- The paper formalizes AI research agents as search algorithms that enhance ML performance by integrating innovative search policies with refined operator sets.
- It demonstrates that leveraging advanced search strategies like MCTS alongside novel operators significantly increases medal success rates from 39.6% to 47.7% on MLE-bench lite.
- It addresses the generalization gap by contrasting validation and test performance, offering strategies to mitigate overfitting in automated ML workflows.
AI Research Agents: Enhancing Machine Learning through Search and Exploration
This paper introduces a framework for AI research agents, focusing on improving their performance within the MLE-bench environment. The core idea revolves around formalizing these agents as search policies that navigate a space of candidate solutions, which are iteratively modified via operators. The paper emphasizes the critical interplay between search strategies (Greedy, MCTS, Evolutionary) and operator sets, demonstrating that this relationship is key to achieving high performance. The authors' best agent achieves a state-of-the-art result on MLE-bench lite, increasing the Kaggle medal success rate from 39.6% to 47.7%. The paper also highlights the importance of addressing the generalization gap between validation and test scores to prevent overfitting, ultimately improving the robustness and scalability of automated machine learning.
The paper formalizes the design of AI research agents as a graph-based search algorithm. This approach allows for the systematic exploration of alternative agent designs and provides insights into the exploration-exploitation trade-off. The agent operates by searching a directed graph Gt=(Vt,Et) that evolves over multiple iterations, where each node v∈Vt represents an artifact. The search algorithm is defined by the tuple (F,πsel,O,πop,τ), which includes the fitness function (F), selection policy (πsel), operator set (O), operator policy (πop), and termination rule (τ).
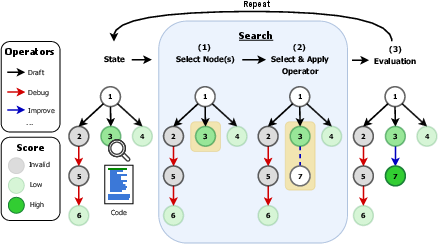
Figure 1: Overview of AIRA. Given a problem specification, AIRA maintains a search graph whose nodes are (partial) solutions. At each iteration, the agent (1) selects nodes via a *selection policy
, (2) picks an operator via an
operator policy and applies this operator to the node, and (3) scores the resulting solution via a
fitness function. Here, a greedy node selection strategy applies the improve operator to the highest scoring node.*
The operator set, denoted as O, comprises transformation functions that propose new artifacts from selected artifacts. The paper builds on the AIDE framework by using Draft, Debug, and Improve operators and introduces the Crossover operator. AIDE is re-casted within this notation, defining its fitness selection, operator set (OAIDE), and operator policy.
Experimental Design and AIRA-dojo
The AIRA-dojo framework is introduced, providing a scalable and customizable environment for AI research agents. AIRA-dojo offers abstractions for operators, policies, and tasks. The agents operate within Jupyter notebooks, allowing them to execute arbitrary Python code. The environment enforces program-level constraints using Apptainer containers, ensuring isolation and mitigating risks. The MLE-bench lite, a subset of 22 tasks from the full MLE-bench, is used for evaluation. The performance is assessed using the Medal Success Rate, measuring the percentage of attempts in which an agent secures a medal. The experiments are conducted using the DeepSeek R1 model and GPT-4o for parsing code execution outputs.
AIRA: Enhanced Operators and Search Policies
The paper proposes a new operator set, OAIRA, which improves upon OAIDE. The key differences include prompt-adaptive complexity, scoped memory, and the use of "Think Tokens" to encourage structured reasoning. Three agents are introduced, combining the operators OAIRA with distinct search policies: , , and . The agent employs greedy search, while the agent uses Monte-Carlo Tree Search (MCTS), and the agent implements an evolutionary approach.
The paper analyzes the performance of the current state-of-the-art method, AIDE, examining the impact of memory, exploration, and the agent's performance profile. The results suggest that memory is not a driving factor behind AIDE's strong performance and that search-level exploration is constrained by the interaction between the operator set and the search policy. Furthermore, the true test performance plateaus over time, indicating potential overfitting.
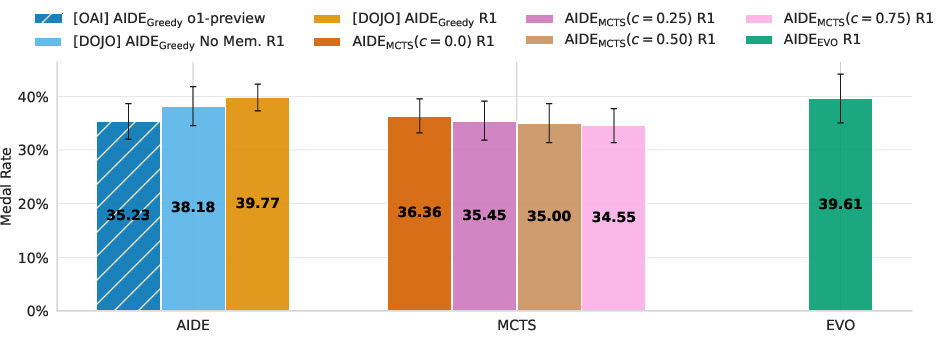
Figure 2: Searching with AIDE's operators. When limited to AIDE's operator set OAIDE, agents using more advances search policies (e.g., MCTS, evolutionary algorithms) gain no advantage, underscoring the operator set as the bottleneck.
The effectiveness of the improved operators is assessed, examining their interplay with more advanced search policies. AIRA-dojo's benefits are highlighted, with the baseline agent implementation improving the medal rate from 35.2% to 45.9% compared to previous results. Comparing the performance of and isolates the effect of the operators, demonstrating the importance of operators for performance. The results show that for R1, achieves the best performance, achieving state-of-the-art performance on MLE-bench Lite with an average medal rate of 47%.
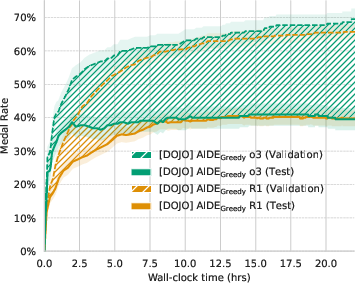
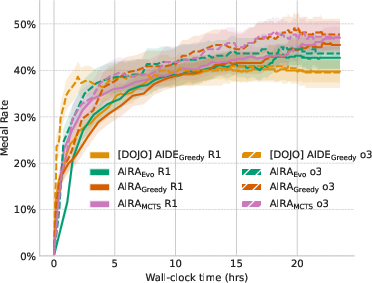
Figure 3: a) AIDE's performance profile over 24-hour search window. Perceived vs. actual medal rate over 24 hours of. The curves show the mean validation (agent-reported) and held-out test medal rates across 20 seeds for all tasks. The widening band illustrates the generalization gap, revealing how apparent gains on the validation set can mask overfitting and ultimately undermine the search process. b) Performance profiles of all agents after 24-hour search window.
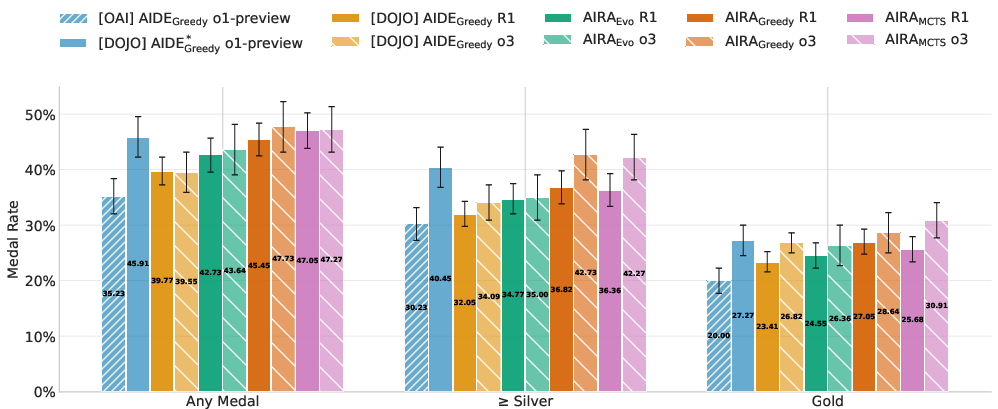
Figure 4: Medal rates on MLE-bench Lite. Performance is shown for three medal categories: any medal, silver medals and above, and gold medals only. Error bars represent 95% confidence intervals computed using stratified bootstrapping.
The paper also investigates the generalization gap, measuring its impact on the agents' performance. The results indicate that searching based on the test score instead of the validation score improves performance. The paper demonstrates that oracle final-node selection eliminates the gap between the standard and oracle settings for and . Bridging the gap through multiple submissions is explored, demonstrating that agents achieve an additional 10% of performance with as little as 3 top-k submissions.
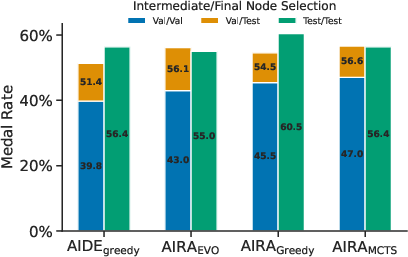
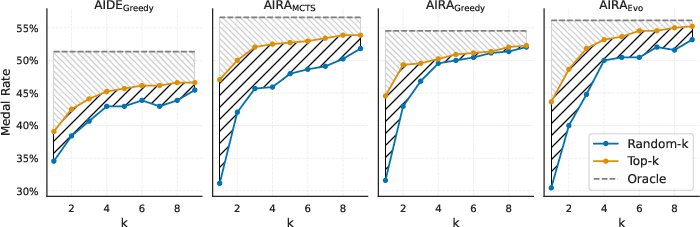
Figure 5: a) The validationâtest metric mismatch. Results shown are for agents using R1. Bars depict the absolute performance gap between three configurations: (i) using the validation metric for both intermediate (search) and final (submission) node selection; (ii) using the validation metric only for search and the test metric for selection; and (iii) using the test metric for both search and selection. b) Bridging the validationâtest gap. Medal rate achieved by two final node selection strategies as a function of k: (i) randomly sampling k nodes and reporting the highest test score among them; (ii) selecting the top k nodes by validation score and reporting the highest test score among those. As k increases, the validation based strategy closes the gap to the upper bound performance given by the best test score over the entire search graph.
The related works section discusses scaling search with LLMs, automating ML engineering and scientific discovery, and AI research frameworks. The paper concludes by summarizing the conceptualization of AI research agents as a combination of search policy and operators. The paper identifies limitations and future work, including agentic operators, fine-tuning, scaling the search, and data contamination. The agents continue to improve beyond the 24-hour period when given extended compute time.
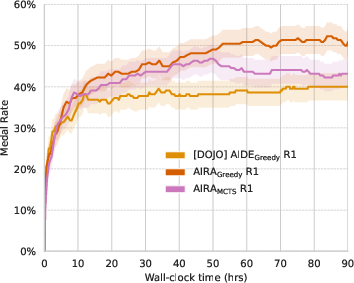
Figure 6: Medal achievement rates over a 90-hour search horizon. Each point represents the mean percentage of medals earned across 10 independent runs per task on the MLE-bench lite suite. Results are based on a complete replication of the baseline experiments and extended to 90 hours of search.
Implications and Future Directions
This research has significant implications for the field of automated machine learning and AI-driven scientific discovery. By formalizing AI research agents as search algorithms and emphasizing the interplay between search policies and operators, the paper provides a framework for systematic investigation and improvement. The findings highlight the importance of operator design, the need to address the generalization gap, and the potential for leveraging advanced search methods to enhance performance. Future research directions include exploring agentic operators, fine-tuning LLMs, scaling the search to longer time horizons and greater computational resources, and addressing the issue of data contamination.

