FASTER: Rethinking Real-Time Flow VLAs
Abstract: Real-time execution is crucial for deploying Vision-Language-Action (VLA) models in the physical world. Existing asynchronous inference methods primarily optimize trajectory smoothness, but neglect the critical latency in reacting to environmental changes. By rethinking the notion of reaction in action chunking policies, this paper presents a systematic analysis of the factors governing reaction time. We show that reaction time follows a uniform distribution determined jointly by the Time to First Action (TTFA) and the execution horizon. Moreover, we reveal that the standard practice of applying a constant schedule in flow-based VLAs can be inefficient and forces the system to complete all sampling steps before any movement can start, forming the bottleneck in reaction latency. To overcome this issue, we propose Fast Action Sampling for ImmediaTE Reaction (FASTER). By introducing a Horizon-Aware Schedule, FASTER adaptively prioritizes near-term actions during flow sampling, compressing the denoising of the immediate reaction by tenfold (e.g., in $π_{0.5}$ and X-VLA) into a single step, while preserving the quality of long-horizon trajectory. Coupled with a streaming client-server pipeline, FASTER substantially reduces the effective reaction latency on real robots, especially when deployed on consumer-grade GPUs. Real-world experiments, including a highly dynamic table tennis task, prove that FASTER unlocks unprecedented real-time responsiveness for generalist policies, enabling rapid generation of accurate and smooth trajectories.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper is about making robot brains that use vision and language (called Vision-Language-Action models, or VLAs) react much faster in the real world. The authors introduce a simple add-on, called FASTER, that helps these models send the robot’s very next move almost immediately—so the robot can respond quickly to what it sees, like returning a fast table-tennis ball—without needing to change the model’s design or retrain it from scratch.
What questions did the researchers ask?
They focused on one big question: how can we make robots not just move smoothly, but also react quickly to sudden changes? More specifically:
- Why do current VLA robots take too long to start moving after something changes in front of them?
- Can we reduce the “time to first action” (how long it takes to send the first move) without messing up the rest of the plan?
- Can we do this with simple changes that work on existing models and everyday computers?
How do these robots usually work, and what’s the problem?
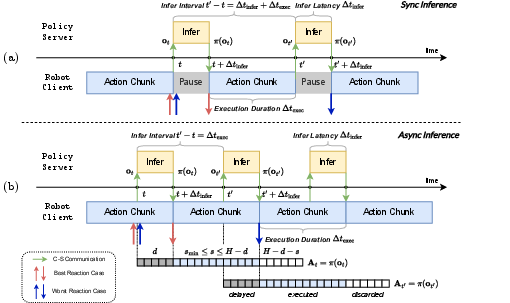
Imagine a robot that plans a short sequence of moves every time it looks around—like making a mini to-do list for the next second. This sequence is called an “action chunk.” Many modern VLAs use a technique similar to cleaning a noisy picture step by step (called “flow matching” or “denoising”) to generate that chunk. Each clean-up step takes time.
Two common ways to run these plans:
- Synchronous: the robot waits until the entire chunk is ready before moving. This can cause stop-and-go motions and slow reactions.
- Asynchronous: the robot starts moving using the current chunk while the next chunk is being prepared. This is smoother, but still doesn’t solve slow reactions if the first action in the new chunk comes late.
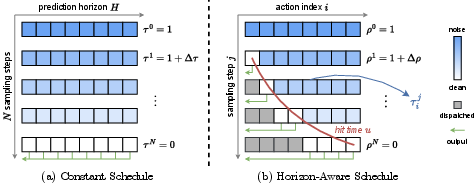
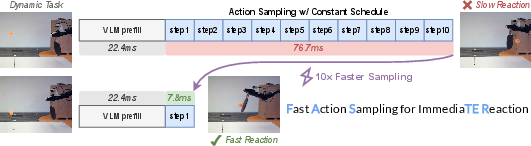
Here’s the core issue: with the usual “constant schedule,” every action in the chunk gets the same number of clean-up steps—even the very next action the robot needs right now. That means the robot can’t start moving until lots of steps are done, causing a long delay.
The authors also point out that reaction time isn’t just “how fast is your computer.” Because events (like a ball arriving) can happen at any moment between planning cycles, the actual reaction delay varies, almost like a random wait between two bus arrivals. So to be truly responsive, you need both low delay per plan and frequent plans.
What is FASTER and how does it work?
FASTER is a “plug-and-play” method that changes how the model allocates its clean-up steps across the action chunk so the robot can send its next move much sooner. Think of it as prioritizing the first move in the to-do list so it’s ready immediately, while still refining the later moves in the background.
Key ideas, explained simply:
- Action chunk: a short sequence of future moves (e.g., 50 small motions).
- Denoising/flow matching: turning a rough guess into a clean plan step by step.
- Time to First Action (TTFA): how long it takes to produce the very first move after new information arrives. This is the most important number for reacting fast.
What FASTER changes:
- Horizon-Aware Schedule (HAS): instead of giving every future action the same number of steps, FASTER gives:
- Very few steps (even just one) to the immediate next action.
- More steps to later actions, which are harder to predict.
- Streaming output: as soon as the first action is ready, the server sends it to the robot, while it keeps working on the rest of the sequence.
- Early stopping: if the robot only needs the next few actions right now, FASTER can stop early and skip computing unused steps, then start the next cycle sooner.
Analogy: If you’re racing to catch a ball, you don’t write a perfect 50-step plan before you start moving. You take the first step immediately, then plan the next steps as you go. FASTER teaches the robot to do exactly that.
What did they find?
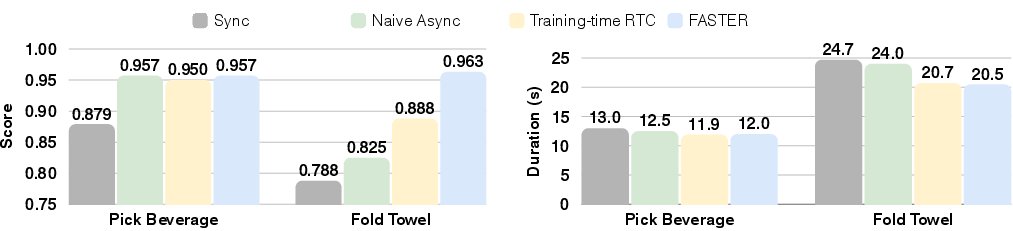
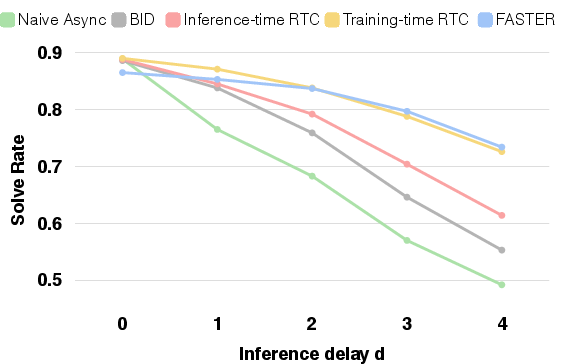
- Much faster first reactions: FASTER compresses the “denoising” for the first action into a single step, cutting Time to First Action by up to about 3× in some setups and around 10× for the action expert portion of the model in certain systems.
- Works on regular hardware: It speeds things up on both powerful GPUs (like an RTX 4090) and consumer laptops (like an RTX 4060).
- Real robots react better: In a table tennis task, the robot using FASTER reacted quickly enough to position and swing the racket at good angles, leading to better hits compared to standard methods.
- Smoothness and accuracy remain strong: Even though FASTER prioritizes the immediate action, it continues refining later actions, so overall movement stays accurate and smooth. In simulator tests, performance stayed competitive with only small drops.
- More frequent planning: Because the first actions come sooner and FASTER can stop early, the robot can start the next planning cycle earlier too—helping it react to new changes more often.
Why is this important?
- Real-time reliability: In the physical world, things change fast—a person moves, an object slips, a ball bounces. Faster reactions make robots safer, more capable, and more useful.
- Easy to adopt: FASTER doesn’t require redesigning the robot’s brain or retraining from scratch. It’s a scheduling and streaming change that can be added to existing flow-based VLAs.
- Better on everyday devices: Since it helps especially on smaller GPUs, FASTER makes real-time robot control more accessible and affordable.
- Stronger foundation for “generalist” robots: It moves VLAs closer to behaving like attentive, agile assistants that can adapt quickly, not just produce smooth motions.
In short, this paper shows a smart, simple way to make robot models react faster by giving priority to the immediate next move, streaming it out right away, and keeping the rest of the plan refining in the background—leading to robots that feel far more “alive” and responsive in the real world.
Knowledge Gaps
Below is a single, consolidated list of concrete knowledge gaps, limitations, and open questions left unresolved by the paper. These pinpoint what is missing, uncertain, or unexplored, and suggest actionable directions for future work.
- Assumption validity of reaction-time model: The analysis treats inference latency as constant and event arrivals as uniformly distributed; the impact of latency jitter, OS scheduling, network variability, and non-uniform or state-correlated event timing on the reaction-time distribution is untested.
- TTFA definition vs. actuation latency: TTFA excludes actuator/low-level controller delays and servo ramp-up; how including motor dynamics changes reaction-time bounds and practical responsiveness is not analyzed.
- Minimal-execution-horizon constraint: The s_min derivation assumes deterministic timing and single-threaded control; how preemption, multi-threading, and varying control frequencies affect feasible s_min and stability is not evaluated.
- Robustness under sensor delays and noise: The framework assumes timely, clean observations; resilience of HAS and streaming to camera/encoder lag, dropped frames, and sensor noise is untested.
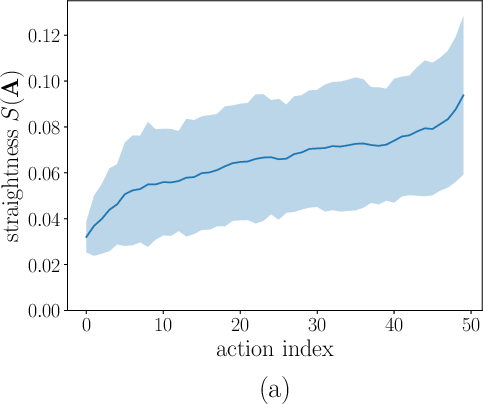
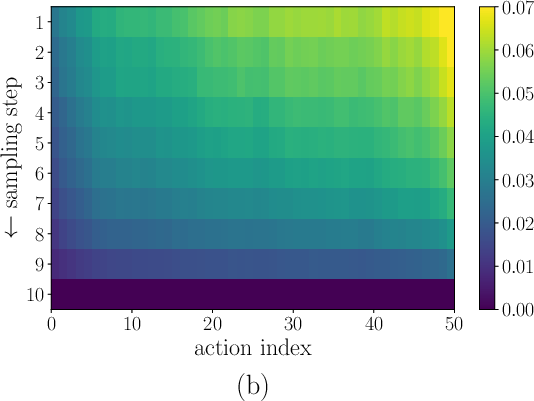
- Generality of “early actions are easier”: The straightness metric evidence is limited to a few tasks; whether this holds across domains (e.g., non-causal tasks, partially observable settings, contact-rich manipulation) remains unverified.
- Causal uncertainty edge cases: In tasks where immediate actions are intrinsically ambiguous (e.g., multiple valid reactions early on), compressing to one-step for the first action may harm accuracy; criteria to detect and relax compression are not proposed.
- Sensitivity to HAS hyperparameters: The effects of α, u0, and N on reaction speed, stability, and accuracy lack a systematic sensitivity analysis or principled hyperparameter selection guidelines.
- Mixed-schedule fine-tuning: The mixing probability p and its scheduling are not justified or ablated; whether plug-and-play (inference-only) HAS without any fine-tuning preserves performance remains unclear.
- Trade-off quantification: The speed–accuracy trade-off (short-horizon reaction vs. long-horizon fidelity) is qualitatively discussed but lacks quantitative curves across multiple α/u0/N settings and tasks.
- Early-stopping impacts: Skipping remaining AE steps once s actions are finalized can bias the remaining trajectory and affect inter-chunk continuity; long-term drift and compounding errors in closed-loop operation are not analyzed.
- Stability guarantees: No theoretical or empirical analysis of closed-loop stability/passivity when dispatching partially denoised, rapidly produced actions is provided.
- Safety and constraint handling: Immediate actions produced with minimal denoising may violate joint limits, torque limits, or collision constraints; integration with safety layers or constraint-aware sampling is not addressed.
- Communication reliability in streaming: The streaming interface omits handling of packet loss, out-of-order arrivals, clock drift, and time-stamping; how these affect buffer management and control safety is unexamined.
- Impact on motion smoothness: While reaction speed is improved, the effect of streaming partial actions on jerk, continuity, and user-perceived smoothness (beyond RTC conditioning) is not quantified.
- Generalization across VLA families: Results are presented for π0.5 and X-VLA; applicability to other flow models, diffusion models with different solvers, autoregressive token VLAs, or hybrid architectures is not studied.
- Solver dependence: HAS is demonstrated with Euler integration; interactions with higher-order/implicit ODE solvers, adaptive-step solvers, or flow matching variants are unexplored.
- Learned or adaptive schedules: The schedule is hand-crafted; learning α/u0 or conditioning the schedule on observation uncertainty, score norms, or predictive variance is an open direction.
- Per-DoF/per-dimension scheduling: HAS allocates by action index only; whether per-joint or task-space dimension–wise timestepping (based on difficulty/uncertainty) yields further gains is not investigated.
- Multi-robot and dual-arm coordination: The approach is not evaluated in settings requiring synchronized multi-effector timing, where different limbs may need different reaction-time priorities.
- Benchmarking TTFA: TTFA is introduced but lacks a standardized community evaluation protocol; its correlation with task success and human-perceived responsiveness across diverse tasks remains to be established.
- Real-world evaluation breadth and statistics: Real-robot tests span few tasks (notably table tennis) with limited data; broader task diversity, more trials, statistical significance testing, and cross-site reproducibility are missing.
- Extremely resource-constrained hardware: Evaluations are on RTX 4090/4060; performance on embedded/edge platforms (e.g., Jetson Orin, CPU-only, MCU co-processors) and under tight power/thermal budgets is not reported.
- Networked/remote deployments: The method is not evaluated over wide-area or congested networks where variable latency and bandwidth limitations may alter the reaction pipeline.
- Interaction with other efficiency techniques: Synergy and interference with quantization, pruning, token compression, distilled/consistency models, or speculative action decoding are only qualitatively discussed.
- Compatibility with other asynchronous controllers: The method is framed around RTC-like conditioning; how it integrates with alternative inpainting/trajectory blending or MPC-based smoothing is not demonstrated.
- Long-horizon accumulation: The observed “marginal degradation” in simulation lacks analysis of how errors accumulate over many chunks in extended tasks or under distribution shift.
- Event-triggered inference: The pipeline uses fixed-frequency inference; whether event-triggered or adaptive-rate inference (e.g., based on novelty/uncertainty) further reduces reaction times is not explored.
- Task-dependent horizon selection: Guidelines for choosing H and s across tasks to jointly optimize reaction and success are not provided; automatic horizon tuning is an open question.
- Contact and tactile feedback: Reaction to tactile events or force thresholds (common in manipulation) is not considered, limiting conclusions to vision-dominant setups.
- Energy and wear: The influence of faster, possibly more abrupt reactions on energy consumption, actuator heating, and mechanical wear is unmeasured.
- Failure recovery: How the system detects and recovers from misreactions (e.g., wrong first action due to minimal denoising) is not addressed.
- Uncertainty calibration: Whether one-step first actions are well-calibrated (epistemic/aleatoric) and how to communicate uncertainty to low-level controllers is not analyzed.
- Distributional shifts: The impact of applying HAS during deployment on out-of-distribution robustness (lighting, objects, dynamics) is unreported.
- Public release and reproducibility: While a URL is provided, details about code, datasets, trained checkpoints, and scripts to reproduce TTFA/evaluation are not explicitly stated.
Practical Applications
Immediate Applications
Below is a curated set of actionable, near-term use cases that can be deployed with current capabilities of FASTER (Horizon-Aware Schedule, streaming client–server, early stopping) on flow-based VLA policies, especially on consumer-grade GPUs.
- High-throughput dynamic bin picking and conveyor tracking
- Sectors: Robotics, Manufacturing, Logistics
- What: Deploy manipulators that must react to moving parts on conveyors or randomly arriving items in bins, reducing misses due to delayed reactions.
- Tools/products/workflows: FASTER-enabled VLA action server (ROS2/gRPC streaming), TTFA monitor to auto-tune execution horizon s and α, drop-in plugin for π0/π0.5/X-VLA; RTC-style action conditioning for smooth chunk transitions.
- Assumptions/dependencies: Flow-based VLA already trained on task; robot controller can accept streaming action updates; network latency is bounded; safety stops in place for mispredictions.
- Human–robot collaboration with fast intent response
- Sectors: Robotics, Manufacturing, Service
- What: Co-bots that adjust grasp, pose, or trajectory in response to human motion or verbal instruction changes without “stop-and-wait.”
- Tools/products/workflows: FASTER streaming with small s_min, vision-language updates on-the-fly, confidence gating and rollback safeguards, HRI supervision UI with TTFA dashboard.
- Assumptions/dependencies: Reliable perception (people detection/intent cues); action conditioning to avoid discontinuities; safety-certified speed/force limits.
- Order-fulfillment picking in warehouses with moving bases
- Sectors: Robotics, Logistics, Retail
- What: Mobile manipulators that must replan grasps while the base and target are in motion (e.g., cart following, shelf picking).
- Tools/products/workflows: ROS2 integration; FASTER server running on edge GPU (e.g., RTX 4060 or Jetson-class) with streaming; early-stop once the next s actions are finalized to increase cycle frequency.
- Assumptions/dependencies: Stable wireless link to server; accurate localization/tracking; action chunking policy aligned with base/manipulator kinematics.
- Dynamic object interception and sports training robots
- Sectors: Robotics, Sports/Entertainment, Research
- What: Table-tennis, ball passing, or juggling robots that require immediate reaction to fast-moving objects.
- Tools/products/workflows: FASTER schedule with u0 set for single-step first action; reaction-focused benchmark harness with TTFA and probabilistic reaction-time analysis; training RTC for smoothness.
- Assumptions/dependencies: High-frame-rate sensing; motion capture or robust ball tracking; tuned control loop (e.g., 30 Hz+) and action buffers.
- Household service robots responding to clutter and people
- Sectors: Consumer Robotics, Daily Life
- What: Home assistants that adjust grasp or path when a pet/person moves an object, fold laundry while responding to disturbances, or pick/place under clutter.
- Tools/products/workflows: FASTER plugin in home-robot SDKs; streaming action buffer with guardrails (velocity/acceleration limits, collision checks); optional cloud-edge deployment.
- Assumptions/dependencies: Diverse demonstrations for generalization; reliable onboard sensing; home-safe behavior constraints.
- Real-time teleoperation assistance with predictive autonomy
- Sectors: Robotics, Industrial Services, Defense
- What: Shared autonomy that reacts to operator high-level language intent and environment changes while smoothing control latency.
- Tools/products/workflows: VLA with FASTER to produce immediate corrective actions between operator commands; UI showing TTFA and reaction probability; rollback-on-drift strategy.
- Assumptions/dependencies: Communication QoS; operator-in-the-loop oversight; task-specific fail-safes.
- On-device, cost-efficient edge robotics deployments
- Sectors: Robotics, Hardware, Startups
- What: Achieve near-real-time responsiveness on consumer-grade GPUs or compact edge modules by compressing immediate-action sampling.
- Tools/products/workflows: FASTER-instrumented inference servers; parameter auto-tuner to pick s_min and α per device; profiling tools to keep acquisition rate ahead of control frequency.
- Assumptions/dependencies: Adequate thermal/power budget; stable CUDA/driver stack; flow-based AE (action expert) present.
- Academic benchmarking and methodology baselines
- Sectors: Academia, Open-Source
- What: Standardize TTFA as a core metric; evaluate streaming VLA pipelines; publish reaction-centric benchmarks (conveyor pick, human perturbation).
- Tools/products/workflows: Open-source FASTER schedule + streaming reference implementation; synthetic “perturbation clocks” to induce randomized events; uniform-reaction-time analysis scripts.
- Assumptions/dependencies: Shared evaluation protocols; access to representative datasets; community adoption.
- Real-time VLA serving infrastructure
- Sectors: Software, MLOps
- What: Inference servers that stream actions as they finalize and early-stop after the next s actions are ready.
- Tools/products/workflows: gRPC/ROS2 streaming endpoints; TTFA-aware autoscaling; canary deployments comparing constant vs. horizon-aware schedules.
- Assumptions/dependencies: Backward-compatible API to existing controllers; observability stack to track TTFA, reaction CDFs, s_min.
- Safety wrappers for streaming control
- Sectors: Robotics Safety, Compliance
- What: Add control barrier functions and runtime checks to safely execute streamed immediate actions without oscillation or unsafe accelerations.
- Tools/products/workflows: Confidence-gated action dispatch; rate limiters and jerk bounds; “pause/fallback” when TTFA spikes or buffer underflows.
- Assumptions/dependencies: Verified kinematic/dynamic models; policy confidence signals or outlier detection.
Long-Term Applications
These opportunities are promising but likely require further research, scaling, safety validation, or domain adaptation before widespread deployment.
- Surgical and clinical assistive robotics
- Sectors: Healthcare
- What: Rapid micro-adjustments to tissue motion or tool–organ interactions with strict safety and explainability.
- Tools/products/workflows: FASTER-enabled surgical VLA with surgeon-in-the-loop oversight; certified streaming controller; reaction-time guarantees in safety cases.
- Assumptions/dependencies: Regulatory approval; clinically validated datasets; stringent fail-safe mechanisms; high-frequency sensing and deterministic latency.
- Human-robot collaboration standards for responsiveness
- Sectors: Policy, Standards, Manufacturing
- What: Define procurement and safety standards that include TTFA and reaction-time distributions as acceptance criteria for collaborative robots.
- Tools/products/workflows: TTFA benchmarking suites; standardized reporting formats; certification procedures referencing reaction CDFs and upper bounds.
- Assumptions/dependencies: Multi-stakeholder consensus (industry, regulators, standards bodies); reproducible testbeds.
- Autonomous driving and micromobility planning with action streaming
- Sectors: Transportation
- What: Apply horizon-aware scheduling to planning policies that generate action sequences (e.g., short-horizon control with continual refinement).
- Tools/products/workflows: Planner with “first-control-now, refine-later” streaming; TTFA-equivalent metric for control latency; mixed-schedule fine-tuning for diffusion/flow planners.
- Assumptions/dependencies: Transfer of flow-based action chunking to driving stacks; real-time perception–planning fusion; formal safety validation.
- Drones and agile mobile robots in cluttered environments
- Sectors: Robotics, Public Safety, Inspection
- What: Immediate evasive/reactive maneuvers while refining longer-horizon paths for navigation and inspection.
- Tools/products/workflows: High-rate FASTER-like scheduling adapted to higher control frequencies; onboard edge deployment; streaming to flight controllers with barrier functions.
- Assumptions/dependencies: Adaptation of action chunking to high-rate control (100–400 Hz); lightweight models for embedded GPUs/NPUs.
- Exoskeletons and prosthetics with fast intent alignment
- Sectors: Healthcare, Assistive Tech
- What: React instantly to user intent changes while planning smooth multi-step assistance.
- Tools/products/workflows: VLA integrating biosignals (EMG/IMU) with FASTER streaming; intent confidence gating; per-user adaptive scheduling.
- Assumptions/dependencies: Robust multimodal sensing; personalized calibration; safety and comfort constraints.
- Industrial process and assembly with variable takt time
- Sectors: Manufacturing
- What: Stations that re-time and re-orient motions when upstream/downstream variability occurs, minimizing idle time and rejects.
- Tools/products/workflows: Reaction-aware scheduling tied to MES/PLC events; TTFA-driven takt optimization; predictive buffering for action chunks.
- Assumptions/dependencies: Tight MES/PLC integration; domain demonstrations; redundancy for safety interlocks.
- Consumer-grade generalist home robots
- Sectors: Consumer Electronics, Daily Life
- What: Broad household tasks under dynamic conditions (pets, kids, clutter) with low-cost hardware.
- Tools/products/workflows: FASTER-enabled generalist VLA with on-device inference and cloud-fallback; auto-tuned α/u0 per task; reaction analytics in companion app.
- Assumptions/dependencies: Scalable data collection; robust generalization; privacy/security; cost-effective edge accelerators.
- Hardware–algorithm co-design for real-time VLAs
- Sectors: Semiconductors, Robotics
- What: AE-optimized accelerators and schedulers that guarantee single-step immediate-action latency under bounded loads.
- Tools/products/workflows: Schedulers that prioritize near-term action kernels; memory layouts for streaming; hardware TTFA SLAs.
- Assumptions/dependencies: Vendor ecosystem support; workload characterization; standardized VLA model interfaces.
- Unified reaction-centric benchmarks and leaderboards
- Sectors: Academia, Open-Source, Policy
- What: Community evaluation suites comparing reaction time distributions, TTFA, and success under perturbations across tasks.
- Tools/products/workflows: Open datasets with stochastic event timings; leaderboards reporting mean/upper-bound reaction under fixed control frequencies; “reaction under load” stress tests.
- Assumptions/dependencies: Shared task definitions; broad participation; reproducible infrastructure.
Cross-cutting assumptions and dependencies
- Model compatibility: FASTER assumes flow-based VLA with action chunking (e.g., π0/π0.5, X‑VLA); adaptation to diffusion-only or token-action models may require additional research.
- Training and fine-tuning: Mixed schedule fine-tuning and (optionally) action conditioning help bridge the distribution gap from constant schedules.
- Systems integration: Benefits depend on a streaming-capable client–server stack (ROS2/gRPC), bounded network latency, and controllers that can buffer and safely execute streamed actions.
- Safety and verification: Streaming immediate actions require guardrails (rate limits, collision checks, barrier functions) and rollback strategies.
- Sensing and control: High-quality, timely perception and a control loop where the action acquisition rate exceeds control frequency are necessary to realize TTFA gains.
- Task data and generalization: Demonstrations or datasets must cover the dynamic regimes in which fast reactions are required.
Glossary
- Action chunking: Splitting a policy’s predicted action sequence into fixed-length segments executed in parts to enable periodic inference and control. "action chunking policies"
- Action conditioning: Conditioning the model on previously executed or predicted actions (prefixes) to guide smooth transitions in new predictions. "the action conditioning technique"
- Action Expert (AE): A dedicated module that generates continuous low-level actions conditioned on vision-language features. "a VLM backbone and an action expert (AE) module"
- Asynchronous inference: Triggering the next model inference before the current action segment finishes executing to avoid pauses. "asynchronous inference"
- Asynchronous pipeline: A client-server execution scheme where inference and execution overlap to maintain continuous motion. "an asynchronous pipeline"
- Closed-loop control: Control where actions are continually updated based on current observations, creating feedback; delays can cause a “blind spot.” "closed-loop control"
- Conditional flow matching: A training approach for continuous generation that learns a velocity field mapping noise to data conditioned on inputs. "using conditional flow matching"
- Control period: The fixed time between controller updates, the inverse of control frequency. "Control period := 1/f"
- Denoising process: The multi-step procedure that iteratively refines noisy samples into clean actions during flow/diffusion sampling. "multi-step denoising process"
- Diffusion Forcing: A scheduling technique from diffusion literature that guides sampling progression, inspiring index-dependent timesteps. "Inspired by Diffusion Forcing"
- Diffusion models: Generative models that transform noise into data through iterative denoising, used here for action generation. "leveraging diffusion models"
- Discretized inference delay: The number of control steps by which newly inferred actions lag due to inference latency. "the discretized inference delay "
- Execution horizon: The number of predicted actions executed before triggering the next inference. "the execution horizon "
- Flow matching: A generative modeling framework that learns a continuous-time vector field transporting noise to data. "flow matching"
- Flow-based VLAs: Vision-Language-Action models that generate continuous actions with flow-based samplers instead of token decoders. "flow-based VLAs"
- Generative sequence modeling: Framing continuous motor control as generating future action sequences conditioned on observations and language. "generative sequence modeling problem"
- Hit time: The timestep at which an individual action within a chunk is considered fully denoised and ready to dispatch. "hit time"
- Horizon-Aware Schedule (HAS): An index-dependent sampling schedule that prioritizes and accelerates near-term actions while keeping later ones slower. "Horizon-Aware Schedule (HAS)"
- Inference-execution cycle: The repeated loop of running inference and executing a portion of predicted actions; its frequency affects reaction speed. "frequency of inference-execution cycle"
- Inference latency: The end-to-end time from sending an observation to receiving predicted actions, including compute and I/O. "Inference latency"
- Inpainting: Filling in or refining parts of a predicted action sequence conditioned on existing context to ensure smooth transitions. "RTC inpaints the next action chunk"
- Inter-chunk discontinuity: Abrupt motion changes when switching between action chunks due to mismatches or delays. "inter-chunk discontinuity"
- ODE solver: A numerical method (e.g., Euler) used to integrate the learned velocity field over timesteps during sampling. "an ODE solver such as the Euler method"
- Optimal transport formulation: Training formulation assuming linear paths from noise to data and regressing the transport velocity. "Training follows the optimal transport formulation"
- Perception-execution gap: The mismatch between the time an observation is captured and when its corresponding actions are executed. "perception-execution gap"
- Prediction horizon: The number of future actions predicted in each chunk by the policy. "the prediction horizon"
- Proprioceptive states: Internal robot states (e.g., joint angles/velocities) used with observations to inform near-term actions. "observations and proprioceptive states"
- Reaction latency: The delay between an external event and the robot’s resulting motion; a key bottleneck for responsiveness. "reaction latency"
- Streaming client-server interface: A communication setup where finalized actions are sent and consumed as they become available, without waiting for the full chunk. "a streaming client-server interface"
- Straightness metric: A measure of how linear the denoising trajectory is; straighter paths can be integrated with fewer steps. "the straightness metric"
- Time to First Action (TTFA): The time from request to when the first action is ready, the critical determinant of responsiveness. "Time to First Action (TTFA)"
- Time to First Token (TTFT): A latency measure from LLMs used by analogy to motivate TTFA for action generation. "Time to First Token (TTFT)"
- Velocity field: The learned vector field that directs samples from noise toward target actions across timesteps. "learning a velocity field"
- Vision-LLMs (VLMs): Models pretrained to process and align visual inputs with language, serving as backbones in VLAs. "Vision-LLMs~(VLMs)"
- Vision-Language-Action (VLA) models: Models that map visual and language inputs to continuous action outputs for robotics. "Vision-Language-Action (VLA) models"
Collections
Sign up for free to add this paper to one or more collections.