- The paper introduces RLCR, which uses Brier score rewards to jointly optimize correctness and confidence calibration in language models.
- RLCR leverages structured chain-of-thought reasoning to produce calibrated confidence estimates for both in-domain and out-of-distribution tasks.
- Empirical results demonstrate improved accuracy, lower calibration error, and enhanced test-time ensembling compared to traditional RL methods.
Training LLMs to Reason About Their Uncertainty: RLCR
Introduction
This paper introduces RLCR (Reinforcement Learning with Calibration Rewards), a method for training LMs to produce both accurate answers and well-calibrated confidence estimates in chain-of-thought (CoT) reasoning. The motivation is that standard RL-based reasoning training (RLVR), which optimizes for binary correctness, often leads to overconfident and poorly calibrated models, especially in out-of-distribution (OOD) settings. RLCR augments the reward with a proper scoring rule (specifically, the Brier score), incentivizing models to output confidence estimates that reflect the true probability of correctness. Theoretical analysis and extensive empirical results demonstrate that RLCR achieves simultaneous improvements in accuracy and calibration, outperforming both standard RL and post-hoc calibration approaches.
Methodology: RLCR Objective and Theoretical Properties
The RLCR objective is defined as:
$RLCR(y, q, y^*) = \mathbbm{1}_{y\equiv y^*} - (q - \mathbbm{1}_{y\equiv y^*})^2$
where y is the model's answer, q is its verbalized confidence, and y∗ is the ground-truth answer. The first term rewards correctness, while the second (the negative Brier score) penalizes miscalibration.
Theoretical analysis shows that, for any bounded proper scoring rule, the expected RLCR reward is maximized when the model outputs the most likely answer and sets its confidence to the true probability of correctness. This is not true for unbounded scoring rules (e.g., log-loss), which can incentivize degenerate solutions. The Brier score is both proper and bounded, making it suitable for this joint objective.
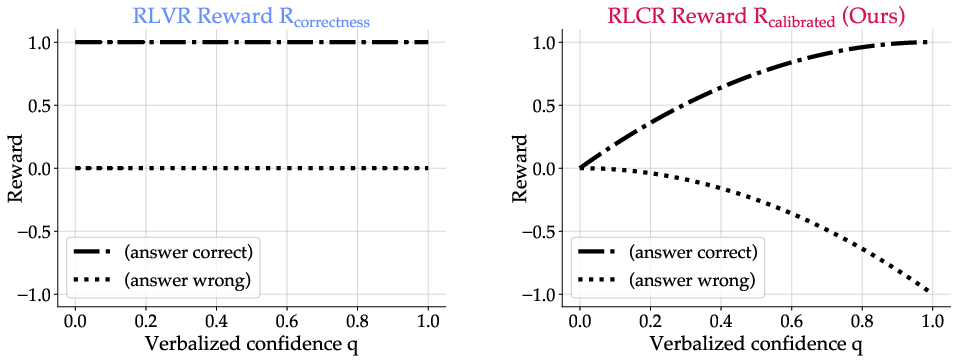
Figure 1: RLVR (a) rewards only correctness, incentivizing overconfident guessing; RLCR (b) jointly optimizes for correctness and calibration.
Implementation Details
RLCR is implemented by prompting models to output structured reasoning traces with > , <answer>, <analysis>, and <confidence> tags. The reward function is computed by evaluating both the correctness of the answer and the calibration of the confidence score. Training uses GRPO as the RL algorithm, with Qwen2.5-7B as the base model. Format rewards are used to enforce output structure.
For math tasks, a lightweight SFT warmup phase is used to improve the quality of uncertainty analyses. Evaluation is performed on a suite of QA and math datasets, with metrics including accuracy, AUROC, Brier score, and ECE.
Empirical Results
In-Domain and Out-of-Domain Calibration
RLCR matches RLVR in accuracy on in-domain tasks (e.g., HotPotQA, Big-Math) but achieves substantially lower calibration error (ECE drops from 0.37 to 0.03 on HotPotQA). On OOD datasets, RLVR degrades calibration relative to the base model, while RLCR improves it, outperforming both RLVR and post-hoc classifier-based calibration.
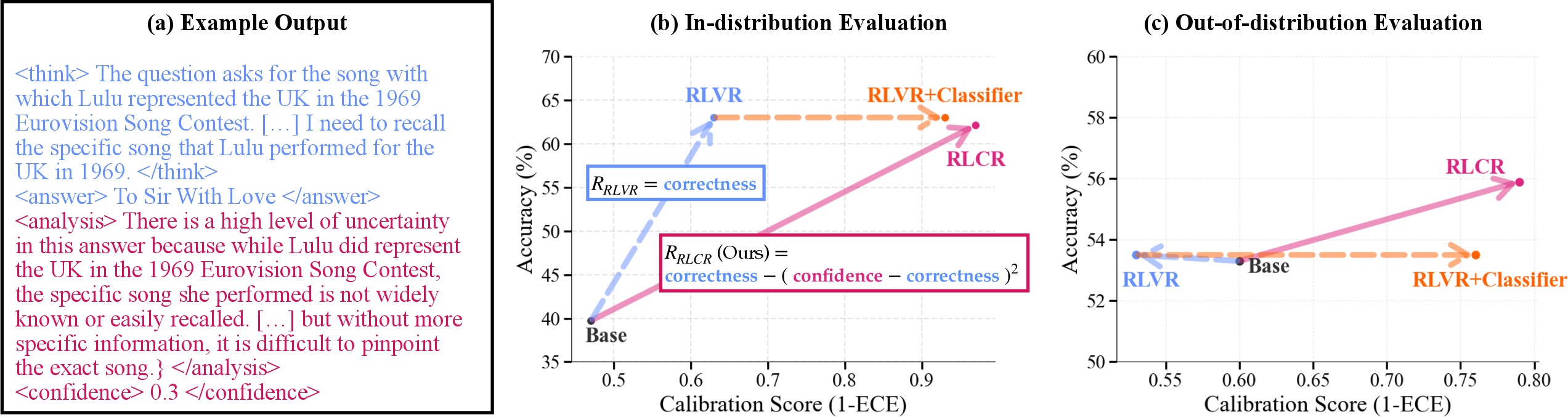
Figure 2: (a) Example RLCR reasoning trace; (b) RLCR improves in-domain accuracy and calibration; (c) RLCR generalizes better to OOD tasks, improving both accuracy and calibration.
Training Dynamics
RLCR enables simultaneous improvement in both correctness and calibration rewards during training, as shown by reward curves. The length of completions increases as the model learns to reason about uncertainty, indicating more elaborate uncertainty analyses.
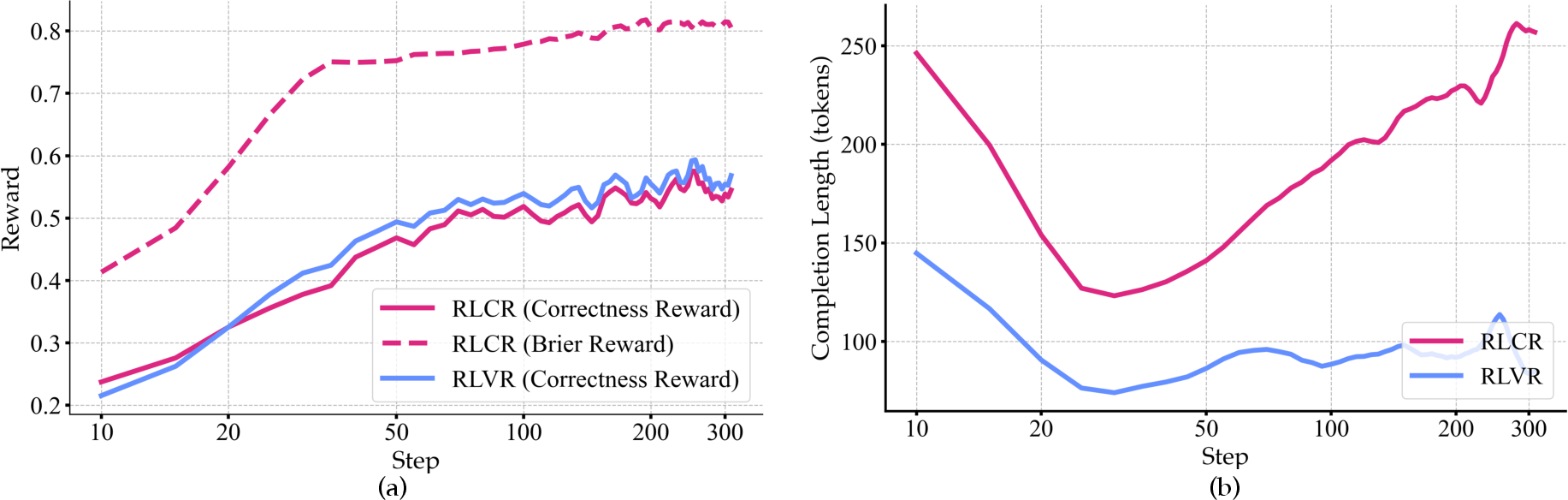
Figure 3: (a) RLCR improves both correctness and calibration rewards; (b) Completion lengths increase as uncertainty reasoning improves.
Test-Time Scaling and Ensembling
Verbalized confidences from RLCR can be used for test-time scaling. Confidence-weighted majority voting outperforms vanilla majority vote and max-confidence selection, demonstrating that calibrated confidences provide complementary information to answer agreement. Ensembling multiple uncertainty analyses for a fixed answer further reduces Brier score, improving calibration with minimal computational overhead.
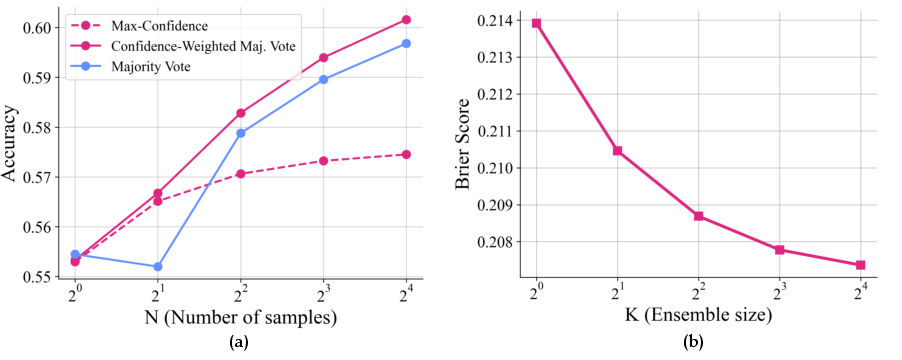
Figure 4: (a) Confidence-weighted majority vote yields highest accuracy as sample count increases; (b) Brier score improves with ensemble size for confidence estimation.
Model Size and Calibration
Analysis classifiers trained on RLCR outputs outperform those trained on RLVR outputs at smaller model sizes, indicating that explicit uncertainty reasoning is especially beneficial for calibration when model capacity is limited.
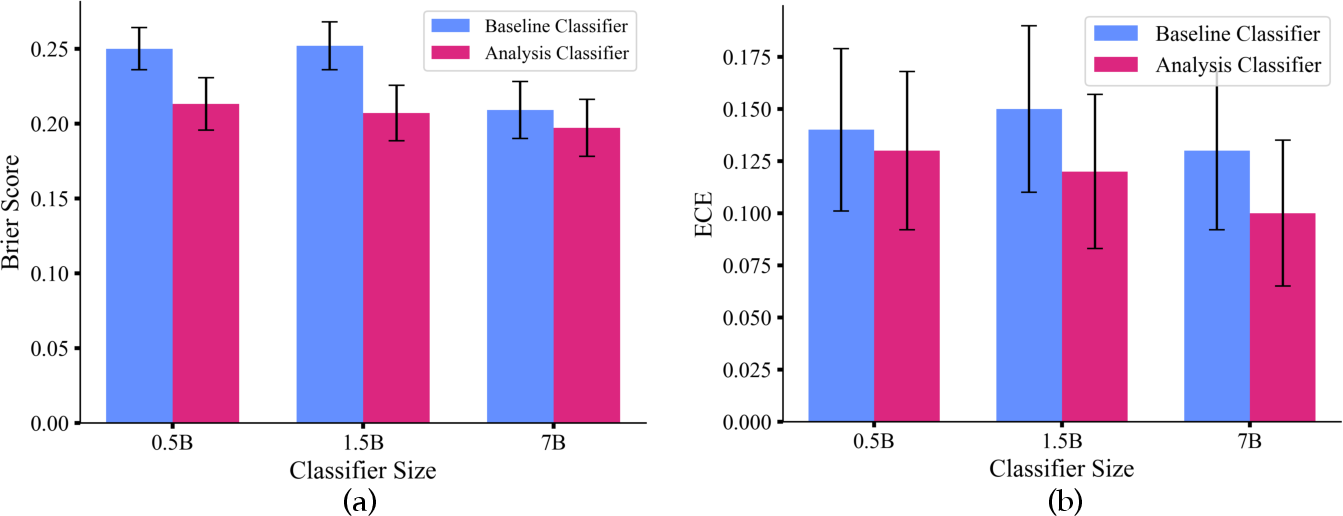
Figure 5: Analysis classifiers (using uncertainty CoT) outperform baselines in Brier and ECE at small model sizes.
Consistency of Confidence Estimates
RLCR models produce self-consistent confidence estimates across multiple reasoning chains for the same answer (low intra-answer standard deviation). For mutually exclusive answers, RLCR's confidence sums are closer to 1 than RLVR, though some overconfidence remains, especially OOD.
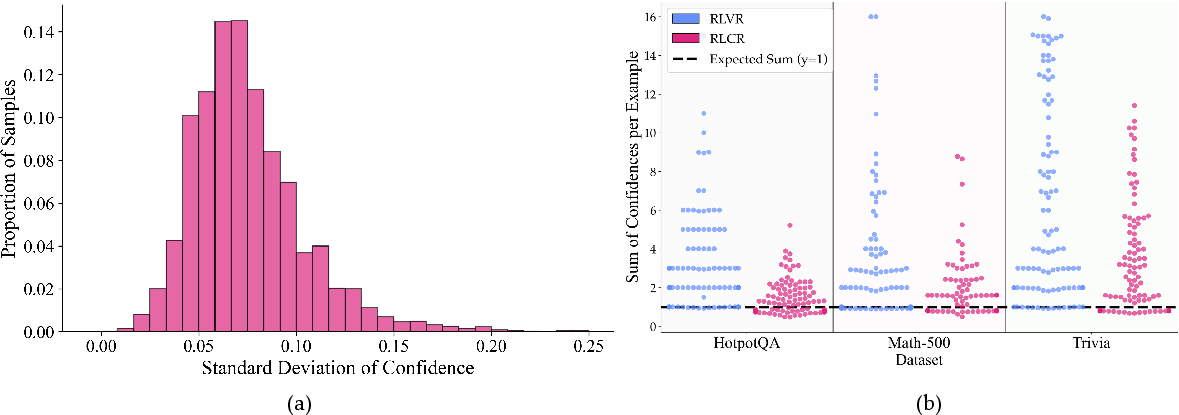
Figure 6: (a) Most samples have low standard deviation in confidence across chains; (b) RLCR's confidence sums are closer to the ideal value of 1.
Practical Implications and Limitations
RLCR provides a practical, theoretically justified approach for training LMs that are both accurate and reliably calibrated. The method is simple to implement, requiring only minor modifications to standard RL training and output formatting. RLCR's calibrated confidences can be directly leveraged for downstream decision-making, abstention, and ensembling, with no need for additional classifiers or probes.
However, absolute calibration error remains high OOD, and models can still assign high confidence to multiple contradictory answers. SFT warmup can improve uncertainty analysis quality but may reduce OOD accuracy due to catastrophic forgetting. Further research is needed to address these limitations, especially for scaling to larger models and more diverse tasks.
Theoretical and Future Directions
The paper's theoretical results clarify the conditions under which joint optimization of accuracy and calibration is possible, highlighting the importance of bounded proper scoring rules. This framework can be extended to more complex output spaces and richer uncertainty representations (e.g., full answer distributions).
Future work may explore:
- More expressive uncertainty representations (e.g., distributions over answers)
- Improved prompts and architectures for uncertainty reasoning
- Integration with abstention and selective prediction frameworks
- Scaling to larger models and more challenging OOD settings
- Applications in high-stakes domains (e.g., healthcare, law) where reliable uncertainty quantification is critical
Conclusion
RLCR demonstrates that LMs can be trained to reason about their own uncertainty, achieving both high accuracy and strong calibration in CoT reasoning. The approach is theoretically grounded, empirically validated, and practically deployable. While challenges remain in OOD calibration and inter-answer consistency, RLCR represents a significant step toward more reliable and trustworthy reasoning systems.