- The paper introduces a Multi-Answer RL approach that incentivizes language models to generate sets of diverse, valid answers rather than a single response.
- Experiments show that this method improves correctness, answer diversity, and token efficiency across tasks like differential diagnosis, ambiguous QA, and code synthesis.
- The approach enhances uncertainty calibration using set-level scoring, paving the way for robust applications in high-stakes and ambiguous settings.
Multi-Answer Reinforcement Learning for Distributional Reasoning in LLMs
Introduction
Traditional reinforcement learning (RL) fine-tuning for LMs, especially RL with verifiable rewards (RLVR), prioritizes optimizing for a single most likely answer. This mode-seeking paradigm inherently limits the capacity of LMs to generate multiple plausible hypotheses, which is crucial for tasks involving irreducible uncertainty or multiple valid outputs (e.g., clinical differential diagnosis, ambiguous question answering, or diverse code synthesis). The present work proposes and systematically investigates "Multi-Answer Reinforcement Learning" (Multi-Answer RL), which directly incentivizes models to produce sets of diverse, plausible answers per prompt, along with calibrated uncertainty estimates when appropriate.
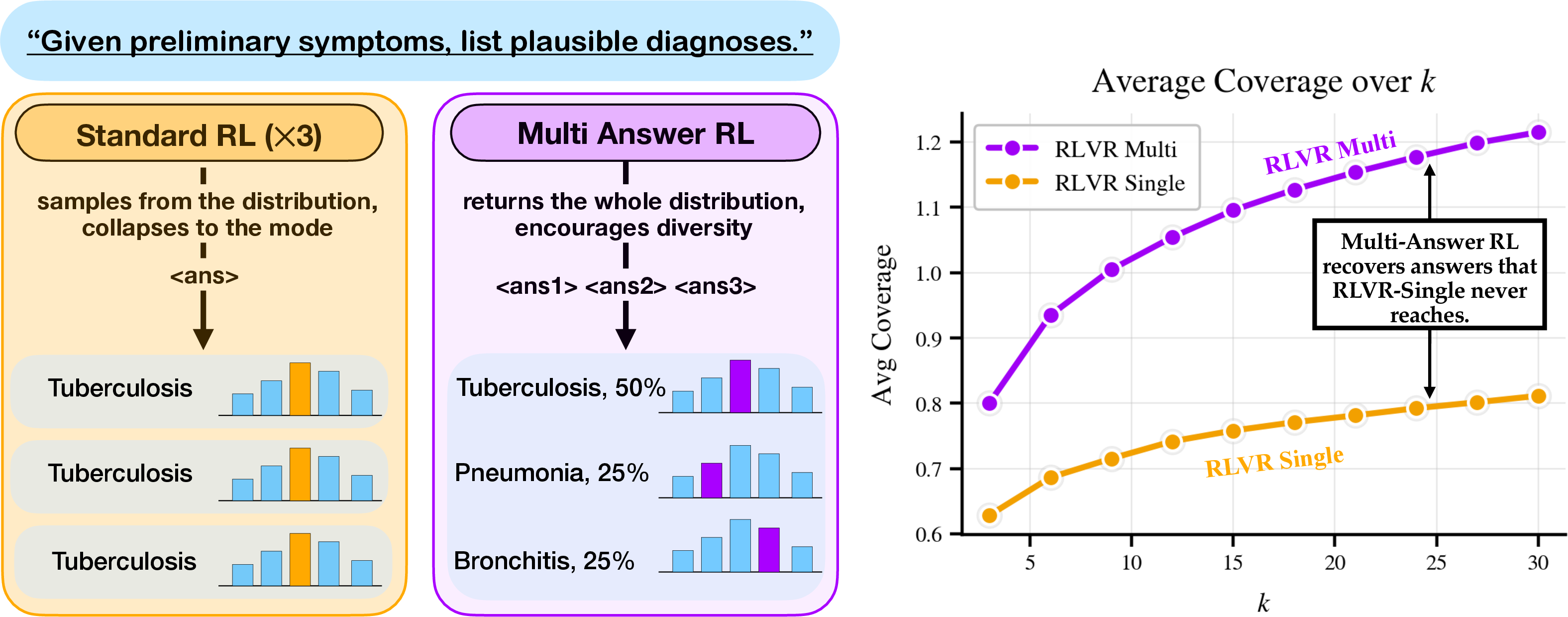
Figure 1: Standard RL trains LMs to produce the most likely answer, while Multi-Answer RL enables explicit set-generative distributional reasoning.
The Multi-Answer RL approach extends RLVR and calibration-focused RLCR by generalizing the reward structure to account for set-valued answers. For RLVR, the policy is trained to maximize the count of distinct, valid answers in a single generation. RLCR is further generalized: the model outputs both a candidate answer set and a vector of confidences, trained with a proper scoring rule (multi-answer Brier score), optimally aligning predicted confidence with ground-truth answer presence.
This set-level optimization internalizes the answer search process: models are trained to reason about diverse hypotheses during generation rather than relying on computationally inefficient inference-time resampling. Rigorous format rewards ensure syntactic validity of structured outputs and uniqueness constraints within sets.
Empirical Evaluation
Experiments are conducted on three tasks with varying ambiguity and multiplicity: DDXPlus (medical differential diagnosis), HotPotQA-Modified (ambiguous QA), and MBPP (program synthesis with multiple correct approaches). The Qwen3-8B backbone is adapted with a GRPO algorithmic variant, and models are evaluated on correctness (coverage, top-1 accuracy), diversity (unique answers), computational efficiency (total token count), and calibration metrics (Brier score, ECE).
Efficacy: Correctness, Diversity, and Efficiency
Across all tasks, Multi-Answer RL consistently outperforms single-answer baselines on set-level correctness (average correct per set) and diversity (uniqueness within sets), even when single-answer models are prompted post hoc to output multiple candidates.
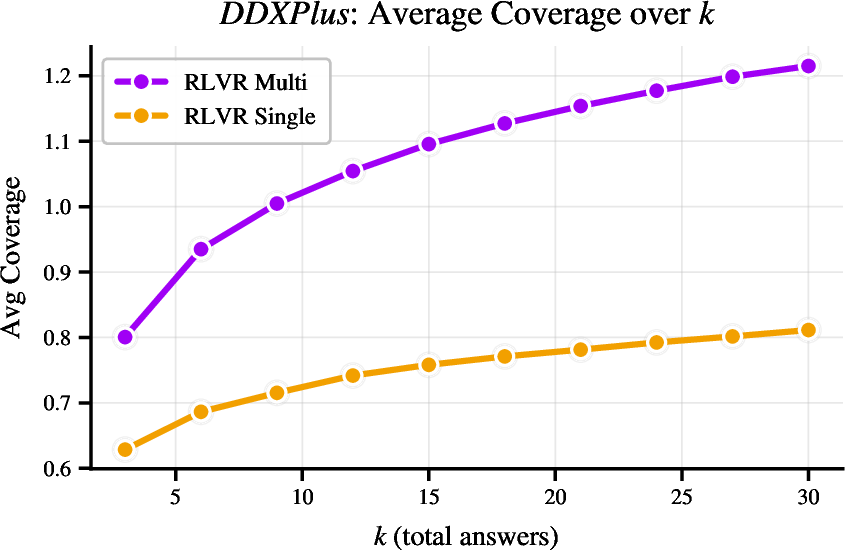
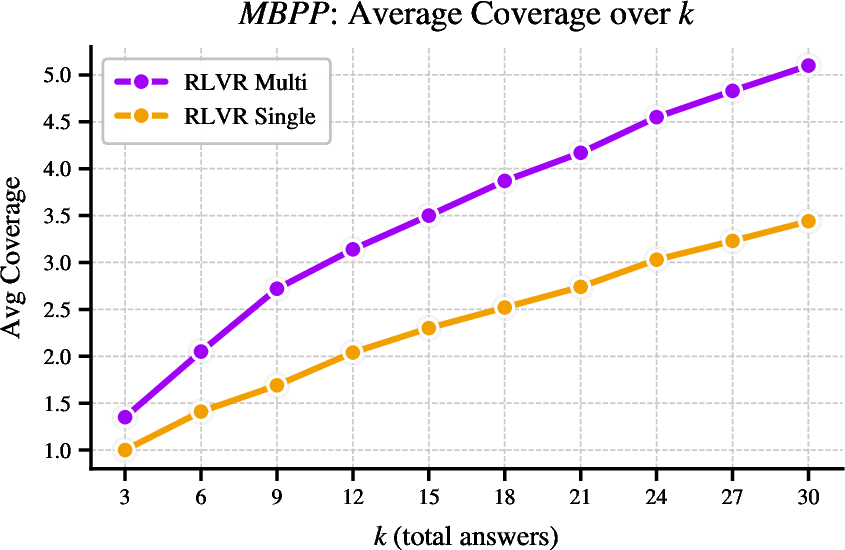
Figure 2: RLVR-Multi produces substantially more unique correct answers than RLVR-Single for identical total generations, indicating a collapse in diversity for single-answer RL.
In DDXPlus, Multi-Answer RL captures a broader subset of gold-standard diagnoses per case than single-answer methods, directly targeting the requirements of real-world differential diagnosis. In MBPP code generation, Multi-Answer training yields not only higher pass@k metrics but also structurally diverse solutions, as measured by AST-based uniqueness, compared to the mode-collapsed samples of RLVR-Single.
Crucially, Multi-Answer training achieves these gains with significantly better token efficiency: generating K answers jointly in one response requires nearly half the total tokens compared to independent repeated sampling, as much of the reasoning is amortized.

Figure 3: Mode-seeking RLVR-Single generations redundantly replicate reasoning subsequences, whereas Multi-Answer RL jointly optimizes diverse, less-overlapping chains, increasing answer diversity per token.
Calibration of Uncertainty
Multi-Answer RLCR establishes set-level confidence calibration never matched by RLVR variants, conferring better Brier scores and lower set- and pooled-ECE, especially on ambiguous or multi-label tasks.
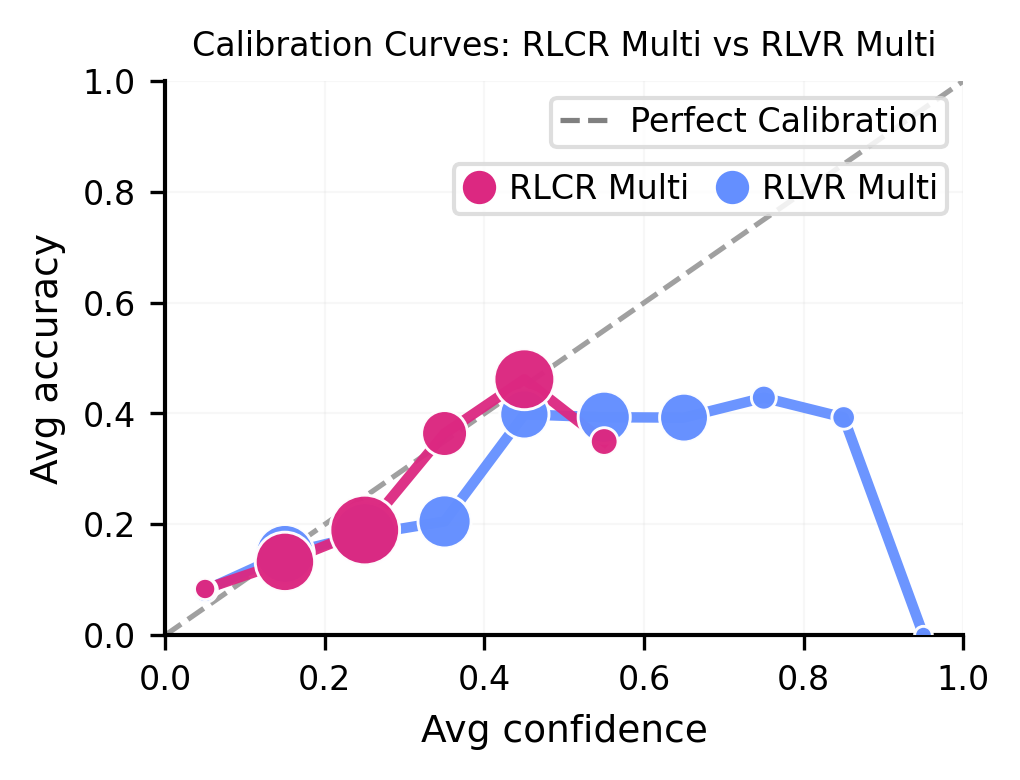
Figure 4: On DDXPlus, RLCR-Multi tracks the calibration identity line, whereas RLVR-Multi is consistently overconfident.
The calibration benefit of RLCR persists across domains. However, a notable failure mode is observed in settings with single gold answers and severe ambiguity: the model heuristic to allocate sum of confidences ≤1 can result in under-confidence relative to the true empirical set coverage. This underlines the need for future developments in differentiating set priors under massive uncertainty.
Stability, Scaling, and Limitations
Multi-Answer RL remains robust as the target set size K increases, with monotonic growth in coverage (i.e., recovery of unique correct answers) and output stability during training.
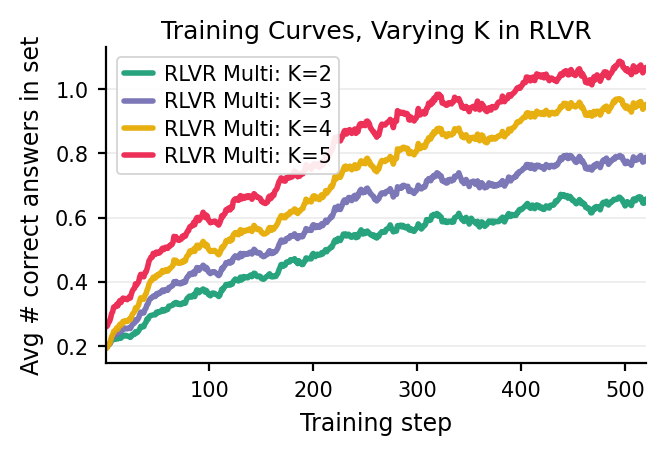
Figure 5: As k increases, Multi-Answer RLVR stably increases the number of unique, correct diagnoses extracted per generation.
Nevertheless, top-1 accuracy with Multi-Answer training may modestly lag behind aggressively mode-seeking single-answer objectives. The method’s benefits manifest primarily for applications prioritizing distributional coverage, calibrated uncertainty, creative generation, or minimizing inference compute cost.
Implications and Future Directions
Multi-Answer RL directly addresses the entropy collapse endemic to mode-seeking RL-fine-tuned LMs, fundamentally increasing the actionable diversity and epistemic transparency of outputs. This framework is theoretically motivated by structured scoring rules and practically validated across domains—enabling deployment of LMs in high-stakes or ambiguous tasks where single-point predictions are insufficient.
The approach’s broad applicability suggests several avenues for extension: scaling to larger sets or more complex compositional outputs, investigating advanced exploration strategies to mitigate over-hedging in calibration, and translation to multi-agent or interactive settings where maintaining calibrated distributions over hypotheses may be essential for robust system behavior.
Conclusion
Multi-Answer Reinforcement Learning reconceptualizes LM output structures as explicit distributions over plausible answers with set-level reasoning and calibrated confidence. This paradigm delivers substantial improvements in diversity, coverage, calibration, and compute efficiency on ambiguous and multi-label reasoning tasks, without sacrificing top-level performance. Its principled integration of distributional reasoning marks a concrete step toward LMs that more faithfully model the epistemic uncertainty intrinsic to language understanding and downstream decision-making.

