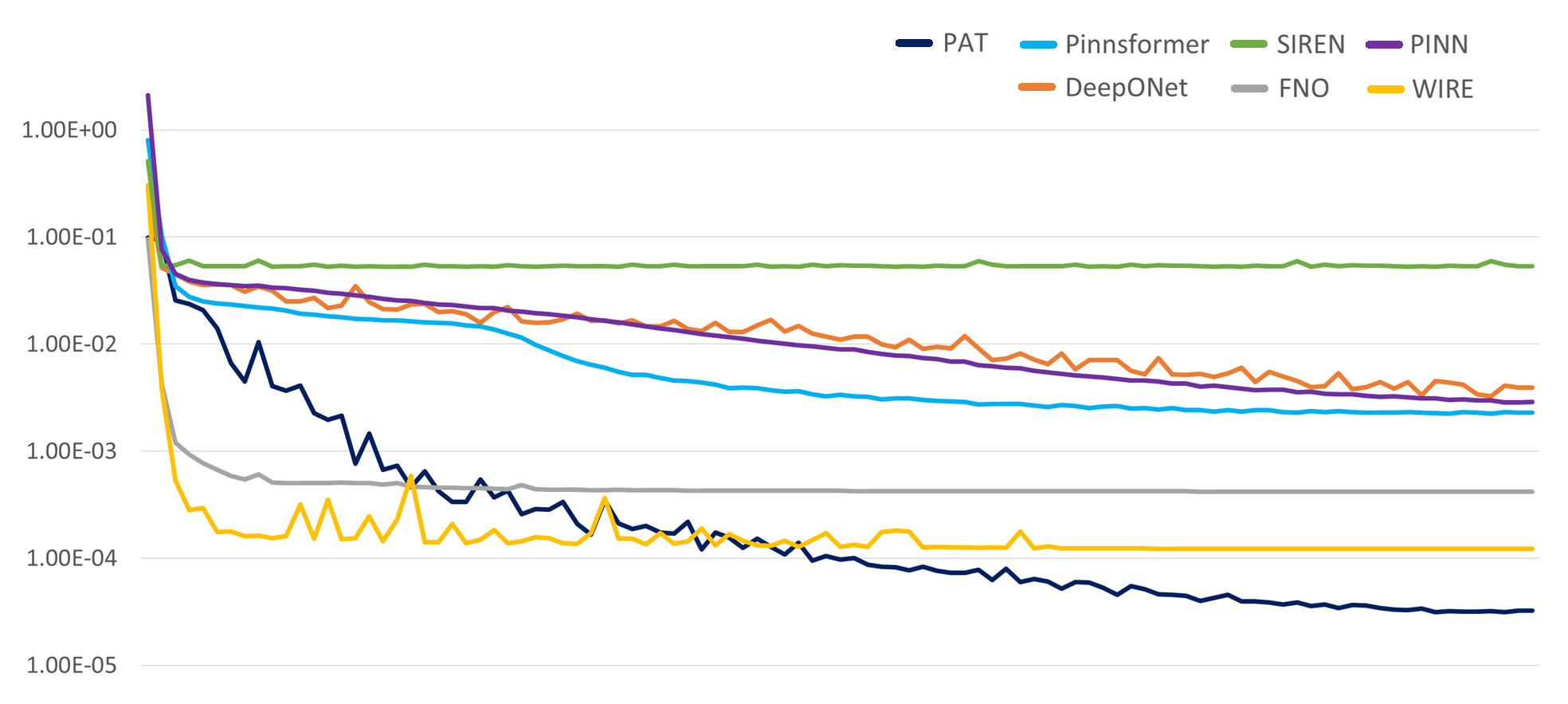
Figure 3: Error convergence for PGT and baselines on Navier–Stokes, illustrating superior optimization stability and monotonic error reduction.
Ablation Analysis
Systematic ablations demonstrate that the physics-guided attention bias Γ is the dominant driver of reconstruction accuracy, while explicit PDE residual is required for governing-equation compliance. Both mechanisms are non-redundant and complementary. Decoder design analysis further shows that FiLM modulation and sinusoidal activations jointly optimize spectral and contextual reconstruction capacity.
Robustness to Noisy Observations
Noise robustness experiments reveal that standard PGT maintains reconstruction error and PDE residual within narrow ranges across all noise levels tested. The architectural bias acts as an implicit regularizer, stabilizing training under sensor uncertainties. Heteroscedastic uncertainty-weighted variants offer no improvement and may destabilize optimization, confirming that architectural physics priors dominate noise resilience.
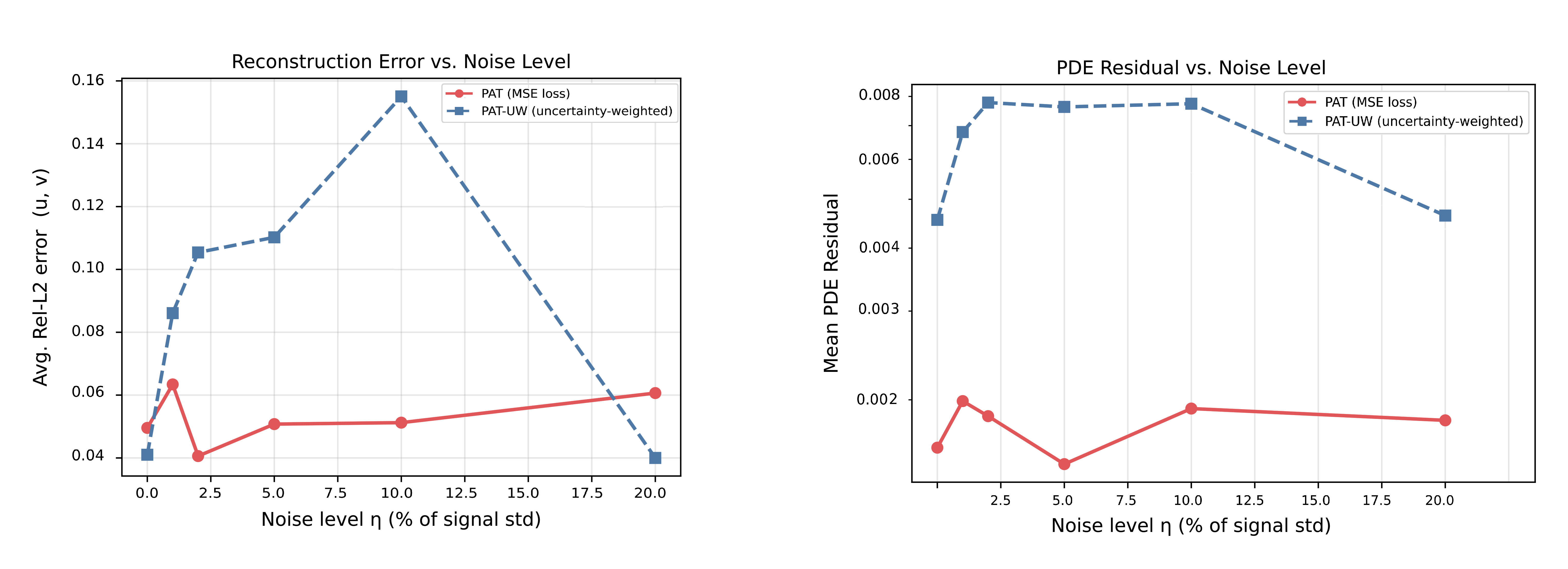
Figure 4: Error and PDE residual as a function of noise level L20, validating PGT's robustness to sensor noise.
Implications and Future Directions
PGT establishes a formal architectural paradigm for embedding physical causality and locality directly into neural operator design, sidestepping the convergence and trade-off failure modes associated with penalty-only residual enforcement. The approach opens new directions in SciML: scalable physics-aware neural operators, interpretable attention mechanisms for PDEs, and reconstructions under extreme data scarcity.
The computational lift of global sparse context attention and FiLM hypernetworks is considerable relative to light baselines. However, the spatial locality of the physics bias motivates future hierarchical or sparse attention variants (e.g., low-rank bias, spatial truncation) to reduce quadratic complexity while preserving physical priors. The method is extensible to multi-physics PDE systems, higher dimensions, and turbulent regimes.
Conclusion
The Physics-Guided Transformer demonstrates that embedding physics at the architectural level, particularly via attention bias informed by Green's functions, is a principled and extensible mechanism for reliable nonlinear PDE reconstruction from sparse data. Empirical results and ablation analyses confirm that architectural physical inductive biases optimize both accuracy and physical coherence beyond what loss-penalty approaches can achieve. This work points toward new synthesis of data-driven and physics-based modeling, with broader potential for interpretable and robust AI in scientific domains.

