- The paper introduces a transformer-based operator learning framework that bypasses iterative finite element analysis to enable real-time topology optimization.
- It leverages global conditioning tokens and self-attention to capture long-range mechanical interactions, achieving compliance error as low as 1.86%.
- Incorporated physical loss terms ensure material connectivity and volume constraints, offering a scalable, physics-informed alternative to classical methods.
Introduction and Motivation
Topology optimization (TO) is a fundamental tool in computational mechanics, permitting the systematic allocation of material within a prescribed domain to maximize performance metrics, typically compliance minimization. Conventional approaches, notably the SIMP method, level-set methods, and the method of moving asymptotes (MMA), offer mathematical rigor and reliable convergence but are fundamentally iterative, requiring repeated finite element analyses (FEA) and sensitivity updates. This heavy computational burden precludes real-time design-space exploration and limits scalability, especially for high-resolution or dynamic problems.
Machine learning (ML) has recently been leveraged to bypass the laborious iterative nature of TO by learning mappings from problem parameters to optimal topologies. Earlier neural methods, including encoder-decoder CNN architectures, GANs, and more recently diffusion models, have shown promise in generating topologies with varying degrees of fidelity and efficiency. However, significant trade-offs remain: direct prediction models offer speed at the expense of physical fidelity, while iterative generative models such as diffusion offer superior accuracy but at high inference cost.
This paper, "Physics-Informed Transformer for Real-Time High-Fidelity Topology Optimization" (2604.03522), presents a transformer-based operator learning framework for TO, targeting direct and high-fidelity topology generation in a non-iterative, single forward-pass manner.
The paper adapts the Vision Transformer (ViT) architecture to operator learning for TO. The key insight is the suitability of transformer self-attention for capturing long-range, nonlocal mechanical interactions inherent in structural domain problems. Inputs including boundary conditions, load location and direction, and target volume fraction are composed into a global conditioning token, while the stress and strain energy fields are patchified and tokenized for transformer processing.
After preprocessing (Figure 1), the neural architecture projects each input patch to an embedding, adds positional encodings, and then processes the sequence—global and patch tokens—through L transformer layers (Figure 2).
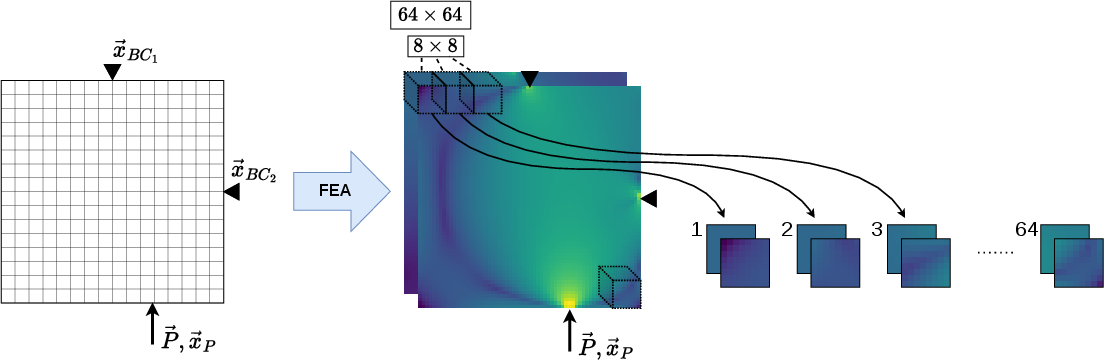
Figure 1: The transformation from structural boundary/load conditions to dense field representations, then patchification for transformer input.
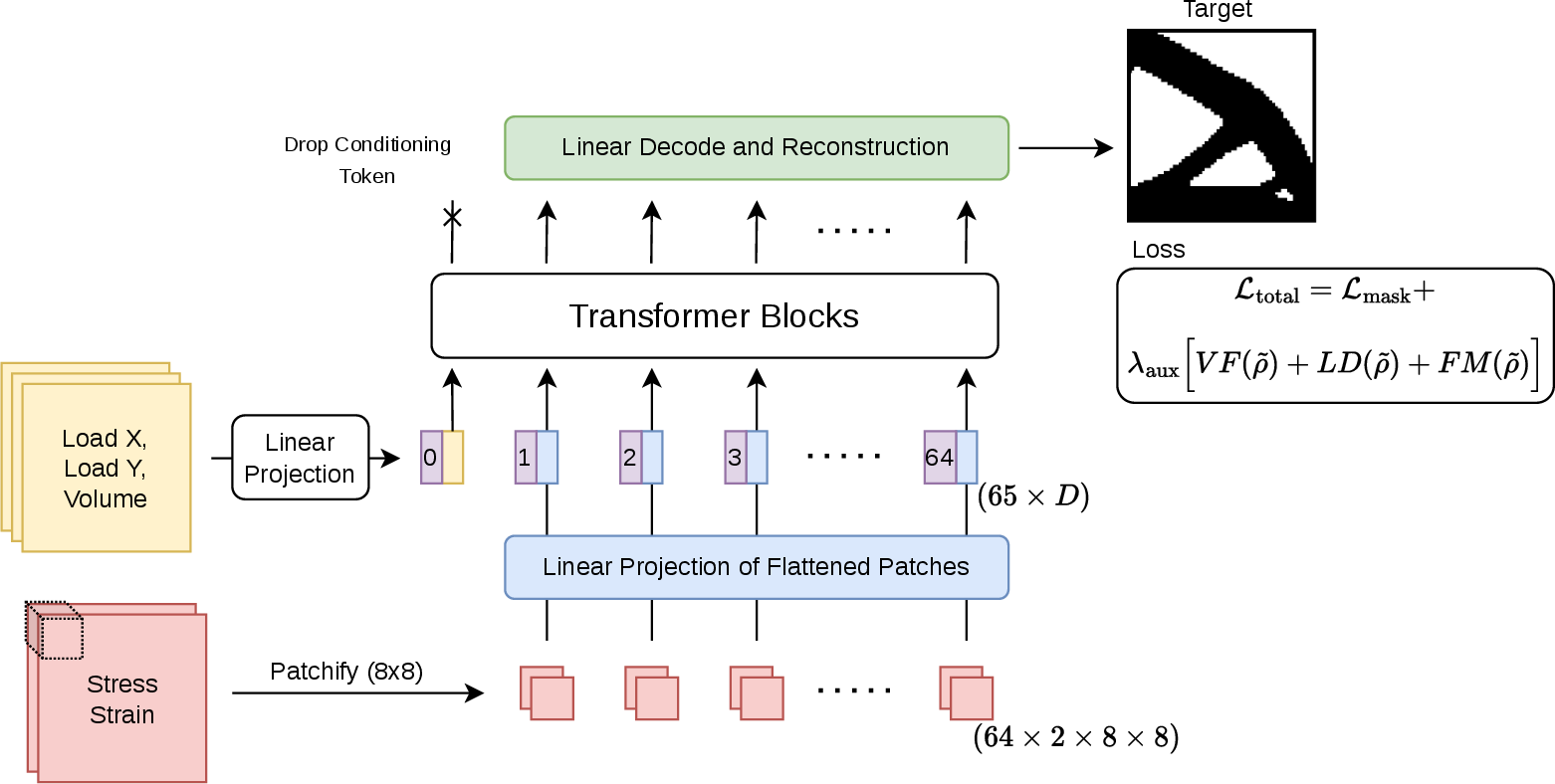
Figure 2: The full transformer architecture, uniquely encoding load/volume parameters and patchified physics fields into transformer tokens.
Global information is thus disseminated to all spatial regions via attention, a notable improvement over convolutional architectures with limited receptive fields and poor modeling of nonlocal dependencies.
A salient architectural feature is the conditioning token: it encodes all global parameters (load, volume, BCs, and, for dynamics, the low-frequency spectrum of the external force) and is projected into the same space as patch tokens. This enforces the simultaneous consideration of global specifications and local field structures within each self-attention block (see also Figure 3, for transformer block details).
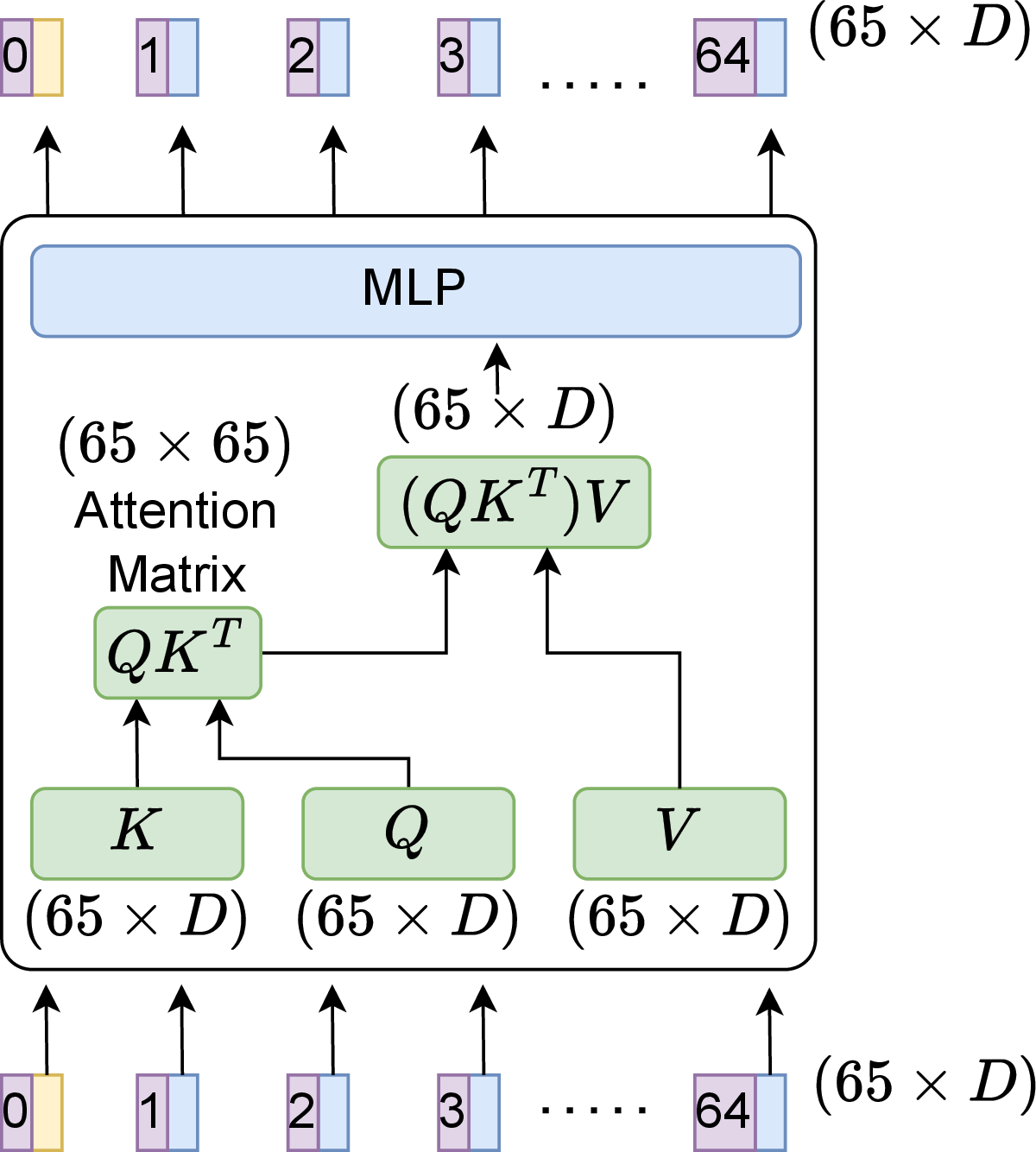
Figure 3: A transformer block mapping a token sequence to updated contextualized embeddings via multi-head self-attention and MLP.
Loss, Physical Constraints, and Post-Processing
Physical consistency is incorporated via auxiliary loss terms beyond the masked autoencoder objective Lmask. The main supplementary terms include:
- Volume Fraction Loss: Penalizes deviation between target and predicted material usage to enforce strict resource constraints.
- Load Discrepancy Loss: Penalizes topologies that do not provide adequate material support at load introduction sites.
- Differentiable Floating-Material Loss: Ensures topological connectivity via a differentiable approximation of a flood-fill on the predicted density, penalizing disconnected (floating) regions (implemented as a recursive, smoothed convolution with flood logic).
These explicit physics-oriented regularizations suppress issues common in image-based generators, particularly disconnected load paths, and improve manufacturability.
Model-generated topologies can benefit from minimal post-processing by backpropagating gradients through the floating material loss, offering a lightweight alternative to post-hoc classical repair (cf. Figure 4 and post-processing figures).
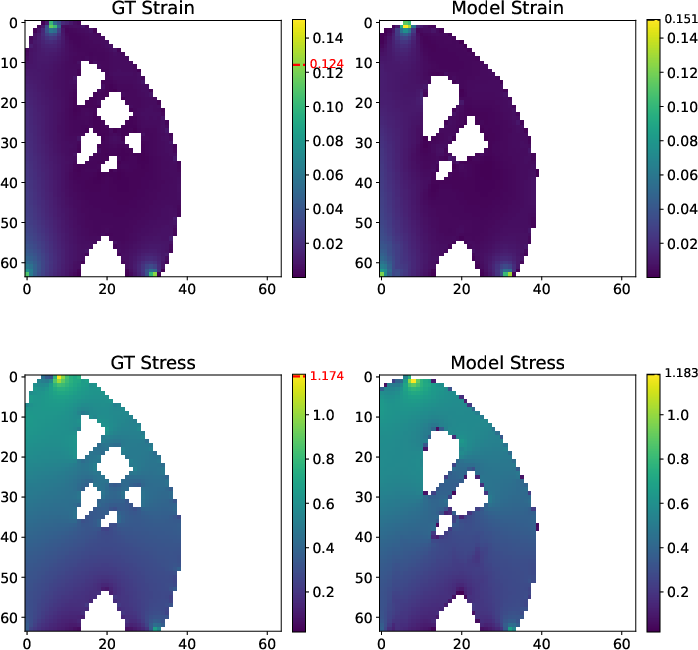
Figure 4: Comparison of predicted and ground truth stress/strain fields; stateful load paths and local responses are well matched.
Dataset and Evaluation
The data is synthesized on 64×64 domains with randomly sampled BCs, external load locations (on the boundary, with some tests at interior locations for OOD generalization), directions, and volume constraints spanning 30% to 50%. For each instance, the ground truth is a SIMP-optimized binary density map. Corresponding von Mises stress and strain energy fields—computed on the unoptimized domain—are inputs to the model, not ground-truth optimized fields.
The authors leverage symmetry-based data augmentation (rotations, mirroring) for improved sample efficiency and invariance, resulting in 30,000 effective static samples.
Static and Dynamic Results
Static Settings
Five ViT variants (Tiny, Small, Base, Large, Huge) are benchmarked. Base and Small provide optimal trade-offs between error and overfitting on the data regime explored. With optimal patch size (P=4), the best models achieve:
- Compliance error: as low as 1.86%
- Median compliance error: 0.32%
- Floating material error: 6.6%, reducible to 0.8% with gradient-based post-processing
Comparisons to diffusion models and GANs demonstrate strong competitive results, with substantially reduced inference cost (single forward-pass versus iterative sampling in diffusion).
Further experiments confirm that patch size (spatial tokenization scale) is a critical hyperparameter: overly large patches (P=8) impair long-range connectivity due to coarse representation; excessively small patches (P=2) lead to learning instability and suboptimal generalization due to excessive fragmentation.
The transformer approach maintains strong physical fidelity on key metrics: predicted structures replicate peak stress/strain statistics and preserve primary load paths and compliance values (see Figure 5, 7 for error/robustness analysis and out-of-distribution load cases).
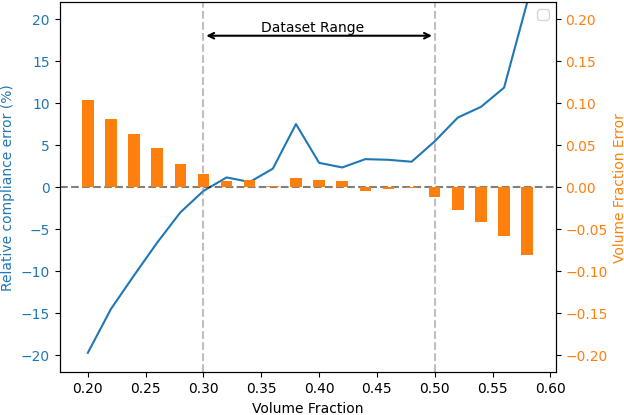
Figure 5: Compliance and volume fraction errors across interpolated and extrapolated volume fraction settings, highlighting robust interpolation, but systematic under/over-estimation outside training bounds.
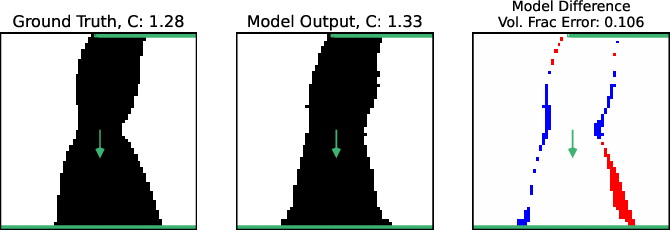
Figure 6: Out-of-distribution test: model generalizes effectively to a center-domain load, showing correct material allocation not seen in training.
Dynamic Settings and Transfer Learning
For dynamic topology optimization (DTO), the main challenge is the small dataset size and the need to encode temporal loading. The authors resolve this by:
- Pretraining the transformer on static data.
- Augmenting the global conditioning token with the low-frequency spectrum (first ten DFT coefficients) of the applied load.
- Fine-tuning decoder and projection layers for efficient dynamic adaptation (see Figure 7 for DFT encoding illustration).
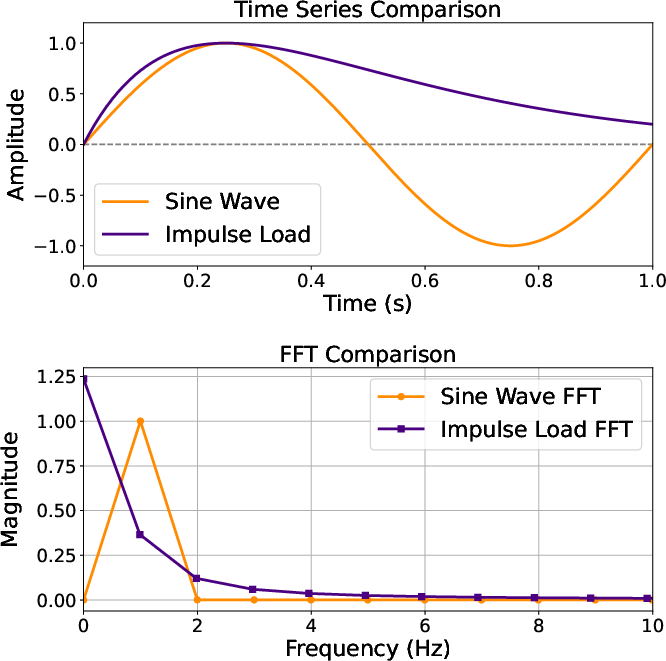
Figure 7: Time-domain (left) and frequency-domain (right) representation of dynamic loads for conditioning token augmentation.
With this strategy, compliance error is limited to 4.8% for the best dynamic model. However, floating material and geometric sharpness degrade due to the compounded challenges of limited data and increased problem complexity. Despite this, the method achieves over three orders of magnitude acceleration compared to classical SIMP-based dynamic TO, enabling practical real-time DTO.
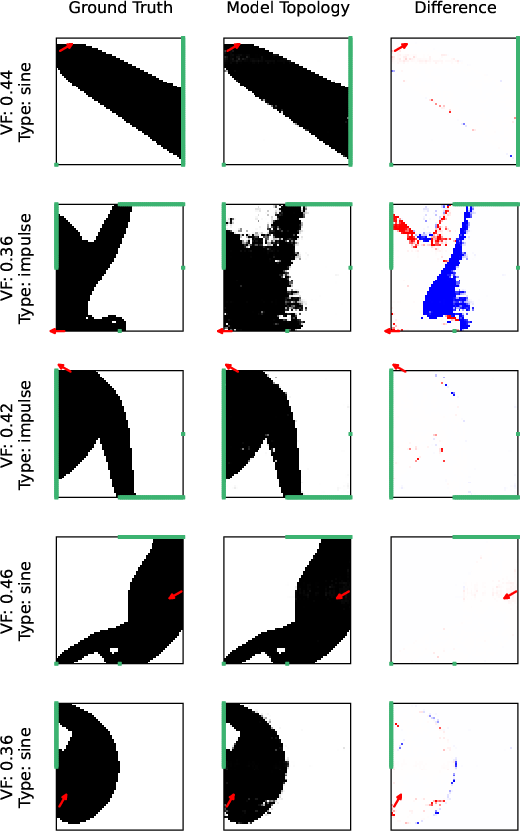
Figure 8: Dynamic topology validation: ground truth, predicted topology, and error map for the model fine-tuned on dynamic data.
Implications, Limitations, and Future Directions
The main implication of this work is the establishment of topology optimization as a tractable operator learning task. By leveraging attention-based architectures, the field can now bypass iterative PDE-constrained optimization for large classes of problems, collapsing optimization and inference into a single forward-pass and thus transforming the computational mechanics workflow.
Practically, this enables rapid interactive design, on-the-fly design exploration, or real-time feedback in CAE software, with minimal loss in solution quality for well-represented data regimes. The framework's generalization to out-of-distribution load placements supports its robustness, though extrapolation in global constraint space (e.g., unattested volume fractions) remains limited.
Avenues for future work include:
- Extension to arbitrary numbers/locations of loads and 3D domains (volumetric patchification).
- Efficient attention architectures to handle the large token counts in unstructured/adaptive/3D meshes.
- Unified conditioning tokens embedding richer multiphysics, manufacturing constraints, or robust design objectives.
- Integration with graph neural networks for mesh-agnostic frameworks applicable to unstructured domains.
Connectivity and topological constraints in data-scarce or highly dynamic regimes remain challenging and motivate the pursuit of improved constraint-aware architectures and loss formulations.
Conclusion
This work rigorously demonstrates the effectiveness of transformer-based operator learning for physics-informed, real-time topology optimization. The synergy of global self-attention, physically informed tokenization, and auxiliary constraint-enforcing losses yields compliance accuracy surpassing many generative methods at a fraction of their inference cost. The framework generalizes effectively within the training data regime and provides a scalable blueprint for future advances in both static and dynamic optimization. Advances in model scaling, constraint integration, and geometric representation will further expand the impact and applicability of this approach in computational engineering and design.