VLASH: Real-Time VLAs via Future-State-Aware Asynchronous Inference
Abstract: Vision-Language-Action models (VLAs) are becoming increasingly capable across diverse robotic tasks. However, their real-world deployment remains slow and inefficient: demonstration videos are often sped up by 5-10x to appear smooth, with noticeable action stalls and delayed reactions to environmental changes. Asynchronous inference offers a promising solution to achieve continuous and low-latency control by enabling robots to execute actions and perform inference simultaneously. However, because the robot and environment continue to evolve during inference, a temporal misalignment arises between the prediction and execution intervals. This leads to significant action instability, while existing methods either degrade accuracy or introduce runtime overhead to mitigate it. We propose VLASH, a general asynchronous inference framework for VLAs that delivers smooth, accurate, and fast reaction control without additional overhead or architectural changes. VLASH estimates the future execution-time state by rolling the robot state forward with the previously generated action chunk, thereby bridging the gap between prediction and execution. Experiments show that VLASH achieves up to 2.03x speedup and reduces reaction latency by up to 17.4x compared to synchronous inference while fully preserving the original accuracy. Moreover, it empowers VLAs to handle fast-reaction, high-precision tasks such as playing ping-pong and playing whack-a-mole, where traditional synchronous inference fails. Code is available at https://github.com/mit-han-lab/vlash
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Simple Summary of the Paper
Overview
This paper introduces VLASH, a way to make robot control faster and smoother. It focuses on Vision-Language-Action (VLA) models—AI systems that look at the world (vision), understand instructions (language), and decide what a robot should do next (action). VLASH helps these robots react quickly and move continuously, instead of stopping and starting.
What questions did the researchers ask?
They wanted to fix a common problem in real robot demos: robots often move slowly and jerkily because they wait for the AI to “think” before acting. The researchers asked:
- How can robots keep moving smoothly while the AI is still computing the next actions?
- How can we avoid mistakes that happen when the robot acts on plans that were made for an earlier moment in time?
- Can we make this work without slowing things down or changing the model’s design?
How did they approach the problem?
Think of this like playing a video game with lag. If your character moves while you’re planning your next move, your plan might be wrong by the time it happens. The paper tackles this with three ideas:
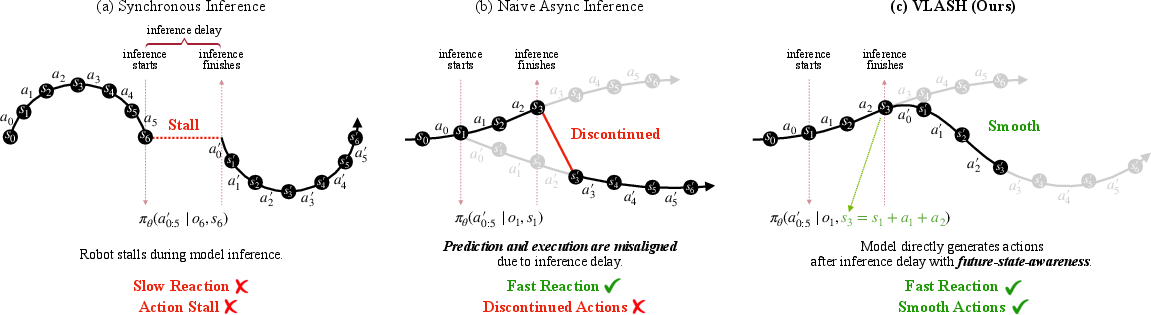
- Synchronous vs. Asynchronous control:
- Synchronous (stop-and-go): The robot thinks first, then moves. This causes delays and choppy motion.
- Asynchronous (think-while-moving): The robot keeps moving while the AI computes the next actions. This is smoother, but introduces “lag” problems.
- The lag problem (misalignment):
- While the model is “thinking,” the robot is still moving. So the actions the model planned might be for the old state (where the robot used to be), not the state where the actions will actually start. That mismatch can make movements unstable or wrong.
- VLASH’s solution: Future-State Awareness
- Analogy: If you know you’ll take two steps while you’re deciding your next move, you can predict where you’ll be after those two steps and plan from there.
- VLASH estimates the robot’s future state (where it will be when the next actions start) by “rolling forward” based on the actions already in progress.
- The model then uses the current camera image plus that predicted future robot state to plan the next action chunk. This lines up the plan with the moment it will actually be executed.
To make sure the model learns to use this future state properly, the paper also adds two training and execution tricks:
- Training with temporal offsets:
- During fine-tuning, the same image is paired with different future robot states and the matching actions. This teaches the model to pay attention to the robot’s state, not just the image.
- Efficient fine-tuning (shared observation):
- Since many training examples reuse the same image, VLASH packs them together so the image is processed once, saving time.
- Action quantization (speed boost):
- Analogy: Instead of taking lots of tiny steps, take bigger steps that reach the same place. VLASH groups small “micro-actions” into “macro-actions” to make the robot move faster without losing too much accuracy.
What did they find?
Across simulations and real robots, VLASH made control faster, smoother, and more responsive, while keeping accuracy high.
Key results include:
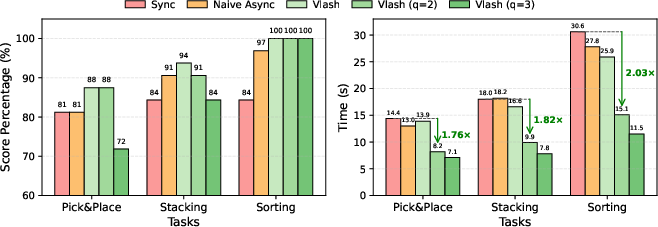
- Faster overall performance: Up to about 2.03× speedup in task completion time compared to the stop-and-go approach.
- Much quicker reactions: Up to around 17.4× reduction in reaction delay (the time it takes to respond to changes).
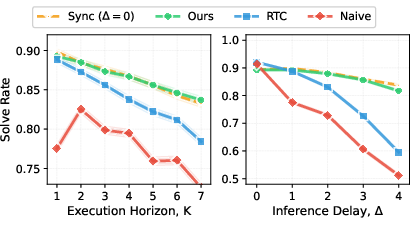
- Stable and accurate motion: VLASH avoided the instability seen in naive asynchronous methods and matched or beat the accuracy of the stop-and-go method.
- Handles fast, dynamic tasks: Robots could do things like playing ping-pong and whack-a-mole—tasks that need quick, continuous movement—where the stop-and-go method failed.
- More efficient training: The shared observation trick sped up training steps by about 3.26×, while reaching similar final accuracy.
Why this matters:
- Robots move more like humans: continuous, responsive, and smooth, even in fast-changing situations.
- No special model redesign: VLASH works with existing VLA models without changing their architecture or adding extra runtime overhead.
Why does it matter?
This work helps bring real-time, responsive robots closer to everyday use. With VLASH:
- Robots can safely and smoothly interact with people and fast-moving objects.
- Tasks like sports, quick sorting, or dynamic assembly become more achievable.
- Companies and researchers can adopt asynchronous control without complicated changes or extra costs.
- It opens the door for VLAs to handle more dynamic, hands-on jobs—not just slow, static tasks.
In short, VLASH teaches robots to “plan for where they’ll be, not where they were,” making them faster, steadier, and smarter in the real world.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of unresolved issues that future researchers could address to extend, validate, or generalize the paper’s findings.
- Future-state estimation only leverages the robot’s commanded actions and a simple additive roll-forward; there is no modeling of true dynamics (e.g., actuator saturation, delays, contact dynamics, compliance, sensor latencies), which can make the estimated execution-time state diverge from reality. How to integrate learned or physics-based dynamics models to predict realized (not just commanded) state?
- The method assumes the actions issued during inference are known and executed as planned; low-level controllers may clip, retime, or modify actions. Can VLASH incorporate measured proprioceptive feedback in-flight (e.g., encoder/force data) to re-estimate the execution-time state robustly?
- The environment observation is stale at inference time (no future observation prediction is used). What are the gains from adding predictive perception (e.g., short-horizon video forecasting, object motion prediction) to align both robot and environment states at execution?
- Inference delay is treated as discrete and relatively constant; real deployments have stochastic latency/jitter and variable execution horizons . How to make VLASH robust to time-varying, uncertain delays and asynchronous sensor/actuator clocks (e.g., via delay estimation and uncertainty-aware policies)?
- The roll-forward assumes a delta-action integration () without explicit kinematics/dynamics constraints. What is the impact on high-speed and contact-rich tasks, and can constrained integration or model predictive rollouts improve alignment?
- No formal safety or stability guarantees are provided for asynchronous control with future-state awareness and action quantization. Can we derive closed-loop stability bounds or safety certificates (e.g., control barrier functions) under bounded delay and quantization?
- Action quantization is chosen heuristically (fixed per task) without a principled selection or adaptation mechanism. How to design adaptive quantization that balances speed and precision online based on task phase, error, or uncertainty?
- The interaction between action quantization and contact/precision tasks is not analyzed (e.g., overshoot near delicate grasps). What are the failure modes and safeguards for quantized control in fine-manipulation?
- The offset augmentation trains on but does not analyze the optimal offset distribution, range , or sampling strategy. How do these choices affect convergence, stability, and robustness across delays and hardware?
- Shared-observation training packs multiple offsets into a single sequence; there is no analysis of potential gradient interference, token competition, or representation entanglement between offsets. Can multi-task or mixture-of-experts strategies mitigate negative transfer?
- The paper claims VLAs under-utilize robot state, but provides limited ablation evidence across architectures and tasks. What architectural modifications (e.g., dedicated state encoders, cross-attention patterns, normalization schemes) systematically improve state utilization?
- Evaluation compares against Sync, Naive Async, and RTC; a concurrent approach (A2C2) that adds correction heads is not empirically benchmarked here. How does VLASH perform relative to correction-head methods, and can they be combined (future-state + correction/inpainting)?
- Kinetix experiments use an MLP-Mixer flow policy and rather than full VLA models for the dynamic benchmark. Does VLASH’s benefit persist with large VLAs on Kinetix-like dynamic tasks, and what are the scaling behaviors?
- LIBERO tasks are relatively slow/deterministic; as acknowledged, asynchronous methods behave similarly there. A standardized dynamic, high-reactivity benchmark (beyond ad hoc demos) is missing. Can the community establish quantitative dynamic-interaction suites (e.g., ball tracking, tool interception, human-robot table tennis) with metrics like reaction latency, trajectory smoothness, and task success?
- Ping-pong and whack-a-mole demos lack quantitative evaluation (e.g., rally length distributions, hit/miss ratio, ball speed ranges, latency traces, smoothness metrics) and reproducible protocols. Providing datasets and standardized metrics would enable rigorous comparison.
- Real-world manipulation evaluation uses 16 rollouts per task without confidence intervals or statistical tests; results may be underpowered. Future work should report variance, CIs, and significance to substantiate improvements.
- The approach relies on accurate time alignment among sensing, inference, and actuation; camera exposure and software pipelines introduce additional latency/misalignment not modeled. How to implement end-to-end time-stamping and synchronization, and what is the sensitivity to sensor delays?
- It is unclear how VLASH behaves when inference latency exceeds execution horizon (i.e., inference cannot be fully hidden by execution). Is there a scheduling policy (e.g., variable , adaptive chunk length) to maintain continuity under compute-constrained conditions?
- Memory/runtime implications of packing many offsets are not fully explored; large may increase sequence length, context usage, and training instability. What are the practical limits, and how does performance scale with ?
- Generalization across embodiments and domains is limited (two arms, simple tabletop tasks, one dynamic interaction domain). How does VLASH perform on mobile robots, legged locomotion, bimanual contact-rich assembly, or deformable object manipulation?
- The method assumes availability and format of state variables (e.g., joint positions, gripper state) and embeds them via a projection layer in . Is the approach robust across different state representations (positions vs. velocities vs. forces) and tokenization schemes?
- Safety in human-robot interaction scenarios (e.g., ping-pong) is not discussed (collision avoidance, speed limits, fail-safes). What policies and runtime monitors are required to ensure safe deployment at higher speeds?
- Energy, thermal, and wear considerations for faster motion via quantization are unmeasured. What is the impact on power consumption, actuator health, and long-term reliability?
- Delay estimation is assumed known or sampled during training; an online delay estimator (e.g., tracking inference and actuation timing) is not included. Can we close the loop by learning or estimating per chunk and embedding delay uncertainty into the policy?
- The approach targets chunked policies; behavior with continuous-time controllers, event-driven policies, or non-chunked VLA architectures is not evaluated. What modifications are needed to extend future-state awareness to these control paradigms?
- VLASH does not address combining future-state awareness with downstream planners (e.g., hierarchical policies where language plans long horizons). How to integrate asynchronous low-level control with high-level re-planning under dynamic environments?
- The code release mentions a repository, but reproducibility of hardware experiments (calibration, controller gains, state interfaces, timing) requires detailed documentation. Providing complete deployment recipes and datasets would improve adoption.
- Interaction between action quantization and asynchronous inference (e.g., quantization changing effective delay or control frequency) is not analyzed. How do we jointly tune , , and for optimal speed-accuracy-latency trade-offs?
- Multi-arm coordination under asynchronous updates (e.g., dual-arm R1 Lite) may require synchronized state roll-forward for both arms; the paper does not detail inter-arm coordination or cross-arm delay handling. What synchronization strategies are needed for multi-effector systems?
- Robustness to occlusions, lighting changes, and sensor noise under stale observations is not tested. Can uncertainty-aware perception or sensor fusion (e.g., tactile/IMU) improve resilience in asynchronous operation?
- The approach presumes consistent control frequency (e.g., 30–50 Hz). How sensitive is VLASH to frequency drift, and can the policy adapt online to varying control rates?
Practical Applications
Immediate Applications
The following applications can be deployed now using VLASH’s future-state-aware asynchronous inference, action chunking, and action quantization, with minimal code and architectural changes to existing VLA systems.
- Robotics (manufacturing and logistics): Real-time pick-and-place, stacking, and sorting on dynamic workcells (e.g., conveyor belts with variable speeds and human presence), achieving smoother motion and 1.1–2.0× task-time speedups without accuracy loss, and up to 2.7× with controlled quantization
- Tools/products/workflows: ROS2/VLA integration module for “future-state rollforward,” an Action Quantization Controller for adjustable speed-accuracy trade-offs, deployment recipes for choosing K (execution horizon), Δ (inference delay), and q (quantization factor)
- Assumptions/dependencies: Reliable robot state sensing at control frequency; the controller uses chunked actions; moderate environmental change during Δ to avoid large perception-state drift; robot safety constraints must be enforced when increasing motion speed
- Robotics (cobots and human-in-the-loop tasks): Smoother, low-latency reactive assistance (e.g., handing tools, tracking moving targets) in shared spaces, with up to 17.4× reduction in maximum reaction latency compared to synchronous control
- Tools/products/workflows: “VLASH Runtime” scheduler that overlaps inference with execution; latency dashboards to measure and tune Δ vs. K in real deployments
- Assumptions/dependencies: Safe stop strategies, collision avoidance layers, and clear HRI policies for operation near humans; tested model utilization of robot state after offset fine-tuning
- Robotics (sports and entertainment): High-speed interactive systems (e.g., ping-pong training robots, whack-a-mole arcade robots) requiring fast and continuous motion with stable control
- Tools/products/workflows: Plug-in for VLA-based sports robots; demo pipelines using future-state conditioning for ball-tracking and strike timing
- Assumptions/dependencies: Robust perception for fast-moving objects; acceptable visual staleness compensated by accurate state rollforward; safety limits on joint speeds
- Robotics (field service): Faster routine tasks (opening/closing doors, flipping switches, operating panels) with reduced stop-and-go behavior
- Tools/products/workflows: VLASH templated workflows for multi-step manipulation sequences; “macro-action” policies to skip unnecessary micro-waypoints
- Assumptions/dependencies: Known kinematics and reliable end-effector state; environment changes within manageable Δ windows
- Software/ML tooling: Efficient fine-tuning pipelines that reuse a single observation across multiple temporal offsets, trimming per-step training time by ~3.3× while preserving synchronous performance after convergence
- Tools/products/workflows: Fine-tuning data packers that build (o_t, s_{t+δ}, A_{t+δ}) sequences with block-sparse attention masks; metric suites for offset generalization
- Assumptions/dependencies: Access to trajectories with robot state and action chunks; masking implementation support in the training framework
- Academia (benchmarks and reproducibility): Standardized evaluation of asynchronous inference on dynamic tasks (Kinetix, LIBERO), enabling fair comparisons against RTC and naive async baselines
- Tools/products/workflows: Open-source VLASH evaluation harness to vary K, Δ, and q; release of protocol for measuring reaction latency and throughput under different hardware budgets
- Assumptions/dependencies: Transparent reporting of inference latency and control frequencies; consistent action chunking policies across models
- Education (robotics labs and courses): Hands-on modules demonstrating the impact of asynchronous inference on reaction speed and motion smoothness; student projects on offset fine-tuning and quantization trade-offs
- Tools/products/workflows: Teaching notebooks illustrating Δ estimation, future-state rollforward, and offset-conditioned training samples; simulator tasks with measurable speedups
- Assumptions/dependencies: Simulators with controllable inference delays; availability of VLA baselines that accept state inputs
Long-Term Applications
The following applications are promising but require further research, scaling, safety certification, and/or domain-specific adaptation beyond the current demonstrations.
- Healthcare (surgical and interventional robots): Low-latency, smooth micro-manipulations in procedures with dynamic tissue motion and instrument interactions
- Tools/products/workflows: Certified VLASH variants with stronger environment prediction (not only robot-state rollforward), fail-safe execution under perception drift, and human oversight loops
- Assumptions/dependencies: Regulatory compliance; rigorous safety layers; high-fidelity sensing; robust handling of rapid, non-robot-originated environment changes
- Autonomous driving and mobile robotics: Future-state-aware planning under sensor latency to stabilize control at high speeds (e.g., warehouse AMRs, delivery robots)
- Tools/products/workflows: Hybrid models that combine VLASH-style robot-state rollforward with environment forecasting (trajectory prediction of dynamic agents)
- Assumptions/dependencies: Accurate motion models and tracking; integration of predictive perception (pedestrians/vehicles); extensive validation in diverse conditions
- Advanced human-robot collaboration: Fast, fluid handovers, co-manipulation, and assembly assistance where the robot anticipates future body states while reasoning over uncertain human motions
- Tools/products/workflows: Joint future-state conditioning for both robot and human pose; multi-agent inference schedulers; compliance control tuned to VLASH output
- Assumptions/dependencies: Reliable human intent/motion prediction; ergonomic and safety standards; social acceptability and operator training
- High-speed industrial assembly: Throughput-optimized lines where macro-actions replace dense micro-waypoints to boost cycle times without degrading quality
- Tools/products/workflows: Toolpath planners built around action quantization, with QA gates that monitor tolerances; automated selection of q per task
- Assumptions/dependencies: Tight tolerances demand accurate calibration; quantization must be constrained to prevent out-of-spec assemblies
- Energy and sustainability: Reduced energy per unit task by minimizing idle periods and stop-and-go motion, with adaptive speed settings to balance power peaks and throughput
- Tools/products/workflows: Energy-aware controllers that co-optimize Δ, K, and q against power budgets; dashboards tracking energy vs. cycle time
- Assumptions/dependencies: Detailed energy metering; facility-level optimization; maintaining safety at higher motion speeds
- Policy and standards: Guidelines for deploying asynchronous VLA control in human environments, covering latency characterization, state rollforward validation, logging, and auditability
- Tools/products/workflows: Certification frameworks that require reporting Δ/K, action-freezing/quantization policies, and safety interlocks
- Assumptions/dependencies: Consensus among regulators, manufacturers, and researchers; standardized benchmarks and incident reporting
- Cross-domain ML advances: Generalizing future-state-aware asynchronous inference beyond robotics (e.g., physical simulation control, prosthetics, mixed-reality systems), pairing state rollforward with environment prediction for robust performance under delays
- Tools/products/workflows: Unified async inference APIs; libraries that combine state evolution with predictive perception modules
- Assumptions/dependencies: Domain-specific models for non-robot state evolution; integration of multimodal forecasts; user safety and comfort in interactive systems
- Consumer home robots: Fast, continuous assistance (tidying, organizing, light meal prep) with minimal stalls and better responsiveness to human cues
- Tools/products/workflows: Household VLAs that accept robot state inputs and implement future-state conditioning; tunable quantization for varying task precision
- Assumptions/dependencies: Robust perception in cluttered, changing environments; strong safety constraints around children and pets; affordability and reliability at scale
In summary, VLASH provides an immediately deployable path to smoother, faster, and more reactive robotic control, with simple future-state conditioning, efficient offset fine-tuning, and action quantization. Its core ideas can be extended to increasingly dynamic, safety-critical, and collaborative scenarios as environment prediction, safety engineering, and certification progress.
Glossary
- Action chunk: A contiguous sequence of low-level robot commands produced in one inference cycle for execution. "the robot first performs model inference to generate an action chunk~\cite{zhao2023learning}, then sequentially executes the actions before initiating the next inference cycle."
- Action chunking policy: A policy that outputs a chunk of future actions conditioned on current observations and robot state. "We consider an action chunking policy ~\cite{zhao2023learningfinegrainedbimanualmanipulation,intelligence2025pi_,shukor2025smolvla}"
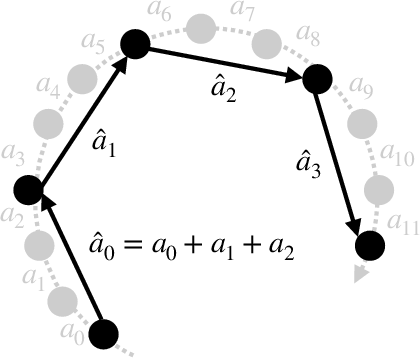
- Action quantization: Grouping fine-grained actions into coarser macro-actions to speed up motion with a controlled accuracy trade-off. "As a result, action quantization offers a tunable speed-accuracy trade-off: small quantization factors behave like the original fine-grained policy, while larger factors yield progressively faster but less fine-grained motion."
- Asynchronous inference: Performing model inference concurrently with action execution to reduce stalls and latency. "Asynchronous inference offers a promising solution to achieve continuous and low-latency control by enabling robots to execute actions and perform inference simultaneously."
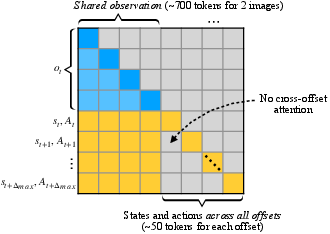
- Block-sparse self-attention mask: An attention design where tokens can attend within defined blocks (e.g., shared observation vs. per-offset branches), improving efficiency. "We then apply a block-sparse self-attention mask with the following structure:"
- Controller timestep: The discrete time index at which the controller updates actions and state. "and is the controller timestep."
- CUDAGraph: A CUDA feature that captures and replays GPU workloads to reduce overhead and latency. "using torch.compile to enable CUDAGraph optimization and kernel fusion for minimal latency~\cite{10.1145/362(0665.36403)66}."
- Delta actions: Actions represented as incremental changes (deltas) to the robot’s state rather than absolute targets. "For delta actions, this can be implemented as"
- DDP: Distributed Data Parallel; a training paradigm that parallelizes model updates across multiple GPUs. "trained on 4ÃH100 GPUs with DDP~\cite{li2020pytorch}."
- DOF: Degrees of freedom; the number of independent movements a robotic arm can perform. "The SO-101 is a 6-DOF collaborative robotic arm from LeRobot~\cite{cadene2024lerobot}."
- Execution horizon: The number of planned actions from a chunk that will actually be executed before the next inference. "We denote as the execution horizon."
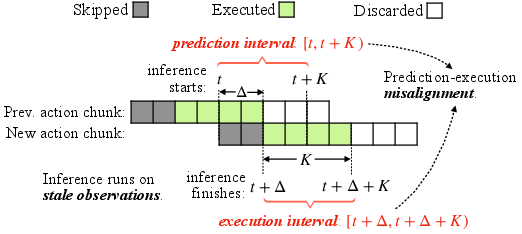
- Execution interval: The time span during which the selected actions from a chunk are applied to the robot, shifted by inference delay. "Then the actions from are actually executed on the robot over the execution interval I_t{\text{exec} = [t+\Delta,\, t+\Delta+K)."
- Flow policies: Policies structured around sequences of action chunks, often used for dynamic control tasks. "we train action chunking flow policies with a prediction horizon of and a 4-layer MLP-Mixer~\cite{tolstikhin2021mlp} architecture for 32 epochs."
- Future-state-aware: Conditioning policy inference on the robot’s predicted state at the time actions will begin execution. "Our key idea is to make the policy future-state-aware: instead of conditioning on the current robot state , we condition on the robot state at the beginning of the next execution interval ."
- Inference latency: The delay, measured in control steps or milliseconds, between starting inference and obtaining actions. "Let be the inference latency measured in control steps."
- Inpainting: Filling in or synthesizing missing parts of an action chunk (e.g., actions not guaranteed to execute) to maintain continuity. "RTC~\cite{black2025real} mitigates this by freezing the actions guaranteed to execute and inpainting the rest, but it introduces additional runtime overhead and complicates the deployment."
- Kernel fusion: Combining multiple GPU kernels into fewer, larger kernels to reduce launch overhead and improve performance. "using torch.compile to enable CUDAGraph optimization and kernel fusion for minimal latency~\cite{10.1145/362(0665.36403)66}."
- Macro-actions: Coarse-grained actions that aggregate several finer micro-actions into a single step. "macro-actions (black), where each macro-action summarizes consecutive fine-grained actions"
- Micro-actions: Fine-grained, small incremental control steps typically recorded at high frequency. "Executing macro-actions instead of all micro-actions increases the distance moved per control step, effectively speeding up the robotâs motion."
- MLP-Mixer: A neural network architecture that uses MLPs for both channel and token mixing, used here for action chunking policies. "a 4-layer MLP-Mixer~\cite{tolstikhin2021mlp} architecture"
- Positional encodings: Numeric embeddings that inject token position information into a model, reused across offset branches here. "Positional encodings of each offset branch are reassigned to start at the same index, equal to the length of observation tokens."
- Prediction-execution misalignment: The mismatch between when actions are predicted and when they are actually executed due to inference delay. "Prediction-execution misalignment in asynchronous inference."
- Prediction horizon: The number of future actions the policy predicts in one chunk. "We refer to as the prediction horizon."
- Prediction interval: The nominal time span for which the predicted actions are planned before considering inference delay. "As illustrated in Fig.~\ref{fig:interval-misalignment}, when , the action chunk is planned for the prediction interval $I_t^{\text{pred} = [t, t+K)$ but actually executed over the shifted execution interval $I_t^{\text{exec} = [t+\Delta, t+\Delta+K)$."
- Quantization factor: The number of fine-grained steps grouped into a single macro-action during quantization. "for quantization factor "
- Real-time Chunking (RTC): A method that freezes guaranteed-to-execute actions and inpaints the remainder to reduce misalignment, with added overhead. "Real-time Chunking (RTC)~\cite{black2025real} mitigates this by freezing the actions guaranteed to execute and inpainting the rest."
- Teleoperation: Human-operated control that produces high-frequency, fine-grained action trajectories used for training. "fine-grained teleoperation data (e.g., 50\,Hz control with small deltas at each step)~\cite{black2024pi_0,intelligence2025pi_}"
- Temporal-offset augmentation: A training strategy that pairs a fixed observation with future states and actions at different time offsets to teach state usage. "We instead apply a simple temporal-offset augmentation with two key steps:"
- Tokenizer: The component that converts text into tokens; here bypassed for state inputs in deployment. "we apply a projection layer to map the robot state into an embedding, bypassing the tokenizer instead of incorporating it into the language prompt in the original implementation."
- Torch.compile: A PyTorch feature that compiles models for optimized execution, enabling graph capture and fusion. "using torch.compile to enable CUDAGraph optimization and kernel fusion for minimal latency~\cite{10.1145/362(0665.36403)66}."
- Vision-Language-Action models (VLAs): Models that integrate visual perception and language understanding to produce robotic actions. "Vision-Language-Action models (VLAs) are becoming increasingly capable across diverse robotic tasks."
Collections
Sign up for free to add this paper to one or more collections.

