- The paper introduces a comprehensive framework that accelerates vision-language-action policy deployment via precise delay measurement and compensation.
- It employs MPC-based temporal and spatial trajectory optimization to achieve smooth, high-speed motion while respecting hardware constraints.
- Human-in-the-loop speed adaptation refines phase-dependent execution, enabling near-human performance on dexterous manipulation tasks.
Accelerating Vision-Language-Action Policy Deployment for Real-World Robotic Manipulation
Introduction
"Realtime-VLA V2: Learning to Run VLAs Fast, Smooth, and Accurate" (2603.26360) presents a comprehensive framework for deploying Vision-Language-Action (VLA) policies in real-world robotics with significant improvements in execution speed, trajectory smoothness, and task accuracy. The paper systematically analyzes fundamental bottlenecks that impair policy transfer from demonstration-based training to high-speed, robust hardware execution. The resulting method includes system-level calibration, model-based and learning-driven speed adaptation, and end-to-end post-processing for trajectory optimization, achieving execution speeds comparable to human operators without sacrificing task reliability.
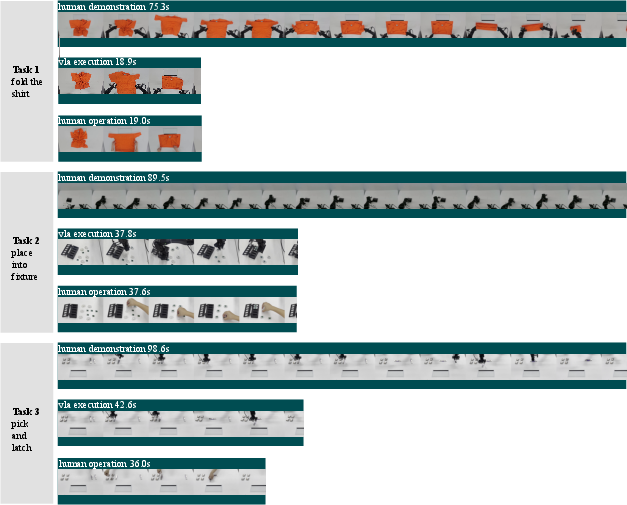
Figure 1: Example tasks used in this paper, illustrating the application domains of the proposed high-speed VLA framework.
System Delay Identification and Compensation
A central challenge addressed is the temporal misalignment between the training environment (with idealized synchronous perception and actuation) and the physical control loop, where camera latency, proprioceptive delay, image readout, and the inherent lag in robot dynamics become dominant at high speeds.
Systematic measurement and calibration techniques are proposed, including LED-phased timestamp alignment and high-frame-rate image analysis to identify and quantify individual delay components with millisecond accuracy. For instance, robot motion lag (tmotion), camera acquisition delay (tcamera), and proprioceptive feedback delay are explicitly measured and compensated.
Compensation is bifurcated: sensory alignment is achieved through history-buffer querying with the calibrated delays; control lag is counteracted via pre-amplification in trajectory post-processing, increasing the command magnitudes to align the actual joint positions with the VLA's intent under lagging dynamics.
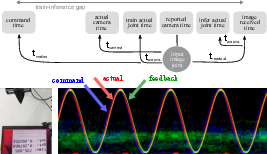
Figure 2: Schematic of system delays and train-inference temporal discrepancy.
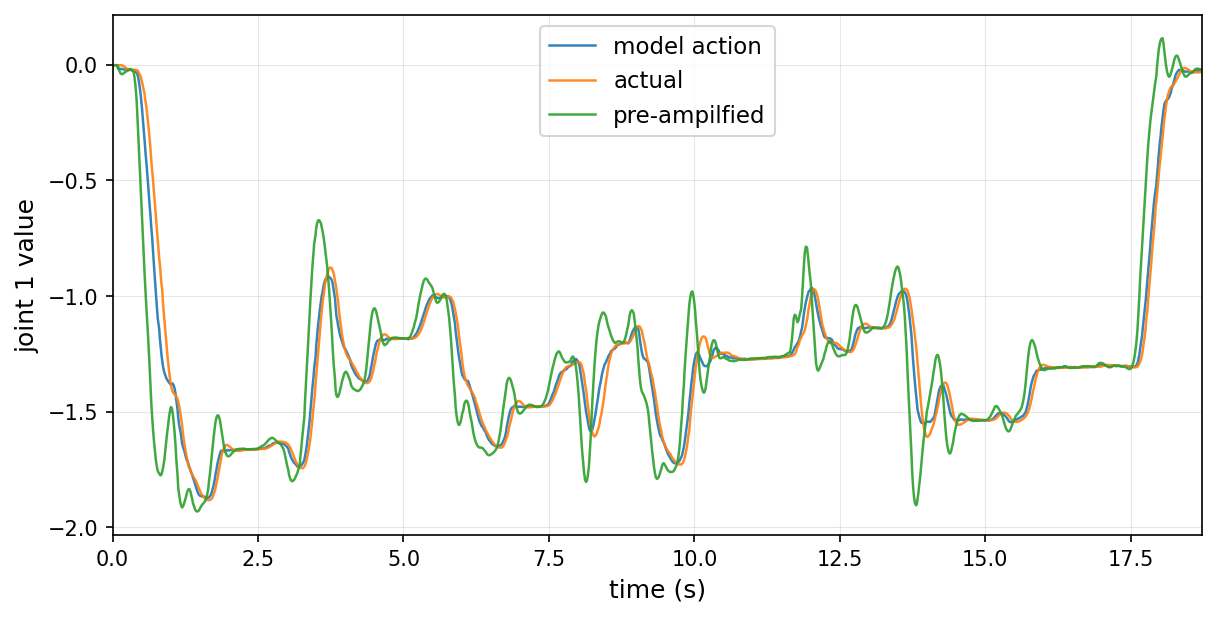
Figure 3: Pre-amplification of robot commands offsets lag to ensure accurate trajectory following at high speeds.
Trajectory Post-Processing: Temporal and Spatial Optimization
To preserve both hardware safety and policy intent under accelerated execution, the VLA output trajectory is post-processed by a client-server framework. The pipeline consists of several stages:
- Speed Adaptation and Temporal Optimization: Stage-wise velocity modulation is determined by a learned model, producing per-timestep scaling factors. Subsequently, a QP-based temporal optimizer reschedules trajectory steps to minimize acceleration peaks, subject to robot kinematic and dynamic constraints.
- Spatial Optimization and Tracking: A receding-horizon MPC (acados implementation) tracks the reference waypoints, applying model-based compensation for actuation lag and enforcing hard physical constraints on position, velocity, and acceleration.
This separation ensures that the VLA model remains agnostic to physical control idiosyncrasies, guaranteeing repeatable deployment regardless of the underlying hardware characteristics.
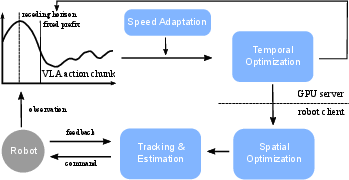
Figure 4: Post-processing framework for the VLA trajectory including speed adaptation, temporal and spatial optimization.
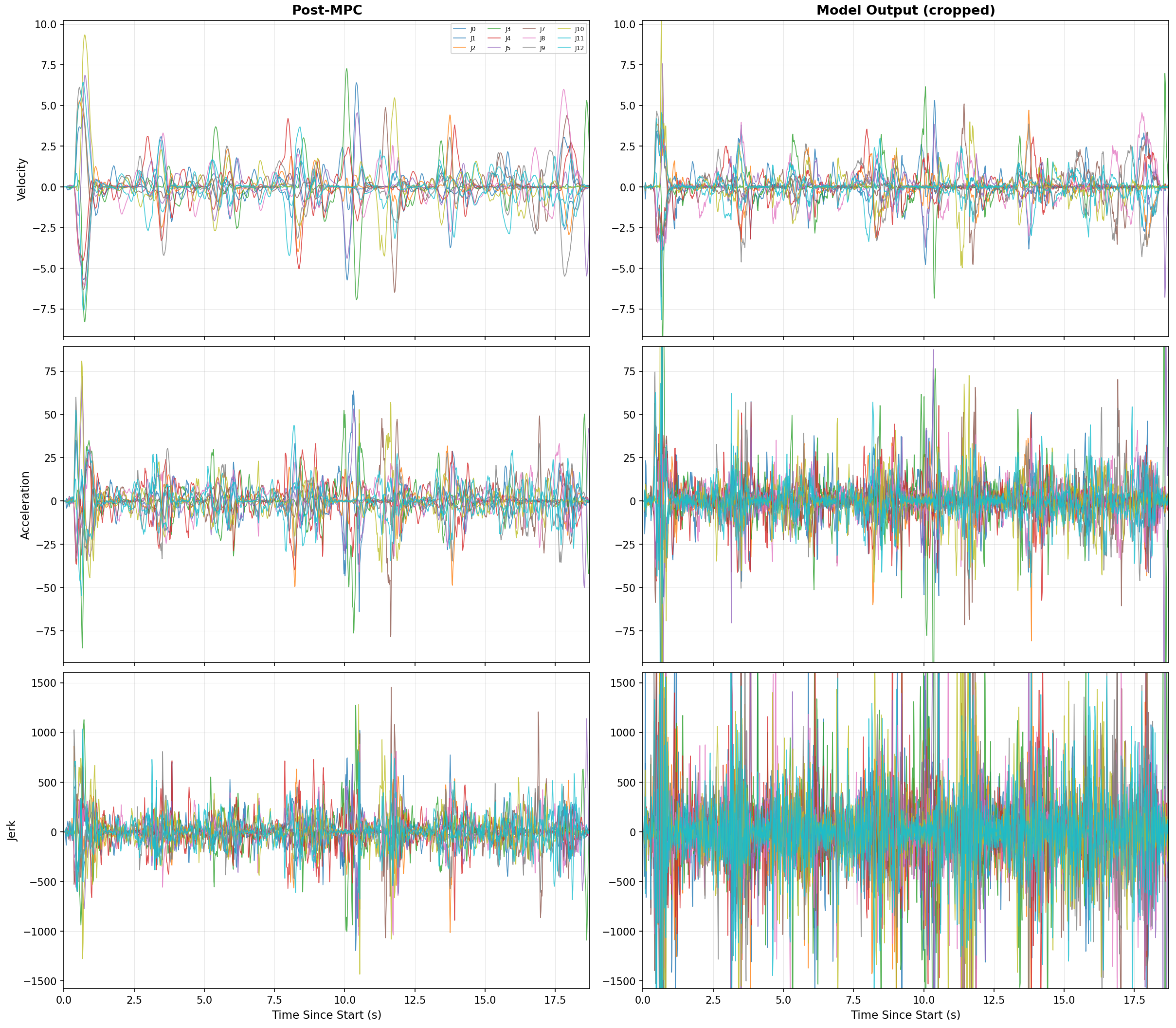
Figure 5: Profiles of velocity, acceleration, and jerk pre- and post-processing, demonstrating the suppression of spurious peaks post-optimization.
Learning High-Throughput Speed Adaptation
The policy exhibits failure at specific phases when naively sped up, with empirical evidence showing that task-critical bottlenecks (e.g., precise cloth folding or PCB insertion) cluster failures under high-speed execution.
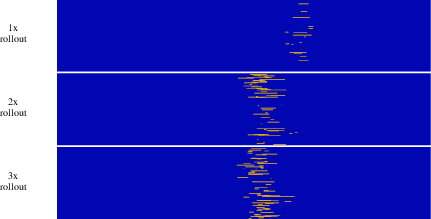
Figure 6: Distribution of failure events at multiple execution speeds, highlighting the phase-bounded nature of execution risk.
Prior approaches require extensive segmentation or hand-tuned heuristics for phase-dependent speed adjustment. In contrast, the paper explores human-in-the-loop speed modulation as a means of collecting fine-grained supervision for a regression-based speed adaptation model. Operators dynamically adjust the “throttle” during rollout, resulting in efficient and dense labeled data and enabling the policy to internalize safety-velocity tradeoffs without introducing architectural changes.
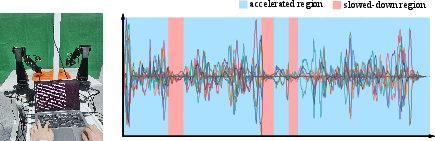
Figure 7: Human-operator provided throttle traces yield direct supervision for per-phase execution speed modulation.
Alternative approaches such as rollout-based failure-rate prediction are also discussed but exhibit overfitting and data sparsity limitations.
Experimental Validation and Upper-Bound Analysis
Tasks requiring both dexterity and precision were selected: shirt-folding, precise part insertion, and fixture latching. Across all tasks, the framework achieves execution times close to human operators, preserving accuracy and end-to-end task success without excessive retries. Notably, the framework generalizes to high-precision and high-dexterity domains.
An upper-bound analysis, inspired by the computational roofline model, segments robot motion into motion-bounded and control-bounded phases. The practical speed limit is dictated either by the physical hardware envelope (max acceleration/jerk) or by the aggregate system and control latency, which determines the feasible lookahead horizon for action chunking.
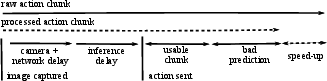
Figure 8: Upper bound model relating system delays to inference speed, characterizing the control bottleneck in chunk-based policy execution.
Post-processing yields nearly motion-bounded performance, with residual jerk and acceleration peaks thoroughly suppressed.
Implications and Prospects
The paper’s modular trajectory optimization and adaptive speed selection strategy address a critical translational gap in policy deployment: achieving robust, high-speed operation across a variety of platforms without retraining or architectural adjustment. The explicit separation of sensory, temporal, and physical compensation, supported by data-efficient speed adaptation strategies, demonstrates that current VLA policies can be leveraged to their maximum practical capacity in industrial and general robotics contexts.
Future research directions include integration of autonomous RL-based speed adaptation for further sample efficiency, scaling the framework to dual-arm or mobile platforms with more complex delay signatures, and optimizing the control stack to further decrease effective system latency and push the motion-bound to new hardware limits.
Conclusion
The presented approach combines precise delay measurement and compensation, MPC-based spatial optimization, and a data-driven, human-supervised speed modulation model to accelerate VLA policies’ real-world deployment. Empirical results manifest robust performance at near-human speed across fine-grained manipulation tasks, and upper-bound analysis confirms close approach to hardware and control constraints. The framework offers both practical and theoretical contributions toward performant and reliable vision-language-driven robotic manipulation.

