- The paper introduces a novel stochastic opacity masking technique that renders binary triangle visibility differentiable, enabling gradient-based optimization for compact radiance field representations.
- It leverages a neural deferred shader and multi-resolution per-triangle textures to capture view-dependent colors, ensuring compatibility with standard rasterization pipelines.
- Experiments show that DiffSoup outperforms state-of-the-art methods in preserving sharp edges and detail while using only 15K–20K triangles, achieving high rendering speeds on diverse hardware.
DiffSoup: Differentiable Opaque Triangle Soup for Extreme Radiance Field Simplification
Introduction
DiffSoup addresses the extreme radiance field simplification problem: reconstructing high-fidelity 3D scenes from multi-view RGB images using a drastically reduced set of textured, opaque triangle primitives. Unlike existing neural scene representations—such as NeRFs and 3D Gaussian Splatting—that rely on millions of volumetric or splatting primitives and require specialized inference engines, DiffSoup proposes a method that leverages stochastic opacity masking and neural textures on a minimal triangle mesh. This mesh is fully compatible with commodity rasterization pipelines (desktop, mobile, VR), supporting real-time, hardware-accelerated rendering, interactive scene editing, and efficient network transmission with budgets as tight as 15,000–20,000 triangles.
Radiance Field Representation and Differentiable Rasterization
DiffSoup encodes the scene radiance field as a triangle soup with per-triangle learnable color and binary opacity textures. Color features are decoded via a neural deferred shader, while opacity is enforced to be binary. Crucially, DiffSoup employs stochastic opacity masking for differentiable rasterization: during training, each fragment's opacity is compared to a random threshold, making the final color a stochastic function of all fragments. This allows gradients to propagate efficiently through both explicit visibility (triangle edges) and opacity-induced (implicit) discontinuities, overcoming the non-differentiability that has historically hindered direct optimization of rasterized opaque primitive meshes.
The adversarial effect of "hard" visibility transitions in opaque rasterization is handled by extending the silhouette-differentiation framework, accumulating gradients from both explicit triangle boundaries and intra-triangle opacity discontinuities using pairwise rasterized pixel comparisons.

Figure 1: Given multi-view RGB images, DiffSoup reconstructs a simplified radiance field as a textured triangle soup using differentiable rasterization and directly renders via standard, hardware-accelerated pipelines on heterogeneous devices.
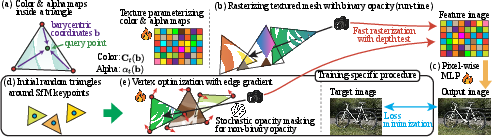
Figure 2: Overview of DiffSoup: (a) textured triangle soup parameterization; (b) depth-tested rasterization with binary opacity masking; (c) pixel-level neural deferred shading; (d, e) initialization from SfM keypoints and differentiable stochastic opacity/geometry optimization.
Stochastic Opacity Masking: Differentiable Binary Visibility
The core technical novelty of DiffSoup lies in converting the non-differentiable, depth-tested visibility of triangles with binary alpha into a differentiable learning signal suitable for gradient-based optimization. This is achieved by using stochastic opacity masking: each fragment’s binary visibility is determined by comparing its alpha to a uniform random value. This stochastic process directly matches the volumetric rendering logic of NeRF/3DGS and enables unbiased likelihood-ratio-based gradient estimation for both color and opacity under severe occlusion situations—without mollified rasterization or laborious scheduling schemes.
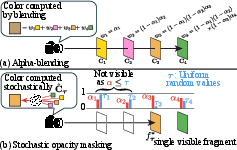
Figure 3: Volumetric alpha blending versus stochastic opacity masking. The latter outputs the exact color of a single surface while simulating a discrete stochastic selection process, facilitating unbiased, sort-free gradient estimation.
Texture Parameterization and Neural Deferred Shading
DiffSoup implements an atlas-free, multi-resolution triangle texture architecture: triangle textures are parameterized via per-triangle, recursively subdivided feature grids, supporting progressive coarse-to-fine optimization. Color is represented using a compact learned feature vector, decoded per-pixel through an efficient shared MLP with view-direction encoding—enabling view-dependent effects, efficient storage (mapping to 8-bit RGBA textures for deployment), and fast inference.
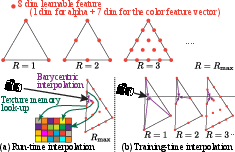
Figure 4: Multi-resolution per-triangle texture: lower-resolution grids at training enable improved optimization stability; at runtime, only the highest resolution is retained and queried.
Opacity, decoupled from color, is stored as a scalar field and optimized independently, promoting binary convergence. This separation avoids computational overhead during inference: fragment opacity-only lookups are fast and independent of the neural decoder.
Optimization and Adaptive Primitive Management
Optimization minimizes a photometric loss (L1 + SSIM) between rendered and ground-truth views over sampled camera trajectories, leveraging stochastic rasterized gradients. Training starts with coarse geometry, initialized from Structure-from-Motion (SfM) keypoints, and refines both triangle positions and per-triangle multi-resolution features. Adaptive primitive management—periodic edge splitting for large triangles and deletion of low-coverage triangles—enforces the primitive budget, ensures effective coverage even in scenes with high spatial extent, and maximizes the perceptual utility of each primitive.
Experimental Results
Real-World Novel-View Synthesis
DiffSoup achieves strong quantitative and qualitative results under extreme primitive constraints on challenging real-world datasets. On MipNeRF360 (15K triangle budget), it consistently outperforms state-of-the-art methods in SSIM and LPIPS, closely matching or exceeding PSNR, and uniquely preserves sharp edges and boundaries, which textured translucent Gaussians and mesh decimation pipelines fail to reproduce.

Figure 5: Qualitative results (MipNeRF360): DiffSoup exhibits the sharpest boundaries and finest detail among all methods under a 15K primitive budget, including 3DGS, Triangle Splatting, and Textured Gaussians.
Synthetic Scenes and Mobile Compatibility
On NeRF-Synthetic and Shelly datasets, DiffSoup matches or exceeds the PSNR/SSIM of high-budget baselines—often with 10x fewer primitives—and is effective even when initialized from random triangle soups, thanks to its adaptive triangle culling and edge splitting. The representation compresses to 8-bit RGBA textures, ensuring extremely low storage and memory demands (tens of MBs per scene) and fast transmission, with rendering at 2–3K FPS on desktop GPUs and competitive interactive rates on MacBooks and mobile devices.

Figure 6: Synthetic dataset qualitative ablation: DiffSoup robustly reconstructs detail from both randomly initialized and MobileNeRF-prioritized triangle soups, outperforming topology-unaware mesh decimation methods.
Ablation Studies
Ablations confirm that omitting opacity learning severely impairs boundary reconstruction, and eschewing multi-resolution textures degrades surface smoothness and color fidelity. Coarse-to-fine training combined with the proposed multi-resolution grid consistently yields the best reconstruction fidelity.

Figure 7: Ablations: (a) Without opacity learning, sub-triangle detail vanishes. (b) Without multi-resolution textures, optimization is unstable and geometry becomes noisy.
Implications and Future Directions
Practical Impact: DiffSoup's opaque triangle soup with neural textures enables scene transmission, lightweight editing, and high-quality view synthesis on any hardware supporting standard rasterization APIs. The approach collapses the gap between neural field representations and graphics-industry rendering pipelines, supporting interactive AR/VR, mobile games, and web experiences with near-instant download and render.
Theoretical Impact: By introducing a rigorous, unbiased, sort-free estimator for gradients through discrete rasterizer decisions using stochastic opacity masking, DiffSoup generalizes differentiable rendering theory, suggesting applicability in inverse graphics, photometric mesh fitting, and hybrid neural-symbolic rendering pipelines.
Limitations and Opportunities: The restricted single-layer, opaque model is less suited for complex transparency (e.g., fur, volumetric clouds), and some ultra-thin structures require increased triangle budgets. Advances in spatially adaptive primitive allocation and hierarchical texture parameterizations may close the remaining gap with volumetric methods while preserving rasterization efficiency.
Conclusion
DiffSoup establishes an efficient and differentiable pipeline for learning extremely compact, detail-preserving 3D representations that are natively compatible with hardware rasterizers across devices. Through stochastic opacity masking and neural multi-resolution textures, it overcomes the longstanding difficulty of learning detail-rich, binary-opaque triangle meshes from images, enabling new progress in view synthesis, 3D content distribution, and real-time graphics applications.

