- The paper presents P3D, a hybrid CNN-Transformer architecture that scales surrogate modeling for high-resolution 3D fluid dynamics and diverse PDE tasks.
- It integrates local convolutions with windowed self-attention and a sequence-based context model to efficiently process domains up to 512³ while reducing boundary uncertainties.
- Experimental results demonstrate significant improvements in normalized RMSE, computational cost, and VRAM efficiency over state-of-the-art baselines in turbulence and channel flow simulations.
P3D: Scalable Neural Surrogates for High-Resolution 3D Physics Simulations with Global Context
Introduction and Motivation
The paper introduces P3D, a hybrid CNN-Transformer architecture designed for scalable surrogate modeling of high-resolution 3D physics simulations, with a particular focus on fluid dynamics and related PDEs. The motivation stems from the prohibitive computational and memory requirements of training neural surrogates on large-scale 3D data, which is a major bottleneck in scientific machine learning. P3D addresses this by combining local feature extraction via convolutions with deep representation learning through windowed self-attention, enabling efficient training and inference on domains with up to $512^3$ spatial resolution.
P3D is evaluated on three core tasks: (1) simultaneous learning of 14 distinct PDE dynamics, (2) scaling to high-resolution isotropic turbulence, and (3) probabilistic generative modeling of turbulent channel flows with global context. The architecture is further augmented with a sequence-to-sequence context model for global information aggregation and adaptive instance normalization for region-specific conditioning.
P3D employs a U-shaped multi-scale backbone, where convolutional blocks process local features and transformer blocks handle high-dimensional token representations at deeper levels. The convolutional encoder compresses spatial crops into latent tokens, which are then processed by windowed multi-head self-attention, following the Swin Transformer paradigm but adapted for 3D. Notably, absolute positional embeddings are omitted to promote translation equivariance, a critical inductive bias for PDE surrogate modeling.
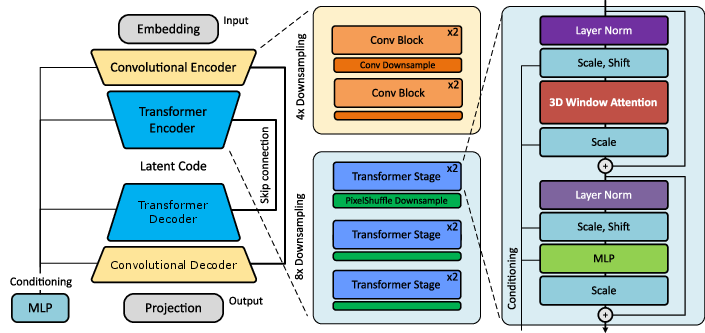
Figure 1: Overview of P3D. Convolutional blocks for local features processing are combined with transformers for deep representation learning, yielding a U-shaped multi-scale architecture. The transformer backbone combines windowed attention and conditioning via adaptive instance normalization, which are modified and optimized for 3D.
The bottleneck layer tokens are embedded and augmented with frequency-based positional encodings. For global context, a sequence model (e.g., HyperAttention or Mamba) aggregates information across crops, and region tokens are injected into adaptive instance normalization layers to modulate decoder outputs based on global and local context.
Training and Scaling Strategies
P3D supports both supervised and probabilistic training regimes. For deterministic surrogate modeling, MSE loss is used. For generative modeling, flow matching-based diffusion training is employed, where the model learns a velocity field to transform noise samples into solution samples via ODE integration.
To address memory constraints, P3D is pretrained on small crops (e.g., $128^3$) and scaled to larger domains at inference. Two upscaling strategies are considered: (1) combining crops for joint processing, leveraging translation equivariance, and (2) independent crop processing with global coordination via the context network. Finetuning setups allow selective backpropagation through encoder/decoder blocks, further reducing VRAM requirements.
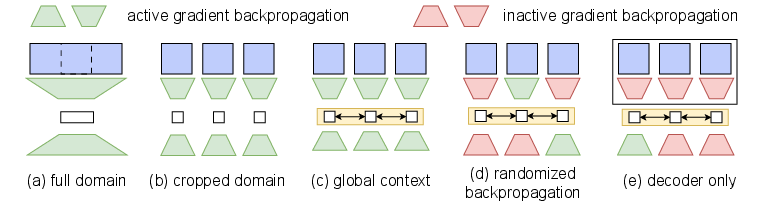
Figure 2: Different training and inference setups, including crop-based pretraining, global context aggregation, and memory-efficient finetuning strategies.
Experimental Results
Joint Learning of Multiple PDEs
P3D is benchmarked against state-of-the-art baselines (Swin3D, AViT, AFNO, TFNO, FactFormer, UNet variants) on the task of simultaneous autoregressive prediction for 14 PDEs at high resolution. P3D consistently achieves the lowest normalized RMSE across crop sizes ($32^3$, $64^3$, $128^3$), outperforming all baselines. Increasing crop size improves accuracy due to reduced boundary uncertainty.

Figure 3: P3D trained on 14 different PDE dynamics simultaneously, demonstrating high efficiency and performance in benchmark comparison (left), scaling to $512^3$ isotropic turbulence (middle), and diffusion modeling for turbulent channel flow with global context (right).
P3D also provides superior trade-offs between accuracy, computational cost (GFLOPs), and memory usage compared to competitors.
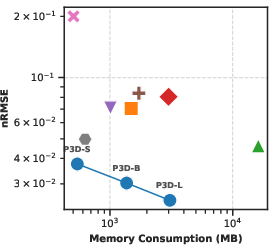
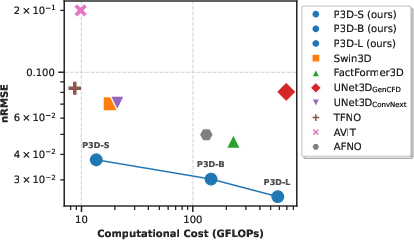
Figure 4: Model accuracy versus memory usage and computational cost for jointly learning different PDEs with crops of size $64^3$.
High-Resolution Isotropic Turbulence
P3D is pretrained on $128^3$ crops and scaled to $512^3$ domains for autoregressive prediction of isotropic turbulence. The model achieves stable rollouts up to 16 steps, with RMSE and spectral errors (enstrophy graph) significantly lower than baselines. Larger models and domain sizes further improve accuracy, with no need for explicit global context due to the homogeneous nature of the simulation.
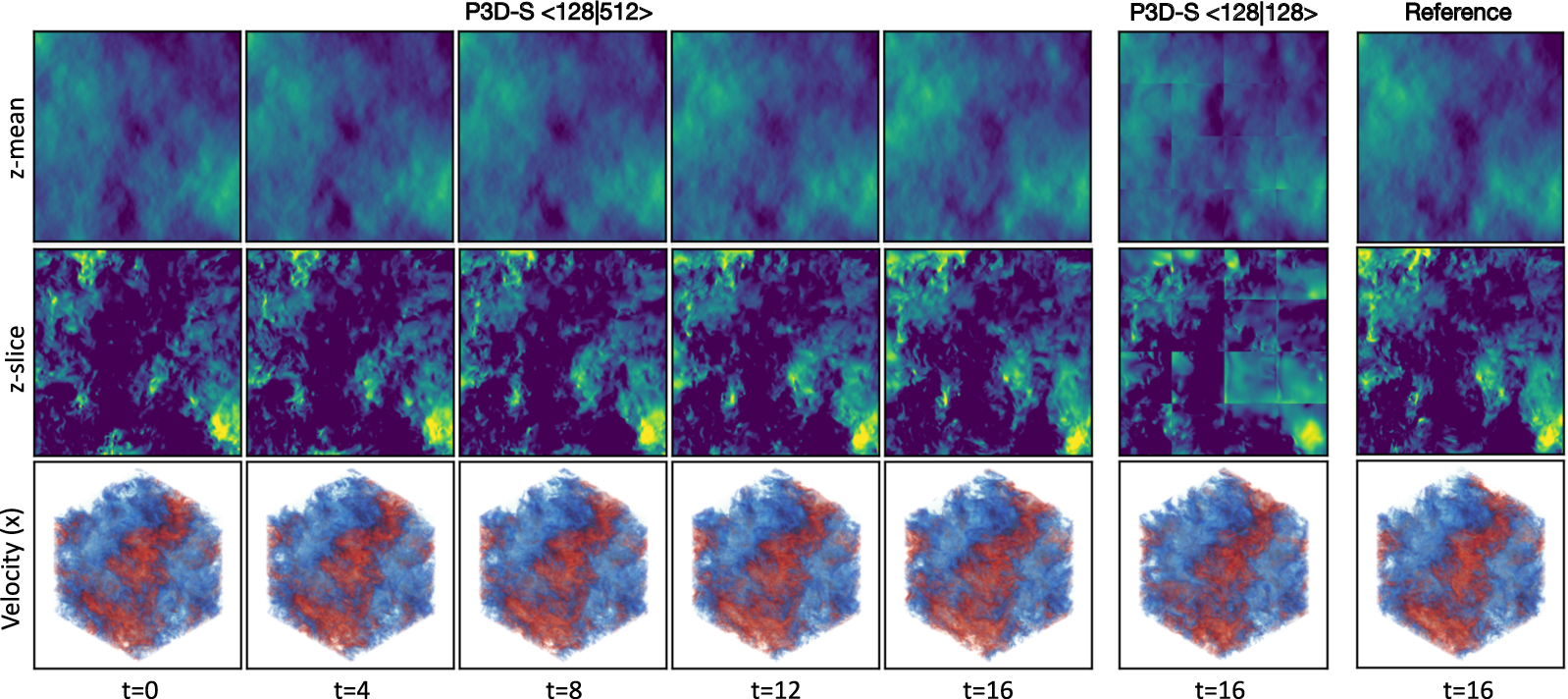
Figure 5: Forced isotropic turbulence. Prediction on the test set at resolution $512^3$ with an autoregressive rollout of 16 steps. P3D-S <128|512> encodes and decodes all region crops simultaneously, whereas P3D-S <128|128> processes crops independently.
Probabilistic Modeling of Turbulent Channel Flow
P3D is trained as a diffusion model to sample equilibrium states of turbulent channel flow across varying Reynolds numbers. Pretraining on $48^3$ crops followed by finetuning with the context network enables accurate global solutions, as region tokens communicate relative positions to the wall. Statistical evaluation of velocity profiles (mean, variance, skewness) shows close agreement with DNS reference, outperforming AFNO and UNet baselines.
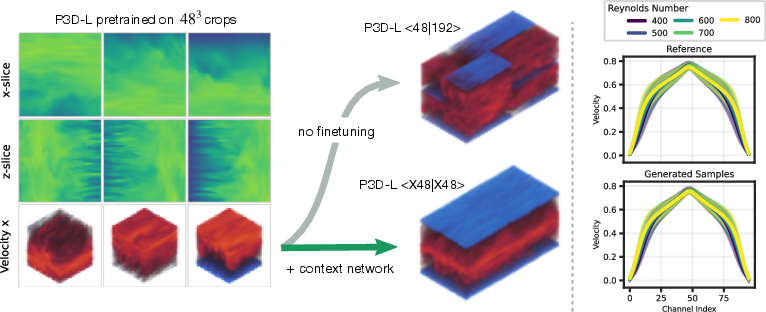
Figure 6: Turbulent channel flow. Pretraining on $48^3$ crops and scaling to $96^2 \times 192$ domain. Finetuning with global context network resolves positional ambiguities, yielding accurate flow statistics across Reynolds numbers.
Finetuning strategies (full, decoder-only, partial backpropagation) are analyzed for VRAM efficiency and statistical accuracy. P3D achieves up to 144x speedup over DNS solvers, with generative sampling bypassing costly transient phases.
Implementation and Resource Considerations
P3D is implemented with three configurations (S, B, L) ranging from 11M to 180M parameters. Training is performed on 4 H100/A100 GPUs, with batch sizes and mixed precision optimized for throughput. The architecture supports flexible crop sizes and domain upscaling, with context network and region token mechanisms enabling efficient global information flow. Memory-efficient finetuning and selective gradient propagation are critical for scaling to $512^3$ and beyond.
Implications and Future Directions
P3D demonstrates that hybrid CNN-Transformer architectures, when combined with crop-based pretraining and global context aggregation, can scale neural surrogates to previously unattainable 3D resolutions. The approach is applicable to a wide range of scientific domains requiring high-fidelity surrogate modeling, including turbulence, climate, astrophysics, and biomedical flows. The probabilistic generative capabilities open avenues for uncertainty quantification and direct sampling of equilibrium states, bypassing expensive solver warm-up phases.
The context model and region token conditioning provide a blueprint for integrating global information in large-scale surrogate models, which is essential for non-homogeneous domains and boundary-sensitive problems. Future work may explore further scaling, integration with foundation models, and extension to more complex boundary conditions and multi-physics scenarios.
Conclusion
P3D establishes a robust framework for scalable, accurate, and memory-efficient surrogate modeling of high-resolution 3D physics simulations. Its hybrid architecture, crop-based training, and global context mechanisms enable superior performance across diverse PDEs and turbulence regimes, with significant computational advantages over existing methods. The results highlight the potential for scientific foundation models to impact real-world applications at scale, and set the stage for further advances in neural surrogate modeling for complex physical systems.

